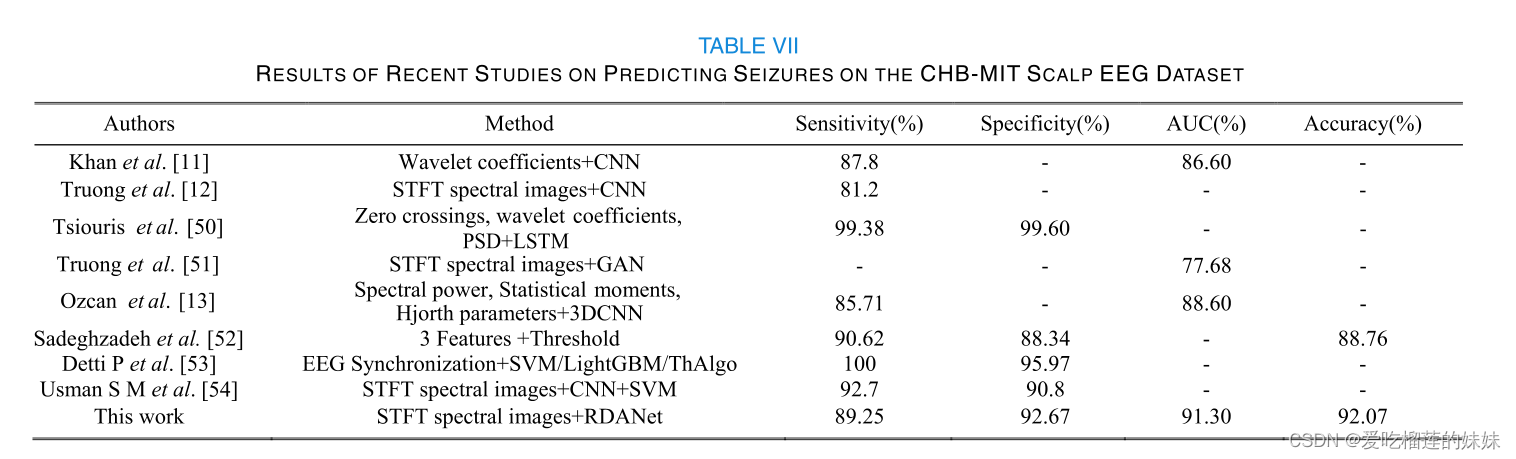
1. 7 Eureka注册中心
1.7.1 远程调用的问题
- 地址信息获取:服务消费者如何获取服务提供者的地址信息(不能每次都写死): URL:http://localhost:8081/user/"+order.getUserId()
- 多选一:如果有多个服务提供者,消费者如何进行选择
- 监测健康状态:消费者如何获知提供者的健康状态
1.7.2 eureka原理
-
地址信息获取:
1)服务提供者启动时,向Eureka注册自己的信息
2)Eureka保存这些信息
3)消费者根据服务名向Erueka拉去提供者信息 -
多选一:
1)使用负载均衡技术,从多个服务列表中,选择一个 -
监测健康状态
1)服务提供者每隔30s会向Eureka发送自己的心跳数据,即是否正常工作
2)如果不工作了会从保存的服务列表中剔除
3)消费者根据最新的服务列表能够或者服务者健康状况

1.7.3 搭建EurekaServer
1)创建项目:引入spring-cloud-starter-netflix-eureka-server的依赖
//服务端依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
2)编写启动类,添加@EnableEurekaServer注解
@EnableEurekaServer //自动装配Eureka注解
@SpringBootApplication //SpringBoot启动类注解
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class,args);
}
}
3)添加application.yml文件,并编写如下配置
server:
port: 10086 #注册的端口
spring:
application:
name: eurekaserver #服务注册名字
eureka:
client:
service-url: #服务注册访问地址
defaultZone: http://127.0.0.1:10086/eureka/
1.7.4 服务注册:注册user-service
- 引入依赖:在user-service项目引入spring-cloud-starter-netflix-eureka-client的依赖
//客户端依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
- 添加配置:在application.yml文件,编写下面的配置
spring:
application:
name: userservice
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka/
- 多服务注册(同一个服务,但是多端口,模拟多服务架构)
1)如果直接复制一个服务,会发生冲突,故需要更改下VM选项:-Dserver.port=8082

1.7.4 服务注册:注册order-service
order-service虽然是消费者,但与user-service一样都是eureka的client端,同样可以实现服务注册:
- 引入依赖:在order-service项目引入spring-cloud-starter-netflix-eureka-client的依赖
//客户端依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
- 添加配置:在application.yml文件,编写下面的配置
spring:
application:
name: orderservice
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka/
1.7.6 order-service完成服务拉取(能够自助选择服务)
服务拉取是基于服务名称获取服务列表,然后在对服务列表做负载均衡
- 修改orderService中的代码,变更url路径
String url = "http://userservice/user/" + order.getUserId();
- 在orderService启动类中,添加的resttemplate远程调用上添加负载均衡注解;主要为了标记该调用发起的请求会被ribbon拦截并操作
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
1.7.7 总结
 ## 1.8 Ribbon 在需要拦截的启动类上面添加注解:@LoadBalanced ### 1.8.1 负载均衡原理
## 1.8 Ribbon 在需要拦截的启动类上面添加注解:@LoadBalanced ### 1.8.1 负载均衡原理

1)order-serice发起请求:http://userservice/use/1
2)获取url中服务的id(userservice)
3)在Eureka中拉去userservice
4)返回服务列表(8081/8082)
5)服务负载均衡策略:IRule
6)选择某个服务:8081
7)修改原来的url,发起请求
8)请求服务8081
1.8.2 负载均衡策略
 1)RoundRobinRule:简单轮询 2)ZoneAviodanceRule:使用Zone对服务器分配类,在做轮询 3)RandomRule:随机选择服务器 ### 1.8.3 负载均衡配置 总共有两种方式:代码方式和更改配置文件方式
1)RoundRobinRule:简单轮询 2)ZoneAviodanceRule:使用Zone对服务器分配类,在做轮询 3)RandomRule:随机选择服务器 ### 1.8.3 负载均衡配置 总共有两种方式:代码方式和更改配置文件方式
- 代码方式:在order-service中的OrderApplication类中,定义一个新的IRule:
@Bean
public IRulerandomRule(){
return new RandomRule();
}
- 配置文件方式:在order-service的application.yml文件中,添加新的配置也可以修改规则:
userservice:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule#负载均衡规则
1.8.4 饥饿加载
Ribbon默认是采用懒加载,即第一次访问时才会去创建LoadBalanceClient,请求时间会很长。
而饥饿加载则会在项目启动时创建,降低第一次访问的耗时,通过下面配置开启饥饿加载:
ribbon:
eager-load:
enabled: true # 开启饥饿加载
clients:userservice # 指定对userservice这个服务饥饿加载
1.8.5 总结
- Ribbon负载均衡规则
1)规则接口是IRule
2)默认实现是ZoneAvoidanceRule,根据zone选择服务列表,然后轮询 - 负载均衡自定义方式
1)代码方式:配置灵活,但修改时需要重新打包发布
2)配置方式:直观,方便,无需重新打包发布,但是无法做全局配置 - 饥饿加载
1)开启饥饿加载
2)指定饥饿加载的微服务名称