测试1( y = 3 ∗ x 1 − 4 ∗ x 2 y=3*x_{1}-4*x_{2} y=3∗x1−4∗x2),lr=1e-2
%matplotlib inline
import torch
import numpy as np
torch.manual_seed(1)
from torch.nn import Linear
from torch.autograd import Variable
import torch.nn as nn
import random
np.random.seed(1)
random.seed(1) #每次运行的结果都一样
torch.manual_seed(1)
import torch
import matplotlib.pyplot as plt
# x1 = torch.unsqueeze(torch.linspace(-1, 1, 200), dim=1)
# x2 = torch.unsqueeze(torch.linspace(-2, 2, 200), dim=1)
#x3 = torch.unsqueeze(torch.linspace(-2, 2, 100), dim=1)
x1=torch.randn(200,1)
x2=torch.randn(200,1)
y = 3*x1 -4*x2
# # 画图
# plt.scatter(x.data.numpy(), y.data.numpy())
# plt.show()
# import numpy as np
# import matplotlib.pyplot as plt
# from mpl_toolkits import mplot3d
# ax = plt.axes(projection='3d')
# ax.scatter3D(x1.data.numpy(), x2.data.numpy(),y.data.numpy())
# print(x1.size())
# print(x2.size())
# print(y.size())
#torch.cat((x1,x2),dim=1)#保持
class Net(nn.Module):#这里是大写的Module
def __init__(self):
super(Net,self).__init__()
self.Linear=nn.Linear(2,1)#把线性层赋值给自己的属性
def forward(self,x):#forward()是有两个参数的
x=self.Linear(x)
return x
model=Net()#网络
print(model)
criter=torch.nn.MSELoss()#损失函数
#optimizer = torch.optim.SGD(model.parameters(), lr=1e-2)#优化器
optimizer=torch.optim.Adam(model.parameters(),lr=1e-2)
#还需要一个DataGenerator()
num_epochs=1000
for i in range(num_epochs):
#向前传播
input=Variable(torch.cat((x1,x2),dim=1))
target=Variable(y)
out=model(input)#
loss=criter(out,target)#
#向后传播
optimizer.zero_grad()#梯度清0
loss.backward()#反向传播
optimizer.step()#更新梯度
print("epoch=%d,loss=%.6f"%(i,loss.item()))
#model.eval()
print(model)
parm={}
for name,parameters in model.named_parameters():
print(name,':',parameters.size())
parm[name]=parameters.detach().numpy()
print(parm)
结果如下

可以看到这个结果是准确的,但是一定要注意迭代的次数不能太少,且学习率不能太低,否则不容易收敛到真值,从而怀疑是不是自己代码写错了
测试2( y = 3 ∗ x 1 − 4 ∗ x 2 y=3*x_{1}-4*x_{2} y=3∗x1−4∗x2,lr=1e-3)
%matplotlib inline
import torch
import numpy as np
torch.manual_seed(1)
from torch.nn import Linear
from torch.autograd import Variable
import torch.nn as nn
import random
np.random.seed(1)
random.seed(1) #每次运行的结果都一样
torch.manual_seed(1)
import torch
import matplotlib.pyplot as plt
