文章目录
- 一、HBase简介
- 1.1、HBase定义
- 1.2、HBase的存储结构
- 1.3、HBase基本架构
- 二、HBase Shell操作
- 2.1、基本操作
- 2.2、namespace
- 2.3、DDL
- 2.4、DML
一、HBase简介
1.1、HBase定义
HBase是一个开源的分布式NoSQL数据库,它是Apache Hadoop项目的一部分,使用Hadoop的HDFS作为底层存储。
1.2、HBase的存储结构
- Name Space
命名空间,类似于关系型数据库中的database概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是:hbase和default,hbase中存放的是HBase内置表,default表是用户默认使用的命名空间。
- Table
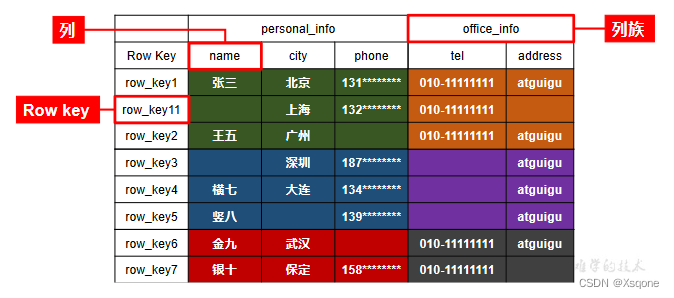
表格,HBase中的数据以表格的形式组织,每个表格由多行和多列组成,其中每行数据都有唯一的行键(Row Key)。
- Row Key
行键,是HBase表格中每行数据的唯一标识符,行键是一个字节数组,长度不限制。
- Cloumn Family
列族,是一组有相关性的列的集合,它们共享相同的前缀,并被存储在相同的物理位置上。在创建表格时必须指定列族,并为每个列族指定一个唯一的名称,通常以字符串形式表示。
- Cloumn Qualifier
列限定符,是列族中每个列的唯一标识符,它们共享相同的列族前缀,以字节数组的形式存储。
- Cell
单元格,是表格中的最小数据单元,它由行键、列族、列限定符和时间戳四个维度组成,时间戳制定了单元格数据的版本信息。
- Version
版本,每个单元格可以存储多个版本的数据,每个版本都有一个时间戳,HBase默认按照时间戳降序排列版本,最新版本在最前面。
- Block
块,HBase中的数据存储都是按照块进行的,每个块包含多个行,每个块的大小由HBase的配置参数决定。
HFile块的大小默认值为:64MB。可以通过HBase配置文件中的“hbase.regionserver.hstore.blockingStoreFiles”参数进行配置,该参数的值表示每个存储区域中允许的最大HFile块数量。
还可通过Hadoop配置文件中的“hdfs.blocksize”参数来进行调整HFile块大小。
关于Table、Cloumn Family、Cloumn Qualifier、Row Key在表中结构如图:
1.3、HBase基本架构
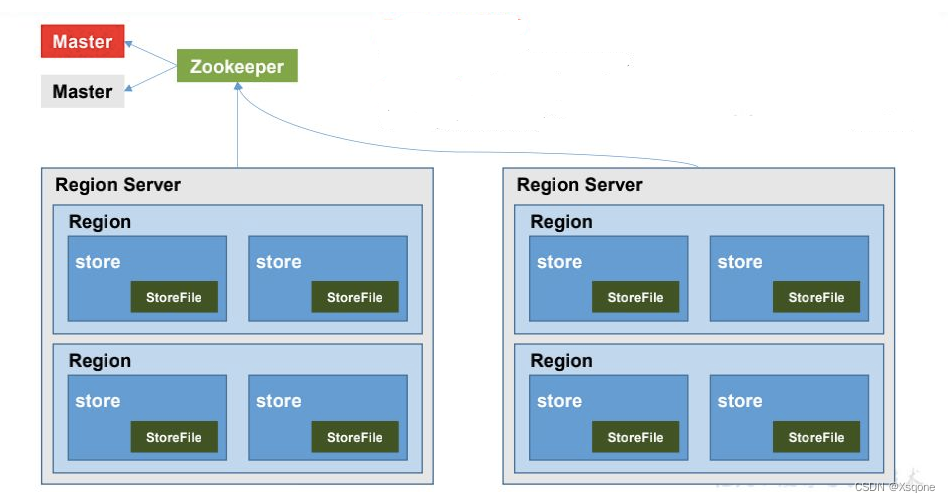
- HMaster:HBase的主节点,负责管理元数据信息和协调整个HBase集群的操作。HMaster通常运行在一个单独的节点上,会跟踪所有的RegionServer,处理RegionServer的加入、退出和故障转移等事件,并管理HBase表的创建、删除、分裂和合并等操作。
- ZooKeeper:HBase集群的协调服务,用于协调分布式计算和存储节点的状态信息和元数据。ZooKeeper提供了分布式锁、选举和协调等基础服务,可以用于实现HBase集群的高可用性和可靠性。
- HRegionServer:HBase的数据节点,负责存储和管理HBase表的数据,每个HRegionServer通常管理多个Region,每个Region负责存储表中的一部分数据。HRegionServer接收来自客户端的读写请求,处理请求后返回结果。若是其中一个HRegionServer发生故障,它所管理的Region会被重新分配到其他的RegionServer上,以确保数据的可用性和可靠性。
- HRegion:HBase表的基本单元,负责存储表中的一部分数据。每个Region都是一个连续的行键范围,可以包含多个HFile。当表数据增加或者Region的大小到达一定阈值时,Region会自动进行拆分或者合并,已实现负载均衡和数据的平衡分布。
- HStore:HRegion的物理存储单元,用于管理单个Region的数据存储和读写操作,每个Region都由一个或多个HStore组成,每个HStore实际上是一个Map,用于存储Region中的一部分数据。HStore中的数据以列族为单位进行组织,不同的列族存储在不同的HStore中,每个列族又包含多个列。在HStore中,数据以字节数组的形式进行存储,支持按行键和列进行快速随机访问。
