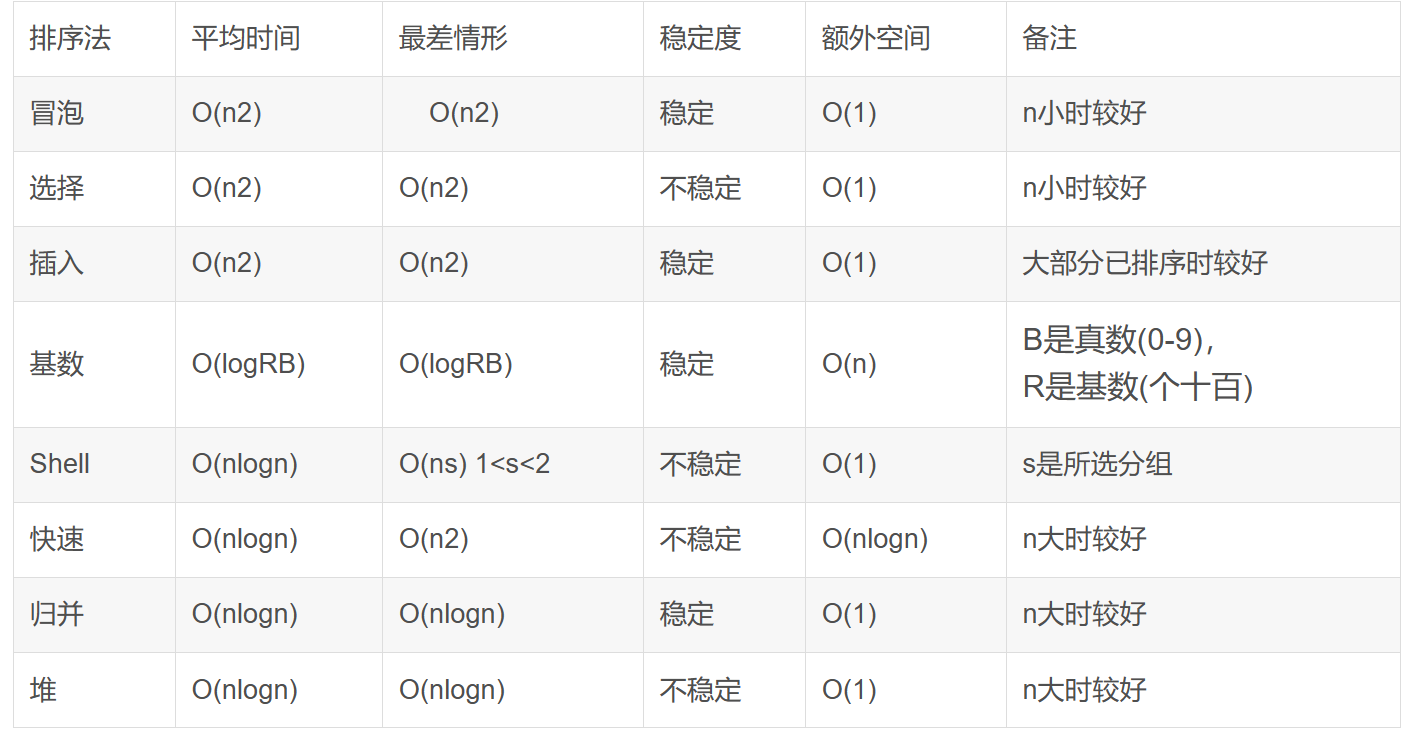
目录
- 摘要
- 本文方法
- 上下文着色
- Context Ensemble
- In-Context Tuning
- 消融实验
摘要
最近基于大规模数据的模型越来越火了,chat GPT以及seg everything,感觉后面很多像目标检测,图像恢复等等都会出现这种泛化能力强,基于大规模数据的模型出现
回到本文:
- 提出了SegGPT,用于分割上下文中所有内容的通用模型,将各种分割任务统一到一个通用上下文学习框架中,将不同类型的分割数据转换为相同格式的图像来适应不同类型的分割数据
- SegGPT的训练被表述为每个数据样本的随机颜色映射的上下文着色问题。目标是根据上下文完成不同的任务,而不是依赖于特定的颜色。
经过训练后,SegGPT可以在图像或视频中通过上下文推理执行任意分割任务。例如对象实例、素材、部件、轮廓和文本。
SegGPT在广泛的任务上进行评估,包括小样本语义分割、视频对象分割、语义分割和泛视分割。我们的结果表明,无论是定性还是定量,在分割域内和域外目标方面都有很强的能力。
代码链接
论文链接
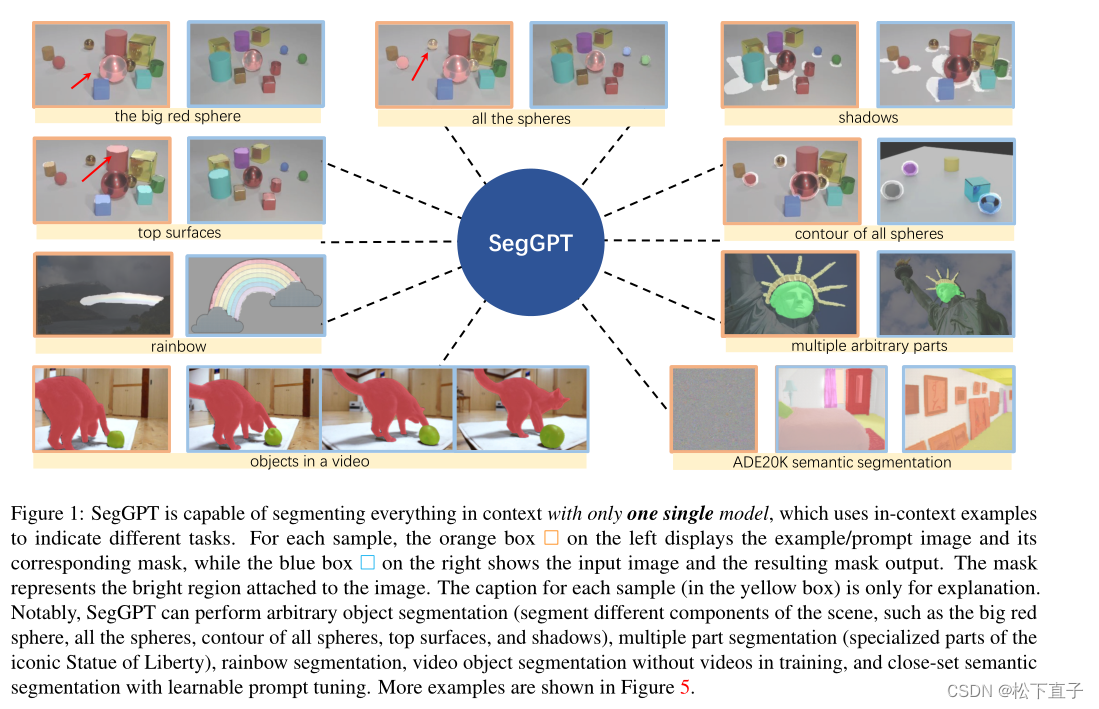