# x1 = torch.unsqueeze(torch.linspace(-1, 1, 200), dim=1)
# x2 = torch.unsqueeze(torch.linspace(-2, 2, 200), dim=1)
#x3 = torch.unsqueeze(torch.linspace(-2, 2, 100), dim=1)
x1=torch.randn(200,1)
x2=torch.randn(200,1)
y = 3*x1 -4*x2
# # 画图
# plt.scatter(x.data.numpy(), y.data.numpy())
# plt.show()
# import numpy as np
# import matplotlib.pyplot as plt
# from mpl_toolkits import mplot3d
# ax = plt.axes(projection='3d')
# ax.scatter3D(x1.data.numpy(), x2.data.numpy(),y.data.numpy())
# print(x1.size())
# print(x2.size())
# print(y.size())
#torch.cat((x1,x2),dim=1)#保持
class Net(nn.Module):#这里是大写的Module
def __init__(self):
super(Net,self).__init__()
self.Linear=nn.Linear(2,1)#把线性层赋值给自己的属性
def forward(self,x):#forward()是有两个参数的
x=self.Linear(x)
return x
model=Net()#网络
print(model)
criter=torch.nn.MSELoss()#损失函数
#optimizer = torch.optim.SGD(model.parameters(), lr=1e-2)#优化器
optimizer=torch.optim.Adam(model.parameters(),lr=1e-3)
#还需要一个DataGenerator()
num_epochs=1000
for i in range(num_epochs):
#向前传播
input=Variable(torch.cat((x1,x2),dim=1))
target=Variable(y)
out=model(input)#
loss=criter(out,target)#
#向后传播
optimizer.zero_grad()#梯度清0
loss.backward()#反向传播
optimizer.step()#更新梯度
print("epoch=%d,loss=%.6f"%(i,loss.item()))
#model.eval()
print(model)
parm={}
for name,parameters in model.named_parameters():
print(name,':',parameters.size())
parm[name]=parameters.detach().numpy()
print(parm)
## 如果学习率过低,收敛很慢
结果如下

可以看到这里没有收敛的,
测试3( y = 3 ∗ x + 4 y = 3*x +4 y=3∗x+4一元线性回归)
%matplotlib inline
import torch
import numpy as np
torch.manual_seed(1)
from torch.nn import Linear
from torch.autograd import Variable
import torch.nn as nn
import random
np.random.seed(1)
random.seed(1) #每次运行的结果都一样
torch.manual_seed(1)
import torch
import matplotlib.pyplot as plt
x1=torch.randn(200,1)
y = 3*x1 +4
# # 画图
# plt.scatter(x.data.numpy(), y.data.numpy())
# plt.show()
# import numpy as np
# import matplotlib.pyplot as plt
# from mpl_toolkits import mplot3d
# ax = plt.axes(projection='3d')
# ax.scatter3D(x1.data.numpy(), x2.data.numpy(),y.data.numpy())
# print(x1.size())
# print(x2.size())
# print(y.size())
#torch.cat((x1,x2),dim=1)#保持
class Net(nn.Module):#这里是大写的Module
def __init__(self):
super(Net,self).__init__()
self.Linear=nn.Linear(1,1)#把线性层赋值给自己的属性
def forward(self,x):#forward()是有两个参数的
