目录
铺垫
内存
线程的角度
线程池
基本代码结构
对于线程池的生产消费的完善
初步实现线程池生产消费
结合日志完善线程池
铺垫
内存
(以STL处理方式,引入提供效率的一种思想)
通过进行C语言与C++语言的学习中,平时我们使用的内存,都是我们需要了,才进行申请。而又通过系统的学习,我们可以发现,需要才进行申请,这样语言上我们要调用语言的接口:malloc、new等,但是它们的底层也一定是要调用操作系统提供的接口的。而调用系统接口,需要:
- 陷入内核。
- 更改CPU状态。
- 切换页表。
- 空间不够,操作系统还需要进行查找(空间碎片),进行其内部的内存管理算法(刷新缓冲区进行IO腾出空间、对内存碎片做整理、杀掉不常用的应用)。
所以,对应的STL容器,对于此方面:增容不是我们要多少给多少,而是直接预先多申请一部分,本质上就是用空间换时间的策略。
线程的角度
内存是资源,线程本质是一种调用执行流,也是资源。所以如果我们预先创建出一大批的线程,当有任务在来的时候,我们直接让线程去进行处理任务,而不用再去当任务到来时,然后才进行创建线程(本质创建各种数据结构,并且进行初始化、以及一系列为管理的操作),这是很浪费时间的。
如果我们预先创建出一大批的线程,当有任务来的时候,然后直接让线程去处理任务,而不用再去当任务来的时候,才创建……。
线程池
线程池的应用场景:
- 需要大量的线程来完成任务,且完成任务的时间比较短。 WEB服务器完成网页请求这样的任务,使用线程池技术是非常合适的。因为单个任务小,而任务数量巨大,你可以想象一个热门网站的点击次数。 但对于长时间的任务,比如一个Telnet连接请求,线程池的优点就不明显了。因为Telnet会话时间比线程的创建时间大多了。
- 对性能要求苛刻的应用,比如要求服务器迅速响应客户请求。
- 接受突发性的大量请求,但不至于使服务器因此产生大量线程的应用。突发性大量客户请求,在没有线程池情况下,将产生大量线程,虽然理论上大部分操作系统线程数目最大值不是问题,短时间内产生大量线程可能使内存到达极限。
- 创建固定数量线程池,循环从任务队列中获取任务对象。
- 获取到任务对象后,执行任务对象中的任务接口。
Note:
核心:用来预先申请资源,达到以空间换时间的一种做法。
线程池的框架实现:
有人向线程池内部push任务,线程池内部的线程就可以自动的处理任务。即:有线程向线程池内部push任务,就一定回有线程在线程池内部拿任务 —— 本质:生产消费模型。
基本代码结构
并未加入互斥量与信号量。
thread.hpp
对线程的封装。
#pragma once
#include <string>
#include <pthread.h>
#include <cstdio>
// 对线程的封装 - 不是完全必要,但是这样便于后期的统一管理
typedef void*(*fun_t)(void*);
// 整合线程的数据
class ThreadData
{
public:
std::string _name;
void* _args;
};
class Thread
{
public:
Thread(int num, fun_t callback, void* args):_func(callback)
{
char nameBuffer[64];
snprintf(nameBuffer, sizeof(nameBuffer), "Thread-%d", num);
_name = nameBuffer;
_tdata._args = args;
_tdata._name = _name;
}
void start()
{
pthread_create(&_tid, nullptr, _func, (void*)&_tdata);
}
void join()
{
pthread_join(_tid, nullptr);
}
// 未来不再使用线程id了,因为其是一个地址不便于我们查看
std::string name()
{
return _name;
}
~Thread()
{}
private:
std::string _name;
fun_t _func;
ThreadData _tdata;
pthread_t _tid;
};
ThreadPool.hpp
#include "thread.hpp"
#include <vector>
#include <queue>
#include <unistd.h>
#include <iostream>
const int g_thread_num = 3;
template<class T>
class ThreadPool
{
public:
ThreadPool(int thread_num = g_thread_num):_num(thread_num)
{
for(int i = 1; i <= _num; i++)
_threads.push_back(new Thread(i, routine, nullptr));
}
// 1.run - 将线程跑起来
void run()
{
int i = 0;
for(auto& iter : _threads)
{
