CUDA系列文章
文章目录
- CUDA系列文章
- 前言
- 一、优化方案
- 简单顺序调用
- 二、Overlapping
- 三、使用CUDA Graph
- 总结
前言
GPU 架构的性能随着每一代的更新而不断提高。 现代 GPU 每个操作(如kernel运行或内存复制)所花费的时间现在以微秒为单位。 但是,将每个操作提交给 GPU 也会产生一些开销——也是微秒级的。
实际的应用程序中经常要执行大量的 GPU 操作:典型模式涉及许多迭代(或时间步),每个步骤中有多个操作。 如果这些操作中的每一个都单独提交到 GPU 启动并独立计算,那么提交启动开销汇总在一起可能导致明显的整体性能下降。
CUDA Graphs 将整个计算流程定义为一个图而不是单个操作的列表。 最后通过提供一种由单个 CPU 操作来启动图上的多个 GPU 操作的方式减少kernel提交启动开销,进而解决上述问题。 下面,通过一个非常简单的示例来演示如何使用 CUDA Graphs。
假设我们有一系列执行时间非常短的kernels:
Loop over timesteps
…
shortKernel1
shortKernel2
…
shortKernelN
…
而其中每个kernel都像下面这样简单:
#define N 500000 // tuned such that kernel takes a few microseconds
__global__ void shortKernel(float * out_d, float * in_d){
int idx=blockIdx.x*blockDim.x+threadIdx.x;
if(idx<N) out_d[idx]=1.23*in_d[idx];
}
从内存中读取浮点数的输入数组,将每个元素乘以一个常数因子,然后将输出数组写回内存。 该kernel单个执行所用的时间取决于数组大小。上面的例子中,在数组大小设置为 500,000 个元素时,kernel执行需要几微秒。 使用profiler测量所花费的时间,在使用 CUDA 10.1 的 NVIDIA Tesla V100 GPU 上运行(同时将每个block的线程数设置为 512 个线程),耗时为2.9μs。 后面,我们将保持这个kernel不变,只改变它的调用方式。
一、优化方案
简单顺序调用
#define NSTEP 1000
#define NKERNEL 20
// start CPU wallclock timer
for(int istep=0; istep<NSTEP; istep++){
for(int ikrnl=0; ikrnl<NKERNEL; ikrnl++){
shortKernel<<<blocks, threads, 0, stream>>>(out_d, in_d);
cudaStreamSynchronize(stream);
}
}
//end CPU wallclock time
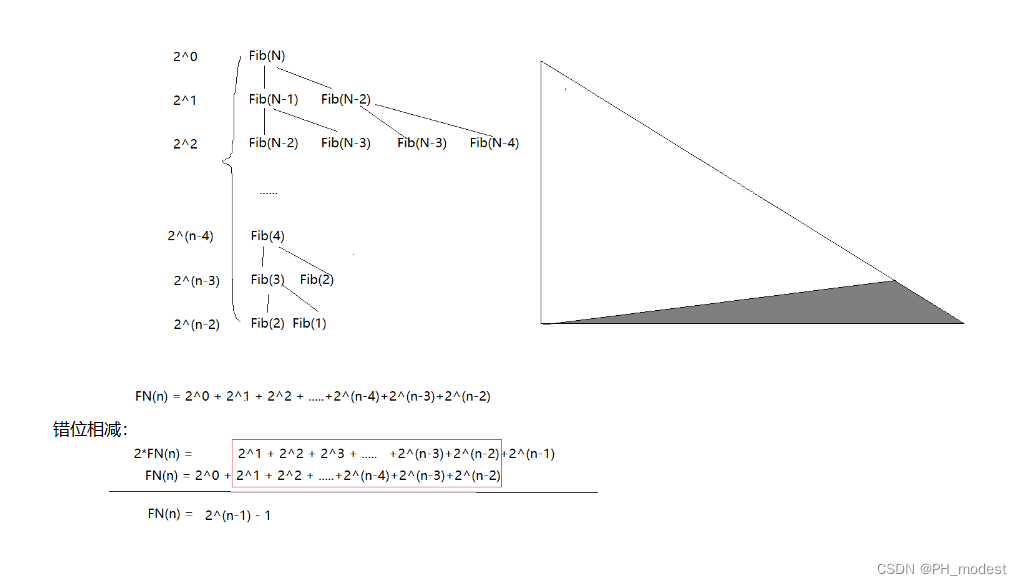
双层循环中 ,内层循环调用内核 20 次,外层进行 1000 次迭代。 在CPU使用timer记录整个操作所花费的时间,然后除以 NSTEP*NKERNEL,得到每个内核 9.6μs(包括启动kernel开销),要远高于 2.9μs 的纯内核执行时间。
由于在每次内核启动后都调用了 cudaStreamSynchronize 方法,所以每个kernel在前一个完成之前不会启动。 这意味着与每次启动相关的任何开销都将完全暴露:总时间将是内核执行时间加上任何开销的总和。 可以使用 Nsight Systems 分析器直观地看到这一点:
 上图截取显示了timeline的一部分(时间从左到右),包括 8 次连续的kernel启动。 理想情况下,GPU 应该保持忙碌计算状态,但情况显然并非如此。 在“CUDA (Tesla V100-SXM2-16G)”右侧部分可以看到每个kernel执行间都有很大的gap,此时GPU处于空闲状态。
上图截取显示了timeline的一部分(时间从左到右),包括 8 次连续的kernel启动。 理想情况下,GPU 应该保持忙碌计算状态,但情况显然并非如此。 在“CUDA (Tesla V100-SXM2-16G)”右侧部分可以看到每个kernel执行间都有很大的gap,此时GPU处于空闲状态。
在CUDA API的那一行,紫色块代表着CPU调用kernel启动方法的耗时,绿色块代表同步GPU所需的时间(包括等待kernel启动完成耗时+计算),cpu对kernel启动方法的调用耗时+kernel启动本身的耗时最后加起来就成为上面gap的时间了。
虽然这个时间尺度上,分析器本身会增加一些额外的启动开销,因此为了准确分析性能,应该使用基于CPU计时器。 尽管如此,分析器在帮助我们理解代码行为方面仍然具有指导意义。
二、Overlapping
// start wallclock timer
for(int istep=0; istep<NSTEP; istep++){
for(int ikrnl=0; ikrnl<NKERNEL; ikrnl++){
shortKernel<<<blocks, threads, 0, stream>>>(out_d, in_d);
}
cudaStreamSynchronize(stream);
}
//end wallclock timer
一个简单有效的优化方案,是overlap不同kernel的调用和执行过程。