x=self.Linear(x)
return x
model=Net()#网络
print(model)
criter=torch.nn.MSELoss()#损失函数
#optimizer = torch.optim.SGD(model.parameters(), lr=1e-2)#优化器
optimizer=torch.optim.Adam(model.parameters(),lr=1e-2)
#还需要一个DataGenerator()
num_epochs=1000
for i in range(num_epochs):
#向前传播
input=Variable(x1)
target=Variable(y)
out=model(input)#
loss=criter(out,target)#
#向后传播
optimizer.zero_grad()#梯度清0
loss.backward()#反向传播
optimizer.step()#更新梯度
print("epoch=%d,loss=%.6f"%(i,loss.item()))
#model.eval()
print(model)
parm={}
for name,parameters in model.named_parameters():
print(name,':',parameters.size())
parm[name]=parameters.detach().numpy()
print(parm)
结果如下
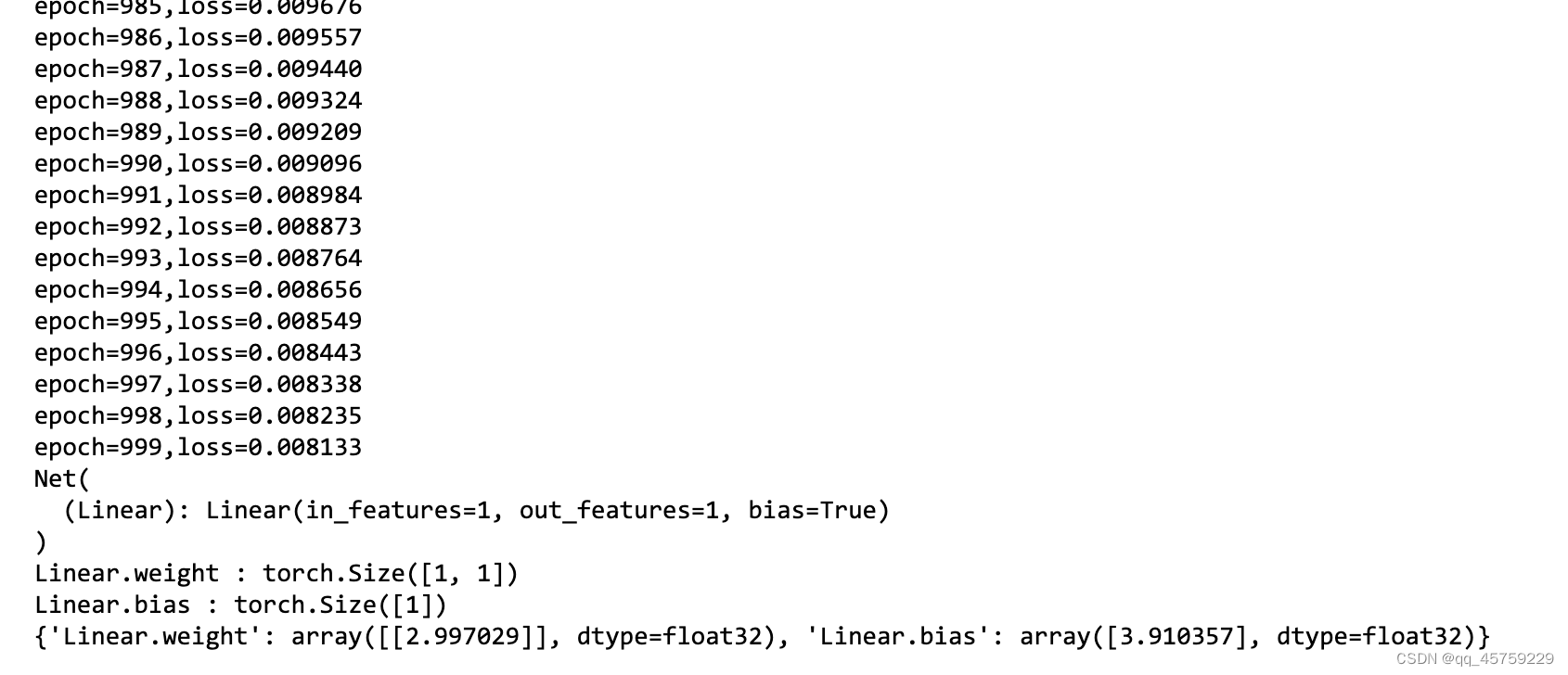
测试4 y = 3 ∗ x + 4 y = 3*x +4 y=3∗x+4 使用dataloader-batch_size=32
%matplotlib inline
import torch
import numpy as np
torch.manual_seed(1)
from torch.nn import Linear
from torch.autograd import Variable
from torch.utils.data import DataLoader, Dataset,TensorDataset
import torch.nn as nn
import random
np.random.seed(1)
random.seed(1) #每次运行的结果都一样
torch.manual_seed(1)
import torch
import matplotlib.pyplot as plt
x1=torch.randn(200,1)
y = 3*x1 +4
# # 画图
# plt.scatter(x.data.numpy(), y.data.numpy())
# plt.show()
# import numpy as np
# import matplotlib.pyplot as plt
# from mpl_toolkits import mplot3d
# ax = plt.axes(projection='3d')
# ax.scatter3D(x1.data.numpy(), x2.data.numpy(),y.data.numpy())
# print(x1.size())
# print(x2.size())
# print(y.size())
#torch.cat((x1,x2),dim=1)#保持
class Net(nn.Module):#这里是大写的Module
def __init__(self):
super(Net,self).__init__()
self.Linear=nn.Linear(1,1)#把线性层赋值给自己的属性
def forward(self,x):#forward()是有两个参数的
x=self.Linear(x)
return x
model=Net()#网络
print(model)
criter=torch.nn.MSELoss()#损失函数
dataset = TensorDataset(torch.FloatTensor(x1),torch.FloatTensor(y))
dataloader = DataLoader(dataset,batch_size = 32)
#optimizer = torch.optim.SGD(model.parameters(), lr=1e-2)#优化器
optimizer=torch.optim.Adam(model.parameters(),lr=1e-3)
#还需要一个DataGenerator()
num_epochs=1000
for epoch in range(num_epochs):
#向前传播
mse_loss=0
for idx,(input_x,target_y) in enumerate(dataloader):
input=Variable(input_x)
target=Variable(target_y)
out=model(input)#
loss=criter(out,target)#
mse_loss += loss.item()
