Oracle基础部分二(伪列/表、单个函数、空值处理、行列转换、分析函数、集合运算)
- 1 伪列、伪表
- 1.1 伪列
- 1.2 伪表
- 2 单个函数
- 2.1 常用字符串函数
- 2.1.1 length() 询指定字符的长度
- 2.1.2 substr() 用于截取字符串
- 2.1.3 concat() 用于字符串拼接
- 2.2 常用数值函数
- 2.2.1 round() 四舍五入
- 2.2.2 trunc(for number) 数字截取
- 2.2.2 mod() 取模
- 2.3 常用日期函数
- 2.3.1 sysdate 当前日期时间
- 2.3.2 add_months() 加月份函数
- 2.3.3 LAST_DAY() 所在月的最后一天
- 2.3.4 TRUNC(for dates) 日期的截取
- 2.4 其他函数
- 2.4.1 nvl() 空值函数
- 2.4.2 decode() 条件取值
- 3 行列转换
- 3.1 使用PIVOT
- 3.2 使用sum和 DECODE 函数
- 3.2 使用 CASE WHEN 和 GROUP BY
- 4 分析函数
- 4.1 rank() 值相同 排名相同 序号跳跃
- 4.2 dense_rank() 值相同 排名相同 序号连续
- 4.3 row_number() over() 序号连续,不管值是否相同
- 5、集合运算
- 5.1 union all 并集(包括重复记录)
- 5.2 union 并集(不包括重复记录)
- 5.3 intersect 交集(两个集合的重复部分)
- 5.4 minus 差集
- 5.4.1 示例1
- 5.4.2 减运算分页
1 伪列、伪表
1.1 伪列
rowid:rowid是一个用来唯一标记表中行的伪列。它是物理表中行数据的内部地址,包含两个地址,其一为指向数据表中包含该行的块所存放数据文件的地址,另一个是可以直接定位到数据行自身的这一行在数据块中的地址。
除了在同一聚簇中可能不唯一外,每条记录的rowid是唯一的。可以理解成rowid就是唯一的
rownum:rownum是Oracle系统顺序分配为从查询返回的行的编号,返回的第一行分配的是1,返回的第二行分配的是2,这个为字段可以用于限制返回查询的总行数,且rownum不可以以任何表的名称作为前缀
1.2 伪表
dual:dual 确实是一张表,是一张只有一个字段,一行记录的表。它的字段和记录都是无意义的。通常我们称之为’伪表’。dual表示系统自带的,是一个系统表,不能删除或者修改其表结构
2 单个函数
2.1 常用字符串函数
2.1.1 length() 询指定字符的长度
语法:length(string)
解释:计算string所占的字符长度
