目录
- 前言
- 一.MASK R-CNN网络
- 1.1.RoIPool和RoIAlign
- 1.2.MASK分支
- 二.损失函数
- 三.Mask分支预测
前言
在介绍MASK R-CNN之前,建议先看下FPN网络,Faster-CNN和FCN的介绍:下面附上链接:
- R-CNN、Fast RCNN和Faster RCNN网络介绍
- FCN网络介绍
- FPN网络介绍
在之前介绍数据集的时候我们讲过图像分割分为语义分割和实例分割,看下面两幅动图展示:
语义分割:

实例分割:

今天介绍的MASK R-CNN是针对实例分割这种情况的,我们主要从以下几个部分进行讲解:
- MASK R-CNN网络
- RoiAlign
- Mask分支(FCN)
- 损失函数
- Mask分支预测
一.MASK R-CNN网络
先来看下MASK R-CNN网络结构:

从上面的网络结构可以看出,前面的RolAlign+CNN就是前面的Faster-RCNN结构(实际中Faster-RCNN使员的也是RoIAlign,并不是RoIPool)。后面一个卷积层就是自己可以并联的的网络结构用于分割,关键点检测都行。

下面我们来看下MASK分支的结构,跟FCN非常像,主要有两种结构:不带FPN特征金字塔结构和带有FPN的,我们经常使用的也是右边这个带有FPN的。

1.1.RoIPool和RoIAlign
上面讲到在MASK R-CNN中吧之前Faster R-CNN中的RoIPool替换成了RoIAlign层,为什么呢?因为在RoIPool中涉及两次取整的操作,会导致定位产生偏差。
这里我们再来看下RoIPool操作:

从上面的图中可以看出,RoIPool可能会涉及两次取整操作,我们以目标检测的标注框为例解释,第一次是在标注框大小投影到最终网络输出特征层进行了一次四舍五入;第二次是在maxpooling的时候,因为投影后的框不能保证能够均分,还会涉及到一次四舍五入。

相比于RoIPool,通过上面的图可以看到,第一次投影的时候RoIAlign并不会涉及到四舍五入的操作,最终计算的值是多少就是多少;第二次池化的时候直接均分第一次投影得到的特征矩阵,找到中心点坐标和周围最近的几个点(也可以采用几个采样点计算均值,这里以一个为例),直接计算双线性差值,也不会涉及到四舍五入的操作。
通过上面的对比可以看出RoIAlign并不会涉及到任何的取整操作,所以他的定位也更加的准确。
1.2.MASK分支
上面我们讲MASK分支有两种,带FPN和不带FPN,我们最常用的是下面这个带有FPN的结构:

注意1:
上图中有两个RoI,上面一个对应的是Faster R-CNN的预测器的分支,他所用的RoIAlign跟MASK分支采用的RoIAlign并不一样,即两者不共用一个RoIAlign,一个输出的大小是
7
×
7
7\times 7
7×7,一个是
13
×
13
13\times13
13×13。因为分割要求保留更多的信息,池化比较大的话会损失比较多的信息。下面一个MASK分支的最后输出
28
×
28
×
80
28\times28\times80
28×28×80的意思是对每一个类别(COCO通常使用的都时候80个类别的)都预测一个
28
×
28
28\times28
28×28大小的蒙版。
在MASK R-CNN中对预测的Mask和class进行解耦,什么意思?FCN对每个像素,每个类别都会预测一个类别概率分数,最后会对每个像素沿着channel方向进行softmax处理,处理之后就能能得到每个像素归属每个类别的概率分数,所以不同类别之间是存在竞争关系的。通过sofmax之后,每个像素在channel方向概率只和等于1,对于某个类别的概率分数大的话,那么其他类别的概率分数就会小。所以他们之间存在竞争关系,即AMSK与class是耦合的状态。那么在MASK R-CNN中是怎么对mask与class进行解耦的呢?刚才说了在mask分支中对每个预测类别都会预测一个蒙版,但是不会针对每一个数据沿着他的channel方向做softmax处理,而是根据faster r-cnn分支预测针对该目标的类别信息将mask分支中针对该类别的蒙版信息提取出来使用。这段话听起来有点绕,晦涩难懂,多理解一下。核心就是mask分支现在不用自己的分类信息了,把faster r-cnn的分类信息拿过来当做自己的。
注意2:
训练网络的时候输入MASK分支的目标是由RPN提供的,即proposals,需要注意的是输入给mask分支的proposals全都是正样本,正样本是在Faster R-cnn分支进行正负样本匹配的时候得到的,即将proposals输入到faster r-cnn分支,在fasterr-cnn分支中会进行正负样本的匹配就会得到每个proposal到底是正样本还是负样本以及这个proposal他所对应的GT类别是什么,将得到的所有正样本传递给Mask分支。
预测的时候输入mask分支的目标是由faster-cnn提供,即最后预测的目标边界框。RPN提供的目标边界框可能并不准确,对于一个目标,RPN可能提供了多个目标边界框,我们刚说了提供给mask分支的proposals都是正样本,所以一定会存在交集,这些proposals都可以提供给mask分支进行训练,但是在最终预测的时候是直接使用的Faster R-CNN分支的输出,因为预测的时候只需要最准确的目标边界框即可,可能就一个目标,将这个目标提供给MASK分支即可,并且在Faster RCNN中,通过NMS处理之后是能过滤掉很多重合在一起的目标,最终送入mask分支的目标也就少一些,目标少一些计算量就会下降。
二.损失函数
损失函数总共三项,就是在Faster R-cnn的基础上加上了mask分支所对应的损失。
L
o
s
s
=
L
r
p
n
+
L
f
a
s
t
r
c
n
n
+
L
m
a
s
k
Loss =L_{r p n}+L_{fast_rcnn }+L_{mask }
Loss=Lrpn+Lfastrcnn+Lmask
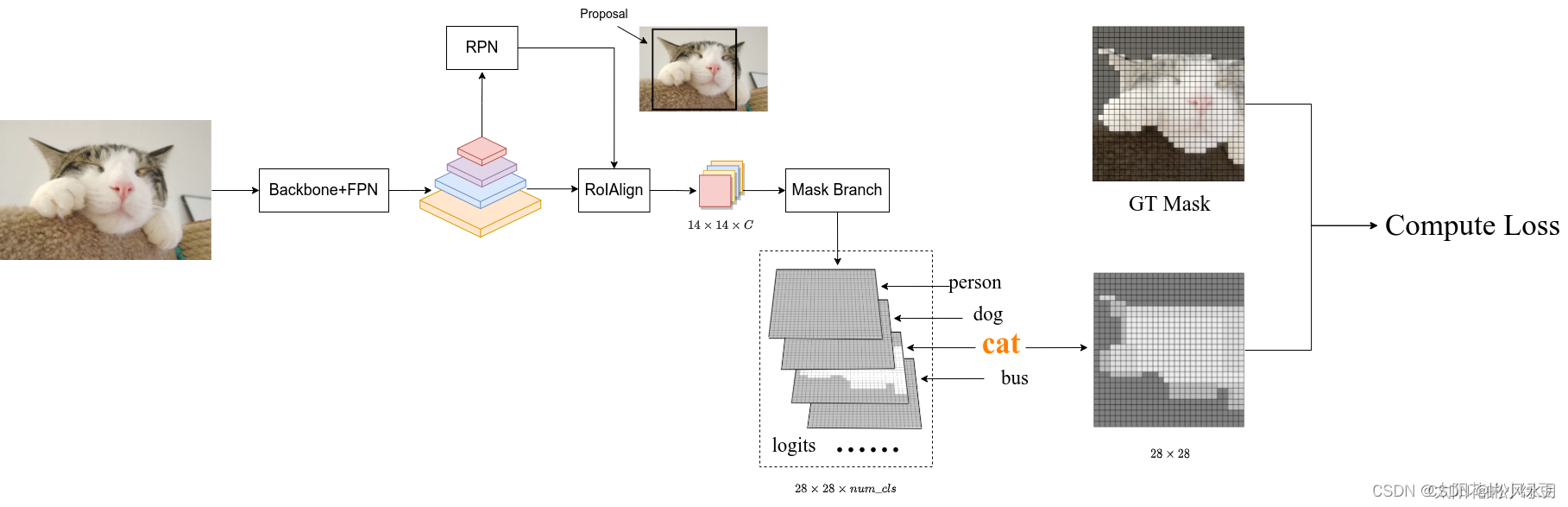
如何计算mask分支的损失,这里我们借用一篇博主画的图,如上图所示,输入一张图片,经过backbone和fpn得到不同采样率的特征层,接着通过RPN就能生成一系列的proposals,假设通过RPN得到了一个Proposal(图中黑色的矩形框),将proposal输入给RoIAlign,就能根据proposal的大小在对应特征层上进行裁剪得到对应的特征(shape为
14
×
14
×
C
14\times14\times C
14×14×C),接着通过Mask Branch预测每个类别的Mask信息得到图中的logits(logits通过sigmoid激活函数后,所有值都被映射到0至1之间)。上面讲了训练的时候输入mask的分支的proposal是由RPN提供的,并且这些proposal都是正样本,这些正样本是通过Fast R-CNN分支正负样本匹配过程知道的,对应图上的proposal通过faster rcnn时,在正负样本匹配的时候可以得到对应的GT是猫,所以将logits中对应类别猫的预测mask(shape为
28
×
28
28\times28
28×28)提取出来。需要注意的是这里的logits虽然没有在通道上做softmax处理,但是会进行sigmoid激活,也就是会将每个预测值映射到0-1之间。然后根据Proposal在原图对应的GT上裁剪并缩放到
28
×
28
28\times28
28×28大小,得到图中的GT mask(对应目标区域为1,背景区域为0)。最后计算logits中预测类别为猫的mask与GT mask的BCELoss(BinaryCrossEntropyLoss)即可。以上仅仅是以一个proposal为例的,实际中会有很多。
三.Mask分支预测

在真正预测推理的时候,输入Mask分支的目标是由Fast R-CNN分支提供的。如上图所示,前面的backbon+fpn,RPN跟上面介绍的都是一样的,不再介绍。RPN输出的proposals通过Fast R-CNN分支(注意这里的RoIAlign跟上面的mask的不一样),我们能够得到最终预测的目标边界框信息以及类别信息。接着将目标边界框信息提供给Mask分支通过RoIAlign得到对应的特征,对于每个类别都预测一个mask,就能预测得到该目标的logits信息,再根据Fast R-CNN分支提供的类别信息将logits中对应该类别的Mask信息提取出来,即针对该目标预测的Mask信息(shape为
28
×
28
28\times28
28×28,由于通过sigmoid激活函数,数值都在0在这里插入代码片到1之间)。然后利用双线性插值将Mask缩放到预测目标边界框大小,并放到原图对应区域。接着通过设置的阈值(默认为0.5)将Mask转换成一张二值图,比如预测值大于0.5的区域设置为前景剩下区域都为背景。现在对于预测的每个目标我们就可以在原图中绘制出边界框信息,类别信息以及目标Mask信息。








![[深入理解SSD系列 闪存实战2.1.7] NAND FLASH基本编程(写)操作及原理_NAND FLASH Program Operation 源码实现](https://img-blog.csdnimg.cn/img_convert/e6b865ca3ac25b73b38d26c1d0afdfe9.png)