1、为什么用
微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元。由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去定位。主要体现在,一个请求可能需要调用很多个服务,而内部服务的调用复杂性,决定了问题难以定位。所以微服务架构中,必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与, 参与的顺序又是怎样的,从而达到每个请求的步骤清晰可见,出了问题,很快定位。
链路追踪组件有 Google 的 Dapper,Twitter 的 Zipkin,以及阿里的 Eagleeye (鹰眼)等,它 们都是非常优秀的链路追踪开源组件。
2、基本术语
Span(跨度):基本工作单元,发送一个远程调度任务 就会产生一个 Span,Span 是一 个 64 位 ID 唯一标识的,Trace 是用另一个 64 位 ID 唯一标识的,Span 还有其他数据信 息,比如摘要、时间戳事件、Span 的 ID、以及进度 ID。
Trace(跟踪):一系列 Span 组成的一个树状结构。请求一个微服务系统的 API 接口, 这个 API 接口,需要调用多个微服务,调用每个微服务都会产生一个新的 Span,所有 由这个请求产生的 Span 组成了这个 Trace。
Annotation(标注):用来及时记录一个事件的,一些核心注解用来定义一个请求的开 始和结束 。这些注解包括以下:
cs - Client Sent -客户端发送一个请求,这个注解描述了这个 Span 的开始
sr - Server Received -服务端获得请求并准备开始处理它,如果将其 sr 减去 cs 时 间戳 便可得到网络传输的时间。
ss - Server Sent (服务端发送响应)–该注解表明请求处理的完成(当请求返回客户 端),如果 ss 的时间戳减去 sr 时间戳,就可以得到服务器请求的时间。
cr - Client Received (客户端接收响应)-此时 Span 的结束,如果 cr 的时间戳减 去cs 时间戳便可以得到整个请求所消耗的时间。
官方文档:
https://cloud.spring.io/spring-cloud-static/spring-cloud-sleuth/2.1.3.RELEASE/single/spring-cloud
-sleuth.html如果服务调用顺序如下

那么用以上概念完整的表示出来如下:

Span 之间的父子关系如下:

3、整合 Sleuth
1、服务提供者与消费者导入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>2、打开 debug 日志
logging:
level:
org.springframework.cloud.openfeign: debug
org.springframework.cloud.sleuth: debug3、发起一次远程调用,观察控制台
DEBUG [user-service,541450f08573fff5,541450f08573fff5,false] user-service:服务名
541450f08573fff5:是 TranceId,一条链路中,只有一个 T
ranceId 541450f08573fff5:是 spanId,链路中的基本工作单元 id
false:表示是否将数据输出到其他服务,true 则会把信息输出到其他可视化的服务上观察
4、整合 zipkin 可视化观察
通过 Sleuth 产生的调用链监控信息,可以得知微服务之间的调用链路,但监控信息只输出 到控制台不方便查看。我们需要一个图形化的工具-zipkin。Zipkin 是 Twitter 开源的分布式跟 踪系统,主要用来收集系统的时序数据,从而追踪系统的调用问题。
zipkin 官网地址如下
https://zipkin.io/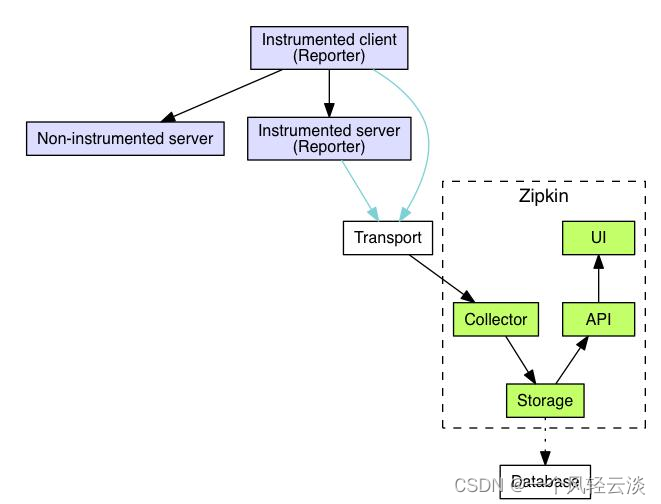
1、docker 安装 zipkin 服务器
docker run -d -p 9411:9411 openzipkin/zipkin2、pom导入
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>zipkin 依赖也同时包含了 sleuth,可以省略 sleuth 的引用
3、添加 zipkin 相关配置
spring:
application:
name: user-service
zipkin:
base-url: http://192.168.56.10:9411/ # zipkin 服务器的地址
# 关闭服务发现,否则 Spring Cloud 会把 zipkin 的 url 当做服务名称
discoveryClientEnabled: false
sender:
type: web # 设置使用 http 的方式传输数据
sleuth:
sampler:
probability: 1 # 设置抽样采集率为 100%,默认为 0.1,即 10%发送远程请求,测试 zipkin。
服务调用链追踪信息统计

服务依赖信息统计

5、Zipkin 数据持久化
Zipkin 默认是将监控数据存储在内存的,如果 Zipkin 挂掉或重启的话,那么监控数据就会丢 失。所以如果想要搭建生产可用的 Zipkin,就需要实现监控数据的持久化。而想要实现数据 持久化,自然就是得将数据存储至数据库。好在 Zipkin 支持将数据存储至:
内存(默认)
MySQL
Elasticsearch
Cassandra
Zipkin 数据持久化相关的官方文档地址如下:
https://github.com/openzipkin/zipkin#storage-component![]() https://github.com/openzipkin/zipkin#storage-component
https://github.com/openzipkin/zipkin#storage-component
Zipkin 支持的这几种存储方式中,内存显然是不适用于生产的,这一点开始也说了。而使用MySQL 的话,当数据量大时,查询较为缓慢,也不建议使用。Twitter 官方使用的是 Cassandra作为 Zipkin 的存储数据库,但国内大规模用 Cassandra 的公司较少,而且 Cassandra 相关文档也不多。Zipkin-server不处理跟踪数据的保留管理。使用ElasticSearch推荐的工具管理数据保留或群集 会无限增长!(这使用Elasticsearch 5 + 功能) 综上,故采用 Elasticsearch 是个比较好的选择,关于使用 Elasticsearch 作为 Zipkin 的存储数 据库的官方文档如下:
elasticsearch-storage:
https://github.com/openzipkin/zipkin/tree/master/zipkin-server#elasticsearch-storage![]() https://github.com/openzipkin/zipkin/tree/master/zipkin-server#elasticsearch-storagezipkin-storage/elasticsearch:
https://github.com/openzipkin/zipkin/tree/master/zipkin-server#elasticsearch-storagezipkin-storage/elasticsearch:
https://github.com/openzipkin/zipkin/tree/master/zipkin-storage/elasticsearch![]() https://github.com/openzipkin/zipkin/tree/master/zipkin-storage/elasticsearch通过 docker 的方式:
https://github.com/openzipkin/zipkin/tree/master/zipkin-storage/elasticsearch通过 docker 的方式:
docker run --env STORAGE_TYPE=elasticsearch --env ES_HOSTS=192.168.56.10:9200
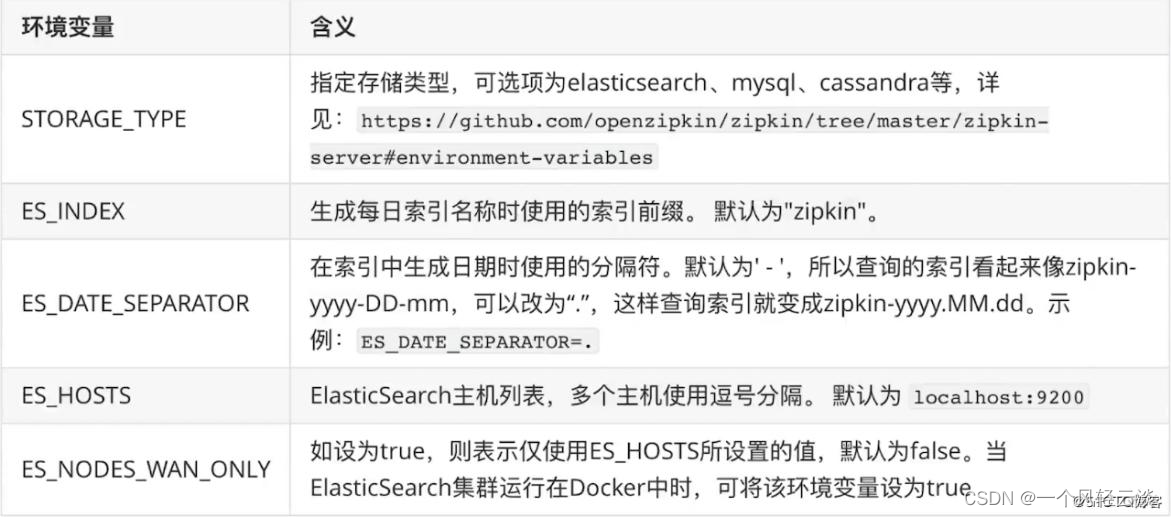
openzipkin/zipkin-dependencies 使用 es 时 Zipkin Dependencies 支持的环境变量
使用 es 时 Zipkin Dependencies 支持的环境变量