WeSpeaker正式更新C++部署链路,推理引擎使用OnnxRuntime,支持从语音中提取Speaker Embedding信息,代码详见WeSpeaker/runtime[1]。
Libtorch和onnx的选择?
-
Speaker Embedding提取任务流程简单,并且声纹模型(如ResNet\ECAPA-TDNN)相对简单,只需简单几行代码即可导出Onnx模型;
-
Libtorch包过大,并且使用过程中需要和pytorch的版本一致,OnnxRuntime相对轻便,只需12M左右;
故采用OnnxRuntime推理引擎,欢迎贡献基于其它推理引擎的代码。
整体概括
整体包含四部分:frontend、speaker、utils、bin
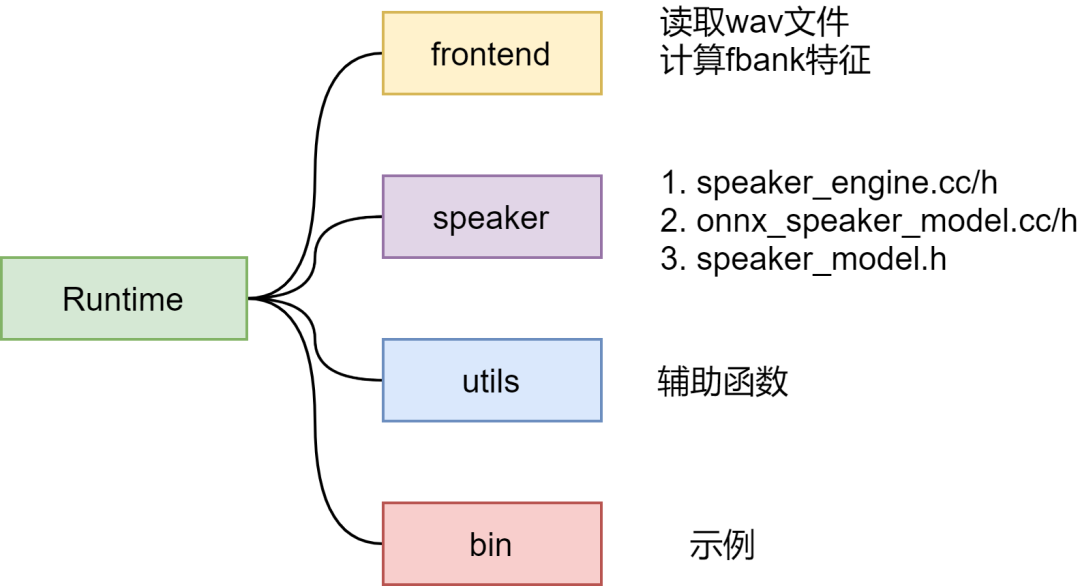
frontend
用于计算fbank特征,该部分代码复用WeNet-frontend[2],支持读取wav文件,计算fbank特征。
speaker
包含主要的推理代码
-
speaker_model.h: 定义基类
SpeakerModel:便于实现对不同推理引擎的支持。 -
onnx_speaker_model.cc/h:继承基类
SpeakerModel,基于OnnxRuntime推理引擎。 -
speaker_engine.cc /h: 实现
SpeakerEngine类,供外部调用:
int EmbeddingSize();
-
返回Embedding的大小,用于推理前申请空间。
void ExtractFeature(const int16_t* data, int data_size,
std::vector<std::vector<std::vector<float>>>* chunks_feat);
-
提取fbank特征,如果SamplesPerChunk<=0, 对整个句子提取特征,否则分块计算特征,块大小为SamplesPerChunk。
-
data:输入数据的地址,数据类型为int16
-
data_size: 输入数据的长度
-
chunks_feat: 输出特征,大小为[n, T, D]
-
void ExtractEmbedding(const int16_t* data, int data_size,
std::vector<float>* avg_emb);
-
输入音频数据,提取Embedding特征。注意:对每个chunk提取embedding,最终取平均输出。
-
data: 输入数据地址,数据类型为int16
-
data_size: 输入数据的长度
-
avg_emb: 输出embedding特征
-
float CosineSimilarity(const std::vector<float>& emb1,
const std::vector<float>& emb2)
-
计算两个embedding之间的余弦相似度得分。
utils
包含辅助函数,比如WriteToFile、ReadToFile将embedding信息写入文件或读取文件。
bin
提供两个示例。
1、asv_main.cc: 计算两条语音的相似度
export GLOG_logtostderr=1
export GLOG_v=2
onnx_dir=your_model_dir
./build/bin/asv_main \
--enroll_wav wav1_path \
--test_wav wav2_path \
--threshold 0.5 \
--speaker_model_path $onnx_dir/final.onnx
2、extract_emb_main.cc: 批量提取embedding并保存到txt文件中,同时计算RTF
export GLOG_logtostderr=1
export GLOG_v=2
wav_scp=your_test_wav_scp
onnx_dir=your_model_dir
embed_out=your_embedding_txt
./build/bin/extract_emb_main \
--wav_list $wav_scp \
--result $embed_out \
--speaker_model_path $onnx_dir/final.onnx
--SamplesPerChunk 80000 # 5s
benchmark
1、RTF
num_threads = 1
SamplesPerChunk = 80000
CPU: Intel(R) Xeon(R) Platinum 8160 CPU @ 2.10GHz
| Model[3] | Params | RTF |
|---|---|---|
| ECAPA-TDNN (C=512) | 6.19 M | 0.018351 |
| ECAPA-TDNN (C=1024) | 14.65 M | 0.041724 |
| RepVGG-TINY-A0 | 6.26 M | 0.055117 |
| ResNet-34 | 6.63 M | 0.060735 |
| ResNet-152 | 19.88 M | 0.179379 |
| ResNet-221 | 23.86 M | 0.267511 |
| ResNet-293 | 28.69 M | 0.364011 |
2、结果一致性
使用voxceleb测试,模型为resnet-34
| Model | vox-O | vox-E | vox-H |
|---|---|---|---|
| ResNet-34-pt | 0.814 | 0.933 | 1.679 |
| ResNet-34-onnx | 0.814 | 0.933 | 1.679 |
欢迎大家使用WeSpeaker,服务于各种下游任务,也欢迎社区的贡献和宝贵建议!
参考资料
[1] WeSpeaker/runtime: https://github.com/wenet-e2e/wespeaker/tree/master/runtime/onnxruntime
[2] WeNet-frontend: https://github.com/wenet-e2e/wenet/tree/main/runtime/core/frontend
[3] Model: https://github.com/wenet-e2e/wespeaker/blob/master/docs/pretrained.md