select length('ABCD') from dual
结果为 4
2.1.2 substr() 用于截取字符串
语法: substr(string string, int a[, int b]);
解释:string 需要截取的,a 截取字符串的开始位置(注:当a等于0或1时,都是从第一位开始截取),b 要截取的字符串的长度(省略为截取到最后)
select substr('ABCD',2,2) from dual
结果为 BC
2.1.3 concat() 用于字符串拼接
语法:Concat(表达式1,表达式2)
解释:用表达式1值和表达式2值进行拼接显示。
select concat('A','B') from dual
结果为 AB
另外还有其他的拼接方式
select concat(concat('A','B'),'C') from dual -- concat只能拼接两个字符串,需要拼接多个需要嵌套
select 'A' || 'B' || 'C' from dual -- 可以使用 || 进行字符串的拼接
2.2 常用数值函数
2.2.1 round() 四舍五入
语法:ROUND(number[,decimals])
解释:number 待做截取处理的数值,decimals 指明需保留小数点后面的位数。可选项,忽略它则截去所有的小数部分,并四舍五入。如果为负数则表示从小数点开始左边的位数,相应整数数字用0填充,小数被去掉。需要注意的是,和trunc函数不同,对截取的数字要四舍五入。
select round(100.456,2) from dual -- 100.46
2.2.2 trunc(for number) 数字截取
语法:TRUNC(number[,decimals])
解释:number 待做截取处理的数值;decimals 指明需保留小数点后面的位数,可选项,忽略它则截去所有的小数部分。
注意:截取时并不对数据进行四舍五入
select trunc(100.456,2) from dual -- 100.45
2.2.2 mod() 取模
语法:mod(m,n)
解释:(1)MOD返回m除以n的余数,如果n是0,返回m;(2)这个函数以任何数字数据类型或任何非数值型数据类型为参数,可以隐式地转换为数字数据类型。
select mod(10,3) from dual -- 1
2.3 常用日期函数
2.3.1 sysdate 当前日期时间
语法:sysdate
解释:返回当前日期时间
select sysdate from dual -- 2023-04-11 22:02:30
2.3.2 add_months() 加月份函数
语法:add_months(times,months)
