- 键值设计
- bigKey
- 例子
- 批处理
- 单机 pipeline
- 集群
- 服务器
- 持久化
- 慢查询
- 安全
- 内存
- 集群问题
- 集群完整性
- 集群带宽
- 数据倾斜
- 客户端性能
- 命令的集群兼容性
- lua和事务:集群下不支持
键值设计
- 长度 <= 44
节省内存。string的底层数据结构中,编码格式embstr(连续空间存储),如果大于,则是非连续空间 - 不包含特殊字符
- 基本格式:[业务名称]:[数据名称]:id。
可读性强,避免重复,便于管理
bigKey
要求
- 集合key元素数量<1000
- 单个key的value<10KB
问题
- 网络阻塞:因单个key太大,少量QPS,使得带宽堵塞,其他请求无法处理
- 数据倾斜:对key散列到各个插槽,bigkey所在的机器内存使用率大于其他机器。需要手动重新分配插槽
- redis阻塞:运算耗时,阻塞主线程
- cpu压力:key序列化和反序列化耗cpu
扫描
- redis-cli --bigkeys 扫描全部key。阻塞主线程
- scan,通过游标,部分迭代,扫描全部key
处理
- unlink 异步删除
- 遍历bigkey的所有元素,逐个删除,最后删除bigkey
例子


