Pre:效果预览
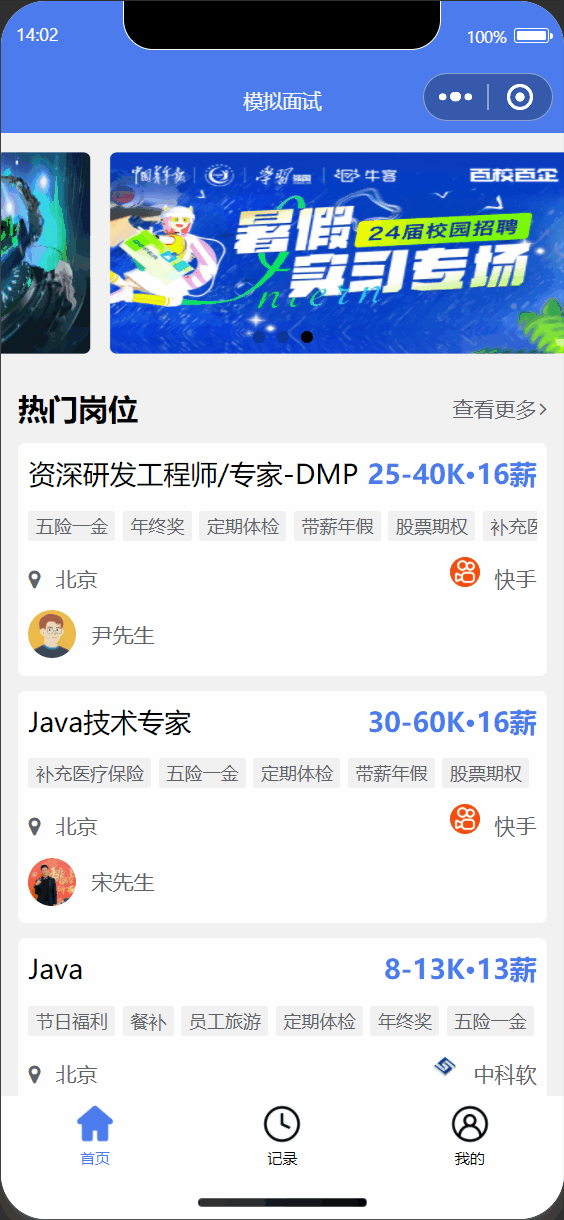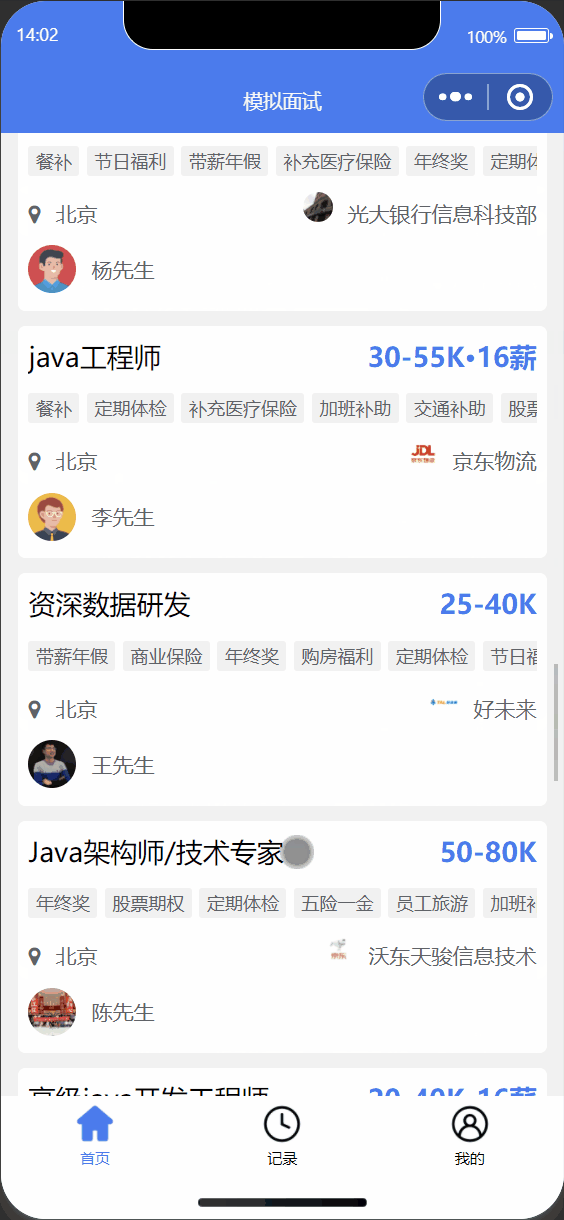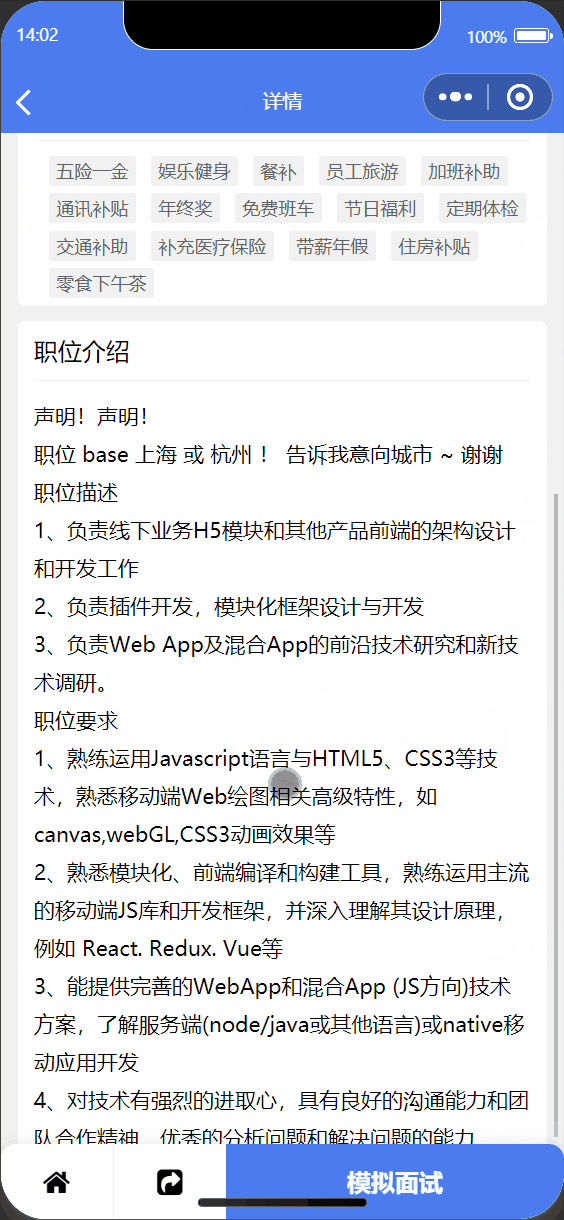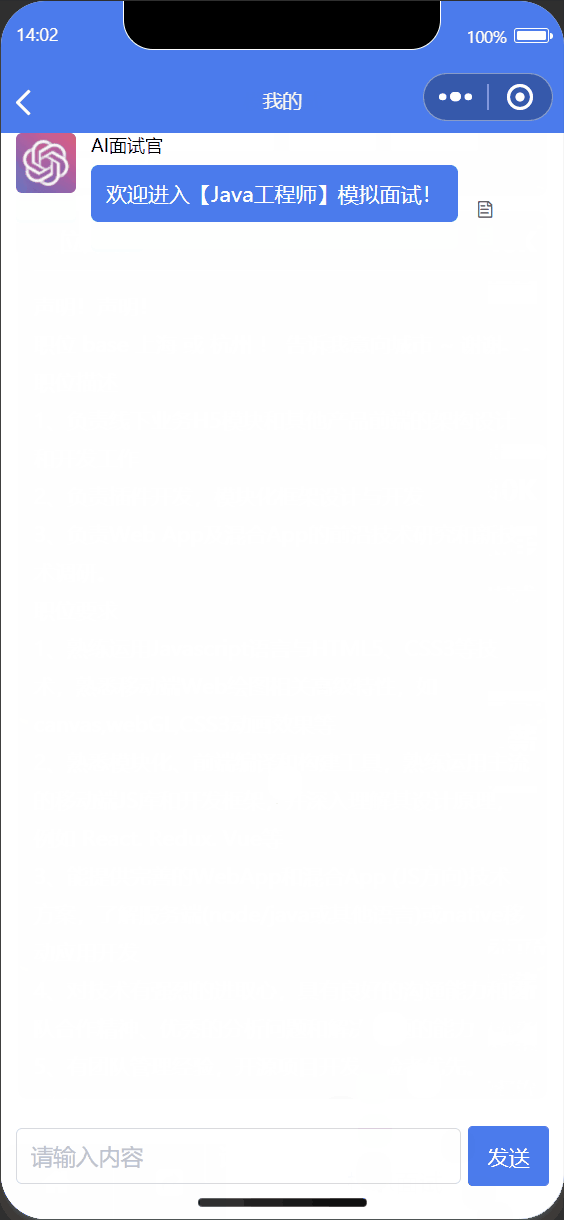
① 选择职位进行面试
② 根据岗位职责进行回答

一、需求背景
这两年IT互联网行业进入寒冬期,降本增效、互联网毕业、暂停校招岗位的招聘,各类裁员、缩招的情况层出不穷!对于这个市场来说,在经历了互联网资本的疯狂时代,现在各大需要的时候更多能实实在在挣钱的项目。