iter->start();
std::cout << iter->name() << " 启动成功" << std::endl;
}
}
// 未来所有执行流所执行的方法 - 核心取任务、执行任务的逻辑
static void* routine(void* args) // 因为在类当中,如果是一个成员方法,其会有一个隐藏的参数this指针,所以我们需要使用static进行修饰。
{
ThreadData *td = (ThreadData*)args;
while(true)
{
std::cout << "我是一个线程,我的名字是:" << td->_name << std::endl;
sleep(1);
}
}
// 2.pushTask - 将任务放到任务池里
void pushTask()
{}
void join()
{
for(auto& iter : _threads)
iter->join();
}
~ThreadPool()
{
for(auto& iter : _threads)
delete iter;
}
private:
std::vector<Thread*> _threads;
int _num;
std::queue<T> _task_queue;
};testMain.cc
#include "threadPool.hpp"
#include <iostream>
int main()
{
ThreadPool<int> *tp = new ThreadPool<int>();
tp->run();
tp->join();
return 0;
}
对于线程池的生产消费的完善
加入互斥量与信号量,并且加入生产者的生产数据、方法,消费者的消费数据、方法。此处我们需要注意:最难的并不是生产,而是消费。
生产者:
生产的过程。
// 2.pushTask - 将任务放到任务池里
void pushTask(const T& task)
{
lockGuard lockguard(&_lock); // 加锁
_task_queue.push(task); // 压入任务
pthread_cond_signal(&_cond); // 唤醒线程
} // 自动释放锁
消费者:
消费的过程。
原:
// 未来所有执行流所执行的方法 - 核心取任务、执行任务的逻辑
static void* routine(void* args) // 因为在类当中,如果是一个成员方法,其会有一个隐藏的参数this指针,所以我们需要使用static进行修饰。
{
ThreadData *td = (ThreadData*)args;
while(true)
{
std::cout << "我是一个线程,我的名字是:" << td->_name << std::endl;
sleep(1);
}
}因为,每一个线程创建出来了,它都会执行routine,并且我们是在构造的时候就将其传送给了我们对应的线程,该线程就会在start的时候就会进入我们设置的回调。
//ThreadPool.hpp //--------------------------- // 构造函数 ThreadPool(int thread_num = g_thread_num):_num(thread_num) { pthread_mutex_init(&_lock, nullptr); pthread_cond_init(&_cond, nullptr); for(int i = 1; i <= _num; i++) _threads.push_back(new Thread(i, routine, nullptr)); } // 1.run - 将线程跑起来 void run() { for(auto& iter : _threads) { iter->start(); std::cout << iter->name() << " 启动成功" << std::endl; } } //Thread.hpp //--------------------------- void start() { pthread_create(&_tid, nullptr, _func, (void*)&_tdata); }
但是,作为势必要消费数据的routine就带来一些问题(困扰):消费就代表要访问,存储对应方法的_task_queue,但是_task_queue作为内类的成员方法,而routine是一个被staict修饰的成员方法(其只能够使用静态成员、静态方法,无法使用内类的成员属性、成员方法)。
#:将_task_queue设置为static修饰的
这个方法是可以的(类内的成员方法,能够使用static修饰的成员),但是是不好的。因为如果定义为static修饰的,未来如果有两个三个等的线程池,这些线程池就相当于_task_queue被大家所共享的,而且对于此类数据还是最好封装住。
与其让routine拿到_task_queue,不如让其直接拿到整体对象。拿到之后可以直接让其利用函数的方式访问类内的各种属性。
直接在构造函数的地方传递:this指针。
//ThreadPool.hpp
