第2章 数据仓库建模概述
2.1 数据仓库建模的意义
如果把数据看作图书馆里的书,我们希望看到它们在书架上分门别类地放置;如果把数据看作城市的建筑,我们希望城市规划布局合理;如果把数据看作电脑文件和文件夹,我们希望按照自己的习惯有很好的文件夹组织方式,而不是糟糕混乱的桌面,经常为找一个文件而不知所措。
数据模型就是数据组织和存储方法,它强调从业务、数据存取和使用角度合理存储数据。只有将数据有序的组织和存储起来之后,数据才能得到高性能、低成本、高效率、高质量的使用。
高性能:良好的数据模型能够帮助我们快速查询所需要的数据。
低成本:良好的数据模型能减少重复计算,实现计算结果的复用,降低计算成本。
高效率:良好的数据模型能极大的改善用户使用数据的体验,提高使用数据的效率。
高质量:良好的数据模型能改善数据统计口径的混乱,减少计算错误的可能性。
2.2 数据仓库建模方法论
2.2.1 ER模型
数据仓库之父Bill Inmon提出的建模方法是从全企业的高度,用实体关系(Entity Relationship,ER)模型来描述企业业务,并用规范化的方式表示出来,在范式理论上符合3NF。
1)实体关系模型
实体关系模型将复杂的数据抽象为两个概念——实体和关系。实体表示一个对象,例如学生、班级,关系是指两个实体之间的关系,例如学生和班级之间的从属关系。
2)数据库规范化
数据库规范化是使用一系列范式设计数据库(通常是关系型数据库)的过程,其目的是减少数据冗余,增强数据的一致性。
这一系列范式就是指在设计关系型数据库时,需要遵从的不同的规范。关系型数据库的范式一共有六种,分别是第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF)。遵循的范式级别越高,数据冗余性就越低。
3)三范式
(1)函数依赖

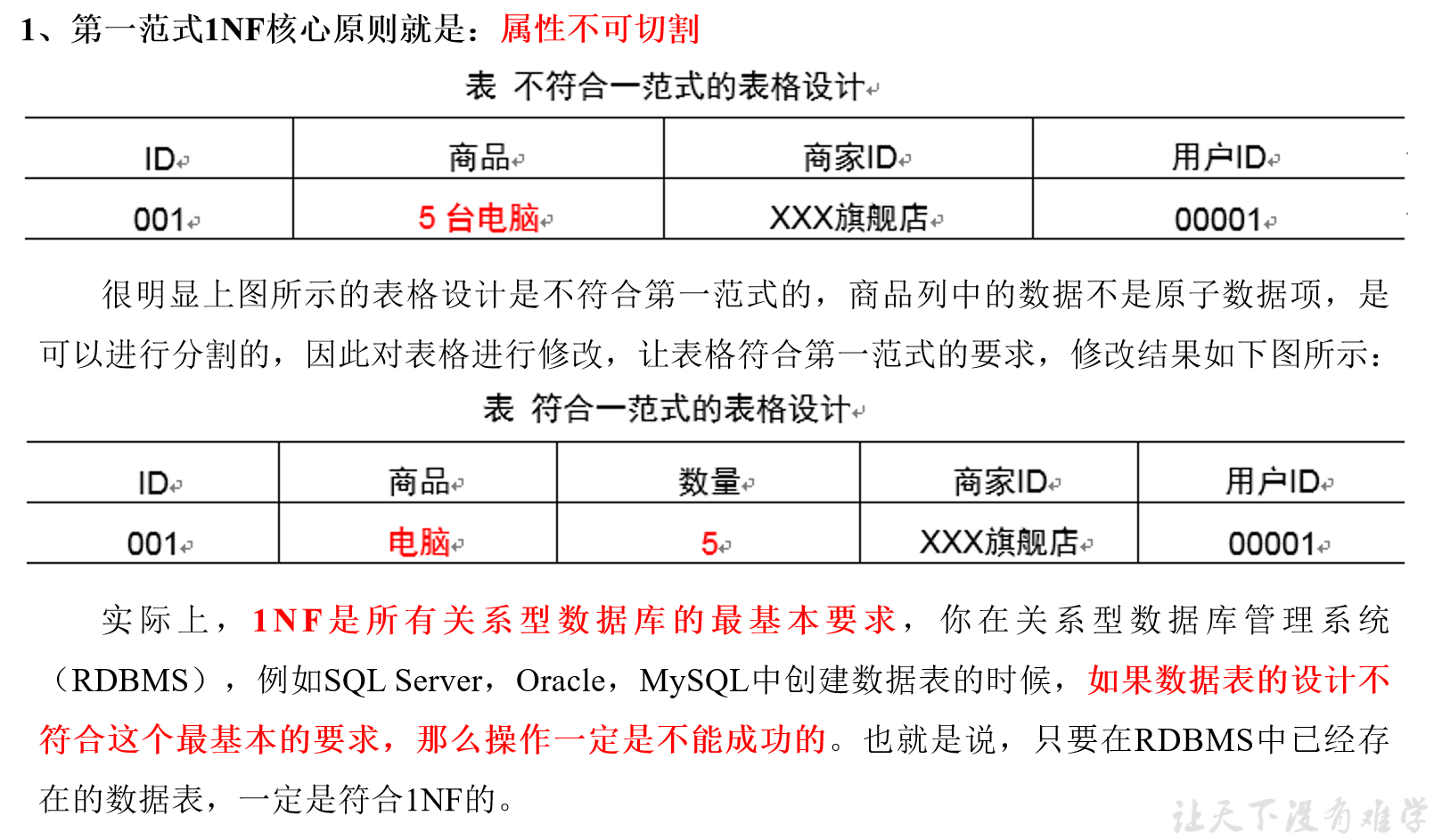
(2)第一范式
(3)第二范式
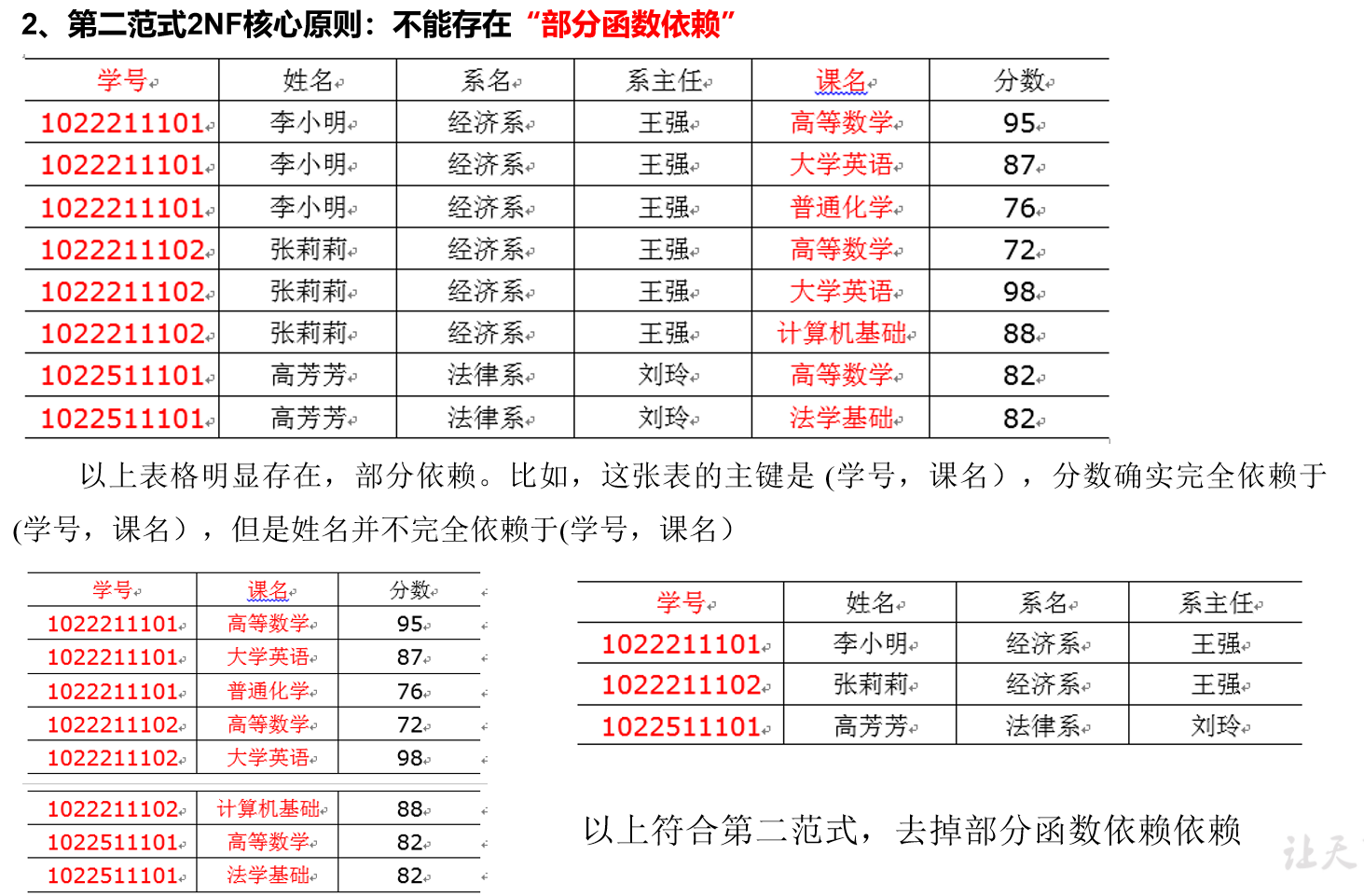
