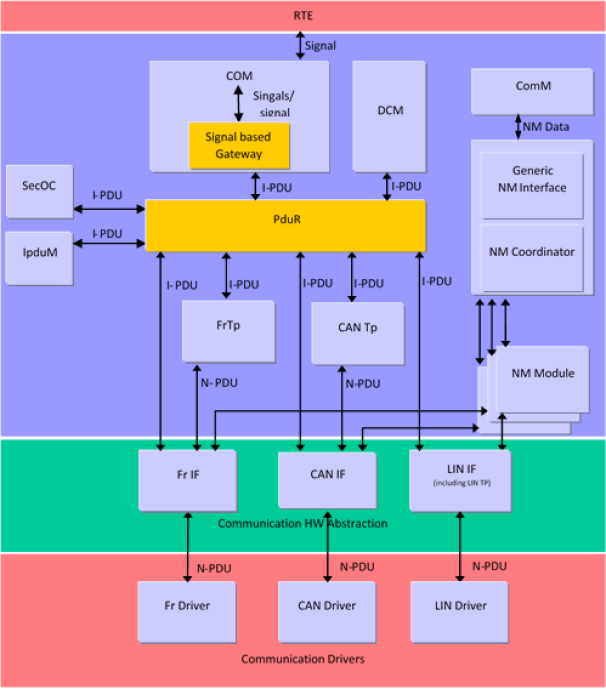
观测到一个有意思的现象:
假设把安全划分为 基础安全 和 业务安全,PR类的议题中,会出现分级:基础安全领域,喜欢讲纵深防御,给出一个炫酷的架构图,然后各种技术关键字往上标;业务安全领域,喜欢讲算法,给出各类数据源,然后把各种算法模型往上标。
这里面当然有很多原因,比如:搞基础安全的人通常是攻防出身,不擅长算法;业务安全的技术层面不深,所以出彩需要靠算法;等等等。
但本次的主题,尝试从安全和算法的角度来展开,为什么基础安全和算法的结合,是一件相对困难的事情。以及个人最近在尝试研究的一些解决方向和思路。
1. 安全运营场景下的算法难题
基础安全是个重运营的工作,不论技术多么炫酷,最终想要拿到结果,都必须落到运营头上。
不论部署了多少安全产品,收集了多少数据,维护了多么精密的规则,最终产出的告警仍然是以误报为主。本质原因在于,基础安全是和人在对抗,在行为特征上,存在极大的变数。正常员工可能某天心血来潮,就登录上一台新的机器,执行某个危险命令。(与之相对的,业务安全通常是和机器在对抗,各种脚本、模拟器环境。虽然代码是人写的,但业务见到的批量请求,还是机器发出的。)这个时候,就需要安全专家对告警事件的上下文进行收集和研判,依靠过往经验判断是否为一起真实入侵。
这个运营过程,可以被算法替代嘛?当然是可以的。但会带来另一个更哲学的问题,算法出现了误判,到底是谁的责任。这个问题代入到医学或自动驾驶领域会更好理解。假设“医院”引入了某“公司”开发的算法,对“医生”的病人执行了错误的治疗方案,导致病人死亡(哪怕本来就没有多大的几率救活),这个时候,应当谁去承担责任呢?