就拿java开发工程师岗位来说,对于有多年工作经验的老鸟程序员,想要晋升跳槽,还是可以依靠自我的资源和主观能动性去谋求更高的发展!
可是对于校招生来说,好不容易学了几年的技术,正好准备要施展一方拳脚的时候,发现今年跟自己的竞争者跟多了,工作岗位却更少了。。。 先来看看时下的牛友们的面试题目。

虽说这些都是八股!但想要非常流利的答出来还是需要多加练习和背诵呀! 所以,我们更应该未雨绸缪,在具备硬实力的前提下,进一步提升我们的面试应答能力! 那么这个时候,我们就用ChatGPT来做一个根据不同公司岗位需求的AI面试助手!帮你提前熟悉面试环节!更稳拿到offer
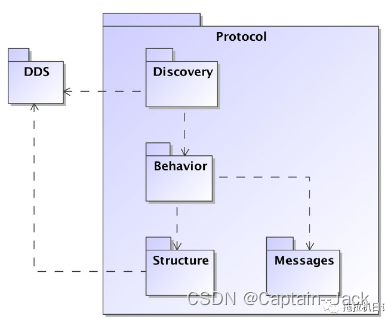
二、项目原理及架构
2.1 实现原理
(1)校招面试体验
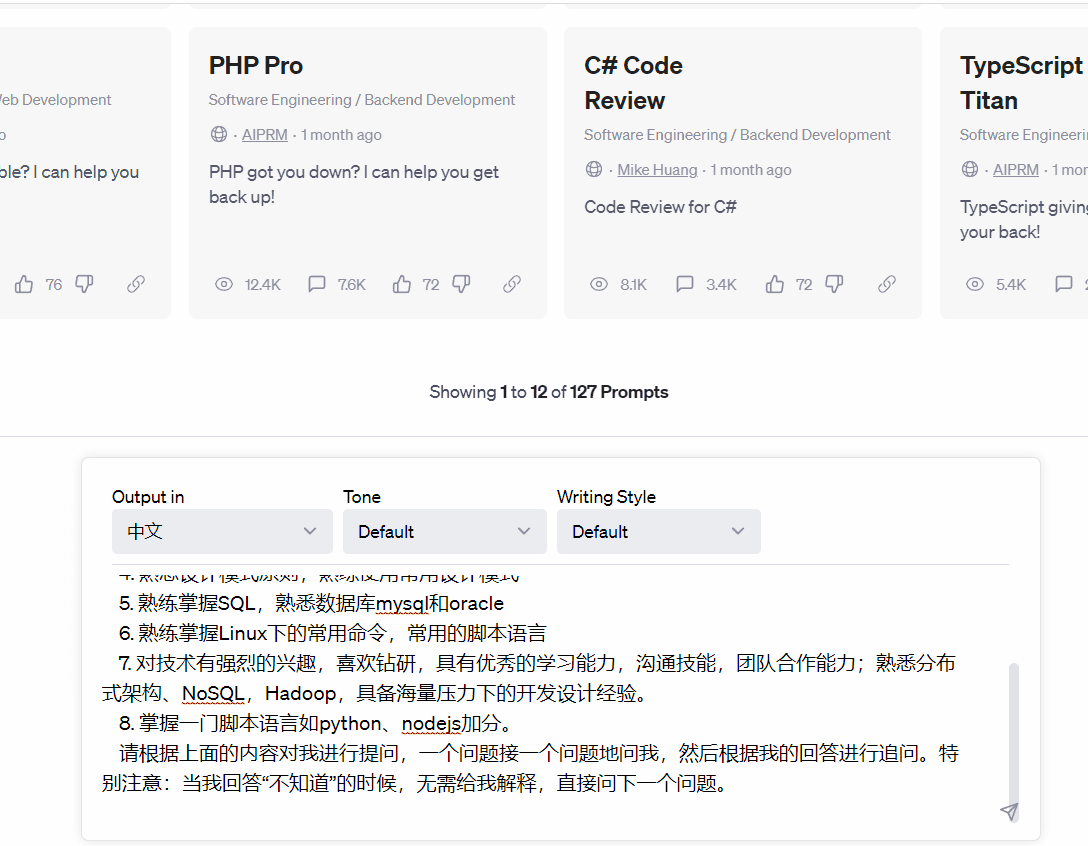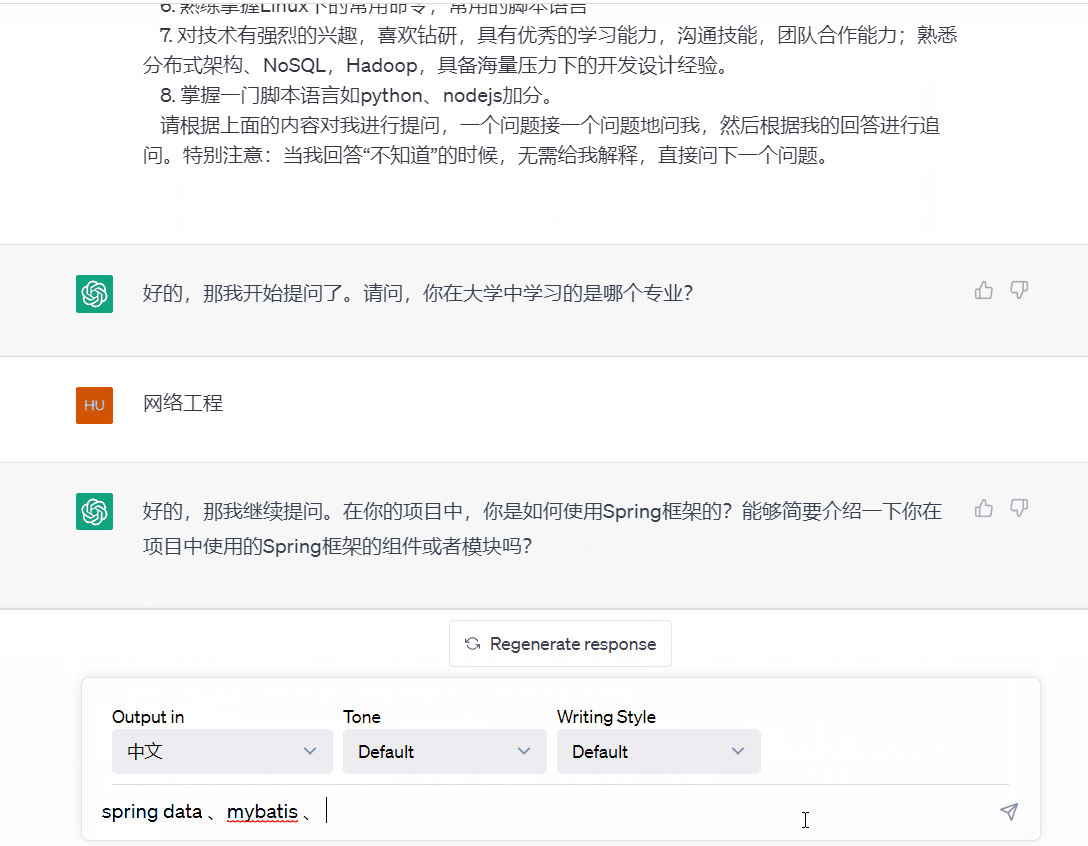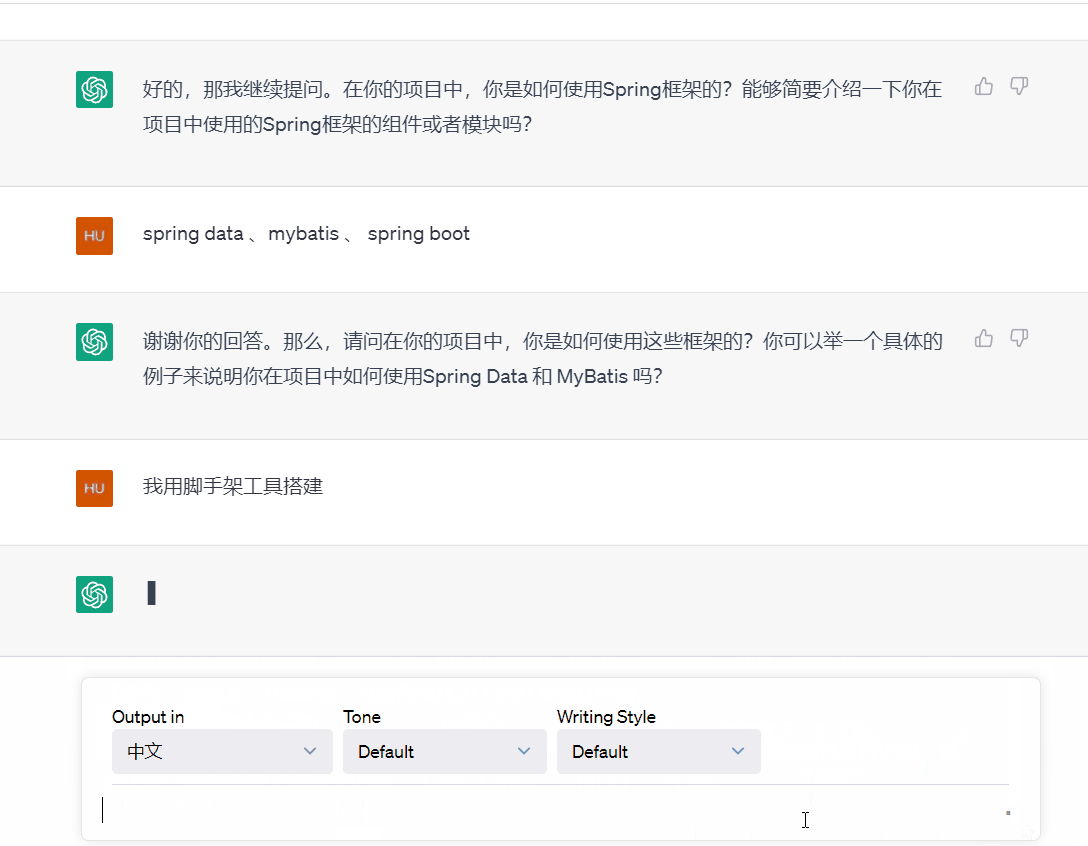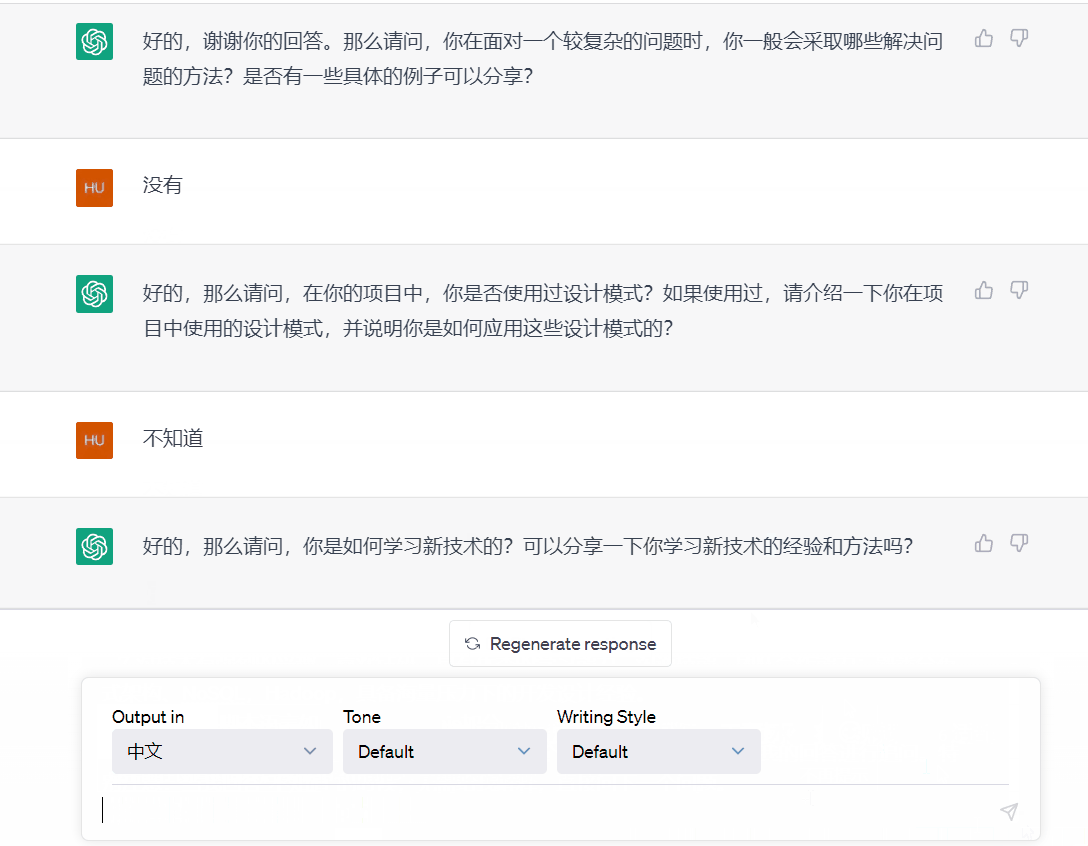
(2)社招面试体验
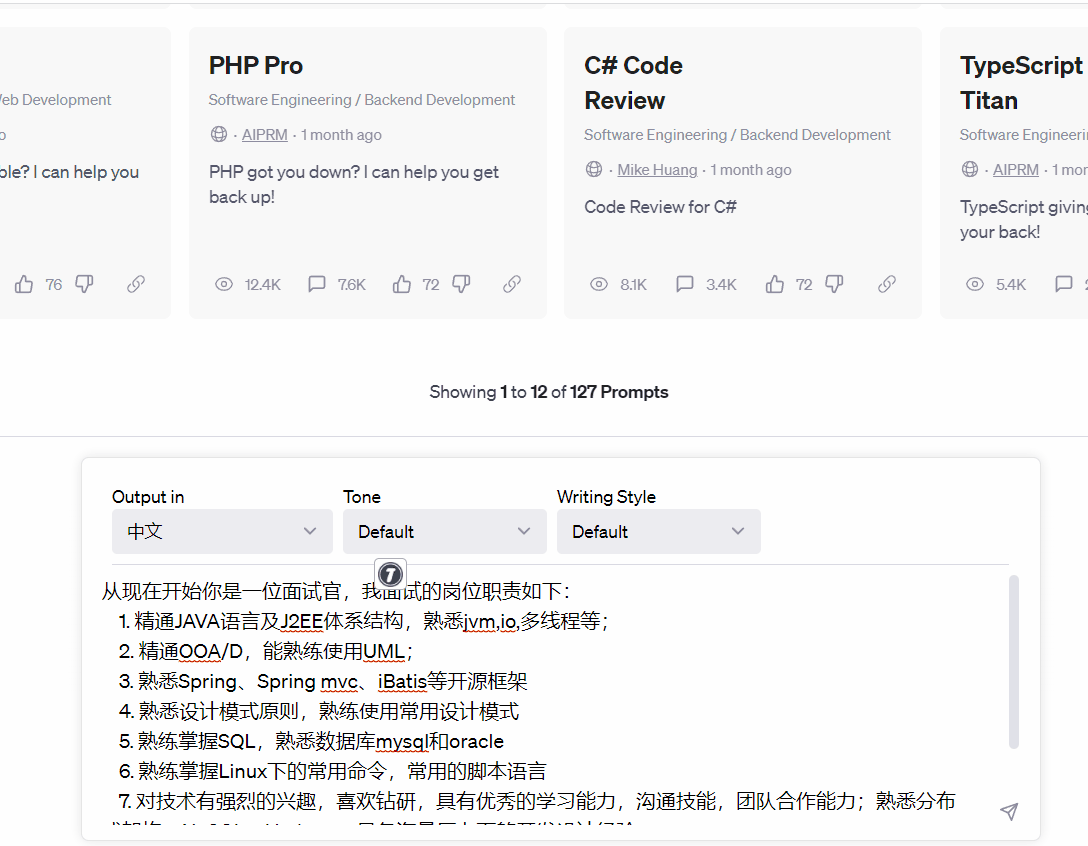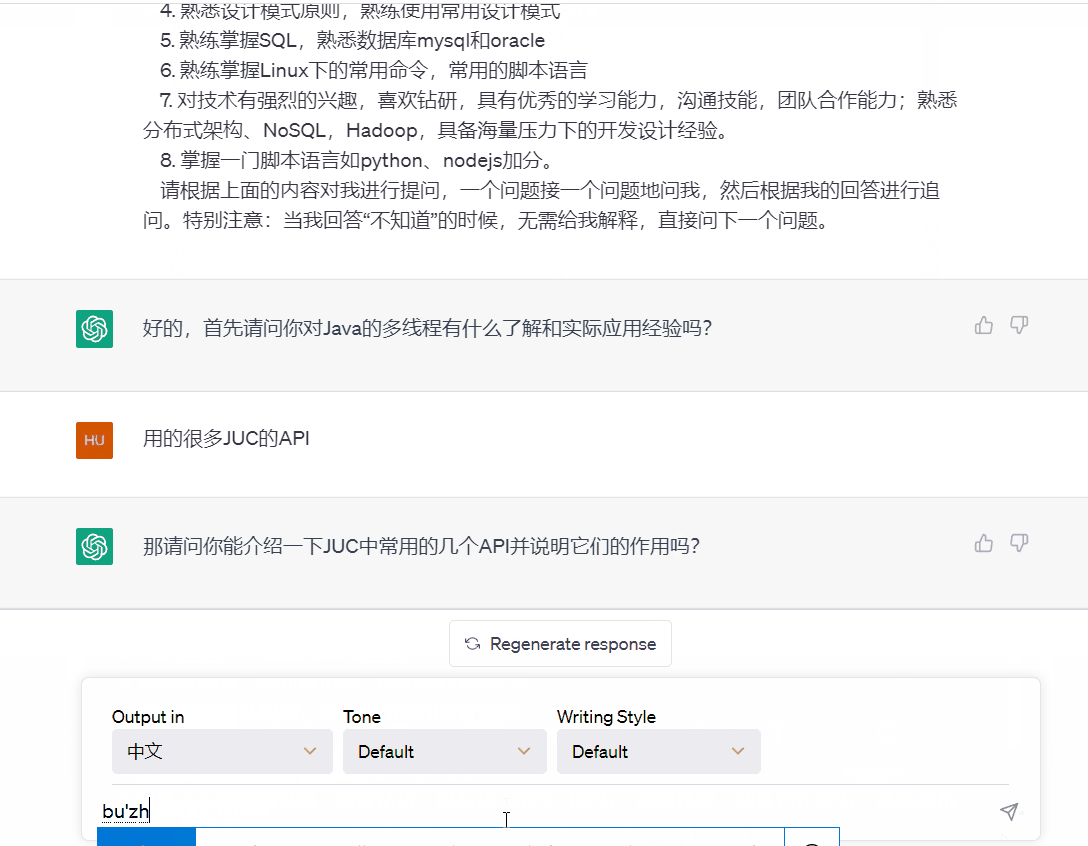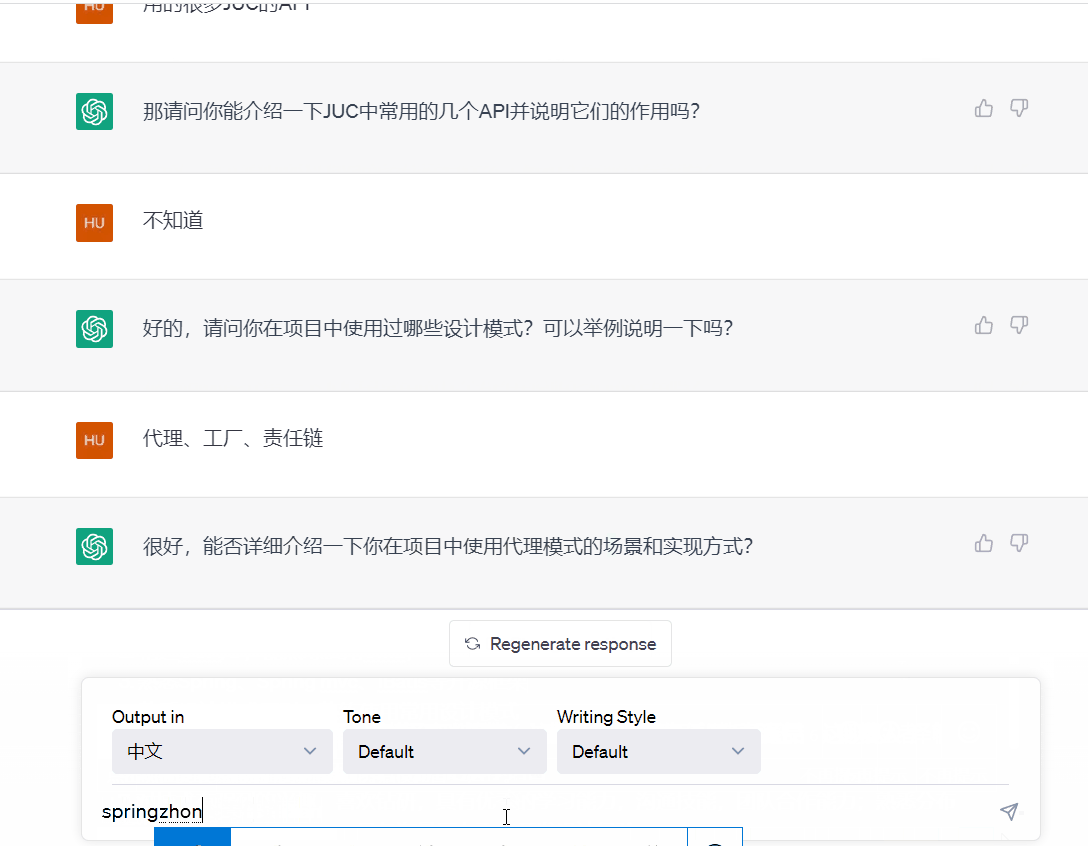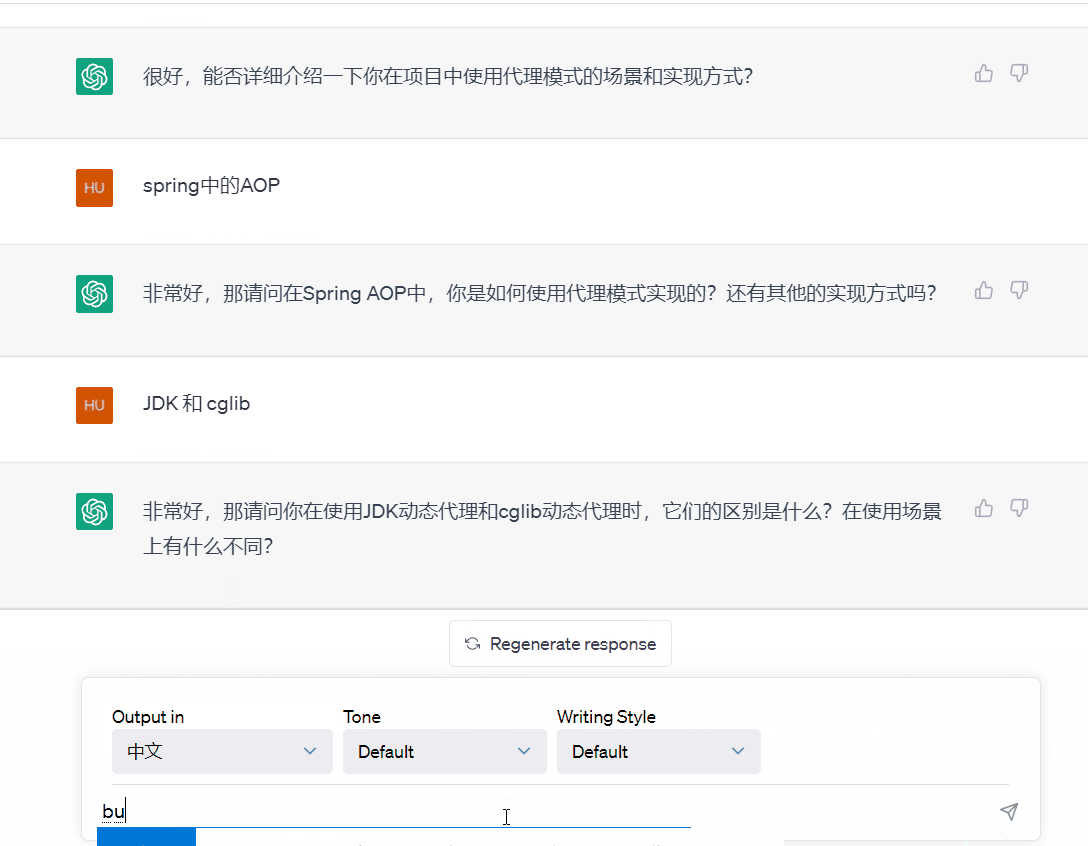