//---------------------------
// 构造函数
ThreadPool(int thread_num = g_thread_num):_num(thread_num)
{
pthread_mutex_init(&_lock, nullptr);
pthread_cond_init(&_cond, nullptr);
for(int i = 1; i <= _num; i++)
_threads.push_back(new Thread(i, routine, this));
}此时,对于routine内部只需要强转一下就行了。
// 未来所有执行流所执行的方法 - 核心取任务、执行任务的逻辑
static void* routine(void* args) // 因为在类当中,如果是一个成员方法,其会有一个隐藏的参数this指针,所以我们需要使用static进行修饰。
{
ThreadData *td = (ThreadData*)args;
ThreadPool<T>* tp = (ThreadPool<T>*)td->_args;
while(true)
{
// lock
// while(task_queue_.empty()) wait();
// 获取任务
// unlock
// 处理任务
}
}初步完善:
public:
// 返回锁的地址
pthread_mutex_t *getMutex()
{
return &_lock;
}
bool isEmpty()
{
return _task_queue.empty();
}
void waitCond()
{
pthread_cond_wait(&_cond, &_lock);
}
T getTask()
{
T t = _task_queue.front();
_task_queue.pop();
return t;
}
------------------------
// 未来所有执行流所执行的方法 - 核心取任务、执行任务的逻辑
static void *routine(void *args) // 因为在类当中,如果是一个成员方法,其会有一个隐藏的参数this指针,所以我们需要使用static进行修饰。
{
ThreadData *td = (ThreadData *)args;
ThreadPool<T> *tp = (ThreadPool<T> *)td->_args;
while (true)
{
T task; // 对应任务的对象
// 利用{}确定加锁的区间
{
// lock
lockGuard lockguard(tp->getMutex());
// while(task_queue_.empty()) wait();
while (tp->isEmpty())
tp->waitCond();
// 获取任务 - 100%有任务
task = tp->getTask(); // 任务队列是共享的->将任务从共享,拿到自己的私有空间
} // 自动释放锁
// 处理任务
task(); // 要求每一个任务都要提供一个仿函数
}
}初步实现线程池生产消费
提供一个:Task.hpp
任务类型的封装,重点:包含仿函数。
#pragma once
#include <iostream>
#include <string>
#include <functional>
typedef std::function<int(int, int)> func_t;
class Task
{
public:
Task(){}
Task(int x, int y, func_t func):_x(x), _y(y), _func(func)
{}
int operator ()()
{
return _func(_x, _y);
}
public:
int _x;
int _y;
// int type;
func_t _func;
};任务是什么样子,不能够让线程池知道,与线程池没有关系,线程池只需要我们让其干什么就干什么就行了,也就是一定意义上的解耦合。
thread.hpp
#pragma once
#include <string>
#include <pthread.h>
#include <cstdio>
// 对线程的封装 - 不是完全必要,但是这样便于后期的统一管理
typedef void*(*fun_t)(void*);
// 整合线程的数据
class ThreadData
{
public:
std::string _name;
void* _args;
};
class Thread
{
public:
Thread(int num, fun_t callback, void* args):_func(callback)
{
char nameBuffer[64];
snprintf(nameBuffer, sizeof(nameBuffer), "Thread-%d", num);
_name = nameBuffer;
_tdata._args = args;
_tdata._name = _name;
}
void start()
{
