简介: 在现实生活中,除了分类问题外,也存在很多需要预测出具体值的回归问题,例如年龄预测、房价预测、股价预测等。相比分类问题而言,回归问题输出类型为一个连续值,如下表所示为两者的区别。在本文中,将完成房价预测这一回归问题。

■ 分类问题与回归问题区别
对于一个回归问题,从简单到复杂,可以采取的模型有多层感知机、SVR、回归森林算法等,下面将介绍如何使用这些算法完成这一任务。
01、使用MLP实现房价预测
首先是载入需要的各种包以及数据集,与前面使用树模型等不同的地方在于,使用多层感知机模型需要对数据集的X和y都根据最大最小值进行归一化处理。下图所示程序使用了线性归一化的方法,即

这种归一化方法比较适用在数值比较集中的情况。这种方法有个缺陷,如max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定,实际使用中可以用经验常量值来替代max和min。
sklearn库中提供了归一化的接口,如代码清单1所示为加载数据集并进行归一化处理的代码实现。
代码清单1 加载数据集并进行预处理操作
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.neural_network import MLPRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error
# 加载数据集并进行归一化预处理
def loadDataSet():
boston_dataset = load_boston()
X = boston_dataset.data
y = boston_dataset.target
y = y.reshape(-1, 1)
# 将数据划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 分别初始化对特征和目标值的标准化器
ss_X, ss_y = preprocessing.MinMaxScaler(), preprocessing.MinMaxScaler()
# 分别对训练和测试数据的特征以及目标值进行标准化处理
X_train, y_train = ss_X.fit_transform(X_train), ss_y.fit_transform(y_train)
X_test, y_test = ss_X.transform(X_test), ss_y.transform(y_test)
y_train, y_test = y_train.reshape(-1, ), y_test.reshape(-1, )
return X_train, X_test, y_train, y_test在预处理过数据集后,构建MLP模型,并设置模型的超参数,并在训练集上训练模型。
代码清单2 训练多层感知机模型
def trainMLP(X_train, y_train):
model_mlp = MLPRegressor(
hidden_layer_sizes=(20, 1), activation='logistic', solver='adam', alpha=0.0001, batch_size='auto',
learning_rate='constant', learning_rate_init=0.001, power_t=0.5, max_iter=5000, shuffle=True,
random_state=1, tol=0.0001, verbose=False, warm_start=False, momentum=0.9, nesterovs_momentum=True,
early_stopping=False, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
model_mlp.fit(X_train, y_train)
return model_mlp如代码清单2所示,该模型的超参数较多,最重要的几个超参数为hidden_layer_sizes(隐藏层神经元个数,在本次实验当中隐藏层分别为5和1),activations(激活函数,可以选择relu、logistic、tanh等),solver(优化方法,即sgd、adam等),以及与优化方法相关的learning_rate(学习率),momentum(动量)等,设置完模型参数后,使用fit函数完成训练过程。
代码清单3 测试模型效果
def test(model, X_test, y_test):
y_pre = model.predict(X_test)
print("The mean root mean square error of MLP-Model is {}".format(mean_squared_error(y_test, y_pre)**0.5))
print("The mean squared error of MLP-Model is {}".format(mean_squared_error(y_test, y_pre)))
print("The mean absolute error of MLP-Model is {}".format(mean_absolute_error(y_test, y_pre)))训练完成后在测试集上验证模型的效果,如代码清单3所示,不同于分类模型有准确率召回率等指标,回归模型验证模型效果通常采用MSE,MAE、RMSE等。
MSE(Mean Squared Error)叫做均方误差

MAE(Mean Absolute Error)为平均绝对误差,是绝对误差的平均值,能更好地反映预测值误差的实际情况
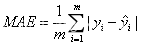
RMSE(Root Mean Square Error)为均方根误差,是用来衡量观测值同真值之间的偏差

以上三项指标的值越小,则表示在测试集上预测的结果与真实结果之间的偏差越小,模型拟合效果越好。
如代码清单4所示,在主函数中依次调用上述函数,完成导入数据集、训练、预测的全过程。
代码清单4 构建main函数
if __name__ == '__main__':
X_train, X_test, y_train, y_test = loadDataSet()
# 训练MLP模型
model = trainMLP(X_train, y_train)
test(model, X_test, y_test)最终可得输出如下图1所示。