- 从医院的视角,算法的引入经过了严格测试,准确率达到99.999999%,超过了医生的判断水平,算法代替医生能够在全局样本下取得更好的治疗结果,应用算法看起来是个合理决策。
- 从公司的视角,已经把算法的准确率优化到99.999999%了,你总不能要求算法的准确率达到100%,所以算法工程师已经尽职尽责了。
- 从医生的视角,算法决策的过程,医生全程没有参与,自然轮不到医生去背什么锅。
病人死亡这个结果,一定是需要有人来承担责任的。但从各方视角来看,似乎谁都没错,那就只能怪病人自己倒霉了呗。
补充说明一下,这里的承担责任,未必是要惩罚,重点在于归因。

在我看来,这个责任关系的定义,是目前算法在医学、自动驾驶、安全等领域下,无法起到革命性作用的最根本原因。区别于常规领域(推荐、搜索、翻译等),少量的错误是可以被接受的,因此算法追求准召率的最大化即可。但在特殊领域,个例的频次较低,后果却极其严重。这个时候,概率是没有意义的,真正需要的是明确的责任归属。
那为什么规则在特殊领域是可以被大规模使用的呢?这就是规则和算法的最大区别,算法是黑盒的。对于规则来说,其实同样不存在准召的概念,只要输入明确,输出就一定符合规则逻辑,相互对应。因此,规则的判断逻辑,是可以被明确责任和归因的。是因为写规则的人疏忽大意,还是专家没有仔细review,还是系统BUG,等等。
因此,只有可以明确归属责任的系统,才是值得信赖的。而当前的算法,因为其黑盒性,所以不值得被信赖。

除此之外,规则和算法在特殊领域的应用,还有理性和感性的抉择问题。例如,在《我,机器人》中,主角和他儿子同时落水,机器人判定主角存活的概率大于儿子,所以救了主角。而人性上来说,救儿子更符合人类情感。这个话题跟本篇关系不大,暂时不展开讨论。
2. 安全运营场景下的算法应用思路
虽然说了这么多算法的不好,但从另一个方面来说,算法替代人类的需求是十分旺盛的。自动驾驶和自动医疗,仍然是大家日思夜想的场景。释放精力、提升效率,对于人类发展来说,无疑能起到至关重要的作用。
因此,我们仍然需要探索算法的应用方式。
1940年,科幻作家阿西莫夫提出了机器人三原则。虽然其完备性饱受争议和挑战,但确实是算法应用的基本条件:必须给算法设定明确的限制。
第一条:机器人不得伤害人类,或看到人类受到伤害而袖手旁观.
第二条:机器人必须服从人类的命令,除非这条命令与第一条相矛盾。
第三条:机器人必须保护自己,除非这种保护与以上两条相矛盾。
个人认为,安全领域(或者其他特殊领域),算法应用必须符合以下几个原则:
2.1 可以被手动调整
业内通常会讨论可解释性,但在我看来,算法仅仅是可解释是不够的,它要能够支持手动的调整优化。
在这一点上,ChatGPT是个比较有意思的中间态,因此借其说明一下这个原则。
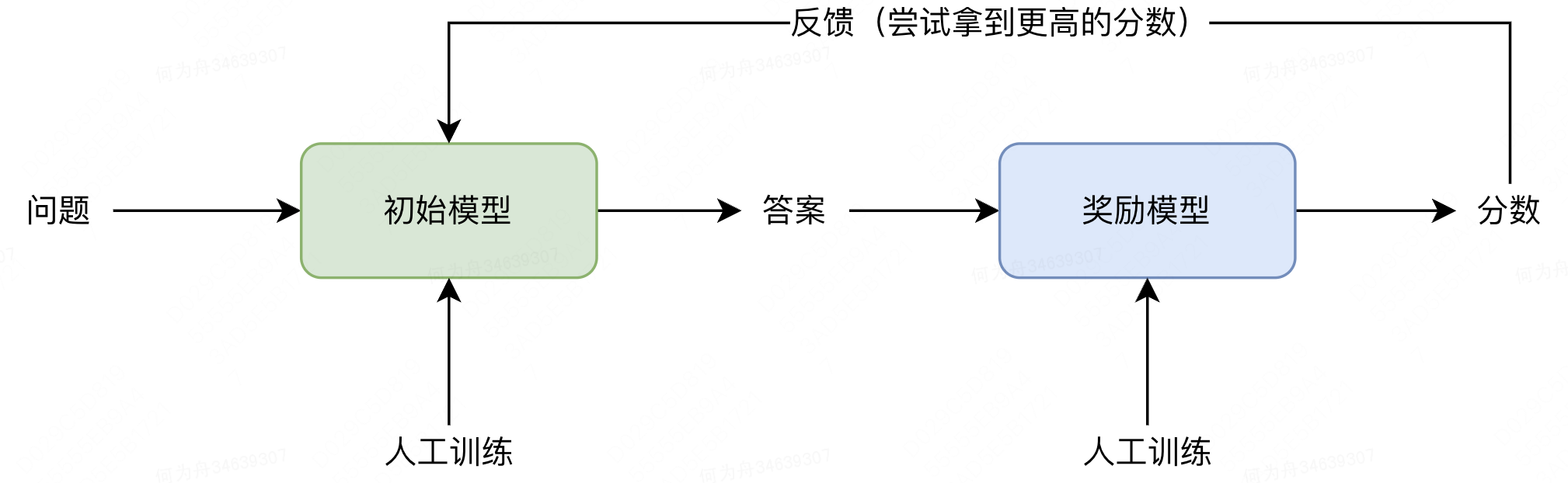
我们都知道,ChatGPT可能会生成相当危险的答案,比如教唆犯罪、种族歧视、网络攻击等。那么OpenAI是怎么去优化这个问题的呢?在GPT-4的文档中,明确说明了,OpenAI会训练安全相关的奖励模型,从而避免模型输出有害的内容。
GPT-4 incorporates an additional safety reward signal during RLHF training to reduce harmful outputs (as defined by our usage guidelines) by training the model to refuse requests for such content. The reward is provided by a GPT-4 zero-shot classifier judging safety boundaries and completion style on safety-related prompts. To prevent the model from refusing valid requests, we collect a diverse dataset from various sources (e.g., labeled production data, human red-teaming, model-generated prompts) and apply the safety reward signal (with a positive or negative value) on both allowed and disallowed categories.
从这个优化模式,可以探讨几个问题:
1)为什么不直接优化初始模型:一方面算法黑盒程度较高,另一方面大模型时代,每一次训练都是需要投入较大成本的。
2)奖励模型是如何生成的:原文中提到了一个zero-shot classifier。大体逻辑是GPT已经学习完了文本特征,然后再基于这个特征,去拼接一个单独的分类模型。最后将两者的特征向量相匹配,就能够利用GPT对语言的理解,去快速判断一个输出是否是安全的。(大模型下的文本分类,通常都会使用这个方法。)
3)这个模式的安全性如何:我评价它是大模型场景中,一个比较高效的解决方案,但黑盒属性仍然很重。因为还是不确定模型到底是如何理解和运算语言特征的,没办法针对性的去让模型按希望的方向调整,可控的只是训练集的分布而已。
综上,ChatGPT通过奖励模式,实现了一定程度上的“可调整性”。但这个调整过程,仍然是黑盒的,只能通过调整训练集、调整模型参数等,去观测最终结果。 因此,并不符合我心目中的“可以被手动调整”。
与之相对的,大部分基础的机器学习模型,贝叶斯、逻辑回归、决策树等,其特征和权重都是很简单明了的。通过分析特征权重、参数分布等,能够知道模型为啥会产生误判。(比如决策树没有把你心目中的特征作为第一层分类特征,那你可以去回溯这个特征在样本空间中的分布,看是否对于分类结果有强相关性。)
2.2 不参与最终决策
在算法责任边界不明晰的情况下,human in the loop显然是当前阶段最适用的应用模式。在安全领域下,我认为需要更加强调由人做出最终决策。
可以从自动驾驶领域来进行类比。通常业界将自动驾驶分为5个等级,并认为当前处于L2技术相对成熟的阶段。
L1级,辅助驾驶。代表性功能如自适应巡航、车道保持辅助、制动刹车等。
L2级,部分自动化。代表性功能如全速自适应巡航、自动泊车、主动车道保持、自动变道、限速识别等。
L3级,条件自动化。能应付大部分路面情况,但驾驶员依然得始终保持注意力,在出现紧急情况时需要随时接管车辆。
L4级,高度自动化。在部分场景下(如城市道路、高速路)车辆几乎可以完成所有的操作,驾驶员变成了辅助。
L5级,完全自动化。无需驾驶员,完全自动化,适用于任何场景。
尽管汽车的自动驾驶迭代时间较短,航天领域的自动驾驶确是上个世纪就已经出现了。航天操作虽然复杂,但胜在容许的反应时间相对宽裕,所以门槛略低一些。但即便如此,经验丰富的驾驶员,仍然是给人们带来安全感最主要的因素,算法的瓶颈可见一斑。
因此,安全领域下,尤其是基础安全领域,经验丰富的专家决策,仍然是不可缺失的一环。
3. 安全运营场景下的算法应用示例
一不小心写了太多理论,下面结合具体算法,分享一下个人的部分思路。
结合上面提到的原则:1)算法需要具备可控性;2)算法需要参与最终决策。将算法在安全运营场景(或者应该更明确定义为告警运营)下的应用目标,定义为:提升运营人员决策的效率。
3.1 告警运营模式分析
我一直认为,算法的本质是,是对人类思维的具象化实现。因此,先来分析一下一起入侵事件是如何被告警并运营出来的。
首先,一次入侵事件是由一系列的异常动作构成的完整路径。参照ATT&CK的模版,效果大致如下:
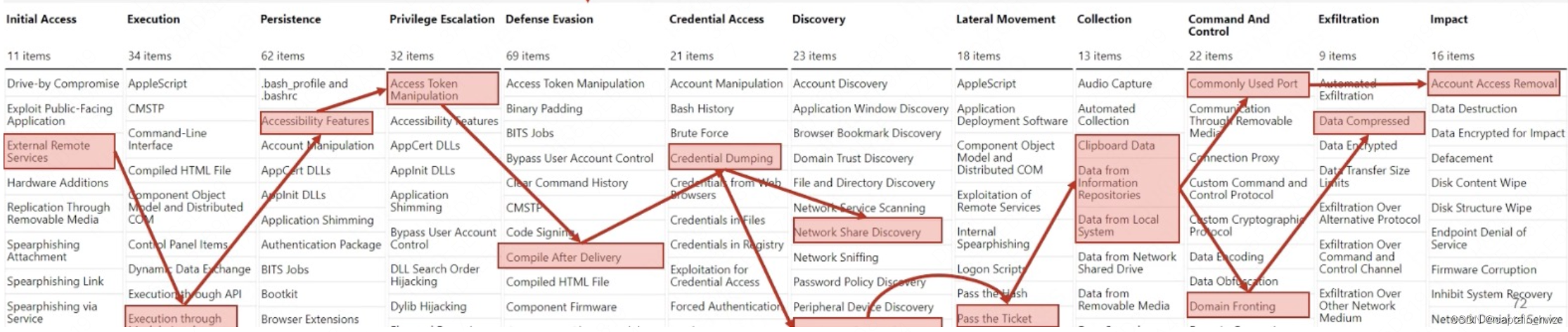
告警运营的过程大致如下:
1)某几个异常动作触发了告警。如异常派生的进程。
2)运营人员关注到告警后,对动作的威胁等级进行判定。如派生的进程是否是恶意的探测、种马等。
3)如果存在潜在威胁,则关联找到找到其他动作,形成事件路径图。如exp的发送方,是否存在下一跳等。
4)通过事件的源头、动机、最终影响等,判断是一次真实入侵还是业务自身的操作。如是由业务人员发起,最终运行了一个开源java组件,那通常是业务自身的操作。
整个过程和相关的技术,可以通过下面这个模式进行抽象:

其中,前两个环节依赖的是对各类数据的收集处理能力和对攻击手法的理解程度,从而制定出相应的规则和检测算法。不属于本篇关注内容,暂不展开。
到了最后这个环节,通常开始交由运营人员开始进行分析和研判。比如判断是否是SQL注入,可能会去看被规则检测出来的异常语句,是否有恶意操作(如条件查询中,是否包含类似“or 1=1”拖取整张表的语义);判断RCE派生进程,可能会去看进程是否在尝试收集信息、提权、横移等;判断某个文件下载是否恶意,可能会去看看目标网站是否正常等。
这个过程往往相对直接,但又极度依赖经验。大体可以抽象成一个比较经典的文本分类场景,输入是各种事件相关数据,输出是是否异常。
3.2 传统机器学习算法
回顾一下目标,提升运营人员决策的效率。遇到的问题则是,基于告警数据的文本分类。所以,算法需要提供的能力是,帮助运营人员更高效的分类。
而运营人员分类的依据大致有两个:1)是否存在能够实锤正常或者异常的关键词;2)同类型的事件历史是否发生过。而文本分类算法基本也是基于这个逻辑去实现的(算法就是人类思维的具体实现),所以直接套用即可。不同的是,我们需要更加关注过程,把算法的分类依据提取出来,而结果是否准确,则相对不重要。
下面以经典贝叶斯算法展开如何实现这个过程:
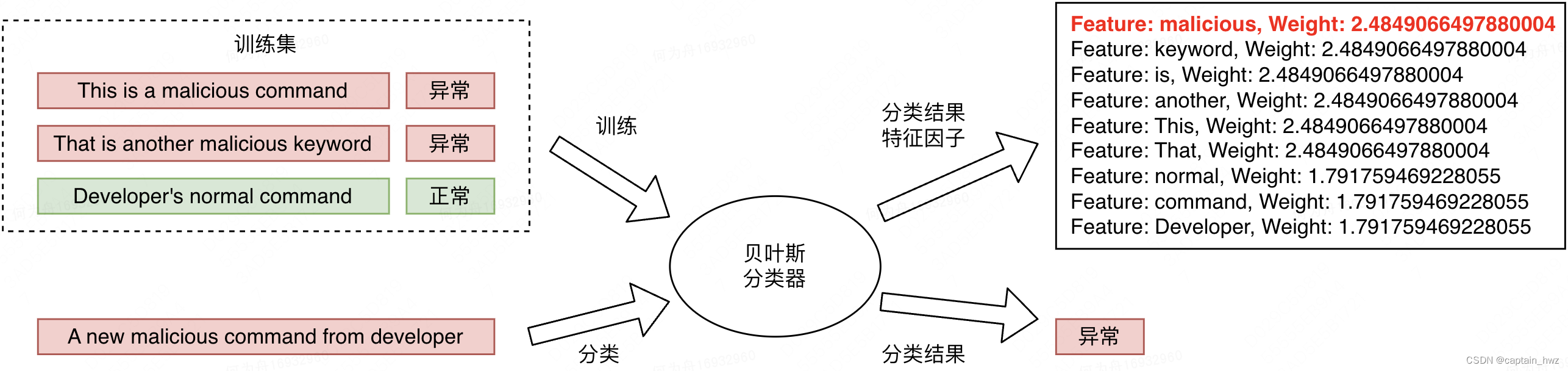