解释:用于计算在时间times之上加上months个月后的时间值,要是months的值为负数的话就是在这个时间点之间的时间值(这个时间-months个月)
select add_months(sysdate,2) from dual -- 2023-06-11 22:06:04
2.3.3 LAST_DAY() 所在月的最后一天
语法:last_day(time)
解析:返回指定日期所在月份的最后一天
select last_day(sysdate) from dual -- 2023-04-30 22:08:30
2.3.4 TRUNC(for dates) 日期的截取
语法:TRUNC(date[,fmt])
解释:date 一个日期值;fmt 日期格式; 该日期将按指定的日期格式截取;忽略它则由最近的日期截取
select trunc(sysdate,'mi') from dual -- 按分钟截取(把秒截掉,显示当前日期的分钟)
select trunc(sysdate,'hh') from dual -- 按小时截取(把分钟截掉,显示当前日期的小时)
select trunc(sysdate) from dual -- 按日截取(把时间截掉)
select trunc(sysdate,'mm') from dual -- 按月截取(把日截掉,显示当月第一天)
select trunc(sysdate,'yyyy') from dual -- 按年截取(把月截掉,显示当年第一天)
2.4 其他函数
2.4.1 nvl() 空值函数
语法:NVL(表达式1,表达式2)
解释:如果表达式1为空值,NVL返回值为表达式2的值,否则返回表达式1的值。该函数的目的是把一个空值(null)转换成一个实际的值。其表达式的值可以是数字型、字符型和日期型。但是表达式1和表达式2的数据类型必须为同一个类型。
SELECT NVL(NULL, 0) FROM DUAL; -- 0
2.4.2 decode() 条件取值
语法1:decode(expression,value,result1,result2)
解释:如果expression=value,则输出result1,否则输出result2
语法1:decode(expression,value1,result1,value2,result2,value3,result3…,default)
解释: 如果expression=value1,则输出result1,expression=value2,输出reslut2,expression=value3,输出result3,若expression不等于所列出的所有value,则输出为default
select decode(100,1,2,400,200,500) from dual -- 500