图1 MLP模型预测效果
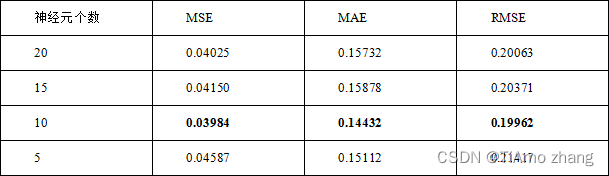
改变实验中的超参数,例如隐藏层的神经元个数,可以得到不同的模型以及这些模型在测试集上的得分。如表2所示,当神经元个数为10时,三项指标均获得了最小值,因此可以固定神经元个数为10,再调整其他参数,例如激活函数、优化方法等。
【小技巧】在难以确定参数时,可以将模型在训练集和测试集的误差都打印出来,当训练集误差远远大于测试集误差时,可能会存在过拟合的问题,应当减少参数数目,即神经元的个数。当训练集的误差与测试集误差都很大时,存在欠拟合的问题,应当增加神经元的个数。
表2 不同神经元个数的预测结果
02、使用随机森林模型实现房价预测
如代码清单5、代码清单6所示,导入与随机森林回归模型有关的包,并新增使用随机森林训练模型的函数,修改主函数,其他部分保持不变。
代码清单5 使用随机森林模型进行训练
def trainRF(X_train, y_train):
model_rf = RandomForestRegressor(n_estimators=10000)
model_rf.fit(X_train, y_train)
return model_rf代码清单6 修改main函数内容
if __name__ == '__main__':
X_train, X_test, y_train, y_test = loadDataSet()
# 训练RF模型
model = trainRF(X_train, y_train)
test(model, X_test, y_test)最终得到如图2所示为命令行输出结果。

图2 随机森林模型预测结果
下面调节n_estimators的数目,并记录相应的评价指标大小。如表3所示为一个随机森林中决策数目发生变化时评价指标的变化。可以发现,随着决策树数目的上升,各项指标都变得更优,一般而言,一个森林中决策树的个数越多,模型预测的准确率越高,但相应的会消耗更多的计算资源,因此在实际应用当中应当权衡效率与正确性这两点。
表3 随机森林不同决策树数目预测结果

03、文末赠书
这是一本讲述如何用NLP技术进行文本内容理解的著作,也是一本系统讲解NLP算法的著作,是作者在NLP和内容理解领域多年经验的总结。
本书结合内容理解的实际业务场景,系统全面、循序渐进地讲解了各种NLP算法以及如何用这些算法高效地解决内容理解方面的难题,主要包括如下几个方面的内容:
(1)文本特征表示
文本特征表示是NLP的基石,也是内容理解的基础环节,本书详细讲解了离散型表示方法和分布型表示方法等特征表示方法及其应用场景,还讲解了词向量的评判标准。
(2)内容重复理解
详细讲解了标题重复、段落重复、文章重复的识别方法和去重算法。
(3)内容通顺度识别及纠正
详细讲解了内容通顺度的识别方法以及纠正不通顺内容的各种算法。
(4)内容质量
详细讲解了多种内容质量相关的算法,以及如何搭建高质量的知识问答体系的流程。
(5)标签体系构建
详细讲解了针对内容理解的标签体系的建设流程和方法,以及相关的多种算法。
(6)文本摘要生成
详细讲解了抽取式文本摘要和生成式文本摘要两种流行的文本摘要生成方法,以及文本摘要的常用数据集和文本摘要评价方法。
(7)文本纠错
详细讲解了文本纠错的传统方法、深度学习方法、工业界解决方案,以及常用的文本纠错工具的安装和使用。

◆作者简介◆
李明琦
资深AI技术专家,现就职于BAT,担任高级算法工程师。长期致力于机器学习、深度学习、NLP等技术在实际业务场景中的落地,在内容理解方面有丰富的经验,主导的内容质量项目曾获得最佳项目奖。
先后发表人工智能相关的学术论文2篇,申请人工智能领域的发明专利5项。在GitHub上贡献了大量内容质量、问答系统、NLP等方面的代码,在CSDN撰写了一些与算法、机器学习、内容理解相关的文章,深受欢迎。
谷雪
现为葡萄牙米尼奥大学博士生,涉及的研究领域为神经架构搜索、自然语言处理、情感分析,博士期间着力于细粒度情感原因提取。先后发表过学术论文2篇,其中一篇是神经架构搜索的综述,另一篇是基于进化策略的神经架构演化方法。在开源平台GitHub上贡献了大量深度学习、机器学习代码,在CSDN上分享了服务器配置、数据分析、图像去噪、情感分析等方向的多篇文章。
孟子尧
在人工智能技术领域有非常深厚的积累,擅长机器学习和深度学习,尤其是深度学习中的图像分类和自然语言处理等技术。热衷于开源的应用和推广,在Github和CSDN上贡献了许多代码和文章。曾在《计算机研究与发展》上发表过1篇人工智能相关论文。
参与方式:评论区置顶评论红包手气王自动获得技术图书《基于NLP的内容理解》1本!









![[学习笔记]计算机图形学(一)](https://img-blog.csdnimg.cn/img_convert/1460cdbf0d4754eca14b73389e9564c9.png)