pthread_create(&_tid, nullptr, _func, (void*)&_tdata);
}
void join()
{
pthread_join(_tid, nullptr);
}
// 未来不再使用线程id了,因为其是一个地址不便于我们查看
std::string name()
{
return _name;
}
~Thread()
{}
private:
std::string _name;
fun_t _func;
ThreadData _tdata;
pthread_t _tid;
};lockGuard.hpp
#pragma once
#include <iostream>
#include <pthread.h>
// RAII风格的加锁方式
class lockGuard
{
public:
lockGuard(pthread_mutex_t *mtx):mtx_(mtx)
{
pthread_mutex_lock(mtx_);
}
~lockGuard()
{
pthread_mutex_unlock(mtx_);
}
private:
pthread_mutex_t *mtx_;
};Task.hpp
#pragma once
#include <iostream>
#include <string>
#include <functional>
typedef std::function<int(int, int)> func_t;
class Task
{
public:
Task(){}
Task(int x, int y, func_t func):_x(x), _y(y), _func(func)
{}
void operator()(std::string& name)
{
std::cout << "线程" << name << "处理完成,结果是" << _x << "+" << _y << "=" << _func(_x, _y) << std::endl;
}
public:
int _x;
int _y;
// int type;
func_t _func;
};threadPool.hpp
#include "thread.hpp"
#include "lockGuard.hpp"
#include <vector>
#include <queue>
#include <unistd.h>
#include <iostream>
const int g_thread_num = 3;
template <class T>
class ThreadPool
{
public:
// 返回锁的地址
pthread_mutex_t *getMutex()
{
return &_lock;
}
bool isEmpty()
{
return _task_queue.empty();
}
void waitCond()
{
pthread_cond_wait(&_cond, &_lock);
}
T getTask()
{
T t = _task_queue.front();
_task_queue.pop();
return t;
}
public:
ThreadPool(int thread_num = g_thread_num) : _num(thread_num)
{
for (int i = 1; i <= _num; i++)
{
_threads.push_back(new Thread(i, routine, this));
}
pthread_mutex_init(&_lock, nullptr);
pthread_cond_init(&_cond, nullptr);
}
// 1.run - 将线程跑起来
void run()
{
for (auto &iter : _threads)
{
iter->start();
std::cout << iter->name() << " 启动成功" << std::endl;
}
}
// 未来所有执行流所执行的方法 - 核心取任务、执行任务的逻辑
static void *routine(void *args) // 因为在类当中,如果是一个成员方法,其会有一个隐藏的参数this指针,所以我们需要使用static进行修饰。
{
ThreadData *td = (ThreadData *)args;
ThreadPool<T> *tp = (ThreadPool<T> *)td->_args;
while (true)
{
T task; // 对应任务的对象
{
// lock
lockGuard lockguard(tp->getMutex());
// while(task_queue_.empty()) wait();
while (tp->isEmpty())
tp->waitCond();
// 获取任务 - 100%有任务
task = tp->getTask(); // 任务队列是共享的->将任务从共享,拿到自己的私有空间
} // 自动释放锁
// 处理任务
task(td->_name); // 要求每一个任务都要提供一个仿函数
}
}