3 行列转换
3.1 使用PIVOT
语法1: PIVOT(任意聚合函数 FOR 列名 IN(类型))
解释:【聚合函数】聚合的字段,是需要转化为列值的字段;【列名】是需要转化为列标识的字段,【类型】即是需要的结果展示,【类型】中可以指定别名; IN中还可以指定子查询。
SELECT * FROM (
SELECT
A16.INTEREST_RATE_CD
,A16.DATA_DT
,A16.TERM
,A16.INTEREST_RATE
FROM FACT_FTP260_BSC_A16 A16
)
PIVOT(
SUM(INTEREST_RATE)
FOR TERM
IN ('1D' AS D1 ,'7D' AS D7 ,'14D' AS D14
,'1M' AS M1 ,'2M' AS M2 ,'6M' AS M6
,'9M' AS M9 ,'1Y' AS Y1 ,'2Y' AS Y2
,'3Y' AS Y3 ,'5Y' AS Y5 ,'7Y' AS Y7
,'10Y' AS Y10 ,'15Y' AS Y15 )
)
3.2 使用sum和 DECODE 函数
select (select name from t_area where id = areaid) 区域,
sum(case when month='01' then money else 0 end)一月,
sum(case when month='02' then money else 0 end)二月,
sum(case when month='03' then money else 0 end)三月,
sum(case when month='04' then money else 0 end)四月,
sum(case when month='05' then money else 0 end)五月,
sum(case when month='06' then money else 0 end)六月,
sum(case when month='07' then money else 0 end)七月,
sum(case when month='08' then money else 0 end)八月,
sum(case when month='09' then money else 0 end)九月,
sum(case when month='10' then money else 0 end)十月,
sum(case when month='11' then money else 0 end)十一月,
sum(case when month='12' then money else 0 end)十二月
from t_account
