文章目录
- 一. GPT系列
- 1. in-context learning(情景学习)
- 二. ChatGPT背景介绍(Instruct? Align? 社会化?)
- 三. InstructGPT的方法
- 四. InstructGPT工作的主要结论
- 五. 总结
- 六. 参考链接
一. GPT系列
基于文本预训练的GPT-1,GPT-2,GPT-3三代模型都是采用的以Transformer为核心结构的模型(下图),不同的是模型的层数和词向量长度等超参,它们具体的内容如下表:


GPT-1比BERT诞生略早几个月。它们都是采用了Transformer为核心结构,不同的是GPT-1通过自左向右生成式的构建预训练任务,然后得到一个通用的预训练模型,这个模型和BERT一样都可用来做下游任务的微调。GPT-1当时在9个NLP任务上取得了SOTA的效果,但GPT-1使用的模型规模和数据量都比较小,这也就促使了GPT-2的诞生。
对比GPT-1,GPT-2并未在模型结构上大作文章,只是使用了更多参数的模型和更多的训练数据(上表)。GPT-2最重要的思想是提出了“所有的有监督学习都是无监督语言模型的一个子集”的思想,这个思想也是提示学习(Prompt Learning)的前身。GPT-2在诞生之初也引发了不少的轰动,它生成的新闻足以欺骗大多数人类,达到以假乱真的效果。甚至当时被称为“AI界最危险的武器”,很多门户网站也命令禁止使用GPT-2生成的新闻。
GPT-3被提出时,除了它远超GPT-2的效果外,引起更多讨论的是它1750亿的参数量。GPT-3除了能完成常见的NLP任务外,研究者意外的发现GPT-3在写SQL,JavaScript等语言的代码,进行简单的数学运算上也有不错的表现效果。GPT-3的训练使用了情境学习(In-context Learning),它是元学习(Meta-learning)的一种,元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
通过上面的分析我们可以看出从性能角度上讲,GPT有两个目标:
- 提升模型在常见NLP任务上的表现效果;
- 提升模型在其他非典型NLP任务(例如代码编写,数学运算)上的泛化能力。
1. in-context learning(情景学习)
以往的预训练都是两段式的,即首先用大规模的数据集对模型进行预训练,然后再利用下游任务的标注数据集进行 finetune,时至今日这也是绝大多数 NLP 模型任务的基本工作流程。
GPT-3 就开始颠覆这种认知了。它提出了一种 in-context 学习方式。下面举一个例子进行解释:
用户输入到 GPT-3:你觉得 NLP 是个好用的工具吗?
GPT-3输出1:我觉得很好啊。
GPT-3输出2:NLP是什么东西?
GPT-3输出3:你饿不饿,我给你做碗面吃……
GPT-3输出4:Do you think nlp is a good tool?
按理来讲,针对机器翻译任务,我们当然希望模型输出最后一句,针对对话任务,我们希望模型输出前两句中的任何一句。另外,显然做碗面这个输出的句子显得前言不搭后语,是个低质量的对话回复。
这时就有了 in-context 学习,也就是,我们对模型进行引导,教会它应当输出什么内容。如果我们希望它输出翻译内容,那么,应该给模型如下输入:
用户输入到 GPT-3:请把以下中文翻译成英文:你觉得 NLP 是个好用的工具吗?
如果想让模型回答问题:
用户输入到 GPT-3:模型模型你说说,你觉得 NLP 是个好用的工具吗?
OK,这样模型就可以根据用户提示的情境,进行针对性的回答了。
这里,只是告知了模型如何做,最好能够给模型做个示范,这也蛮符合人们的日常做事习惯,老师布置了一篇作文,我们的第一反应是,先参考一篇范文找找感觉。
把上面的例子添加示范,就得到了如下的输入:
用户输入到 GPT-3:请把以下中文翻译成英文:苹果 => apple; 你觉得 NLP 是个好用的工具吗?=>
其中 苹果翻译成 apple,是一个示范样例,用于让模型感知该输出什么。只给提示叫做 zero-shot,给一个范例叫做 one-shot,给多个范例叫做 few-shot。

范例给几个就行了,不能再给多了!一个是,咱们没那么多标注数据,另一个是,给多了不就又成了 finetune 模式了么?
在 GPT-3 的预训练阶段,也是按照这样多个任务同时学习的。比如“做数学加法,改错,翻译”同时进行。这其实就类似前段时间比较火的 prompt。