SegGPT能够仅使用一个模型就分割上下文中的所有内容,该模型使用上下文内的示例来指示不同的任务。对于每个示例,左边的橙色框显示示例/提示图像及其对应的MASK,而右边的蓝色框显示输入图像和由此产生的MASK输出。MASK表示附着在图像上的明亮区域。每个示例的标题(在黄色框中)仅用于解释。
值得注意的是,SegGPT可以执行任意对象分割(分割场景的不同组件,如大红色球体、所有球体、所有球体的轮廓、顶部表面和阴影)、多部分分割(标志性的自由女神像的专门部分)、彩虹分割、训练中没有视频的视频对象分割,以及具有可学习提示调准的近集语义分割。图5中显示了更多的示例。
本文方法
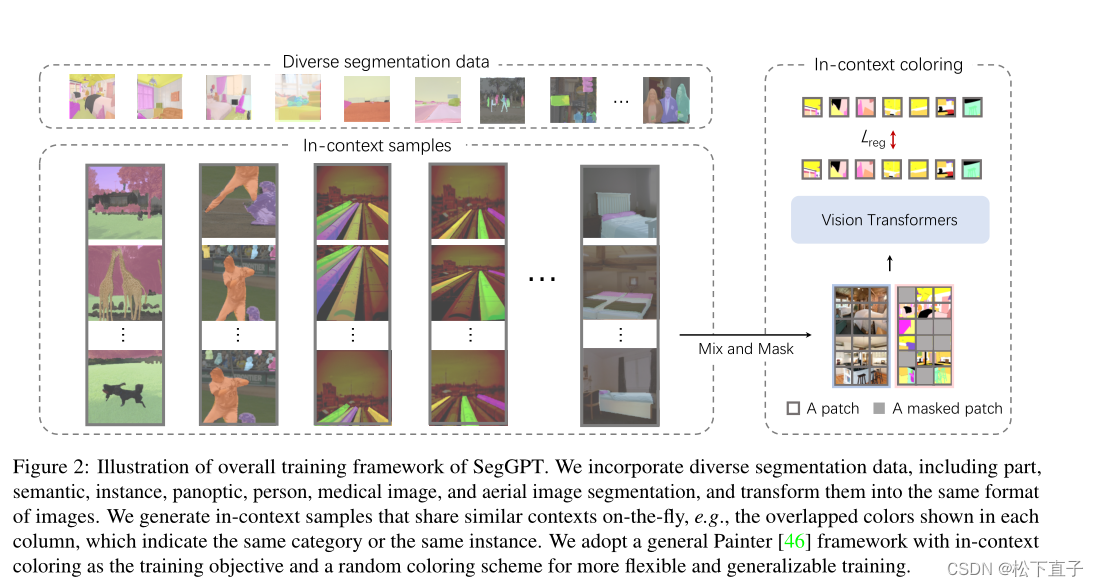
SegGPT整体训练框架:将不同的分割数据,包括部分、语义、实例、全景、人、医学图像和航空图像分割,并将其转换为相同的图像格式。生成动态共享相似上下文的上下文内样本,例如,每列中显示的重叠颜色,它们表示相同的类别或相同的实例。采用了一个通用的Painter框架,以上下文着色为训练目标,并采用随机着色方案,使训练更加灵活和泛化。
上下文着色
在传统的Painter框架中,每个任务的颜色空间都是预先定义好的。例如,对于语义分割,预先定义一组颜色,并为每个语义类别分配一个固定的颜色。从而得到模型只依靠颜色本身来确定任务,而不是利用片段之间的关系。
为了解决这一限制,本文提出了一种随机着色方案用于上下文着色。
首先随机采样与输入图像共享相似上下文的另一张图像,例如相同的语义类别或对象实例。
