3、读写状态的设计
同步状态在重入锁的实现中是表示被同一个线程重复获取的次数,即一个整形变量来维护,但是之前的那个表示仅仅表示是否锁定,而不用区分是读锁还是写锁。而读写锁需要在同步状态(一个整形变量)上维护多个读线程和一个写线程的状态。
读写锁对于同步状态的实现是在一个整形变量上通过“按位切割使用”:将变量切割成两部分,高16位表示读,低16位表示写。
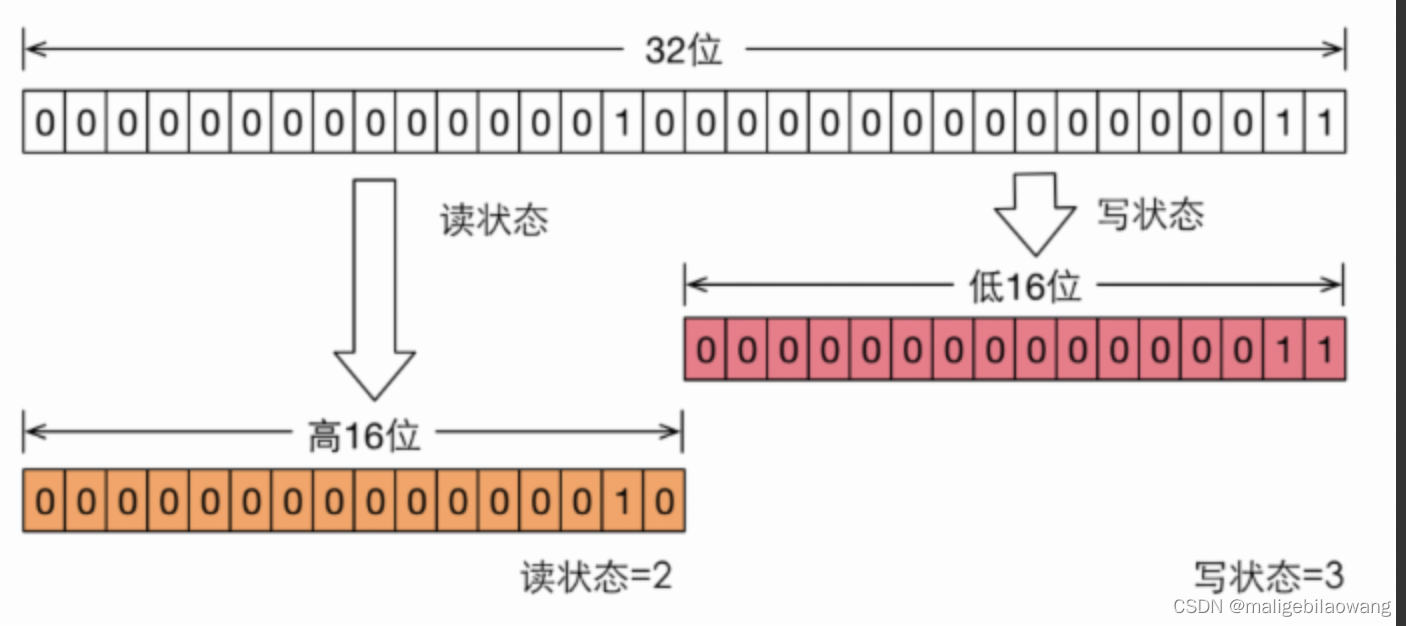
假设当前同步状态值为S,get和set的操作如下:
(1)获取写状态:
S&0x0000FFFF:将高16位全部抹去
(2)获取读状态:
S>>>16:无符号补0,右移16位
(3)写状态加1:
S+1
(4)读状态加1:
S+(1<<16)即S + 0x00010000
在代码层的判断中,如果S不等于0,当写状态(S&0x0000FFFF),而读状态(S>>>16)大于0,则表示该读写锁的读锁已被获取。
4、写锁的获取与释放
看下WriteLock类中的lock和unlock方法:
public void lock() {
sync.acquire(1);
}
public void unlock() {
sync.release(1);
}
可以看到就是调用的独占式同步状态的获取与释放,因此真实的实现就是Sync的 tryAcquire和 tryRelease。
写锁的获取,看下tryAcquire:
1 protected final boolean tryAcquire(int acquires) {
2 //当前线程
3 Thread current = Thread.currentThread();
4 //获取状态
5 int c = getState();
6 //写线程数量(即获取独占锁的重入数)
7 int w = exclusiveCount(c);
8
9 //当前同步状态state != 0,说明已经有其他线程获取了读锁或写锁
10 if (c != 0) {
11 // 当前state不为0,此时:如果写锁状态为0说明读锁此时被占用返回false;
12 // 如果写锁状态不为0且写锁没有被当前线程持有返回false
13 if (w == 0 || current != getExclusiveOwnerThread())
14 return false;
15
16 //判断同一线程获取写锁是否超过最大次数(65535),支持可重入
17 if (w + exclusiveCount(acquires) > MAX_COUNT)
18 throw new Error("Maximum lock count exceeded");
19 //更新状态
20 //此时当前线程已持有写锁,现在是重入,所以只需要修改锁的数量即可。