2.2 技术架构
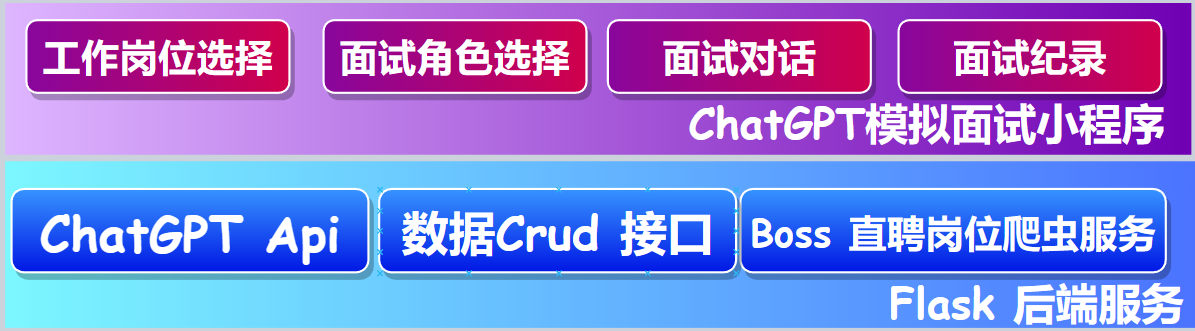
2.3 技术栈
| 模块 | 语言及框架 | 涉及的技术要点 |
|---|---|---|
| 小程序前端 | 基于VUE 2.0语法+Uni-app跨平台开发框架 | Http接口通信、Flex布局方式、uView样式库的使用、JSON数据解析、定时器的使用 |
| 小程序接口服务端 | Python + Flask WEB框架 | rest接口的开发、 ChatGPT API接口的数据对接 、 前后端websocket实时通信 |