接下来,从目标图像中随机抽取一组颜色,并将每个颜色映射到一个随机的颜色。这将导致对应像素的重新着色。
结果,得到了两对图像,它们被定义为上下文内对。
此外,还引入了混合上下文训练方法,即使用混合实例训练模型。这涉及到用相同的颜色映射将多个图像拼接在一起。
然后,生成的图像被随机裁剪和调整大小,以形成混合上下文训练样本。通过这样做,模型学会关注图像的上下文信息,而不是仅仅依赖特定的颜色信息来确定任务。
Context Ensemble
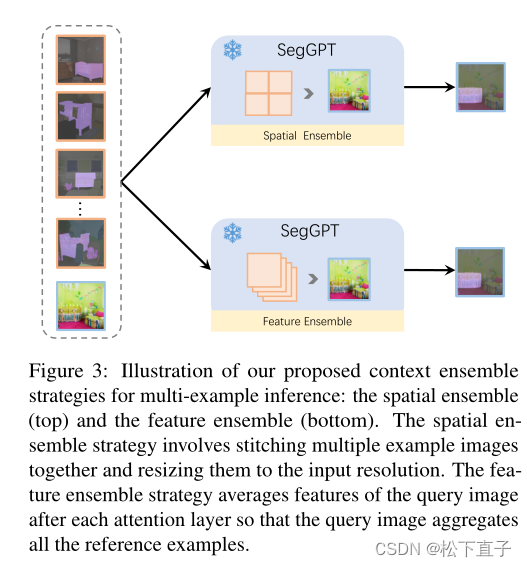
空间集成(上)和特征集成(下)。空间集成策略包括将多个示例图像拼接在一起,并根据输入分辨率调整它们的大小。特征集成策略将查询图像在每个注意层之后的特征进行平均,从而使查询图像聚合所有参考示例。
SegGPT支持上下文中的任意分割,例如,单个图像及其目标图像的示例。目标图像可以是单一颜色(不包括背景),也可以是多种颜色,例如,在一个镜头中分割出几个类别或感兴趣的对象。具体来说,给定一个要测试的输入图像,我们将其与示例图像拼接,并将其提供给SegGPT以获得相应的上下文内预测。
为了提供更准确和具体的上下文,可以使用多个示例。例如,可以使用相同语义类别的几个例子,或者视频中前面的帧。为了有效地利用SegGPT模型的多个示例,我们提出了两种上下文集成方法。