21 setState(c + acquires);
22 return true;
23 }
24
25 //到这里说明此时c=0,读锁和写锁都没有被获取
26 //writerShouldBlock表示是否阻塞
27 if (writerShouldBlock() ||
28 !compareAndSetState(c, c + acquires))
29 return false;
30
31 //设置锁为当前线程所有
32 setExclusiveOwnerThread(current);
33 return true;
34 }
其中exclusiveCount方法表示占有写锁的线程数量,源码如下:
static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; }
说明:直接将状态state和(2^16 - 1)做与运算,其等效于将state模上2^16。写锁数量由state的低十六位表示。
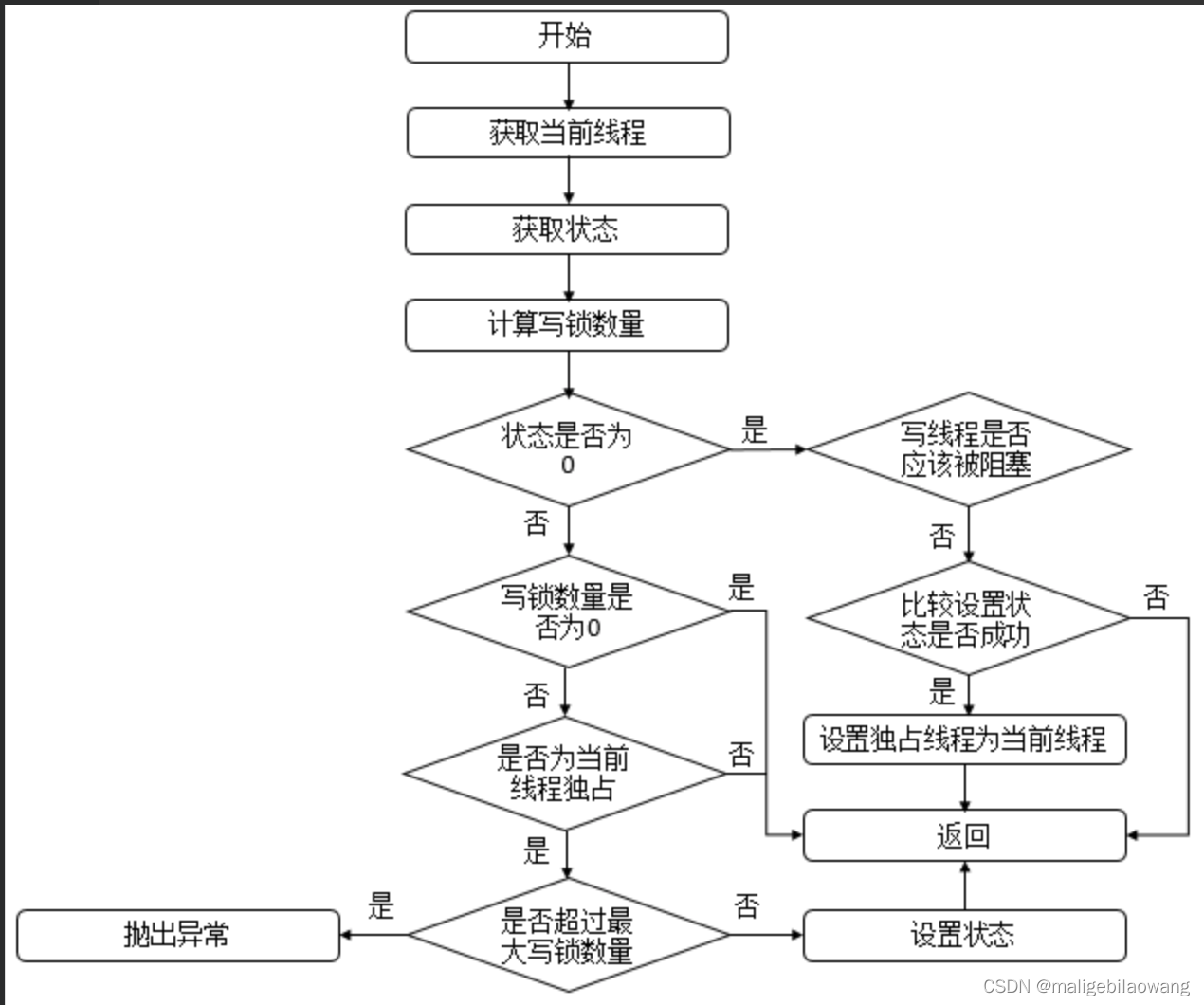
从源代码可以看出,获取写锁的步骤如下:
(1)首先获取c、w。c表示当前锁状态;w表示写线程数量。然后判断同步状态state是否为0。如果state!=0,说明已经有其他线程获取了读锁或写锁,执行(2);否则执行(5)。
(2)如果锁状态不为零(c != 0),而写锁的状态为0(w = 0),说明读锁此时被其他线程占用,所以当前线程不能获取写锁,自然返回false。或者锁状态不为零,而写锁的状态也不为0,但是获取写锁的线程不是当前线程,则当前线程也不能获取写锁。
(3)判断当前线程获取写锁是否超过最大次数,若超过,抛异常,反之更新同步状态(此时当前线程已获取写锁,更新是线程安全的),返回true。
(4)如果state为0,此时读锁或写锁都没有被获取,判断是否需要阻塞(公平和非公平方式实现不同),在非公平策略下总是不会被阻塞,在公平策略下会进行判断(判断同步队列中是否有等待时间更长的线程,若存在,则需要被阻塞,否则,无需阻塞),如果不需要阻塞,则CAS更新同步状态,若CAS成功则返回true,失败则说明锁被别的线程抢去了,返回false。如果需要阻塞则也返回false。
(5)成功获取写锁后,将当前线程设置为占有写锁的线程,返回true。
写锁的释放,tryRelease方法:
1 protected final boolean tryRelease(int releases) {
2 //若锁的持有者不是当前线程,抛出异常
3 if (!isHeldExclusively())
4 throw new IllegalMonitorStateException();
5 //写锁的新线程数
6 int nextc = getState() - releases;
7 //如果独占模式重入数为0了,说明独占模式被释放