2.4 数据交互原理
三、项目功能的实现
3.1 ChatGPT API的接入
要接入ChatGPT API,需要按照以下步骤进行操作:
- 注册一个账号并登录到OpenAI的官网:https://openai.com/
- 在Dashboard页面上,创建一个API密钥。在“API Keys”选项卡下,点击“Generate New Key”按钮。将生成的密钥保存好,以备后续使用。
- 选择所需的API服务,例如“Completion” API,以使用OpenAI的文本生成功能。
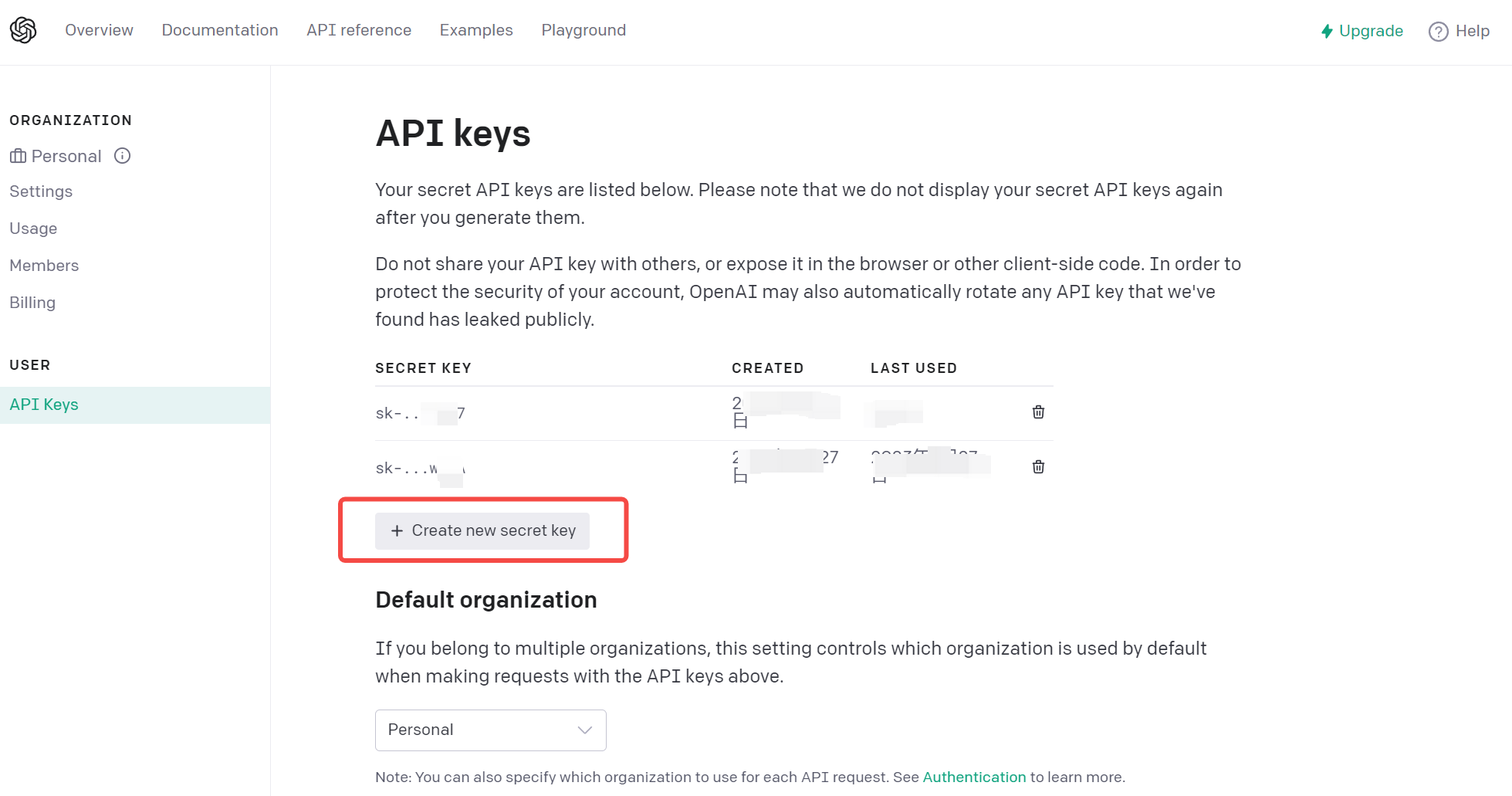
使用Python调用ChatGPT API实现代码如下:
- 方法一:使用
request库
import requests
import json
# 构建API请求
url = "https://api.openai.com/v1/engines/davinci-codex/completions"
headers = {"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY"}
data = {
"prompt": "Hello, my name is",
"max_tokens": 5
}
# 发送API请求
response = requests.post(url, headers=headers, data=json.dumps(data))
# 解析API响应
response_data = json.loads(response.text)
generated_text = response_data["choices"][0]["text"]
print(generated_text)
- 方式二:使用
openAI库
from flask import Flask, request
import openai
app = Flask(__name_
_)
openai.api_key = "YOUR_API_KEY_HERE"
@app.route("/")
def home():
return "Hello, World!"