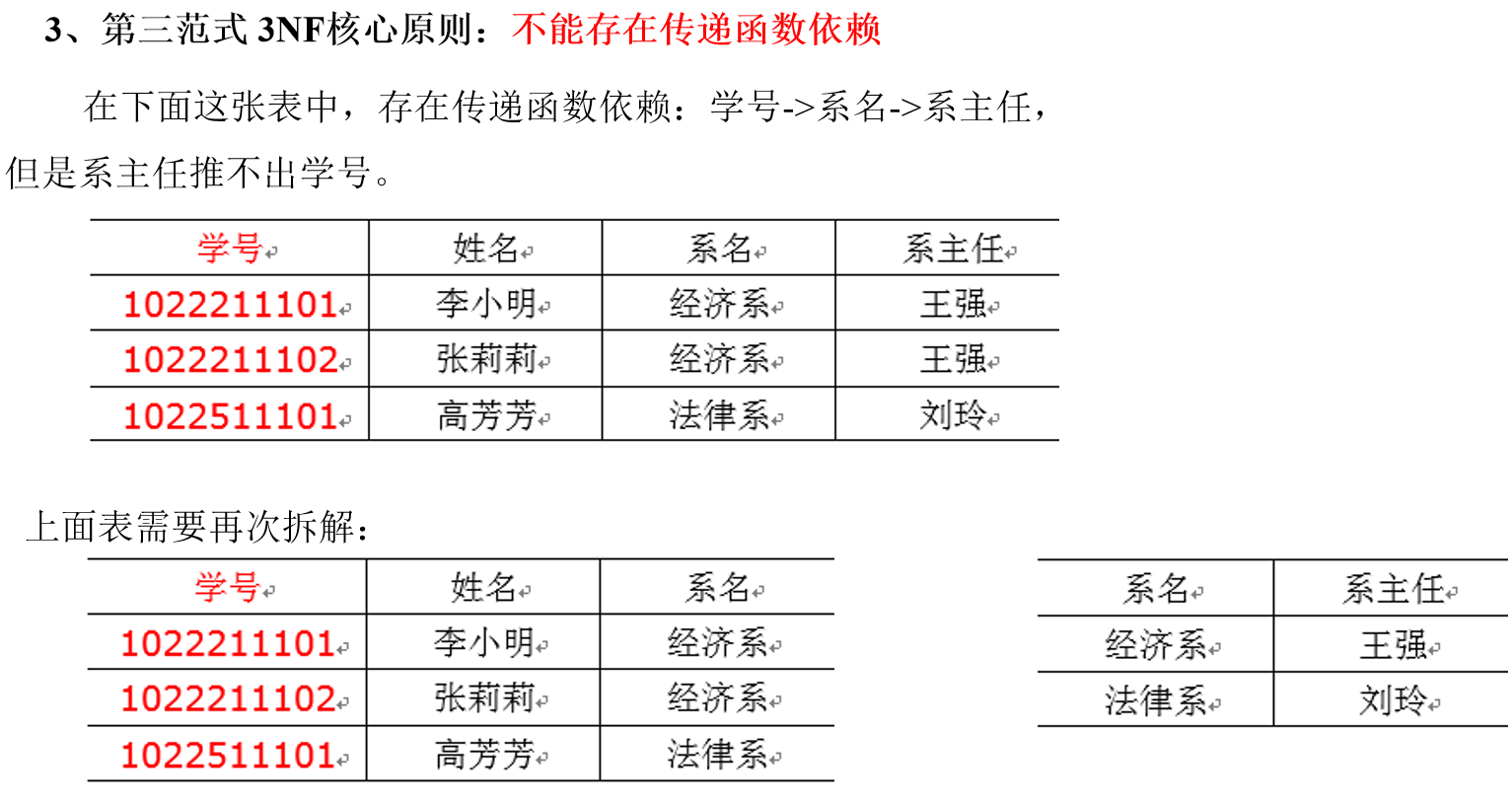
(4)第三范式
下图为一个采用Bill Inmon倡导的建模方法构建的模型,从图中可以看出,较为松散、零碎,物理表数量多。
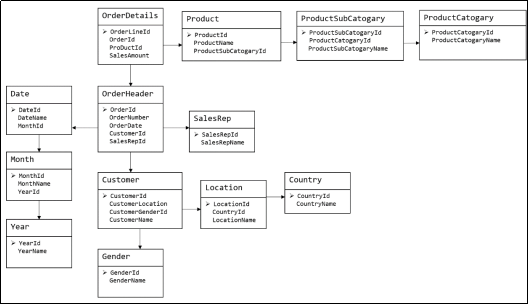
这种建模方法的出发点是整合数据,其目的是将整个企业的数据进行组合和合并,并进行规范处理,减少数据冗余性,保证数据的一致性。这种模型并不适合直接用于分析统计。
2.2.2 维度模型
数据仓库领域的令一位大师——Ralph Kimball倡导的建模方法为维度建模。维度模型将复杂的业务通过事实和维度两个概念进行呈现。事实通常对应业务过程,而维度通常对应业务过程发生时所处的环境。
注:业务过程可以概括为一个个不可拆分的行为事件,例如电商交易中的下单,取消订单,付款,退单等,都是业务过程。
下图为一个典型的维度模型,其中位于中心的SalesOrder为事实表,其中保存的是下单这个业务过程的所有记录。位于周围每张表都是维度表,包括Date(日期),Customer(顾客),Product(产品),Location(地区)等,这些维度表就组成了每个订单发生时所处的环境,即何人、何时、在何地下单了何种产品。从图中可以看出,模型相对清晰、简洁。
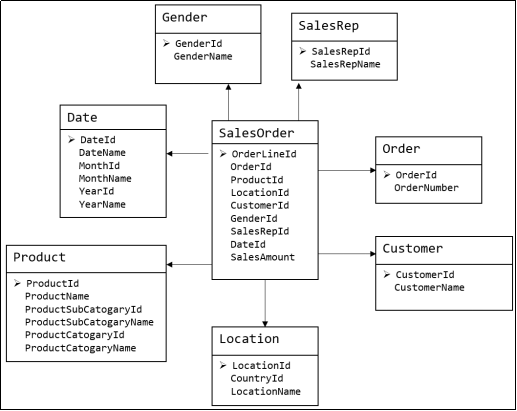
维度建模以数据分析作为出发点,为数据分析服务,因此它关注的重点的用户如何更快的完成需求分析以及如何实现较好的大规模复杂查询的响应性能。

![[JavaEE]----Spring03](https://img-blog.csdnimg.cn/abd888e6246e43fcb6a199e363d2300d.png)







![150.网络安全渗透测试—[Cobalt Strike系列]—[DNS Beacon原理/实战测试]](https://img-blog.csdnimg.cn/bca7879176b644e488a4d398d7129b59.png)