// 2.pushTask - 将任务放到任务池里
void pushTask(const T &task)
{
lockGuard lockguard(&_lock); // 加锁
_task_queue.push(task); // 压入任务
pthread_cond_signal(&_cond); // 唤醒线程
} // 自动释放锁
// void join()
// {
// for (auto &iter : _threads)
// {
// iter->join();
// }
// }
~ThreadPool()
{
for (auto &iter : _threads)
{
iter->join();
delete iter;
}
pthread_mutex_destroy(&_lock);
pthread_cond_destroy(&_cond);
}
private:
std::vector<Thread *> _threads;
int _num;
std::queue<T> _task_queue;
pthread_mutex_t _lock;
pthread_cond_t _cond;
};
testMain.cc
#include "threadPool.hpp"
#include "Task.hpp"
#include <ctime>
#include <iostream>
int main()
{
srand((unsigned long)time(nullptr) ^ getpid()); // 利用 ^ getpid()让数据更随机
ThreadPool<Task> *tp = new ThreadPool<Task>();
tp->run();
while (true)
{
// 生产的过程(制作任务的时候,要花时间)
int x = rand() % 1000;
usleep(5000); // 模拟制作任务的时候,花费的时间
int y = rand() % 1000;
Task t(x, y, [](int x, int y)->int{
return x + y;
});
std::cout << "制作任务完成" << std::endl;
// 推送任务到线程池中
tp->pushTask(t);
sleep(1); // 防止刷新过快
}
return 0;
}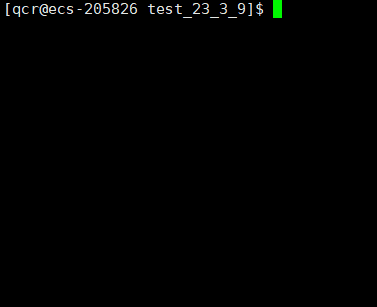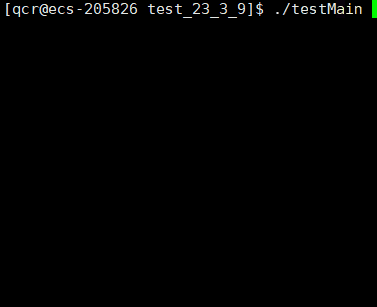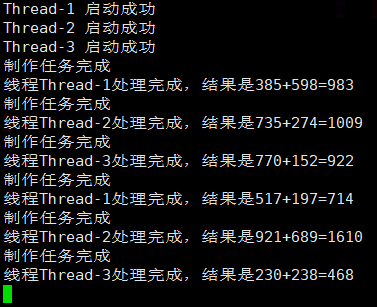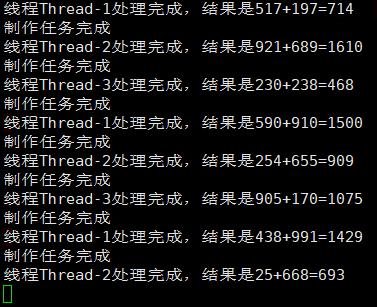
将上述代码进行优化:
进阶:
// 方案2: // queue1,queue2 // std::queue<T> *p_queue, *c_queue // p_queue->queue1 // c_queue->queue2 // p_queue -> 生产一批任务之后,swap(p_queue,c_queue),唤醒所有线程/一个线程 // 当消费者处理完毕的时候,你也可以进行swap(p_queue,c_queue) // 因为我们生产和消费用的是不同的队列,未来我们要进行资源的处理的时候,仅仅是指针
- 需要加锁的仅仅是swap的地方
- swap方式:
- 满了就swap。
- 让一个线程不断地去观察,消费完了,且生产的数据就交换。
对于上述的多处打印信息的逻辑,其实在正常的时候是需要封装成日志的。一般在公司内部是,任何一款软件,都必须有日志:
日志中因为要实现,至少:日志等级、时间、日志内容、支持用户自定义。所以参数的传递中,我们需要利用到可变参数列表。
补充:
可变参数表的使用。
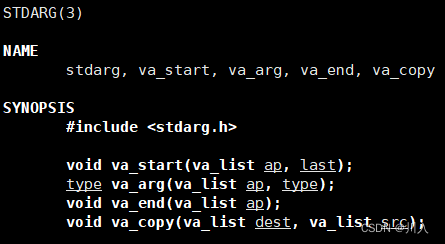
参数:
#include <stdarg.h> void va_start(va_list ap, last); type va_arg(va_list ap, type); void va_end(va_list ap); void va_copy(va_list dest, va_list src);
- va_list:本质上一个char类型的指针。
- last:代表可变参数的前面的参数当中的最后一个具体参数。
- type:具体的类型。
// 完整的日志功能,至少:日志等级 时间 日志内容 支持用户自定义 void logMessage(int level, const char* format, ...)// level:日志等级,format, ...:用户传参、日志对应的信息等。 { va_list ap; // va_list本质上就是char类型的指针 va_start(ap, format); // 让指针指向栈帧对应的结构 int x = va_arg(ap, int); // 通过具体的类型,来从通过指针提取特定的值 —— 没有参数就返回NULL va_end(ap); // 将指针设置为空(相当于:ap = nullptr) }但是,如果让我们自己提取,那也就太麻烦了,而且使用起来也不舒服。我们可以使用:#include <stdarg.h>中的。