一种是空间集成(Spatial Ensemble),将多个样本拼接在n × n的网格中,然后下采样到与单个样本相同的大小。该方法符合上下文着色的直觉,可以在几乎没有额外成本的情况下提取多个示例的语义信息。另一种方法是功能集成。多个示例在批处理维度上进行组合,独立计算,但查询图像的特征在每个注意层之后平均。通过这种方式,查询图像在推理期间收集关于多个示例的信息。
In-Context Tuning
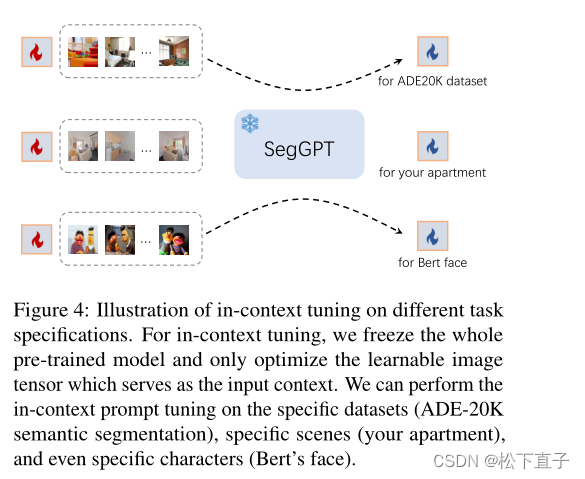
说明了不同任务规范上的上下文调优。对于上下文调优,我们冻结整个预训练的模型,只优化作为输入上下文的可学习图像张量。我们可以在特定的数据集(ADE-20K语义分割),特定的场景(你的公寓),甚至特定的人物(伯特的脸)上执行上下文内的提示调优
调优后,我们将学习到的图像张量取出,并将其用作特定应用的即插即用键。例如,给定一个具有固定对象类别集的数据集,例如ADE20K,我们可以为这个数据集训练一个定制的提示符,同时对模型的通用性没有损害。或者,我们可以优化一个特定场景的提示图像,例如,你的公寓,或一个特定的角色,例如,伯特的脸。这为广泛的应用提供了机会。
消融实验

![[2019.01.24]JNI经验积累](https://img-blog.csdnimg.cn/7516100b75f446b29da86e26a5bf453f.png)