#向后传播
optimizer.zero_grad()#梯度清0
loss.backward()#反向传播
optimizer.step()#更新梯度
print("epoch={},mse loss ={}".format(epoch,mse_loss/len(dataloader)))
model.eval()
print(model)
parm={}
for name,parameters in model.named_parameters():
print(name,':',parameters.size())
parm[name]=parameters.detach().numpy()
print(parm)
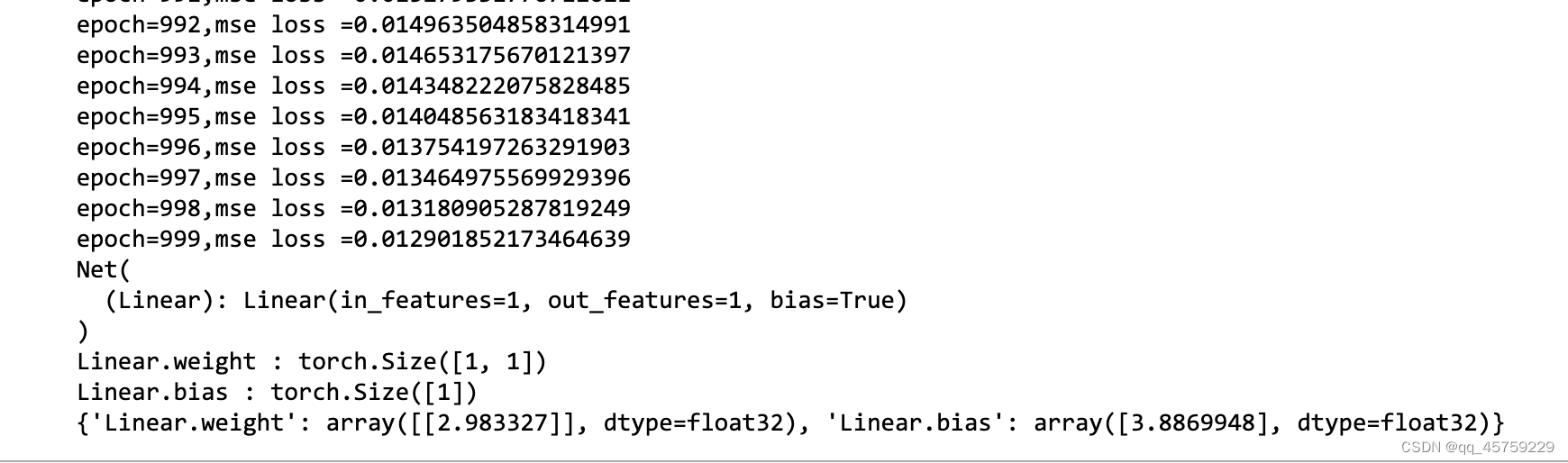 可以看到使用batch_size进行训练时,也是可以得到准确的结果的
可以看到使用batch_size进行训练时,也是可以得到准确的结果的
测试5( y = 3 ∗ x 1 − 4 ∗ x 2 + 2.30 y=3*x1-4*x2+2.30 y=3∗x1−4∗x2+2.30 dataloader,batch_size=32)
%matplotlib inline
import torch
import numpy as np
torch.manual_seed(1)
from torch.nn import Linear
from torch.autograd import Variable
from torch.utils.data import DataLoader, Dataset,TensorDataset
import torch.nn as nn
import random
np.random.seed(1)
random.seed(1) #每次运行的结果都一样
torch.manual_seed(1)
import torch
import matplotlib.pyplot as plt
# x1 = torch.unsqueeze(torch.linspace(-1, 1, 200), dim=1)
# x2 = torch.unsqueeze(torch.linspace(-2, 2, 200), dim=1)
#x3 = torch.unsqueeze(torch.linspace(-2, 2, 100), dim=1)
x1=torch.randn(200,1)
x2=torch.randn(200,1)
y = 3*x1 -4*x2 + 2.30
class Net(nn.Module):#这里是大写的Module
def __init__(self):
super(Net,self).__init__()
self.Linear=nn.Linear(2,1)#把线性层赋值给自己的属性
def forward(self,x):#forward()是有两个参数的
x=self.Linear(x)
return x
model=Net()#网络
print(model)
criter=torch.nn.MSELoss()#损失函数
#optimizer = torch.optim.SGD(model.parameters(), lr=1e-2)#优化器
optimizer=torch.optim.Adam(model.parameters(),lr=1e-2)
dataset = TensorDataset(torch.FloatTensor(x1),torch.FloatTensor(x2),torch.FloatTensor(y))
dataloader = DataLoader(dataset,batch_size = 32)
#还需要一个DataGenerator()
num_epochs=1000
for epoch in range(num_epochs):
mse_loss=0
for idx,(input_x1,input_x2,target_y) in enumerate(dataloader):
#向前传播
input=Variable(torch.cat((input_x1,input_x2),dim=1))
target=Variable(target_y)
out=model(input)#
loss=criter(out,target)#
mse_loss += loss.item()
#向后传播
optimizer.zero_grad()#梯度清0
loss.backward()#反向传播
optimizer.step()#更新梯度
print("epoch={},mse loss ={}".format(epoch,mse_loss/len(dataloader)))
#model.eval()
print(model)
parm={}
for name,parameters in model.named_parameters():
print(name,':',parameters.size())
parm[name]=parameters.detach().numpy()
print(parm)