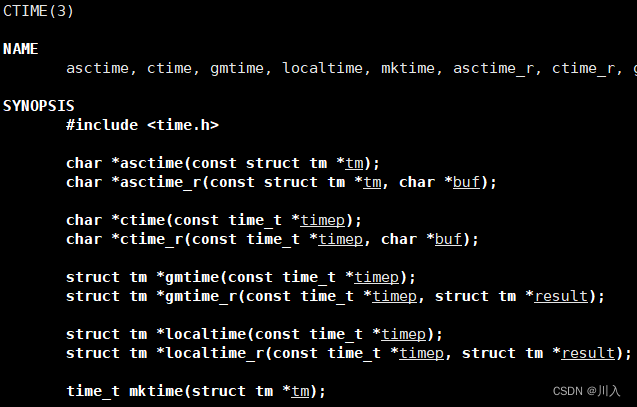
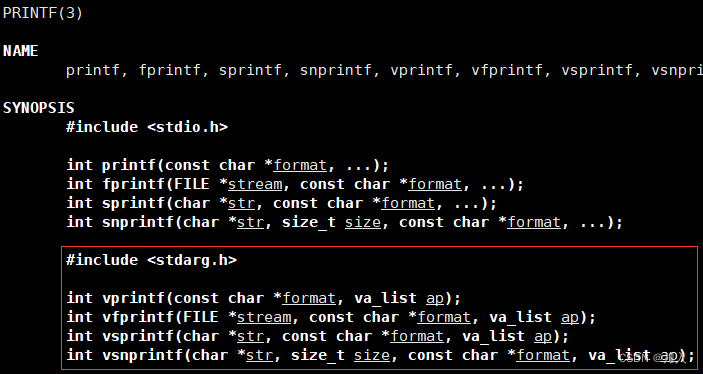
#include <stdarg.h> // 将我们传入的参数,可变的方式,格式化显示到: // 显示器 int vprintf(const char *format, va_list ap); // 文件 int vfprintf(FILE *stream, const char *format, va_list ap); // 支付串 int vsprintf(char *str, const char *format, va_list ap); // 指定长度的字符串 int vsnprintf(char *str, size_t size, const char *format, va_list ap);可以发现它们是与图中的上面四个,#include <stdio.h>中的类似的。
log.hpp:
#pragma once #include <cstdarg> // 日志是有日志级别的 #define NORMAL 1 // 正常 #define WARNING 2 // 警告 -- 没出错 #define ERROR 3 // 错误 -- 不影响后续执行(一个功能因为条件等,没有执行) #define FATAL 4 // 致命 -- 代码无法继续向后执行 // 完整的日志功能,至少:日志等级 时间 日志内容 支持用户自定义 void logMessage(int level, const char* format, ...)// level:日志等级; format, ...:用户传参、日志对应的信息等。 { va_list args; va_start(args, format); // 这个时候就有一个可变参数列表的起始地址 vprintf(format, args); va_end(args); }testMain.cc:
#include "log.hpp" #include <iostream> int main() { logMessage(NORMAL, "%s %d %c %f\n", "这是一条日志信息", 1234, 'a', 3.14); return 0; }

结合日志完善线程池
log.hpp
#pragma once
#include <cstdarg>
#include <ctime>
// 日志是有日志级别的
#define DEBUG 0
#define NORMAL 1 // 正常
#define WARNING 2 // 警告 -- 没出错
#define ERROR 3 // 错误 -- 不影响后续执行(一个功能因为条件等,没有执行)
#define FATAL 4 // 致命 -- 代码无法继续向后执行
const char* gLevelMap[] = {
"DEBUG",
"NORMAL",
"WARNING",
"ERROR",
"FATAL",
};
#define LOGFILE "./threafpool.log"
// 完整的日志功能,至少:日志等级 时间 日志内容 支持用户自定义
void logMessage(int level, const char* format, ...)// level:日志等级; format, ...:用户传参、日志对应的信息等。
{
#ifndef DEBUG_SHOW
if(level == DEBUG) return;
#endif
char stdBuffer[1024]; //标准部分
time_t timestamp = time(nullptr);
//struct tm* localtime = localtime(×tamp); //- 详细时间输出操作
//localtime->tm_year;
snprintf(stdBuffer, sizeof stdBuffer, "[%s] [%ld] ", gLevelMap[level], timestamp);
char logBuffer[1024]; //自定义部分
va_list args;
va_start(args, format);
// 这个时候就有一个可变参数列表的起始地址
// 向屏幕中直接打印
// vprintf(format, args);
// 向缓冲区logBuffer中打印
vsnprintf(logBuffer, sizeof logBuffer, format, args);
va_end(args);
// 向屏幕
printf("%s%s\n", stdBuffer, logBuffer);
// 向文件
FILE *fp = fopen(LOGFILE, "a");
fprintf(fp, "%s%s\n", stdBuffer, logBuffer);
fclose(fp);
}
Task.hpp
#pragma once
#include "log.hpp"