8 boolean free = exclusiveCount(nextc) == 0;
9 if (free)
10 //若写锁的新线程数为0,则将锁的持有者设置为null
11 setExclusiveOwnerThread(null);
12 //设置写锁的新线程数
13 //不管独占模式是否被释放,更新独占重入数
14 setState(nextc);
15 return free;
16 }
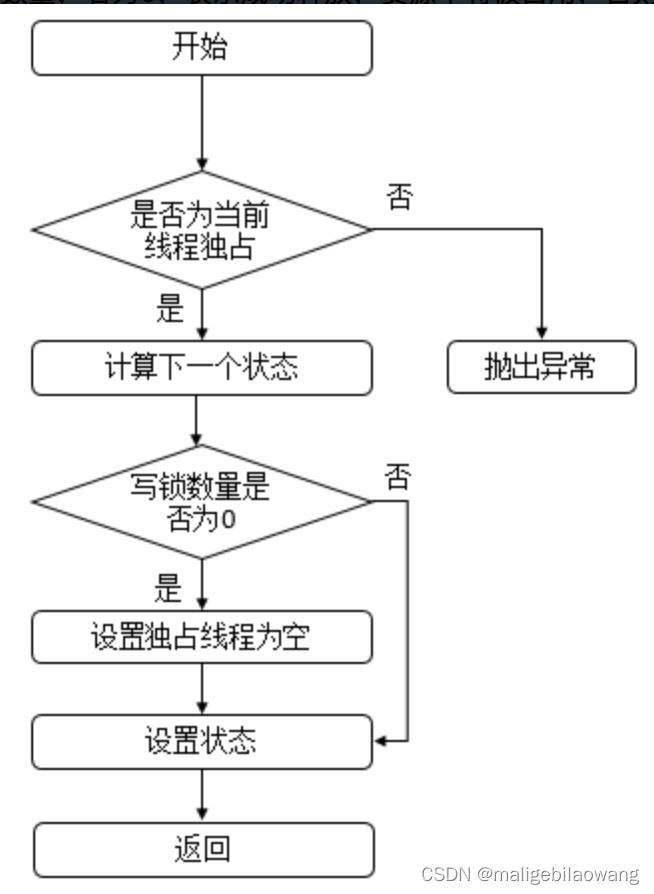
写锁的释放过程还是相对而言比较简单的:首先查看当前线程是否为写锁的持有者,如果不是抛出异常。然后检查释放后写锁的线程数是否为0,如果为0则表示写锁空闲了,释放锁资源将锁的持有线程设置为null,否则释放仅仅只是一次重入锁而已,并不能将写锁的线程清空。
说明:此方法用于释放写锁资源,首先会判断该线程是否为独占线程,若不为独占线程,则抛出异常,否则,计算释放资源后的写锁的数量,若为0,表示成功释放,资源不将被占用,否则,表示资源还被占用。其方法流程图如下。
5、读锁的获取与释放
类似于写锁,读锁的lock和unlock的实际实现对应Sync的 tryAcquireShared 和 tryReleaseShared方法。
读锁的获取,看下tryAcquireShared方法
1 protected final int tryAcquireShared(int unused) {
2 // 获取当前线程
3 Thread current = Thread.currentThread();
4 // 获取状态
5 int c = getState();
6
7 //如果写锁线程数 != 0 ,且独占锁不是当前线程则返回失败,因为存在锁降级
8 if (exclusiveCount(c) != 0 &&
9 getExclusiveOwnerThread() != current)
10 return -1;
11 // 读锁数量
12 int r = sharedCount(c);
13 /*
14 * readerShouldBlock():读锁是否需要等待(公平锁原则)
15 * r < MAX_COUNT:持有线程小于最大数(65535)
16 * compareAndSetState(c, c + SHARED_UNIT):设置读取锁状态
17 */
18 // 读线程是否应该被阻塞、并且小于最大值、并且比较设置成功
19 if (!readerShouldBlock() &&
20 r < MAX_COUNT &&
21 compareAndSetState(c, c + SHARED_UNIT)) {
22 //r == 0,表示第一个读锁线程,第一个读锁firstRead是不会加入到readHolds中