拆分成多个小的hash每个hash一部分数据
eg:原数据1-100万
现:拆为100各hash 每个1万条数据,每个之前加不同前缀
one:somekey-{field-value}
two:somekey-{field-value}
…
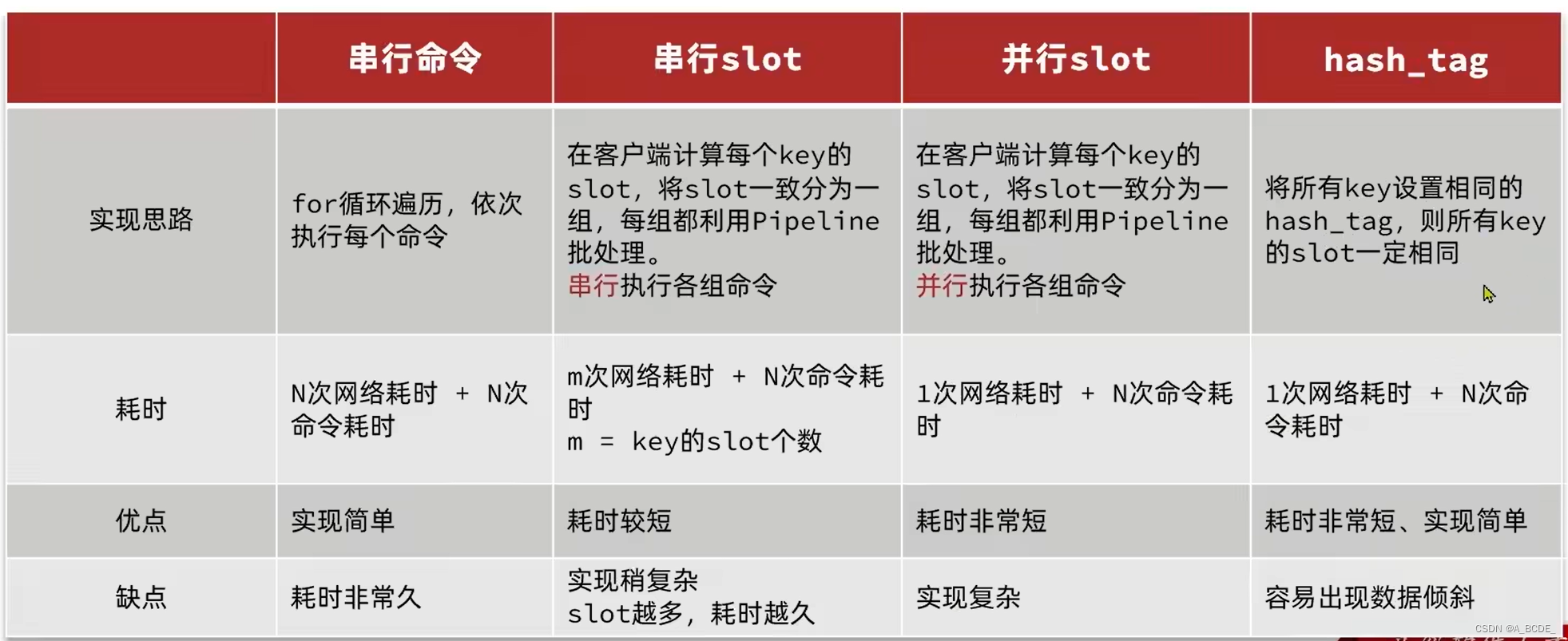
批处理
单机 pipeline
- mxxx一次处理多个命令(不要过大,否则可能导致网络堵塞),节省网络时间。eg:mset。
- redis内置操作,更快,将一组命令做成原子性的
- 只能处理部分数据类型
- pipeline 各种数据类型都可以
- 批处理的多个key必须落在一个插槽里。不同插槽在一个连接中无法完成
集群
服务器
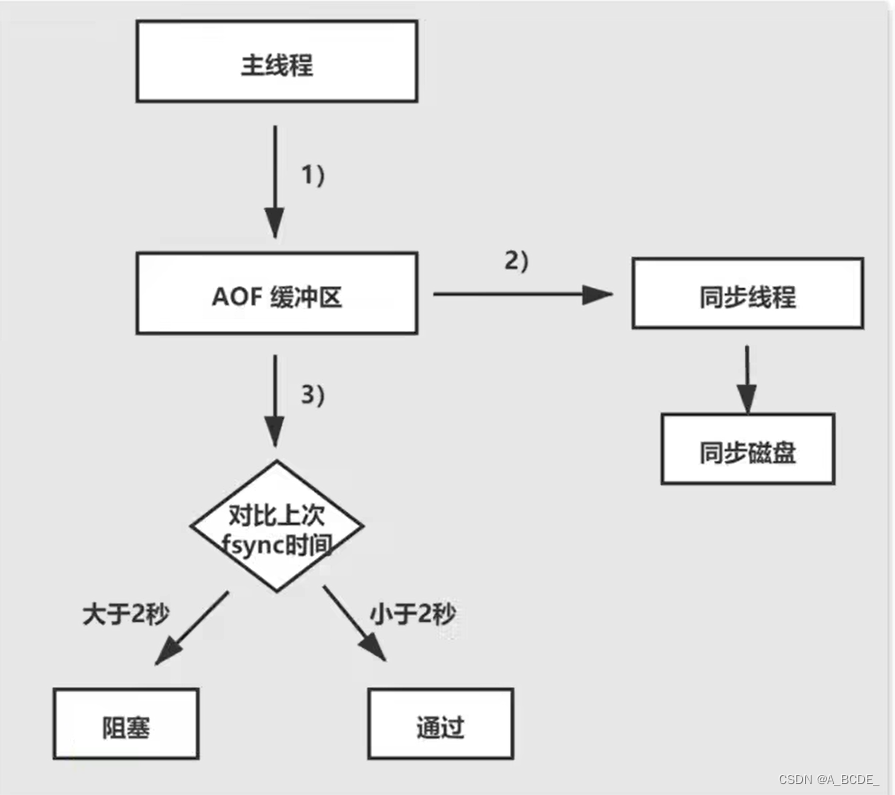
持久化
- redis做缓存尽可能不开启持久化,在做分布式锁等操作时使用
- 建议关闭RDB(丢数据),使用AOF。
RDB适合做数据备份,可手动处理
更改配置,避免AOF频繁rewrite,避免在rewrite中AOF。
主线程阻塞,等待AOF结束,但rewrite产生磁盘IO,AOF阻塞,则主线程长时间阻塞
- 部署

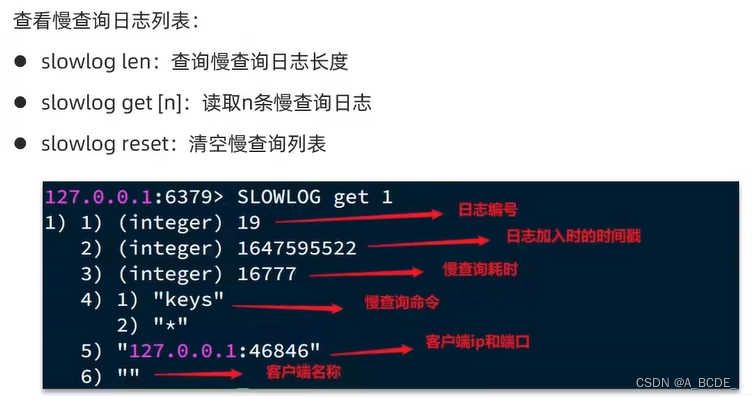