#include <iostream>
#include <string>
#include <functional>
typedef std::function<int(int, int)> func_t;
class Task
{
public:
Task(){}
Task(int x, int y, func_t func):_x(x), _y(y), _func(func)
{}
void operator()(std::string& name)
{
//std::cout << "线程" << name << "处理完成,结果是" << _x << "+" << _y << "=" << _func(_x, _y) << std::endl;
logMessage(WARNING, "%s处理完成: %d+%d=%d | %s | %d",
name.c_str(), _x, _y, _func(_x, _y), __FILE__, __LINE__); // __FILE__, __LINE__:预处理符。
}
public:
int _x;
int _y;
// int type;
func_t _func;
};预处理符:
这就是为什么要有这些预处理符,其一的原因就是日志中会使用到,便于我们找到文件的执行位置。
__FILE__ //进行编译的源文件 __LINE__ //文件当前的行号 __DATE__ //文件被编译的日期 __TIME__ //文件被编译的时间 __STDC__ //如果编译器遵循ANSI C,其值为1,否则未定义
thread.hpp
#pragma once
#include <string>
#include <pthread.h>
#include <cstdio>
// 对线程的封装 - 不是完全必要,但是这样便于后期的统一管理
typedef void*(*fun_t)(void*);
// 整合线程的数据
class ThreadData
{
public:
std::string _name;
void* _args;
};
class Thread
{
public:
Thread(int num, fun_t callback, void* args):_func(callback)
{
char nameBuffer[64];
snprintf(nameBuffer, sizeof(nameBuffer), "Thread-%d", num);
_name = nameBuffer;
_tdata._args = args;
_tdata._name = _name;
}
void start()
{
pthread_create(&_tid, nullptr, _func, (void*)&_tdata);
}
void join()
{
pthread_join(_tid, nullptr);
}
// 未来不再使用线程id了,因为其是一个地址不便于我们查看
std::string name()
{
return _name;
}
~Thread()
{}
private:
std::string _name;
fun_t _func;
ThreadData _tdata;
pthread_t _tid;
};lockGuard.hpp
#pragma once
#include <iostream>
#include <pthread.h>
// RAII风格的加锁方式
class lockGuard
{
public:
lockGuard(pthread_mutex_t *mtx):mtx_(mtx)
{
pthread_mutex_lock(mtx_);
}
~lockGuard()
{
pthread_mutex_unlock(mtx_);
}
private:
pthread_mutex_t *mtx_;
};
threadPool.hpp
#include "thread.hpp"
#include "lockGuard.hpp"
#include "log.hpp"
#include <vector>
#include <queue>
#include <unistd.h>
#include <iostream>
const int g_thread_num = 3;
template <class T>
class ThreadPool
{
public:
// 返回锁的地址
pthread_mutex_t *getMutex()
{
return &_lock;
}
bool isEmpty()
{
return _task_queue.empty();
}
void waitCond()
{
pthread_cond_wait(&_cond, &_lock);
}
T getTask()
{
T t = _task_queue.front();
_task_queue.pop();
return t;
}
public:
ThreadPool(int thread_num = g_thread_num) : _num(thread_num)
{
for (int i = 1; i <= _num; i++)