23 if (r == 0) { // 读锁数量为0
24 // 设置第一个读线程
25 firstReader = current;
26 // 读线程占用的资源数为1
27 firstReaderHoldCount = 1;
28 } else if (firstReader == current) { // 当前线程为第一个读线程,表示第一个读锁线程重入
29 // 占用资源数加1
30 firstReaderHoldCount++;
31 } else { // 读锁数量不为0并且不为当前线程
32 // 获取计数器
33 HoldCounter rh = cachedHoldCounter;
34 // 计数器为空或者计数器的tid不为当前正在运行的线程的tid
35 if (rh == null || rh.tid != getThreadId(current))
36 // 获取当前线程对应的计数器
37 cachedHoldCounter = rh = readHolds.get();
38 else if (rh.count == 0) // 计数为0
39 //加入到readHolds中
40 readHolds.set(rh);
41 //计数+1
42 rh.count++;
43 }
44 return 1;
45 }
46 return fullTryAcquireShared(current);
47 }
其中sharedCount方法表示占有读锁的线程数量,源码如下:
static int sharedCount(int c) { return c >>> SHARED_SHIFT; }
说明:直接将state右移16位,就可以得到读锁的线程数量,因为state的高16位表示读锁,对应的第十六位表示写锁数量。
读锁获取锁的过程比写锁稍微复杂些,首先判断写锁是否为0并且当前线程不占有独占锁,直接返回;否则,判断读线程是否需要被阻塞并且读锁数量是否小于最大值并且比较设置状态成功,若当前没有读锁,则设置第一个读线程firstReader和firstReaderHoldCount;若当前线程线程为第一个读线程,则增加firstReaderHoldCount;否则,将设置当前线程对应的HoldCounter对象的值。流程图如下。
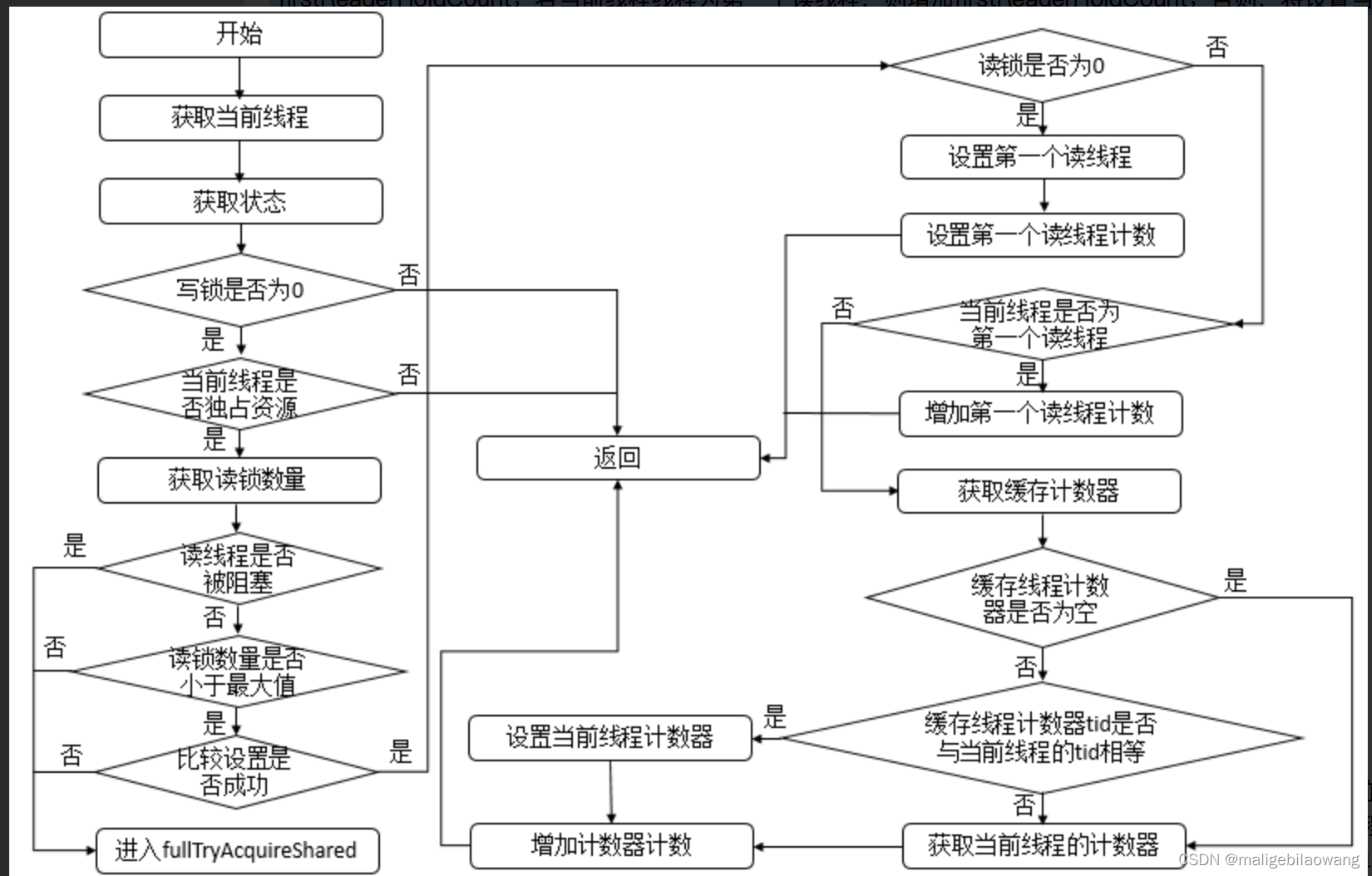
注意:更新成功后会在firstReaderHoldCount中或readHolds(ThreadLocal类型的)的本线程副本中记录当前线程重入数(23行至43行代码),这是为了实现jdk1.6中加入的getReadHoldCount()方法的,这个方法能获取当前线程重入共享锁的次数(state中记录的是多个线程的总重入次数),加入了这个方法让代码复杂了不少,但是其原理还是很简单的:如果当前只有一个线程的话,还不需要动用ThreadLocal,直接往firstReaderHoldCount这个成员变量里存重入数,当有第二个线程来的时候,就要动用ThreadLocal变量readHolds了,每个线程拥有自己的副本,用来保存自己的重入数。
fullTryAcquireShared方法:
final int fullTryAcquireShared(Thread current) {
HoldCounter rh = null;
for (;;) { // 无限循环
// 获取状态
int c = getState();
if (exclusiveCount(c) != 0) { // 写线程数量不为0
if (getExclusiveOwnerThread() != current) // 不为当前线程
return -1;
} else if (readerShouldBlock()) { // 写线程数量为0并且读线程被阻塞
// Make sure we're not acquiring read lock reentrantly
if (firstReader == current) { // 当前线程为第一个读线程
// assert firstReaderHoldCount > 0;
} else { // 当前线程不为第一个读线程
if (rh == null) { // 计数器不为空
//
rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current)) { // 计数器为空或者计数器的tid不为当前正在运行的线程的tid
rh = readHolds.get();
if (rh.count == 0)
readHolds.remove();
}
}
if (rh.count == 0)
return -1;
}
}
if (sharedCount(c) == MAX_COUNT) // 读锁数量为最大值,抛出异常
throw new Error("Maximum lock count exceeded");
if (compareAndSetState(c, c + SHARED_UNIT)) { // 比较并且设置成功
if (sharedCount(c) == 0) { // 读线程数量为0
// 设置第一个读线程
firstReader = current;
//
firstReaderHoldCount = 1;
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
if (rh == null)
rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
cachedHoldCounter = rh; // cache for release
}
return 1;
}
}
}
说明:在tryAcquireShared函数中,如果下列三个条件不满足(读线程是否应该被阻塞、小于最大值、比较设置成功)则会进行fullTryAcquireShared函数中,它用来保证相关操作可以成功。其逻辑与tryAcquireShared逻辑类似,不再累赘。
读锁的释放,tryReleaseShared方法
1 protected final boolean tryReleaseShared(int unused) {
2 // 获取当前线程
3 Thread current = Thread.currentThread();
4 if (firstReader == current) { // 当前线程为第一个读线程
5 // assert firstReaderHoldCount > 0;
6 if (firstReaderHoldCount == 1) // 读线程占用的资源数为1
7 firstReader = null;
8 else // 减少占用的资源
9 firstReaderHoldCount--;
10 } else { // 当前线程不为第一个读线程
11 // 获取缓存的计数器
12 HoldCounter rh = cachedHoldCounter;
13 if (rh == null || rh.tid != getThreadId(current)) // 计数器为空或者计数器的tid不为当前正在运行的线程的tid
14 // 获取当前线程对应的计数器
15 rh = readHolds.get();
16 // 获取计数
17 int count = rh.count;
18 if (count <= 1) { // 计数小于等于1
19 // 移除
20 readHolds.remove();
21 if (count <= 0) // 计数小于等于0,抛出异常
22 throw unmatchedUnlockException();
23 }
24 // 减少计数
25 --rh.count;
26 }
27 for (;;) { // 无限循环
28 // 获取状态
29 int c = getState();
30 // 获取状态
31 int nextc = c - SHARED_UNIT;
32 if (compareAndSetState(c, nextc)) // 比较并进行设置
33 // Releasing the read lock has no effect on readers,
34 // but it may allow waiting writers to proceed if
35 // both read and write locks are now free.
36 return nextc == 0;
37 }
38 }
说明:此方法表示读锁线程释放锁。首先判断当前线程是否为第一个读线程firstReader,若是,则判断第一个读线程占有的资源数firstReaderHoldCount是否为1,若是,则设置第一个读线程firstReader为空,否则,将第一个读线程占有的资源数firstReaderHoldCount减1;若当前线程不是第一个读线程,那么首先会获取缓存计数器(上一个读锁线程对应的计数器 ),若计数器为空或者tid不等于当前线程的tid值,则获取当前线程的计数器,如果计数器的计数count小于等于1,则移除当前线程对应的计数器,如果计数器的计数count小于等于0,则抛出异常,之后再减少计数即可。无论何种情况,都会进入无限循环,该循环可以确保成功设置状态state。其流程图如下。
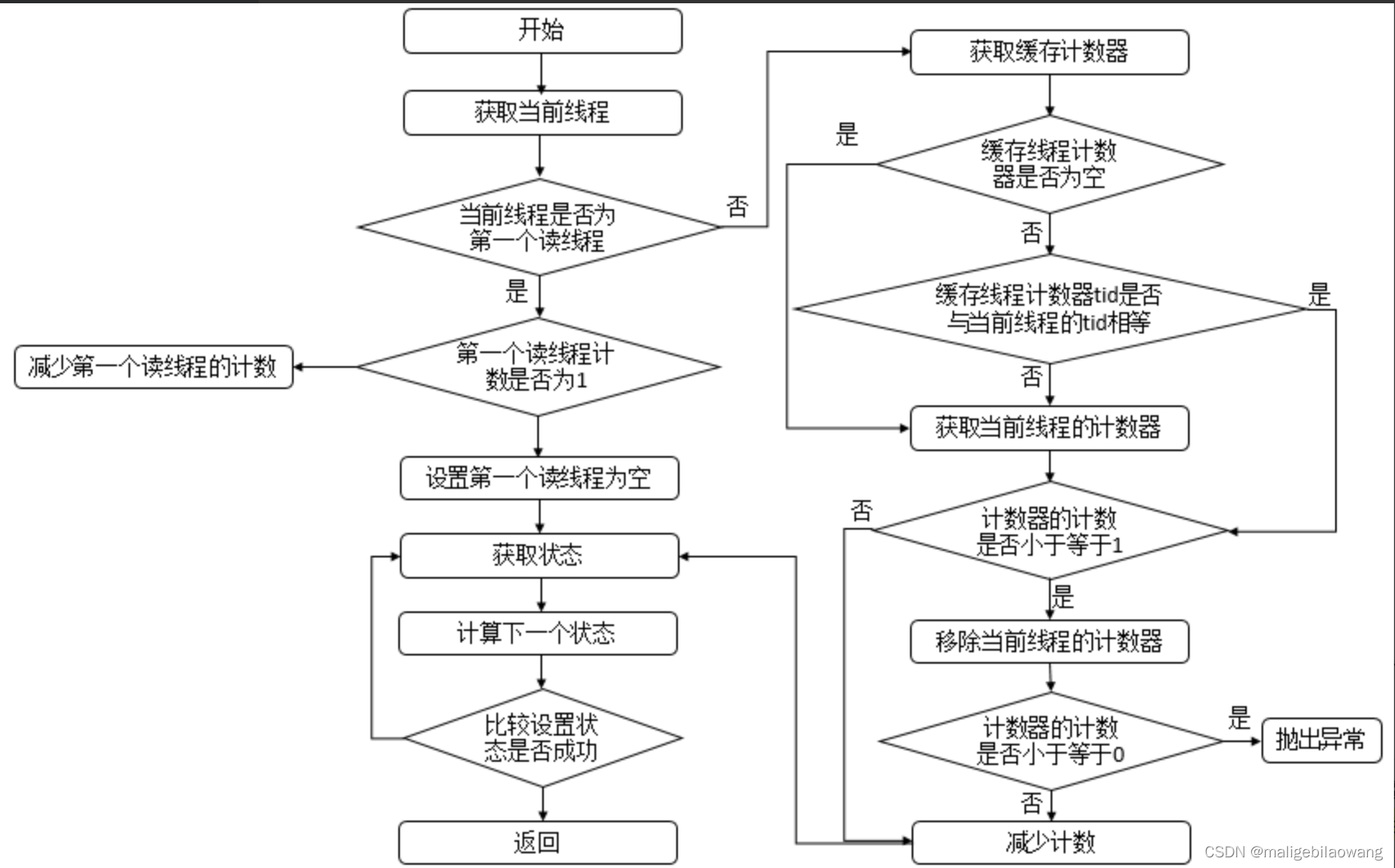
在读锁的获取、释放过程中,总是会有一个对象存在着,同时该对象在获取线程获取读锁是+1,释放读锁时-1,该对象就是HoldCounter。
要明白HoldCounter就要先明白读锁。前面提过读锁的内在实现机制就是共享锁,对于共享锁其实我们可以稍微的认为它不是一个锁的概念,它更加像一个计数器的概念。一次共享锁操作就相当于一次计数器的操作,获取共享锁计数器+1,释放共享锁计数器-1。只有当线程获取共享锁后才能对共享锁进行释放、重入操作。所以HoldCounter的作用就是当前线程持有共享锁的数量,这个数量必须要与线程绑定在一起,否则操作其他线程锁就会抛出异常。
先看读锁获取锁的部分:
if (r == 0) {//r == 0,表示第一个读锁线程,第一个读锁firstRead是不会加入到readHolds中
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {//第一个读锁线程重入
firstReaderHoldCount++;
} else { //非firstReader计数
HoldCounter rh = cachedHoldCounter;//readHoldCounter缓存
//rh == null 或者 rh.tid != current.getId(),需要获取rh
if (rh == null || rh.tid != current.getId())
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh); //加入到readHolds中
rh.count++; //计数+1
}
这里为什么要搞一个firstRead、firstReaderHoldCount呢?而不是直接使用else那段代码?这是为了一个效率问题,firstReader是不会放入到readHolds中的,如果读锁仅有一个的情况下就会避免查找readHolds。可能就看这个代码还不是很理解HoldCounter。我们先看firstReader、firstReaderHoldCount的定义:
private transient Thread firstReader = null;
private transient int firstReaderHoldCount;
这两个变量比较简单,一个表示线程,当然该线程是一个特殊的线程,一个是firstReader的重入计数。
HoldCounter的定义:
static final class HoldCounter {
int count = 0;
final long tid = Thread.currentThread().getId();
}
在HoldCounter中仅有count和tid两个变量,其中count代表着计数器,tid是线程的id。但是如果要将一个对象和线程绑定起来仅记录tid肯定不够的,而且HoldCounter根本不能起到绑定对象的作用,只是记录线程tid而已。
诚然,在java中,我们知道如果要将一个线程和对象绑定在一起只有ThreadLocal才能实现。所以如下:
static final class ThreadLocalHoldCounter
extends ThreadLocal<HoldCounter> {
public HoldCounter initialValue() {
return new HoldCounter();
}
}
ThreadLocalHoldCounter继承ThreadLocal,并且重写了initialValue方法。
故而,HoldCounter应该就是绑定线程上的一个计数器,而ThradLocalHoldCounter则是线程绑定的ThreadLocal。从上面我们可以看到ThreadLocal将HoldCounter绑定到当前线程上,同时HoldCounter也持有线程Id,这样在释放锁的时候才能知道ReadWriteLock里面缓存的上一个读取线程(cachedHoldCounter)是否是当前线程。这样做的好处是可以减少ThreadLocal.get()的次数,因为这也是一个耗时操作。需要说明的是这样HoldCounter绑定线程id而不绑定线程对象的原因是避免HoldCounter和ThreadLocal互相绑定而GC难以释放它们(尽管GC能够智能的发现这种引用而回收它们,但是这需要一定的代价),所以其实这样做只是为了帮助GC快速回收对象而已。
三、总结
通过上面的源码分析,我们可以发现一个现象:
在线程持有读锁的情况下,该线程不能取得写锁(因为获取写锁的时候,如果发现当前的读锁被占用,就马上获取失败,不管读锁是不是被当前线程持有)。
在线程持有写锁的情况下,该线程可以继续获取读锁(获取读锁时如果发现写锁被占用,只有写锁没有被当前线程占用的情况才会获取失败)。
仔细想想,这个设计是合理的:因为当线程获取读锁的时候,可能有其他线程同时也在持有读锁,因此不能把获取读锁的线程“升级”为写锁;而对于获得写锁的线程,它一定独占了读写锁,因此可以继续让它获取读锁,当它同时获取了写锁和读锁后,还可以先释放写锁继续持有读锁,这样一个写锁就“降级”为了读锁。
综上:
一个线程要想同时持有写锁和读锁,必须先获取写锁再获取读锁;写锁可以“降级”为读锁;读锁不能“升级”为写锁。


![[算法]计数排序和基数排序](https://img-blog.csdnimg.cn/6b35d818ace64ef09ea555075d06503f.png)