虽然上面的代码中,由于kernel在同一个stream中,它们仍将按顺序执行。但现在由于不需要每个kernel执行都进行同步(调用cudaStreamSynchronize),使得在前一个kernel执行完成之前可以启动下一个kernel(kernel调用是异步的),最终达到了将kernel启动开销隐藏在内核执行时间内。此时测量每个内核所花费的时间(包括开销)为 3.8μs。与 2.9μs 内核执行时间相比,这已大大改善,但仍然存在与多次启动相关的开销。
 可以看到绿色块代表的同步时间已经基本没有了(只有进入外层循环时会产生),但是不同kernel执行间还是有一定的gap存在。
可以看到绿色块代表的同步时间已经基本没有了(只有进入外层循环时会产生),但是不同kernel执行间还是有一定的gap存在。
三、使用CUDA Graph
bool graphCreated=false;
cudaGraph_t graph;
cudaGraphExec_t instance;
for(int istep=0; istep<NSTEP; istep++){
if(!graphCreated){
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
for(int ikrnl=0; ikrnl<NKERNEL; ikrnl++){
shortKernel<<<blocks, threads, 0, stream>>>(out_d, in_d);
}
cudaStreamEndCapture(stream, &graph);
cudaGraphInstantiate(&instance, graph, NULL, NULL, 0);
graphCreated=true;
}
cudaGraphLaunch(instance, stream);
cudaStreamSynchronize(stream);
}
引入了两个新对象:
cudaGraph_t 类型的对象定义了kernel graph的结构和内容;
cudaGraphExec_t 类型的对象是一个“可执行的graph实例”:它可以以类似于单个内核的方式启动和执行。
首先,定义一个kernel graph,然后通过 cudaStreamBeginCapture 和 cudaStreamEndCapture 方法来捕捉它们之间stream上所有的 GPU kernel,来得到kernel graph。
然后,必须通过 cudaGraphInstantiate 调用实例化graph,该调用创建并预初始化所有kernel工作描述符,以便它们可以尽可能快地重复启动。
最后,通过 cudaGraphLaunch 调用提交生成的实例以供执行。
关键点在于,kernel graph只需要捕获和实例化一次,并在所有后续循环中重复使用相同的实例(上例中由 graphCreated 布尔值上的条件语句控制)。
所以实际的执行流程是:
循环第一个步:
捕捉创建和实例化kernel graph
启动kernel graph(包含 20 个kernel)
等待kernel graph 执行完成
对于剩余循环步骤:
启动kernel graph(包含 20 个kernel)
等待kernel graph 执行完成
测量这个完整过程所花费的时间,除以 1000×20 得到每个内核的有效时间(包括开销),得到 3.4μs(相对于 2.9μs 内核执行时间),成功地进一步降低了开销。 请注意,在这种情况下,创建和实例化图的时间相对较大,约为 400μs,但这仅执行一次,平摊到每个kernel上约为 0.02μs。 同样,第一个图启动比所有后续启动慢约 33%,但当多次重复使用同一个图时,这变得微不足道。 初始化的开销是否不可接受显然取决于问题(也可以采用程序的预热来规避):通常为了从cuda graph中受益,需要重复调用相同的cuda graph足够多次。 许多现实世界的问题涉及大量重复执行,因此适合使用cuda graph。
当前的profiler和cuda graph还做不到完全兼容(Sep 05, 2019,现在应该ok了),所以开启profiler会禁用cuda graph,所以上不了图。但可以想象一下它的样子,大概就是20个kernel紧密执行,中间加上graph本身的启动开销。
进一步学习
即使在上述非常简单的演示案例中(其中大部分开销已经通过重叠的内核启动和执行隐藏),也能看到 CUDA Graphs 对效率的提升,但更复杂的计算逻辑提供了更多优化提升的空间。 cuda graph支持多个stream间的融合,而且不仅可以包含kernel执行,还可以包括在主机 CPU 上执行的函数和内存拷贝。在 CUDA 示例中的 simpleCUDAGraphs 有更详尽的例子。
另外,除了自动捕捉graph,也可以通过 API 调用显式定义节点和依赖关系——simpleCUDAGraphs 示例中有采用这两种技术来完成相同问题的例子。 此外,graph还可以跨越多个 GPU。
在同一个graph中包含更多的kernel信息,显然也给cuda以更多的优化空间。可以查看Programming Guide中CUDA Graphs的章节。在GTC 2019 talk 中也有相关信息:CUDA: New Features and Beyond.
总结
翻译自:Getting Started with CUDA Graphs | NVIDIA Developer Blog