- StoreFile:StoreFile是HBase的存储文件格式,用于存储每个HStore中的数据。每个StoreFile都包含多个块(Block),每个块都包含若干行数据。每个StoreFile都对应一个HFile。
二、HBase Shell操作
2.1、基本操作
# 进入HBase客户端
hbase shell
# 查看帮助命令
help
# 查看命令如何使用
help '具体命名'
2.2、namespace
# 查看所有的命名空间
list_namespace
# 查看xsqone下的表
list_namespace_tables 'xsqone'
# 创建命名空间xsqone
create_namespace 'xsqone'
# 删除命名空间xsqone
drop_namespace 'xsqone'
2.3、DDL
# 在xsqone创建表student,列族为'studentInfo','schoolInfo'
create 'xsqone:student','studentInfo','schoolInfo'
# 查看表详情
desc/describe 'xsqone:student'
# 禁用student表
disable 'xsqone:student'
# 启用student表
enable 'xsqone:student'
# 查看student表是否禁用或启用
is_enabled 'xsqone:student' (true为启用,false为禁用)
is_disabled 'xsqone:student' (true为禁用,false为启用)
# 删除student表(前提需先禁用)
disable 'xsqone:student'
drop 'xsqone:student'
# 新增列族familyInfo
alter 'xsqone:student','familyInfo'
# 删除列族familyInfo
alter 'xsqone:student',{NAME=>'familyInfo',METHOD=>'delete'}
# 更改schoolInfo列族存储限制
alter 'xsqone:student',{NAME=>'schoolInfo',VERSIONS=>3}
2.4、DML
# 写入数据
put 'xsqone:student','row1','studentInfo:name','zs'
put 'xsqone:student','row1','studentInfo:age','18'
put 'xsqone:student','row1','schoolInfo:name','qh'
put 'xsqone:student','row1','schoolInfo:address','bj'
# 修改数据也是使用put,是进行覆盖
# 修改schoolInfo:name
put 'xsqone:student','row1','schoolInfo:name','bd'
# 读取数据,可以使用get和scan两种方式来读取
# get一条数据
get 'xsqone:student','row1'
# get具体列
get 'xsqone:student','row1',{COLUMN=>'studentInfo:name'}
# scanscan 是扫描数据,能够读取多行数据,不建议扫描过多的数据,推荐使用 startRow 和stopRow 来控制读取的数据,默认范围左闭右开
scan 'xsqone:student',{COLUMNS=>'studentInfo:name',STARTROW=>'rowkey2',STOPROW=>'rowkey4'}
# 扫描value为q的行列(模糊查询)
scan 'bigdata:student',FILTER=>"ValueFilter(=,'substring:q')"
# 扫描value为bj的行列
scan 'bigdata:student',FILTER=>"ValueFilter(=,'binary:bj')"
# ColumnPrefixFilter(列前缀过滤器)列以birth开头的
scan 'bigdata:student',FILTER=>"ColumnPrefixFilter('add')"
# 删除数据
# delete表示删除一个版本的数据,即为 1 个 cell,不填写版本默认删除最新的一个版本
delete 'xsqone:student','row1','schoolInfo:name'
# deleteall 表示删除所有版本的数据,即为当前行当前列的多个 cell
deleteall 'xsqone:student','row1','schoolInfo:name'