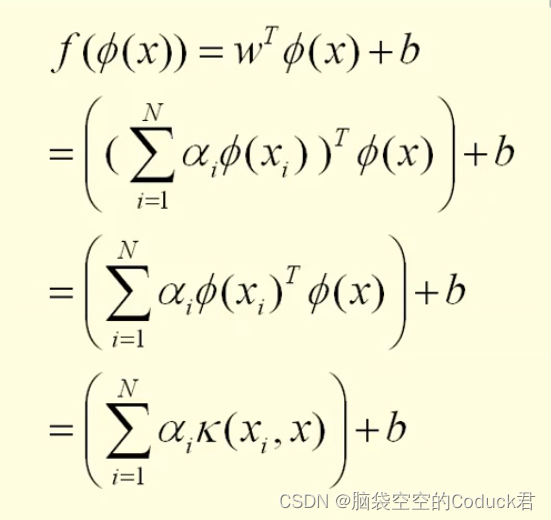为什么会有哈希冲突?
哈希表通过哈希函数来计算存放数据,在curd数据时不用多次比较,时间复杂度O(1)。但是凡事都有利弊,不同关键字通过相同哈希函数可能计算出来相同的存放地址,这种现象被称为哈希冲突。
如何避免哈希冲突?
1.设计合理的哈希函数
直接定制法
取关键字的某个线性函数作为哈希地址:Hash = A * Key + B
优点:简答,均匀
缺点:需要事先知道关键字的分布情况,
适合场景:查找比较小且连续的情况
除留余数法
设哈希表允许的地址数m,取一个<=m,但最接近或者等于m的质数p作为除数,按照哈希函数Hash = key % p,将关键码转换成哈希地址
2.调节负载因子
负载因子 = 元素个数 / 哈希表的容量

如图所示,负载因子越大,发生哈希冲突的可能性越大。又哈希表中元素不能减少,只能扩大哈希表中的数组容量
解决哈希冲突
如果哈希冲突无法避免,又该如何处理哈希冲突呢?
开放地址法/闭散列
线性探测
当发生哈希冲突时,如果哈希表没被装满说明还有空位置,那么可以把key存放到冲突位置的“下一个”空位置。

要往哈希表中插入14,hash(14) = 14 % 10 = 4。已经存放了4,就往下找,直到找到空位置(也就是5下标),24,34,44同理。
缺点:1.线性探测把可能冲突的元素,放到一起,挨得很近。
2.不好删除,如果你删除了4,会影响到44的查找
二次探测
为了解决线性探测大量冲突元素堆积在一起的缺点,使用函数Hi = (H0 + i2 ) % m (其中i = 1,2,3....).H0 是通过哈希函数对元素关键字Key进行计算得到的位置,m表示哈希表的大小,i表示发生冲突的次数

14的下标 (4 + 12 ) % 10 = 5, 24的下标 (4 + 22 ) % 10 = 8
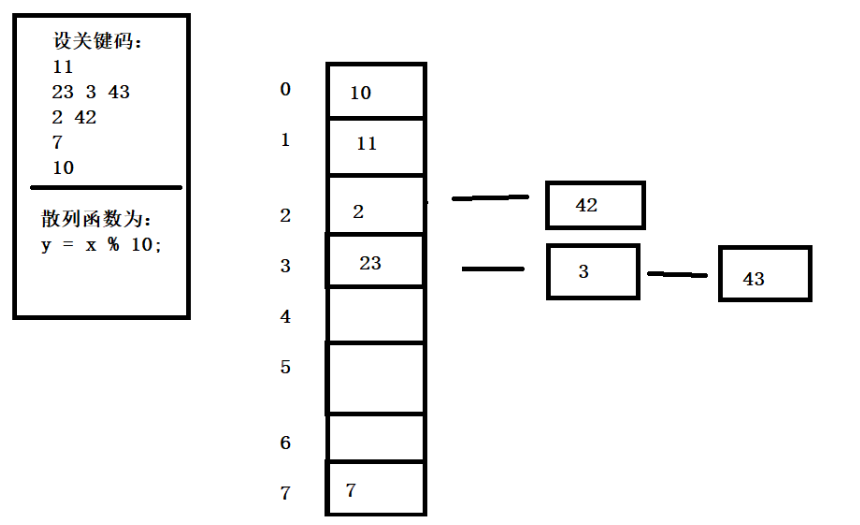
开散列/哈希桶/链地址法/开链法
首先对关键码集合用哈希函数计算哈希地址,具有相同地址的关键码归于同一子集合,每个子集合称为一个桶,每个桶里的元素通过一个单链表连接起来,各个链表的头节点存储在哈希表中(即数组+链表)。如果冲突非常严重,每个桶的背后变成一棵红黑树(数组+链表+红黑树)



![[NIPS 2017] Improved Training of Wasserstein GANs (WGAN-GP)](https://img-blog.csdnimg.cn/992fdcd069eb49a98e25245bd9e973ab.png#pic_center)