文 | zzy
文章地址:
https://arxiv.org/abs/2304.05302v1
训练代码:
https://github.com/GanjinZero/RRHF
模型权重:
https://huggingface.co/GanjinZero/wombat-7b-delta
文章提出RRHF一种无须强化学习的对齐方法训练语言模型。该文章利用chatGPT或者GPT-4作为得分模型,开发了语言模型Wombat-7B和Wombat-7B-GPT4。Wombat-7B在Vicuna的部分测试集上(因没有GPT4 API,无法完整测试),可以达到ChatGPT 93% 的性能。其中GPT-4给ChatGPT的回复平均打了8.5分,而给Wombat-7B平均打了7.9分。
OpenAI的chatGPT理解多种多样的的人类指令,并且可以很好的应对不同的语言任务需求。chatGPT令人惊叹的能力来源于一种新颖的大规模语言模型微调方法:RLHF(通过强化学习对齐人类反馈)。RLHF方法不同于以往传统的监督学习的微调方式,该方法使用强化学习的方式对LLM进行训练。RLHF解锁了语言模型跟从人类指令的能力,并且使得语言模型的能力和人类的需求和价值观对齐。
当前研究RLHF的工作主要使用PPO算法对语言模型进行优化。PPO算法包含有众多的超参数,并且在算法迭代的过程中需要多个独立模型的相互配合,错误的实现细节都会导致不好的训练结果。

在和人类对齐的角度上,强化学习算法是不是必须的呢?来自阿里巴巴达摩院的作者们提出了不需要强化学习的基于排序的人类偏好对齐方法,它对不同语言模型生成的回复(可以是ChatGPT、GPT-4或者当前的训练模型)进行评分,并通过排名损失使它们与人类偏好对齐。不同于PPO,RRHF的训练过程可以利用人类专家或者GPT4的输出作为对比。RRHF训练好的模型可以同时作为生成语言模型和奖励模型使用。
Playgound AI的CEO Suhail表示这是最近最令他兴奋的一篇论文。
下图中对比了PPO算法和RRHF算法的区别。
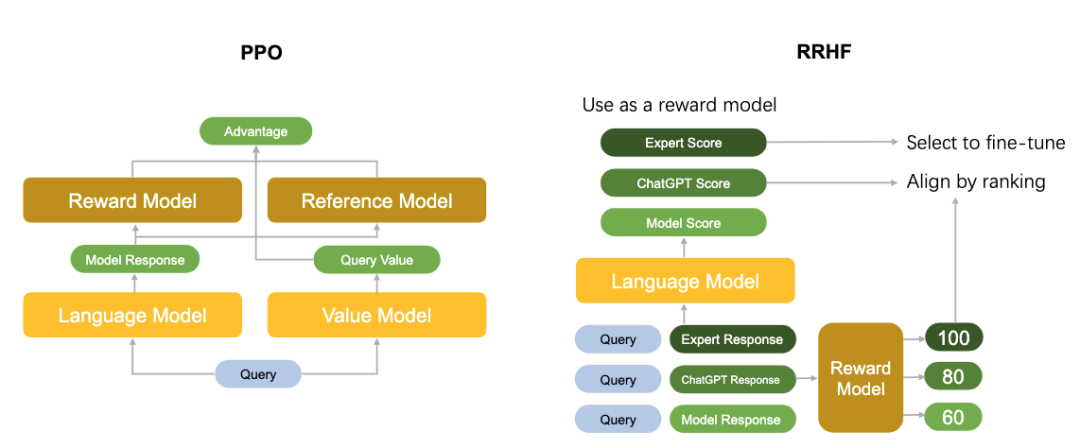
RRHF算法可以有效地将语言模型输出概率与人类偏好对齐,其训练思路非常简单,训练完成的模型有几个特点:
只需要1到2个模型。相比之下,PPO需要4个模型。
监督微调(SFT)可以看做是他的一种特殊形式,超参数很少
他可以同时直接作为一个语言模型和一个奖励模型使用
他以相当低的训练难度就可以拟合奖励模型的偏好,达到PPO的效果
袋熊Wombat作为新的开源预训练模型可以更好的与人类偏好对齐。作者们实验发现Wombat-7B拥有角色扮演和进行反事实推理等复杂的能力。作者也在Huggingface放出了WomBat的权重,来供大家尝试。以下是袋熊Wombat给大家的一个自我介绍。
Give an introduction of wombat
Wombat is a marsupial mammal native to Australia. It is typically found in mountainous areas and is known for its burrowing behavior. Wombats are typically around two feet long and weigh up to 30 pounds. They have a gray coat with white on their chests, and they have thick and powerful hind legs which they use for digging. Wombats are mostly nocturnal and eat a variety of insects, leaves, and grasses.

链接:
https://huggingface.co/GanjinZero/wombat-7b-delta
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群






![[Python工匠]输出②数值与字符串](https://img-blog.csdnimg.cn/a86269db5c6a4845a932ef1bb08117c3.png)