{
_threads.push_back(new Thread(i, routine, this));
}
pthread_mutex_init(&_lock, nullptr);
pthread_cond_init(&_cond, nullptr);
}
// 1.run - 将线程跑起来
void run()
{
for (auto &iter : _threads)
{
iter->start();
// std::cout << iter->name() << " 启动成功" << std::endl;
logMessage(NORMAL, "%s %s", iter->name().c_str(), "启动成功");
}
}
// 未来所有执行流所执行的方法 - 核心取任务、执行任务的逻辑
static void *routine(void *args) // 因为在类当中,如果是一个成员方法,其会有一个隐藏的参数this指针,所以我们需要使用static进行修饰。
{
ThreadData *td = (ThreadData *)args;
ThreadPool<T> *tp = (ThreadPool<T> *)td->_args;
while (true)
{
T task; // 对应任务的对象
{
// lock
lockGuard lockguard(tp->getMutex());
// while(task_queue_.empty()) wait();
while (tp->isEmpty())
tp->waitCond();
// 获取任务 - 100%有任务
task = tp->getTask(); // 任务队列是共享的->将任务从共享,拿到自己的私有空间
} // 自动释放锁
// 处理任务
task(td->_name); // 要求每一个任务都要提供一个仿函数
}
}
// 2.pushTask - 将任务放到任务池里
void pushTask(const T &task)
{
lockGuard lockguard(&_lock); // 加锁
_task_queue.push(task); // 压入任务
pthread_cond_signal(&_cond); // 唤醒线程
} // 自动释放锁
// void join()
// {
// for (auto &iter : _threads)
// {
// iter->join();
// }
// }
~ThreadPool()
{
for (auto &iter : _threads)
{
iter->join();
delete iter;
}
pthread_mutex_destroy(&_lock);
pthread_cond_destroy(&_cond);
}
private:
std::vector<Thread *> _threads;
int _num;
std::queue<T> _task_queue;
pthread_mutex_t _lock;
pthread_cond_t _cond;
};
testMain.cc
#include "threadPool.hpp"
#include "Task.hpp"
#include "log.hpp"
#include <ctime>
#include <iostream>
int main()
{
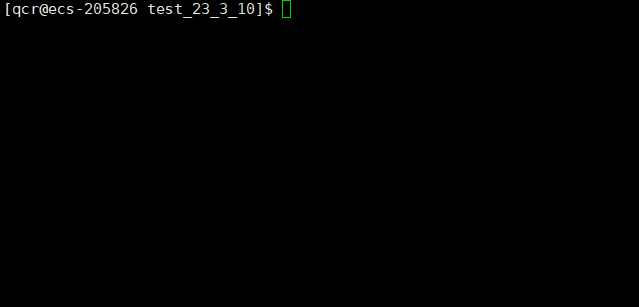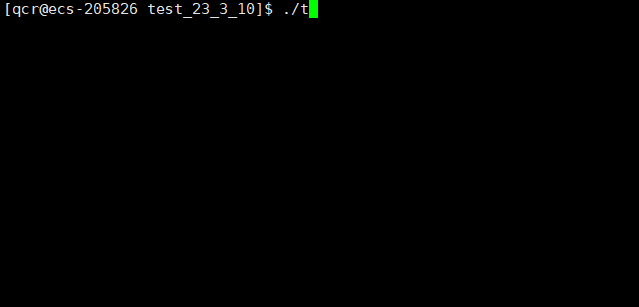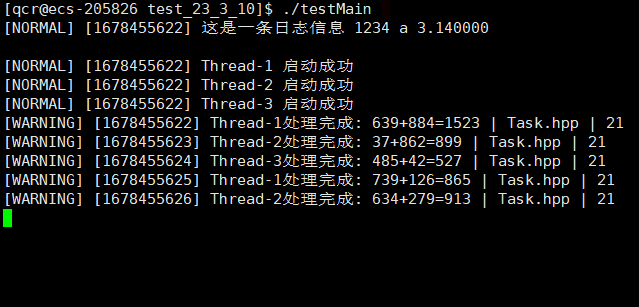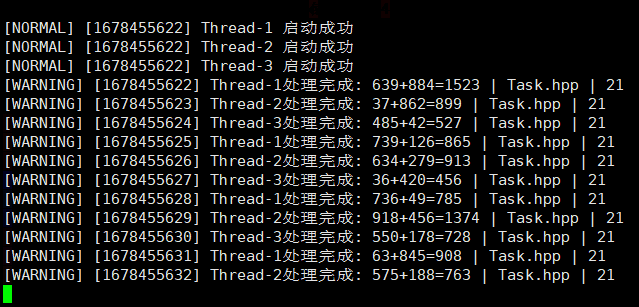
logMessage(NORMAL, "%s %d %c %f\n", "这是一条日志信息", 1234, 'a', 3.14);
srand((unsigned long)time(nullptr) ^ getpid()); // 利用 ^ getpid()让数据更随机
ThreadPool<Task> *tp = new ThreadPool<Task>();
tp->run();
while (true)
{
// 生产的过程(制作任务的时候,要花时间)
int x = rand() % 1000;
usleep(5000); // 模拟制作任务的时候,花费的时间
int y = rand() % 1000;
Task t(x, y, [](int x, int y)->int{
return x + y;
});
// std::cout << "制作任务完成" << std::endl;
logMessage(DEBUG, "制作任务完成: %d+%d=?", x, y);
// 推送任务到线程池中
tp->pushTask(t);
sleep(1); // 防止刷新过快
}
return 0;
}
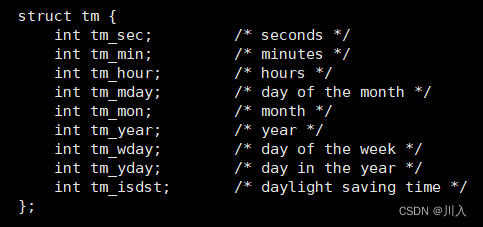
补充:
对于时间信息的提取与输出:
struct tm中所存储的内容: