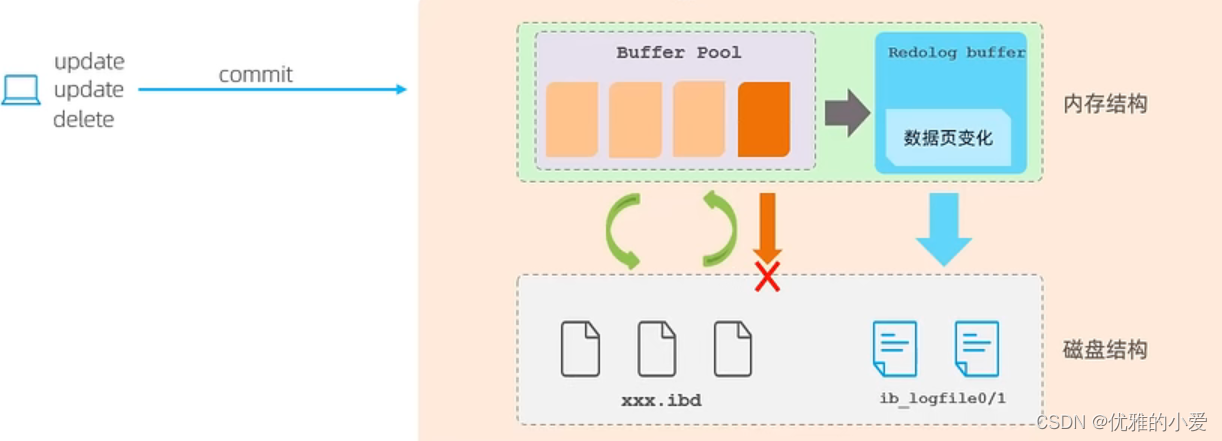
问题由来
数据redis和MySQL都要有一份,如何保证两边的一致性。
- 如果redis中有数据:需要和数据库中的值相同
- 如果redis中没有数据:数据库中的值是最新值,且准备会写redis
缓存操作分类
- 自读缓存
- 读写缓存:
(一)同步直写策略:
写数据后也同步写redis缓存,缓存和数据库中的数据一致;
对于读写缓存来说,要想报增缓存和数据库中的数据一致,就要采用同步直写策略。
(二)异步缓写策略
正常业务运行中,mysql数据变动了,但是可以在业务上容许出现一定时间后才作用于redis,比如长裤、物流系统;
异常情况出现了,不得不将失败的动作重新修补,有可能需要节奏Kafka或者RbbitMQ等消息中间件,实现重试重写。
一致性问题:
ckage com.atguigu.redis.service;
import com.atguigu.redis.entities.User;
import com.atguigu.redis.mapper.UserMapper;
import io.swagger.models.auth.In;
import lombok.extern.slf4j.Slf4j;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.ValueOperations;
import org.springframework.stereotype.Service;
import org.springframework.web.bind.annotation.PathVariable;
import javax.annotation.Resource;
import java.util.concurrent.TimeUnit;
/**
*
* 不能直接用哦,理解高并发下“双检加锁”的思路。
*/
@Service
@Slf4j
public class UserService {
public static final String CACHE_KEY_USER = "user:";
@Resource
private UserMapper userMapper;
@Resource
private RedisTemplate redisTemplate;
/**
* 业务逻辑没有写错,对于小厂中厂(QPS《=1000)可以使用,但是大厂不行
* @param id
* @return
*/
public User findUserById(Integer id)
{
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql
user = (User) redisTemplate.opsForValue().get(key);
if(user == null)
{
//2 redis里面无,继续查询mysql
user = userMapper.selectByPrimaryKey(id);
if(user == null)
{
//3.1 redis+mysql 都无数据
//你具体细化,防止多次穿透,我们业务规定,记录下导致穿透的这个key回写redis
return user;
}else{
//3.2 mysql有,需要将数据写回redis,保证下一次的缓存命中率
redisTemplate.opsForValue().set(key,user);
}
}
return user;
}
/**
* 加强补充,避免突然key失效了,打爆mysql,做一下预防,尽量不出现击穿的情况。
* @param id
* @return
*/
public User findUserById2(Integer id)
{
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql,
// 第1次查询redis,加锁前
user = (User) redisTemplate.opsForValue().get(key);
if(user == null) {
//2 大厂用,对于高QPS的优化,进来就先加锁,保证一个请求操作,让外面的redis等待一下,避免击穿mysql
synchronized (UserService.class){
//第2次查询redis,加锁后
user = (User) redisTemplate.opsForValue().get(key);
//3 二次查redis还是null,可以去查mysql了(mysql默认有数据)
if (user == null) {
//4 查询mysql拿数据(mysql默认有数据)
user = userMapper.selectByPrimaryKey(id);
if (user == null) {
return null;
}else{
//5 mysql里面有数据的,需要回写redis,完成数据一致性的同步工作
redisTemplate.opsForValue().setIfAbsent(key,user,7L,TimeUnit.DAYS);
}
}
}
}
return user;
}
}
数据库和缓存一致性的几种策略
目的:总之我们要到达最终的一致性。
(一)停机运维
- 挂牌报错,凌晨升级,温馨提示,服务降级
- 单线程,这样重量级的数据操作最好不要用多线程
(二)不停机的四种策略
①先更新数据库,再更新缓存
②先更新缓存,再更新数据库
③先删除缓存,再更新数据库(延伸:延迟双删)
④先更新数据库,再删除缓存
阿里巴巴的canal等中间件就是类似的思想,通过binlog日志去更新消息、缓存,这些中间件去订阅binlog的日志。
比如:
总结:如果我们想着A/B等多个线程去竞争,无论如何都有可能导致不一致。但一般系统都已数据库为最终解释权,这样3和4的方案会好许多,最不推荐的是第二种。
1 先删除缓存值再更新数据库,有可能导致请求因缓存缺失而访问数据库,给数据库带来压力导致打满mysql。
2 如果业务应用中读取数据库和写缓存的时间不好估算,那么,延迟双删中的等待时间就不好设置。
如果业务叫非要一致性:那就别用缓存了。加一个页面返回也是一个很好的解决方案,不用太纠结这肉眼难见的事件。当然异常了还是得处理。