在训练集的样本分布中,malicious、keyword是只在异常样本中出现的词,在贝叶斯分类方式中,会成为贡献最大的概率特征。
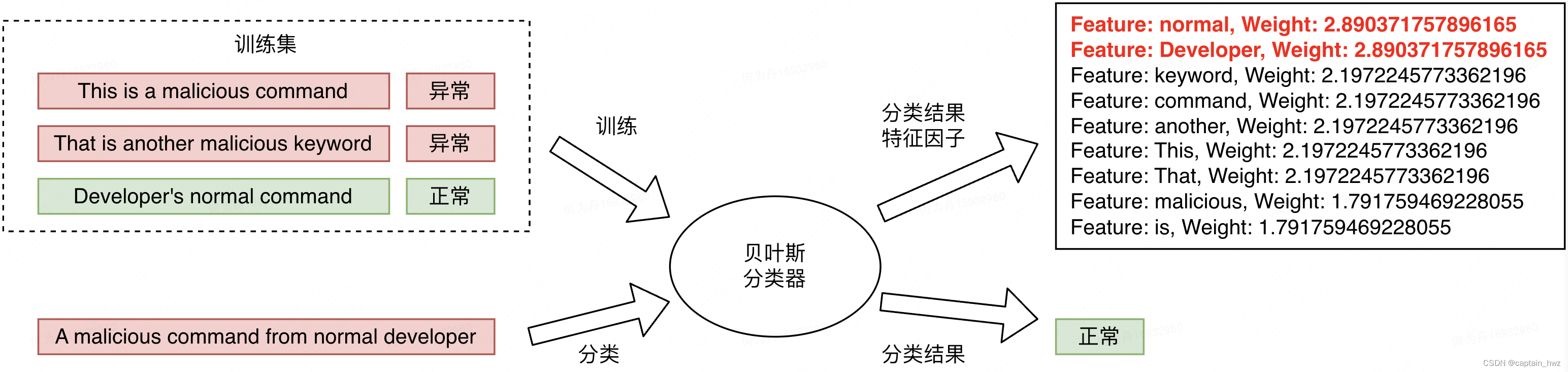 假设在另外一个告警中,出现了一些正向特征,使得模型分类错误。但在输出的特征因子排序中,能够表明模型是基于哪些特征判定的正常。对于运营人员来说,仍然是一个有增益的信息。
假设在另外一个告警中,出现了一些正向特征,使得模型分类错误。但在输出的特征因子排序中,能够表明模型是基于哪些特征判定的正常。对于运营人员来说,仍然是一个有增益的信息。
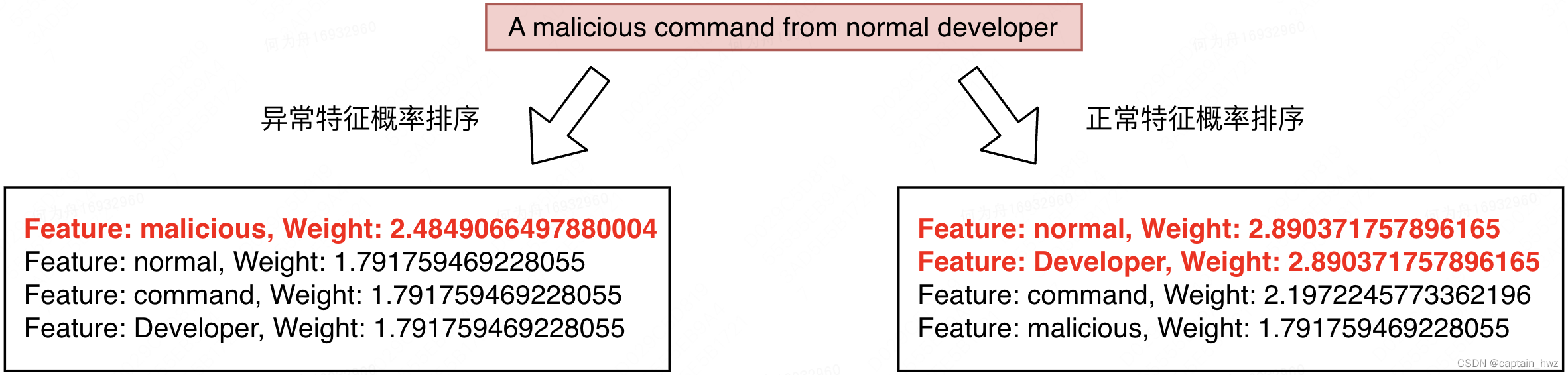
事实上,不论预测结果如何。上述两个特征因子的排序结果,都是可以被呈现出来的。在和预测样本中实际出现的特征做交集之后,能够呈现出,当前样本有哪些特征可以支撑该样本为异常,哪些为正常。大抵效果如下:
3.3 大语言模型
基于贝叶斯的实现,大部分情况下还是好用的。但会有几个问题:
1)无法提取多特征之间的关联性特征:大部分传统机器学习都会默认特征之间相互独立。如果存在关联关系,则需要通过特征空间转化(如PCA),把关联关系去除,才能够达到理想的效果。但特征空间转化,会消除可解释性,因此不能直接使用。
2)对于没见过的特征无法处理:传统机器学习依赖人工进行特征工程,它本身不理解特征具体是什么含义,只是一个符号而已。所以,当一个新的特征出现的时候(比如某个新的Bash命令),是无法进行处理的,只能忽略掉。
这个时候,在传统机器学习领域下,需要进行精巧的特征工程优化和样本选取,来提升模型的效果。但是大模型是可以通过大量的样本去学习这部分信息的,因此,也可以尝试引入大语言模型来解决这个问题。
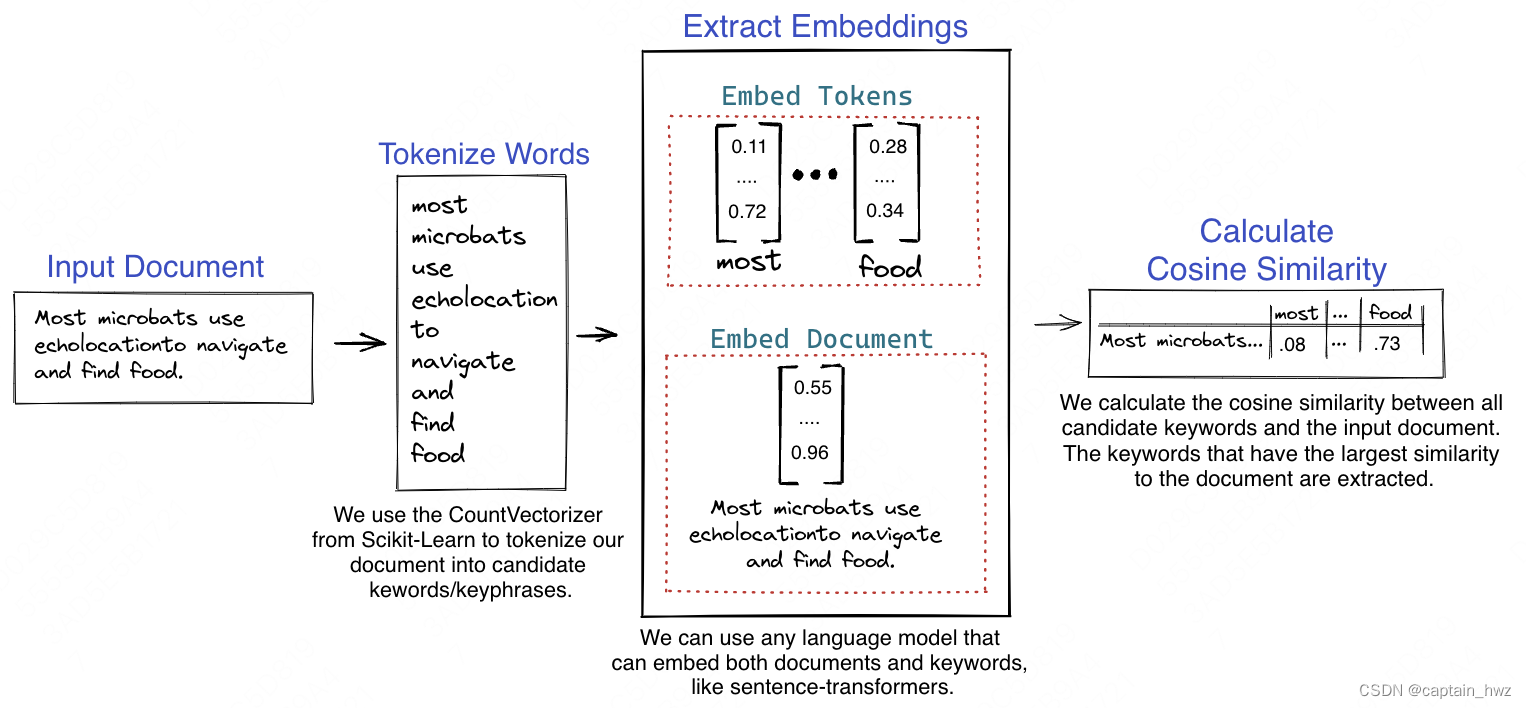
大语言模型提取关键词已经是一个有比较多研究的场景了,比较成熟的KeyBERT。大致原理是,认为关键词的embedding和整个文本的embedding在分布上应该比较相近,直接计算余弦相似度取最大值即可。
但在告警运营场景上,其实不希望是纯粹无监督模式的关键词提取,而是针对分类任务产出的关键词,这样才能给出倾向性建议。因此,应用上会更复杂一些。
大体会分为几个步骤:1)对训练好的大语言模型进行Fine-Tuning,让它学会告警分类;2)提取其中的embedding或者attention层;3)假定结果为异常或正常,分别做对应关键词提取。
这块暂时还只是设想,没有深入研究。本章篇幅也比较多了。因此,计划下篇再做展开。
4. 总结
本篇主要对安全和算法的定位做了展开讨论,废话也比较多。。。
总结来说,个人认为,在基础安全这类“后果严重”的领域,目前是不具备交由算法来完成决策的。与之相对的,业务安全领域下,追求的是对抗平衡,算法是可以发挥较大作用的。
举个例子,“10次入侵漏过了1次”和“100万资损降低到了50万”,前者会被认为是基础安全的失误,而后者会被认为是业务安全取得的收益。
但这也并不意味着算法在安全领域中无法使用(毕竟提效的需求是强烈的)。因此,本篇做了一些细分场景下的简单尝试,后续会进一步探索更多的场景和不同类型的算法应用(少废话,多实践)。




![[Date structure]时间/空间复杂度](https://img-blog.csdnimg.cn/9234b44878814ac3b295f50ef7a07024.png)