DMA(Direct Memory Access):直接存储器访问;
一、DMA传输将数据从一个地址空间复制到另一个地址空间,提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。
DMA用来提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。无须CPU的干预,通过DMA数据可以快速地移动。这就节省了CPU的资源来做其他操作。
DMA的工作原理是,如果按数据块进行I/O,即需要传输大量数据时,就无须CPU的介入。
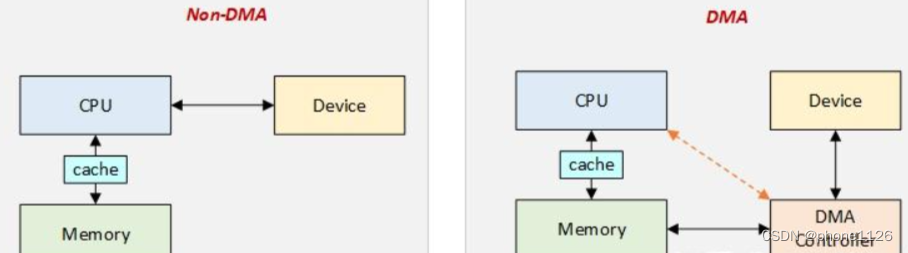
在这种情况下,我们可以让I/O设备与计算机内存进行直接数据交换。而CPU则可以去忙别的事情。这种将CPU的介入减少的I/O模式称为直接内存访问。
二、DMA中也有cpu(DMA数据传输需要使用CPU,只不过这里使用的CPU不是计算机里面所有进程共享的CPU,而是由另外一个CPU来负责数据传输。这个另外的CPU就是DMA控制器) 只不过里面的CPU可以比通用CPU简单,且价格便宜很多,它只需要能够以不慢于I/O设备的速度进行数据读写即可。其他复杂功能,如算数运算、移位、逻辑运算等功能皆可以不要。
DMA控制器既可以构建在设备控制器里面,也可以作为独立的实体挂在计算机主板上。而以独立形式存在的DMA控制器更为常见。使用DMA进行I/O的工作流程下所示。
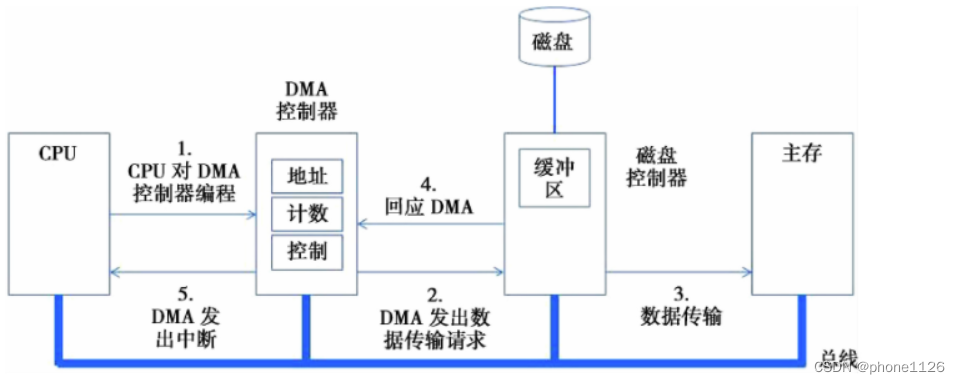
DMA输入输出的过程如下所示:
1)CPU对DMA进行设置,告诉其I/O的起始地址和数据长度。
2)启动DMA过程。
3)DMA进行数据传输。
4)DMA结束后发出中断。
5)CPU响应中断并处理结束事宜。
DMA控制器依生产商的不同而有很大的区别。最简单的DMA控制器在一段时间内只能处理一个I/O,即不能并发;而复杂的DMA控制器可以同时处理多个I/O,即它能够提供多个I/O通道,每个通道可以对应一个I/O设备。
三、DMA传输方式
DMA的作用就是实现数据的直接传输,而去掉了传统数据传输需要CPU寄存器参与的环节,主要涉及四种情况的数据传输,但本质上是一样的,都是从内存的某一区域传输到内存的另一区域(外设的数据寄存器本质上就是内存的一个存储单元)。四种情况的数据传输如下:
外设到内存
内存到外设
内存到内存
外设到外设
四、DMA传输参数
我们知道,数据传输,首先需要的是1 数据的源地址 2 数据传输位置的目标地址 ,3 传递数据多少的数据传输量 ,4 进行多少次传输的传输模式 DMA所需要的核心参数,便是这四个
当用户将参数设置好,主要涉及源地址、目标地址、传输数据量这三个,DMA控制器就会启动数据传输,当剩余传输数据量为0时 达到传输终点,结束DMA传输 ,当然,DMA 还有循环传输模式 当到达传输终点时会重新启动DMA传输。
也就是说只要剩余传输数据量不是0,而且DMA是启动状态,那么就会发生数据传输。
五、DMA的主要特征
每个通道都直接连接专用的硬件DMA请求,每个通道都同样支持软件触发。这些功能通过软件来配置;
在同一个DMA模块上,多个请求间的优先权可以通过软件编程设置(共有四级:很高、高、中等和低),优先权设置相等时由硬件决定(请求0优先于请求1,依此类推);
独立数据源和目标数据区的传输宽度(字节、半字、全字),模拟打包和拆包的过程。源和目标地址必须按数据传输宽度对齐;
支持循环的缓冲器管理;
每个通道都有3个事件标志(DMA半传输、DMA传输完成和DMA传输出错),这3个事件标志逻辑或成为一个单独的中断请求;
存储器和存储器间的传输、外设和存储器、存储器和外设之间的传输;
闪存、SRAM、外设的SRAM、APB1、APB2和AHB外设均可作为访问的源和目标;
可编程的数据传输数目:最大为65535。
六、DMA的寻址能力
默认情况,内核假设外设的DMA寻址能力是32-bits,但这并不普适(比如有些外设的寻址能力是24-bits,只能访问0MB--16MB的物理地址)。正确的操作应该是在设备初始化过程中,显示的指定DMA的寻址能力,有如下三个接口可以完成该操作:
/* 流式DMA设置寻址能力 */
int dma_set_mask(struct device *dev, u64 mask);
/* 一致性DMA设置寻址能力 */
int dma_set_coherent_mask(struct device *dev, u64 mask);
/* 流式DMA与一致性DMA同时设置寻址能力(两种模式的寻址能力相同) */
int dma_set_mask_and_coherent(struct device *dev, u64 mask);
需要强调的是,一致性DMA的寻址能力(掩码值)小于等于流式DMA的寻址能力(掩码值)
七、DMA能搬运哪些内存?
哪些内存可以使用DMA mapping framework提供的API接口呢?
- 通过伙伴系统分配器(buddy allocater)的接口(__get_free_page*()/kmalloc()/kmem_cache_alloc())分配的DMA buffer;
- 不建议vmalloc()返回的虚拟地址用于DMA buffer,因为大小超过一页(one page)时其物理地址不连续,一般来说DMA硬件要求物理地址连续,即使DMA硬件支持scatter-gether,vmalloc分配的虚拟地址与对应的物理地址没有固定的偏移,我们仍需要遍历页表才能找到其对应关系。综上所述,不建议使用vmalloc创建DMA buffer。
- 不建议使用内核全局变量(存储在data/text/bss段)、内核模块中的全局变量、栈地址作为DMA buffer。需要保证这些虚拟内存cacheline对齐,否则会在CPU和非一致性DMA中有cacheline共享问题(CPU写一个word,同时DMA可能在同一个cache line中写一个不同的word,导致其中的一个被覆盖)
- 不建议kmap()接口返回的虚拟地址用于DMA buffer,原因与vmalloc同。
- 块设备IO和网络buffer是可以用于DMA buffer的,这一点由块设备IO和网络子系统保证。
八、两种类型的DMA mapping:一致性DMA映射&流式DMA映射
- 一致性DMA:在驱动初始化时mapping,在驱动shutdown时unmapping**(意味着不是一次性的,是持续性的使用该DMA映射)**。硬件需要保证外设和CPU能并行访问同一块数据,并且保证在软件无显式flush操作的情况下,CPU和外设能同步看到对方对数据的更新。一致性(consistent)可以理解为同步(synchronous)。
- 典型的使用一致性DMA的例子:网卡DMA环形缓冲区(ring descriptors)。
- 一致性DMA不妨碍内存屏障(memory barriers)的使用,比如设备需要先看到word0的修改,再看到word1的修改,代码可以如下:
desc->word0 = address;
wmb();
desc->word1 = DESC_VALID;
- 流式DMA:一般是需要一次DMA transfer时map,传输结束后unmap(当然也可以有dma_sync的操作,下文会详聊),硬件可以优化存取的顺序。流式(streaming)可以理解为异步(asynchronous)。
- 典型用例:网卡进行数据传输使用的DMA buffer;SCSI设备写入/读取的文件系统buffer;
- 设计这样的接口是为了充分优化硬件的性能。
另外需要注意的是,无论是哪种类型的DMA都有对齐的限制;此外,如果系统中的cache不是DMA-coherent的,而且底层的DMA buffer不和其他数据共享cache lines,这样的系统将会有更好的性能。