@app.route("/chat", methods=["POST"])
def chat():
data = request.json
response = openai.Completion.create(
engine="davinci",
prompt=data["message"],
max_tokens=60
)
return response.choices[0].text
if __name__ == "__main__":
app.run()
3.2 小程序端设计与实现
| 岗位列表首页 | 面试记录 |
|---|---|
 | 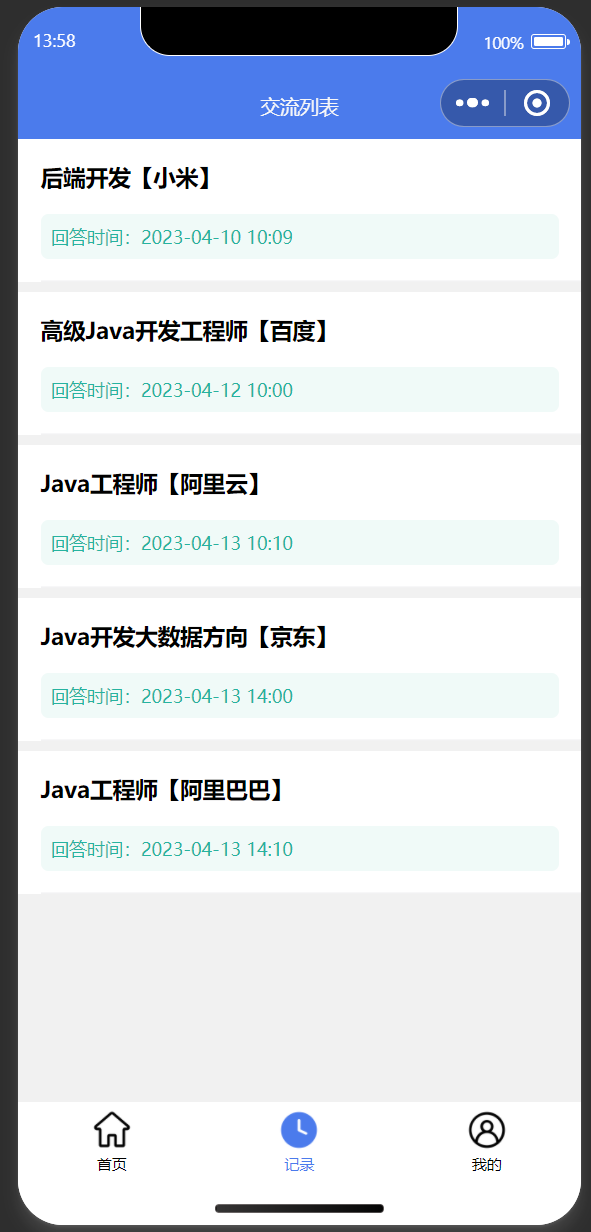 |
| 职位详情页面 | 面试聊天界面 |
|---|---|
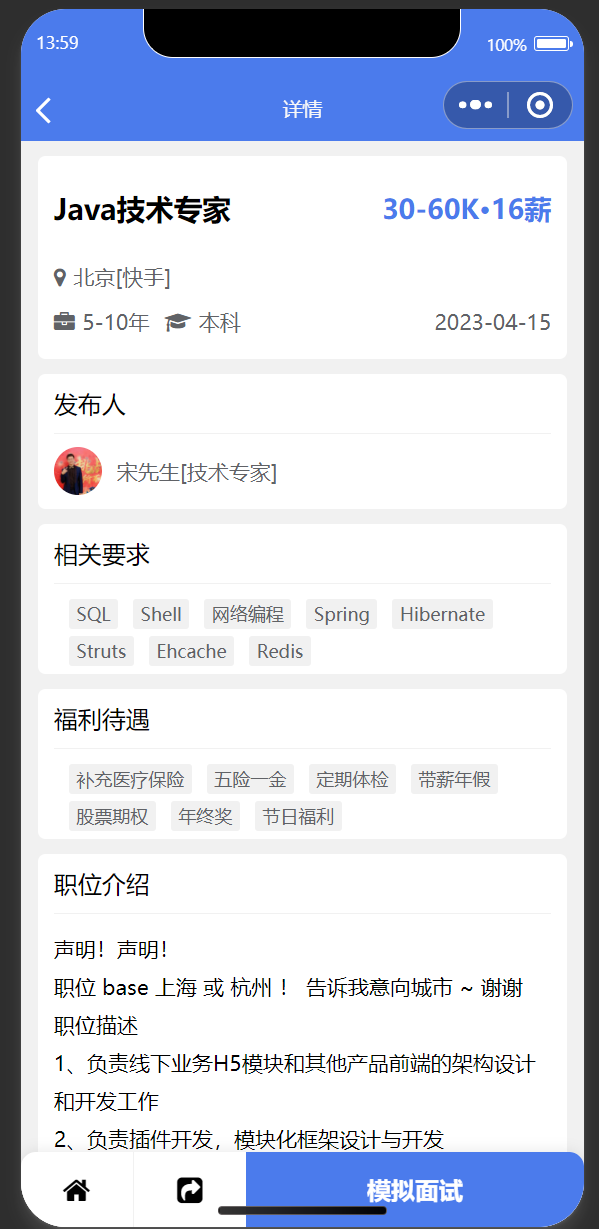 |  |
3.4 岗位爬虫以及数据交互功能设计与实现
import requests
from lxml import etree
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/jobs')
def get_jobs():
url = 'https://www.zhipin.com/job_detail/?query=java工程师&city=101010100&industry=&position='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299'
}
response = requests.get(url, headers=headers)
html = etree.HTML(response.content)
jobs = html.xpath('//div[@class="job-list"]/ul/li')
job_list = []
for job in jobs:
job_name = job.xpath('.//div[@class="job-title"]/text()')[0]
company_name = job.xpath('.//div[@class="company-text"]/h3/text()')[0]
salary = job.xpath('.//span[@class="red"]/text()')[0]
job_dict = {
'job_name': job_name,
'company_name': company_name,
'salary': salary
}
job_list.append(job_dict)
return jsonify(job_list)
if __name__ == '__main__':
app.run(debug=True)
- 首先,我们导入 Flask 和其他必要的库。然后我们定义了一个路由 /jobs,当我们请求这个路由时,会触发 get_jobs() 函数。
get_jobs() 函数中,我们首先定义了要爬取的页面 URL 和一个伪装成浏览器的 headers。然后我们发送了一个 GET 请求并得到了响应,使用 lxml 中的 etree 解析响应内容。接下来,我们使用 XPath 找到每个职位的信息块,并使用 xpath() 方法找到每个信息块中我们需要的信息(职位名称、公司名称、薪水)。最后,我们将每个职位的信息封装成一个字典,并将所有职位信息的字典存储在一个列表中。我们将这个列表转化成 JSON 格式并返回。
- 最后,我们在 main 函数中运行 Flask 应用,开启调试模式。
这个爬虫提供了一个 RESTful API 接口,可以使用 GET 请求获取所爬取的岗位列表数据。在浏览器中输入
http://localhost:5000/jobs就可以看到所获取到的数据。
四、推荐阅读
🥇入门和进阶小程序开发,不可错误的精彩内容🥇 :
- 《小程序开发必备功能的吐血整理【个人中心界面样式大全】》
- 《微信小程序 | 借ChatGPT之手重构社交聊天小程序》
- 《微信小程序 | 网易云+ChatGPT实现一个智能音乐推荐小程序》
- 《微信小程序 | 基于ChatGPT实现电影推荐小程序》
- 《吐血整理的几十款小程序登陆界面【附完整代码】》










![[2022 SP] Copy, Right? 深度学习模型版权保护的测试框架](https://img-blog.csdnimg.cn/img_convert/a92d3cb1785a4762013b2227dda689ed.gif)