where year = '2012'
group by areaid
3.2 使用 CASE WHEN 和 GROUP BY
注:这种方式是最常用的,比价容易理解
SELECT
A16.INTEREST_RATE_CD
,SUM(CASE TERM WHEN '1D' THEN A16.INTEREST_RATE ELSE 0 END) AS D1
,SUM(CASE TERM WHEN '7D' THEN A16.INTEREST_RATE ELSE 0 END) AS D7
,SUM(CASE TERM WHEN '14D' THEN A16.INTEREST_RATE ELSE 0 END) AS D14
,SUM(CASE TERM WHEN '1M' THEN A16.INTEREST_RATE ELSE 0 END) AS M1
,SUM(CASE TERM WHEN '2M' THEN A16.INTEREST_RATE ELSE 0 END) AS M2
,SUM(CASE TERM WHEN '3M' THEN A16.INTEREST_RATE ELSE 0 END) AS M3
,SUM(CASE TERM WHEN '6M' THEN A16.INTEREST_RATE ELSE 0 END) AS M6
,SUM(CASE TERM WHEN '9M' THEN A16.INTEREST_RATE ELSE 0 END) AS M9
,SUM(CASE TERM WHEN '1Y' THEN A16.INTEREST_RATE ELSE 0 END) AS Y1
,SUM(CASE TERM WHEN '2Y' THEN A16.INTEREST_RATE ELSE 0 END) AS Y2
,SUM(CASE TERM WHEN '3Y' THEN A16.INTEREST_RATE ELSE 0 END) AS Y3
,SUM(CASE TERM WHEN '5Y' THEN A16.INTEREST_RATE ELSE 0 END) AS Y5
,SUM(CASE TERM WHEN '7Y' THEN A16.INTEREST_RATE ELSE 0 END) AS Y7
,SUM(CASE TERM WHEN '10Y' THEN A16.INTEREST_RATE ELSE 0 END) AS Y10
,SUM(CASE TERM WHEN '15Y' THEN A16.INTEREST_RATE ELSE 0 END) AS Y15
FROM FACT_FTP260_BSC_A16 A16
GROUP BY
A16.INTEREST_RATE_CD
4 分析函数
可用于排名(1:值相同 排名相同 序号跳跃;2.值相同 排名相同 序号连续;3.序号连续,不管值是否相同)
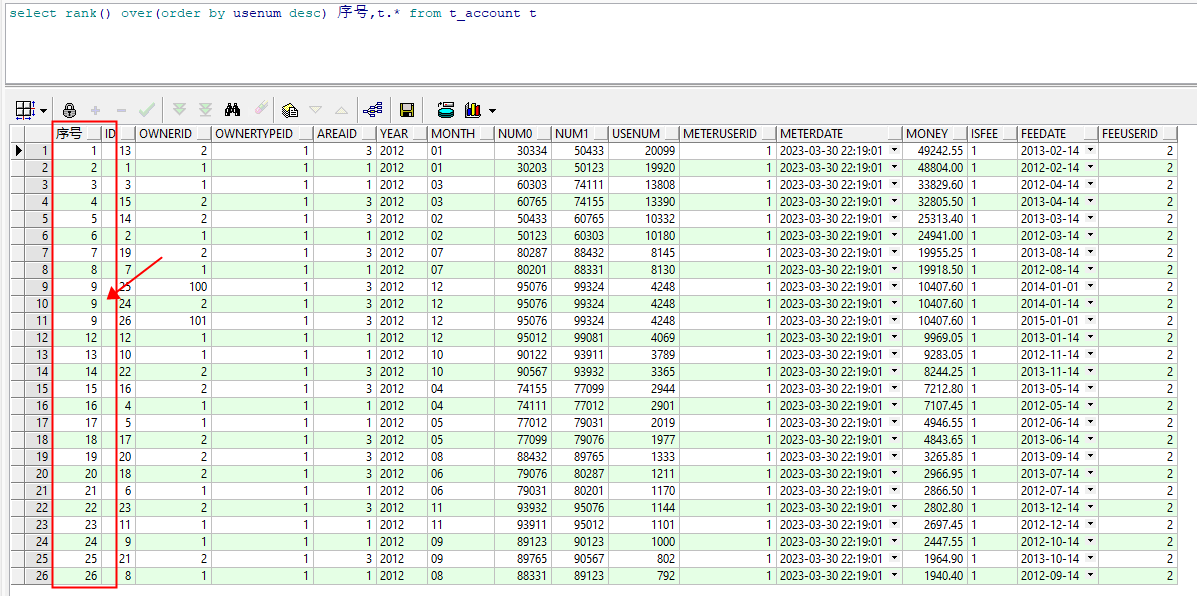
4.1 rank() 值相同 排名相同 序号跳跃
select rank() over(order by usenum desc) 序号,t.* from t_account t
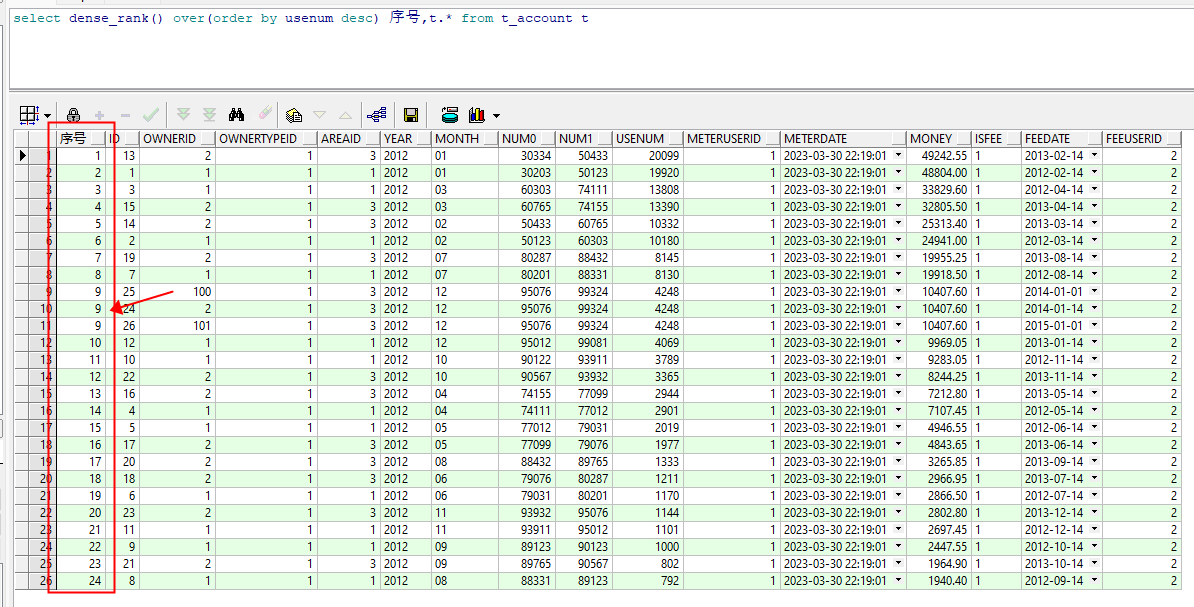
4.2 dense_rank() 值相同 排名相同 序号连续
select dense_rank() over(order by usenum desc) 序号,t.* from t_account t
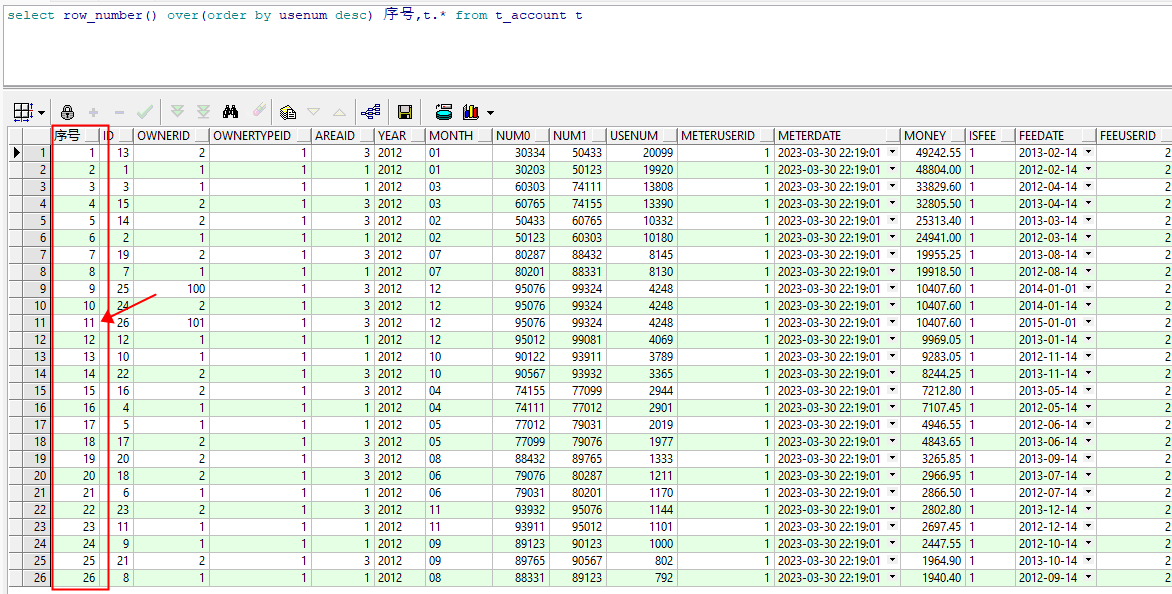
4.3 row_number() over() 序号连续,不管值是否相同
select row_number() over(order by usenum desc) 序号,t.* from t_account t
5、集合运算
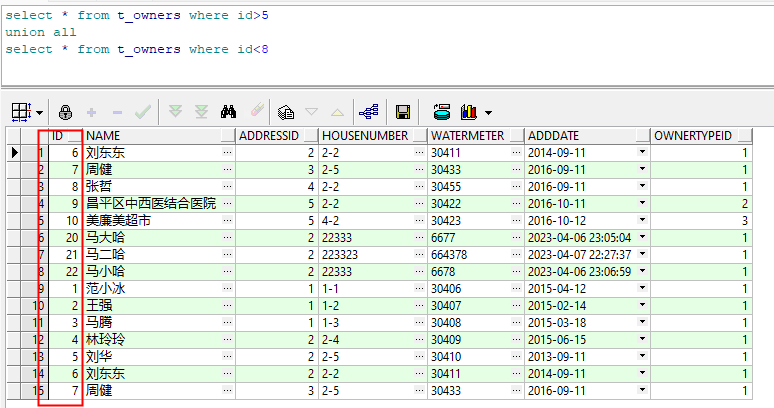
5.1 union all 并集(包括重复记录)
select * from t_owners where id>5
union all
select * from t_owners where id<8
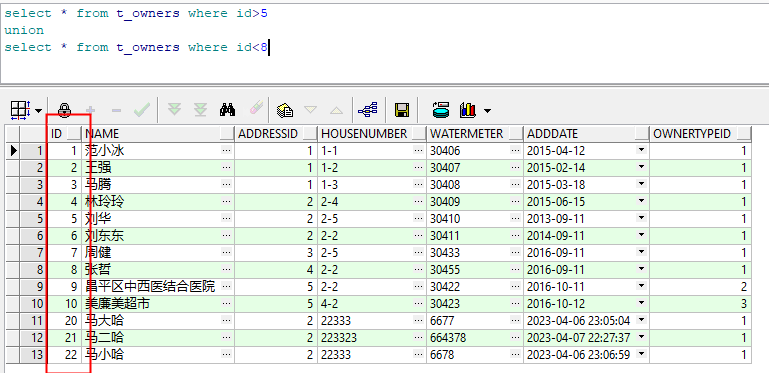
5.2 union 并集(不包括重复记录)
select * from t_owners where id>5
union
select * from t_owners where id<8
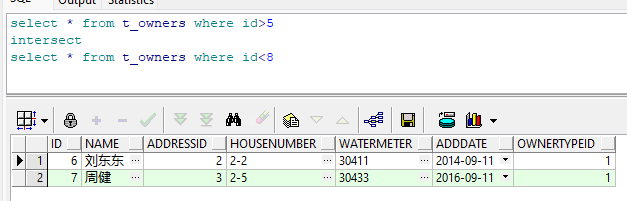
5.3 intersect 交集(两个集合的重复部分)
select * from t_owners where id>5
intersect
select * from t_owners where id<8
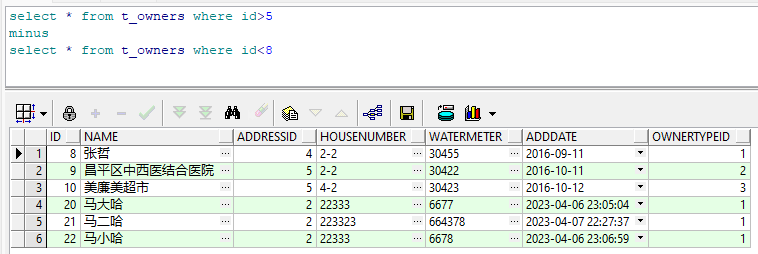
5.4 minus 差集
5.4.1 示例1
select * from t_owners where id>5
minus
select * from t_owners where id<8
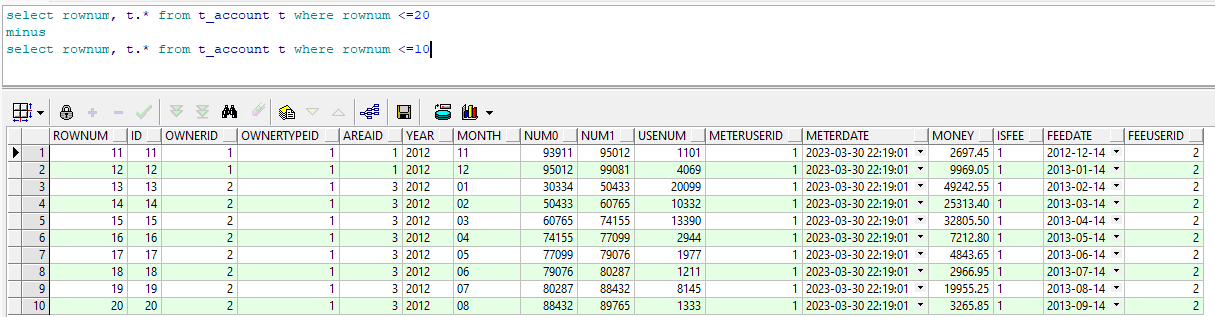
5.4.2 减运算分页
select rownum, t.* from t_account t where rownum <=20
minus
select rownum, t.* from t_account t where rownum <=10