慢查询
- 设置阈值,超过阈值时间的都为慢查询
- 慢查询命令存储在slowlog中
安全

内存
内存不足 key频繁被删,qps不稳定,响应时间增长

info memory 查看内存情况
- 复制缓冲区:RDB时,有新的数据,放在此处。从节点和主节点的增量更新,在此处的offset比较
- AOF:AOF刷盘时的新命令
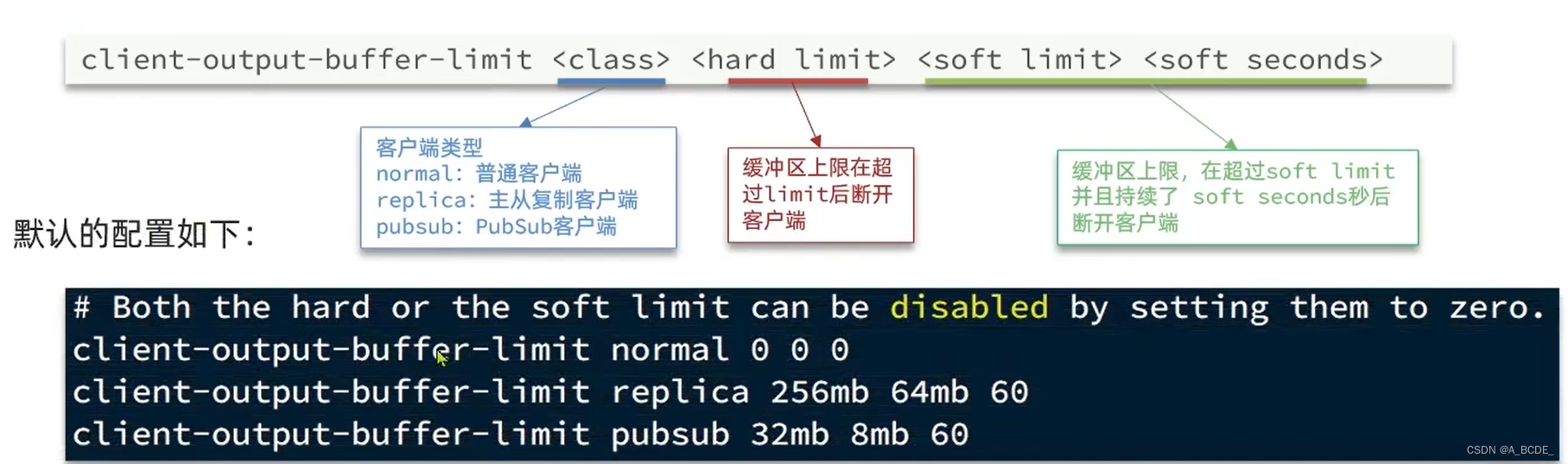
- 客户端缓冲区:redis连接的客户端,输入输出缓冲区
输入缓冲区:1G不可变,除非redis主进程堵塞,一般不会溢出
输出缓冲区:可设置。bigkey/带宽不够可能导致溢出,
集群问题
集群完整性
有个别插槽不可用则认为整个集群不可用
集群带宽
多个节点之间互相ping ,同时携带集群和插槽信息
如果节点过多,携带数据会很大,使用带宽变大,导致网络堵塞
- 避免集群过大 > 1000, 可以拆分为多个集群
- 不要在一个实例中运行多个redis
- 设置阈值,心跳检测超过时间认为节点下线,时间越大ping的次数越小,发现故障越完
数据倾斜
客户端性能
redis做集群,客户端需要选择节点
命令的集群兼容性
部分命令不支持集群,只能单机
集群需要使用代码完成,增加复杂度