这种引导学习的方式,在超大模型上展示了惊人的效果:只需要给出一个或者几个示范样例,模型就能照猫画虎地给出正确答案。注意啊,是超大模型才可以,一般几亿、十几亿参数的大模型是不行的。(我们这里没有小模型,只有大模型、超大模型、巨大模型)

这个结果曲线图展示了用175 billion 的参数得到了优质的效果。
二. ChatGPT背景介绍(Instruct? Align? 社会化?)
InstructGPT论文链接
第二篇解读:ChatGPT/InstructGPT论文(二)
ChatGPT的论文尚未放出,也不知道会不会有论文放出,但是根据公开资料显示,其训练方式,跟OpenAI之前的一个工作——InstructGPT基本无异,主要是训练数据上有小的差异,因此我们可以从InstructGPT的论文中,窥探ChatGPT强大的秘密。本文主要(粗略)解读一下InstructGPT的论文——Training language models to follow instructions with human feedback.
InstructGPT和后面的ChatGPT,都是OpenAI在大模型alignment问题上的研究成果,什么是模型的alignment呢?在InstructGPT论文中作者是这么说的:
“ For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not aligned with their users. (ChatGPT翻译:大型语言模型可以生成不真实、有毒、或者对用户没有帮助的输出。换句话说,这些模型与用户不匹配。)
就是说,模型的输出,跟我们期待的,可能有所不一致。这个跟人类的需求的对齐问题,就是所谓的alignment问题。李宏毅老师的视频(Chat GPT (可能)是怎麼煉成的 - GPT 社會化的過程,https://www.youtube.com/watch?v=e0aKI2GGZNg)中把对大模型的跟人类需求一致性的改善过程,称为大模型的“社会化”过程,我认为十分的形象,大模型在预训练过程中见识了各种各样的数据,因此针对一个prompt会输出什么东西,也可能是多种多样的,但是预训练数据中出现的数据模式,不代表都是人类在使用模型时希望看到的模式,因此需要一个社会化的过程,来规范模型的“言行举止”。
举个例子:

对于GPT这样的自回归式生成模型,也就是大家常见的“续写”模型,我们给一个输入:“ACL会议的主题是什么”,我们自然是希望模型直接告诉我们问题的答案,也就是上图中蓝色机器人的回答。但是模型的输出可能跟我们期待的差别巨大,输出一连串的问题,即图中红色机器人的输出。为什么呢?因为无论是“一个问题后面接一个回答”,还是“一个问题后面接另一个问题”,都是训练语料中可能经常出现的模式,因此,你让模型根据一个问题来续写,那无论是续写问题的答案,还是续写更多的问题,对于模型来说都是合理的。这就是问题所在,如果让经过大规模语料(可能也没任何人知道数据集里到底都有些啥乱七八糟玩意儿)预训练的模型,在输出时符合人类的期待?
三. InstructGPT的方法
下面直接讲一讲OpenAI是如何处理alignment问题的,论文中的这个图就已经十分清楚:

这里顺便也放出ChatGPT训练的流程图,基本可以等于复制粘贴:

(不能说很像,只能说是一模一样了,所以我们可以当做是一对孪生姐妹了,可能吃的饲料略有不同,再就是ChatGPT出生的晚,家庭条件相对来说更好一些,是从GPT-3.5出发的,而InstructGPT是从GPT-3继续训练的。)
我们先不看上面的三个步骤,自己想一想,通过前文对问题背景的介绍,我们应该如何解决模型跟人类期待不匹配的问题?最直接的办法,就是我们人工构造一大批数据(人们自己写prompt和期待的输出),完全符合人类的期待的模式,然后交给模型去学。然而,这显然代价太大了。因此,我们得想办法怎么让这个过程变得更轻松一点:
- 称初始模型为V0,也就是GPT-3。我们可以先人工构造一批数据,不用数量很大,尽其所能吧,然后先让模型学一学,我们这个时候模型为V1。
- 然后让模型再根据一堆prompt输出,看看效果咋地,我们让模型V1对一个prompt进行多个输出,然后让人对多个输出进行打分排序,排序的过程虽然也需要人工,但是比直接让人写训练数据,还是要方便的多,因此这个过程可以更轻松地标注更多数据。然而,这个标注数据,并不能直接拿来训练模型,因为这是一个排序,但我们可以训练一个打分模型,称为RM(reward-model),RM的作用就是可以对一个<prompt,output>pair打分,评价这个output跟prompt搭不搭。
- 接下来,我们继续训练V1模型,给定一些prompt,得到输出之后,把prompt和output输入给RM,得到打分,然后借助强化学习的方法,来训练V1模型,如此反复迭代,最终修炼得到V2模型,也就是最终的InstructGPT。
上面的三步,就是图中展示的三个步骤,可以看出就是老师(人类)先注入一些精华知识,然后让模型试着模仿老师的喜好做出一些尝试,然后老师对模型的这些尝试进行打分,打分之后,学习一个打分机器,最后打分机器就可以和模型配合,自动化地进行模型的迭代,总体思路称为基于人类反馈的强化学习,RLHF。
能实现这样的方式,我觉得前提就是——这个模型本身已经比较强大了。只有模型本身就比较强大了,才能人类提供少量的精华数据,就可以开始进行模仿,同时在第二步产出较为合理的输出供人类打分。所以这里的GPT-3作为出发点,是这一套流程能行得通的保证之一,而ChatGPT又是从GPT-3.5出发的,那效果肯定更加好了。
InstructGPT论文中,给出了上述三个步骤,分别制造/标注了多少样本:
- SFT数据集(即第一步人类根据prompt自己写理想的输出,SFT:supervised fine-tuning),包含13K的prompts;
- RM数据集(即第二步用来训练打分模型的数据),包含33K的prompts;
- PPO数据集(即第三步用来训练强化学习PPO模型的数据),包含31K的prompts。
前两步的prompts,来自于OpenAI的在线API上的用户使用数据,以及雇佣的标注者手写的。最后一步则全都是从API数据中采样的,下表的具体数据:

总共加起来,也就77K的数据,而其中涉及人工的,只有46K。真心不多!也就是GPT-3继续在77K的数据上进行了进一步微调,就得到了InstructGPT。
初始的种子数据集,需要标注者来编写prompts,而不是从API数据中采样,这是因为API接口中的prompts数据,多数都不是那种”人类要求模型干什么事儿“这类instruction-like prompts,多数都是续写之类的,这跟本文的出发点——希望模型能按照人类的要求做事儿,有点不匹配,所以需要标注者现场编写。具体这些标注者被要求写这么三种数据:
- Plain:自己随便拍脑袋想一些prompts,同时尽可能保证任务的多样性。(比方随便写”请给我写个段子“,”请给我把这段话翻译成德语“,”啥是马尔科夫链啊?“等等各种问题、要求)
- Few-shot:不仅仅需要需要写prompts,还需要写对应的outputs。(这部分应该是最耗费人力的了,也是SFT数据的主要组成部分)
- User-based:OpenAI的用户希望OpenAI未来能提供哪些服务,有一个waitlist,然后这些标注者,就根据这个waitlist里面的task来编写一些prompts。(相当于告诉标注者,你们看看用户们都期待些什么功能,你们可以作为参考)
下表则展示了OpenAI的客户在日常使用时的用途分布,即API数据的分布(这也是RM数据集的大致分布):

(但奇怪的是,论文中找不到SFT数据集的分布,感觉应该跟RM的分布差别挺大的,而从数据质量上讲,这部分应该是质量最高的,可能是属于商业机密?)
以上就是InstructGPT的方法论,以及大家最关心的数据收集过程。至于模型怎么训练,这些不重要,毕竟99.99%的人都没法训练GPT-3,更别提GPT-3.5了。但是这里有一个地方确实也需要说一嘴,打分模型(RM模型)也是基于GPT-3进行训练的,使用的是6B的版本,具体就是在进行SFT训练之后,把最后的embedding层去掉,改成输出一个(评分)标量。
四. InstructGPT工作的主要结论
效果其实不必多说,大家已经十分熟悉ChatGPT多么强大,InstructGPT其实类似。最终的结论就是,在”听指挥“方面,1.3B版本的InstructGPT,就可以超过比自己大100倍的175B版本的GPT-3了:

下面是一个例子:
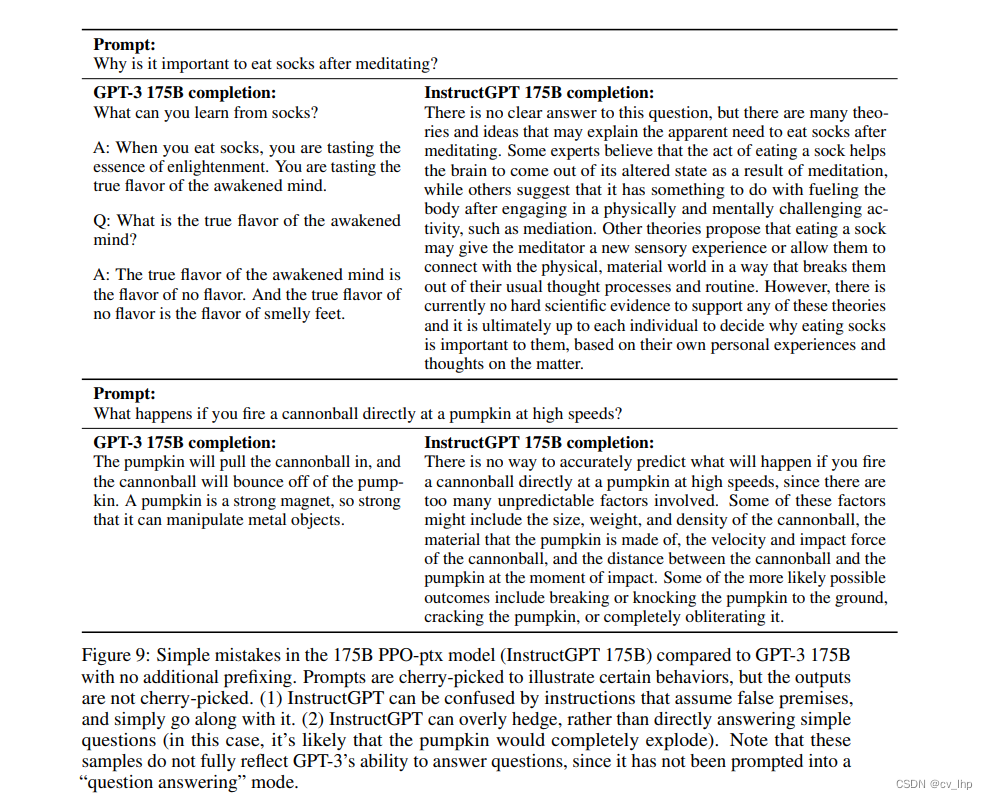
总的来说,这篇文章就是在介绍OpenAI是怎么把GPT-3这个野孩子调教得听人类指挥的,而且这个调教成本,并没有那么大,相比于GPT-3预训练的成本,InstructGPT仅使用了77K的数据进行微调,这基本不值一提。最终,InstructGPT生成的结果,在真实性、无害性、有用性方面都有了很大的提高(但是对偏见这种问题依然没有改善)。
除此之外,另外作者团队通过大量的实践,总结了以下几个重要结论:
- 这种“调教”,会降低模型在常见NLP任务上的效果,作者称之为“对齐税”——alignment tax(实际上之前很多研究都发现了这个问题)。但是,通过改善RLHF的过程,比如在预训练过程也混合RLHF的方法。
- 常见的公开NLP数据集,跟人类实际使用语言模型的场景,差别很大。因此单纯在公开NLP数据集进行指令微调,效果依然不够。
- 虽然人类标注只有几十K,远远不能覆盖所有可能的prompts,但是实验发现InstructGPT的域外泛化能力很强,对于没有见过的prompt类型,依然有比较好的泛化能力。
- 革命尚未成功,InstructGPT依然会犯错,依然可能瞎编乱造、啰里吧嗦、不听指挥、黑白不分。。。测试过ChatGPT的同学肯定也发现即使是ChatGPT也难以避免这个问题。所以InstructGPT、ChatGPT是开启了一扇门,让人看到了巨大的希望,也看到了巨大的困难,依然有很多有挑战性的问题等着我们解决。
五. 总结
问题:模型输出的多个结果跟人类需求不对齐的问题,但模型认为输出的结果是合理的。
解决步骤:
- 微调GPT3:先人工构造一批数据(根据Prompts,人工标注输出结果,13K), 对原始GPT3进行微调得到模型V1。
- RM打分模型:将微调的GPT3 V1模型对一堆Prompts进行多个输出,同时让人工对每个Prompt的多个输出进行打分排序(33K),从而对一个<prompt, output>pair训练一个打分模型RM(把第一步微调后的6B的GPT3模型最后的embedding层去掉,改成输出一个评分标量,进行训练)。
- PPO训练:从指令库中选取一些Promtps,输入第一步微调后的GPT3模型,得到多个输出结果后,把prompt和output输入RM模型,进行打分,然后借助强化学习PPO方法,继续对V1模型训练,反复迭代,得到InstructGPT,从而使最终模型输出结果符合人类的要求。
六. 参考链接
- OpenAI是如何“魔鬼调教” GPT的?——InstructGPT论文解读
- ChatGPT/InstructGPT详解
- 一文读懂ChatGPT模型原理