这篇文章主要是整理下使用pandas的一些技巧,因为经常不用它,这些指令忘得真的很快。前段时间在数模美赛中已经栽过跟头了,不希望以后遇到相关问题的时候还去网上查(主要是太杂了)。可能读者跟我有一样的问题,我在这里根据实际应用对照着使用这些方法,算是整理。
这里我的首要目标是完成任务,其次才是速度,特别是对一些赋值操作,其实这不是pandas所擅长的,pandas擅长的是快速的读和转换而不是update,一些操作真的想快需要其他包帮助(比如numpy向量化)。
这篇都是最简单机械的数据预处理,不包括异常值(outlier)检测等需要算法调优的部分。
pandas版本 1.3.2
numpy版本 1.21.2
目录
- 0. 数据集
- 1. 数据处理
- 1.1. 基本操作
- csv读取(小/大文件)
- 遍历(行/列/单元格)
- 取(单/多)行/列/单元格
- 简单高阶函数
- 任务1:取tsne1\tsne2两位小数,并输出这两列
- 任务2:保留word中含a的样本,标记word中a开头的样
- 任务3:将k++的标签转化为数字
- 任务4:给socre上套一个sigmoid,并把小于0.5的标记为0
- 代码和注意点
- 去重
- 任务1:删除全部重复的行
- 任务2:删除 1 try 和 5 tries 都重复的行
- 任务2:删除 1 try 和 5 tries 有一个重复的行
- 任务4:删除 1 try 中重复 且 5 tries 中大于平均数的行(条件去重)
- 代码及结果
- 2维转1维/1维转2维
- 保存
- 全部显示(行/列)
- 任务1:去标点(引号)
- 任务2:获取词数
- 任务3:建立词典
- 任务4:正则表达式把日期转化为标准日期和年月日列
- 任务代码
- 1.2. 增删改查空
- 空
- 任务1:定位某列空
- 任务2:定位含有空的行
- 任务3:统计有空行
- 任务4:删除有空行
- 任务5:替换空值
- 全部代码
- 增加行/列
- 合并行/列
- 数据准备
- 行合并
- 列合并
- 全部代码
- 删除行/列
- 查询修改行/列/单元格
- 1.3. 类似数据库操作
- 任务0:数据清洗(去含空去全重,计算sentence特征)
- 任务1:把数据按照列 k++ 的取值分成多个df。(超常用groupby)
- 任务2:把数据按照 score 的四分位数分成 4 个label 并 查看组中成员1 try, 2 tries, 5 tries 都大于平均水平的样本。(等比分割)
- 任务3:把数据按照 score 的取值区间等分成 5 个label。(等间分割)
- 任务4:计算列 k++ 中每个取值的其它列的平均值。(聚类常用)
- 任务5:把列 3 tries 和 2 tries 列中都低于平均值的数据去掉/把列 3 tries 或 2 tries 列中低于平均值的数据去掉。(基础,数据筛选常用)
- 任务6:把score列内容转化为 int 型的数据;把date转为时间数据。(时间序列)
- 任务7:统计word列内每个元素(字符串)含['a', 'b', 'c']中字符的个数总和,并将其存为一个新列。(nlp常用)
- 任务8:按照季度统计score_raw( ∑ i = 1 7 i t r i e s ∗ ( 7 − i ) \sum_{i=1}^{7}{i\ tries *(7-i)} ∑i=17i tries∗(7−i))并.Z-score标准化。(平平无奇特征工程计算)
- 任务9:将 sentence 长度在中位数之上或者 word 含['a', 'b', 'c']中字符的样本按照 k++ 分类统计(tsne1,tsne2)的欧式距离和,并去除距离最短和最长的样本后计算 score 的标准差,并赋给这些样本(没有什么意义就是练手)
- 代码合集
- 1.4. 计算
- 加减乘除方log
- 皮尔逊、余弦相似度
- 2. 数据概览
- 2.1. 统计
- 查看数据特性
- 按照某列的值排序
- 查看属性中元素为特定值的个数
- 2.2. 画图
- 饼图
- 柱状图
- 散点图
- 总结与感想
- 全部代码
- 参考
0. 数据集
做过的问题实在有点多,而且好多数据集很大很难搞,这里就以 2023 年美赛的数据集示范,中间加了点其他数据(文本、浮点、label):
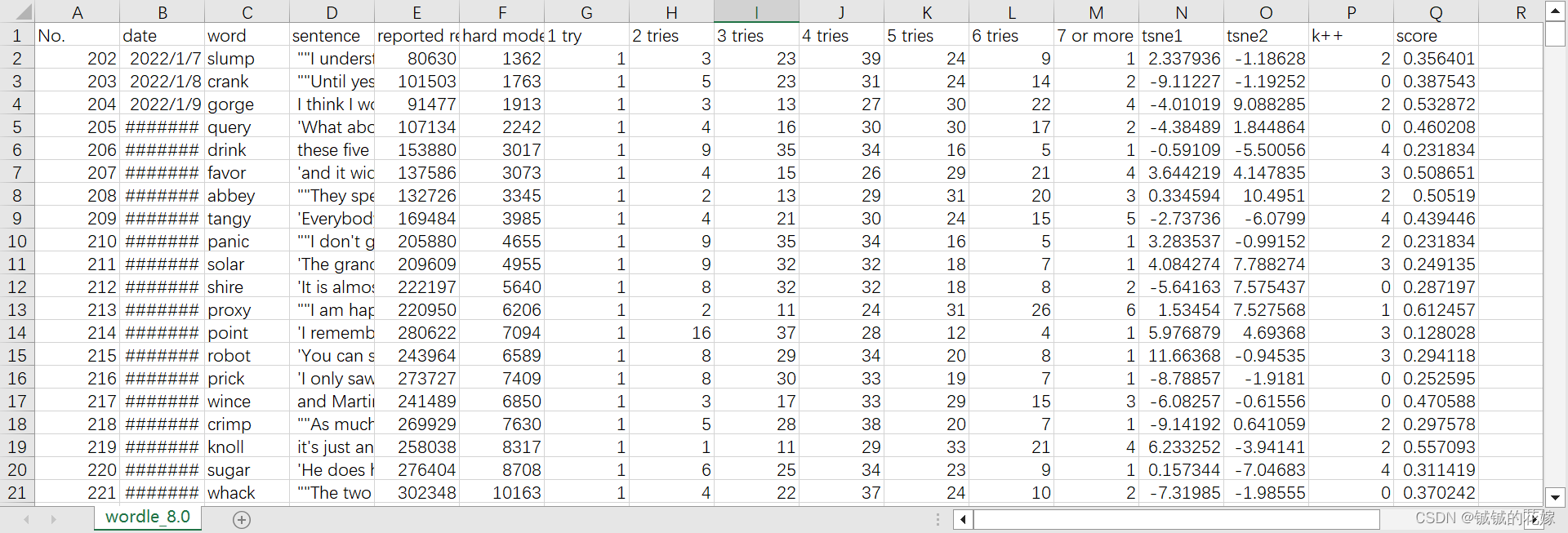
为了练习方便,找的数据集具有以下特性:
- 有类别数据(label):k++(分类),scre(回归)
- 有日期型数据:date
- 有文本型数据:word sentence
- 有空数据:自己查,我随便挖空的
- 有浮点型数据:tsne1,tsne2,score
- 有整型数据:剩下都是
不需要管这个表格的具体意义,本身就是拼凑出来的东西,练习方法而已。
数据集我传网盘上了,想练的也可以试试。
数据,密码jhnb
1. 数据处理
1.1. 基本操作
csv读取(小/大文件)
- file 直接读取
- table 对于特别大的csv,内存吃不下,只能分块读取
- reasder 对于特别大的数据,迭代着读
- 5Tb 往上的,那咱别用大熊猫了,得Hadoop了
# 获取数据
def get_data(file_name, encode):
file = pd.read_csv(file_name, encoding=encode)
# 读前100行,指定列
file1 = pd.read_csv(file_name, encoding=encode, nrows=100, usecols=['No.', 'word', 'reported results'])
# 特别大的csv我们分块读取分块处理(chunksize)
table = pd.read_csv(file_name, encoding=encode, chunksize=100)
for chunk in table:
# 该干嘛干嘛
print(type(chunk), chunk.shape)
# 迭代着读
reader = pd.read_csv(file_name, encoding=encode, iterator=True)
ret = [] # 结果存这
while 1:
try:
chunk = reader.get_chunk(100)
# 该干嘛干嘛
print(type(chunk), chunk.shape)
ret.append(chunk)
except StopIteration:
print("Iteration is stopped.")
break
print(ret)
# 超级超级大的数据(亿级别) 快跑~~
return file
遍历(行/列/单元格)
首先强调下这里的任务是遍历,与取特定行\列\单元格不同。
行遍历方法很多(基本就那两种),大多数情况下是弱水三千我只取一瓢饮,不过每个方法都有自己的特点,这里稍微提一下,一面又用到的时候一脸懵:
- df.iterrows:返回(index, Series)对。
- df.itertuples:读速度 itertuples > iat >iloc >> iterrows,写速度 iat >> iterrows >> iloc。缺点是只能读不能写。返回的是元组。
列遍历 iteritems() 将 DataFrame 的每一列迭代为 (列名, Series) 对,不过感觉用的还是比较少的,一般对某个列操作的比较多,遍历所有列基本没咋用。
单元格遍历的关键是使用高阶函数,直接 for 循环从速度上来讲狗都不用。
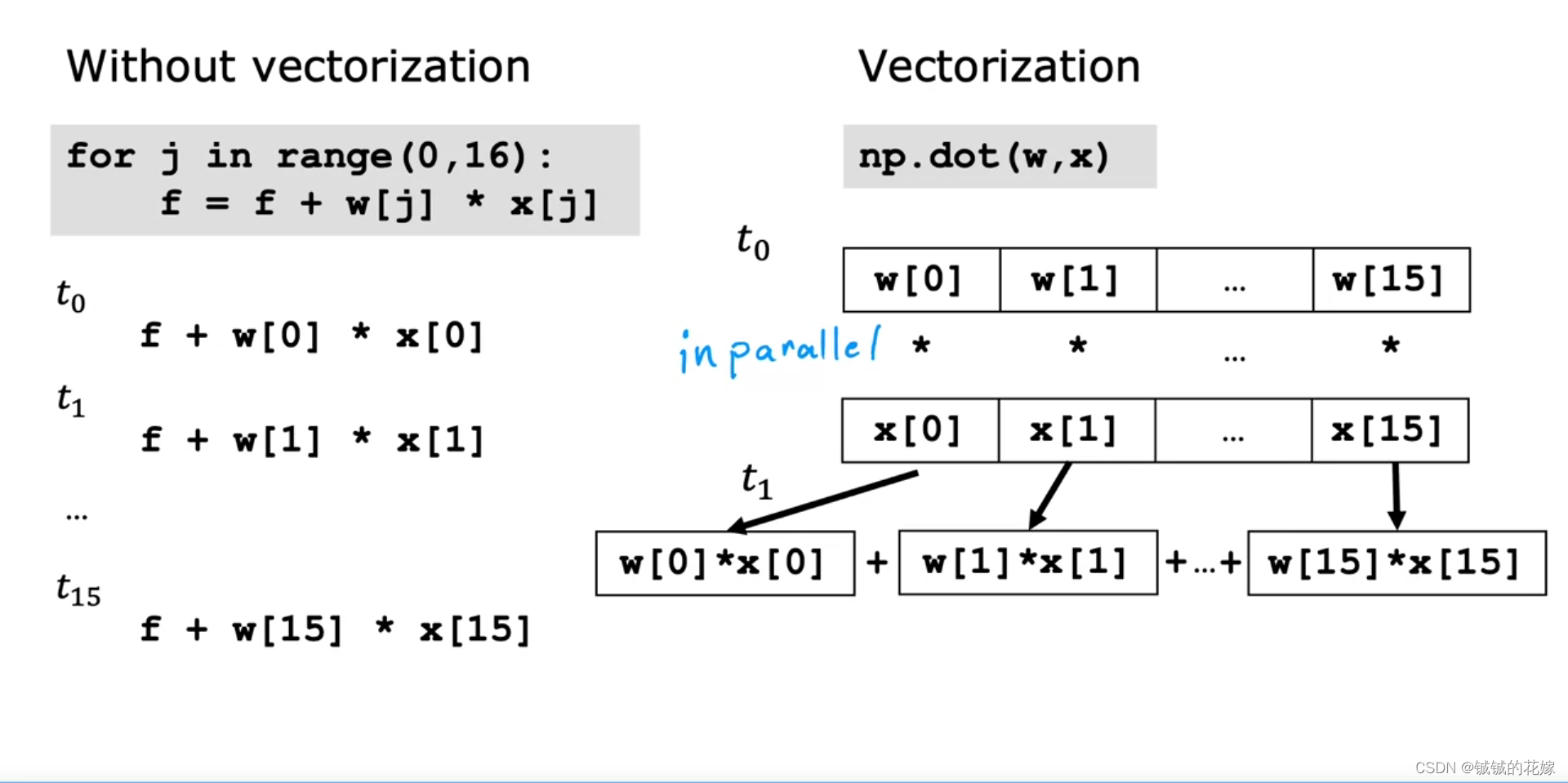
为什么for循环遍历被numpy之类的速度上吊打,觉得斯坦福大学吴恩达老师的解释很好,向量化的好处在这里体现的淋漓尽致:
此外,高阶函数在本篇的另一节,不会用的可以去看。
# 行/列/遍历
def read_row_column_cell(data):
data = data[data.columns[:3]]
data = data.head(3)
print("原数据:\n", data)
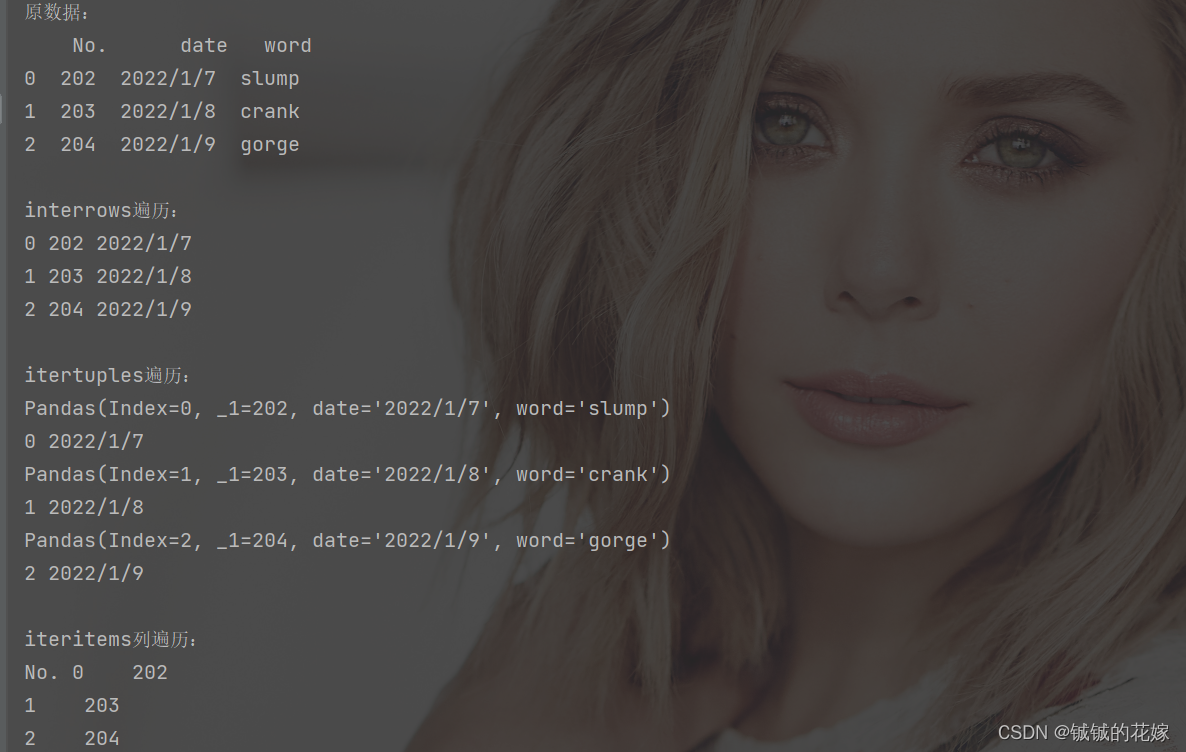
print("\ninterrows遍历:")
for index, row in data.iterrows():
print(index, row['No.'], row['date'])
print("\nitertuples遍历:")
for row in data.itertuples():
print(row)
print(getattr(row, 'Index'), getattr(row, 'date'))
print("\niteritems列遍历:")
for row in data.iteritems():
# 0是列名,1是列内容
print(row[0], row[1])
运行结果:

取(单/多)行/列/单元格
主要的注意点是:
- loc iloc 区别和联系
- at iat 区别和联系
- iat 的速度很快
- 条件提取在其他部分广泛用到,这里不提了
这部分没啥好说的,就直接代码展示吧
# 取行列单元格
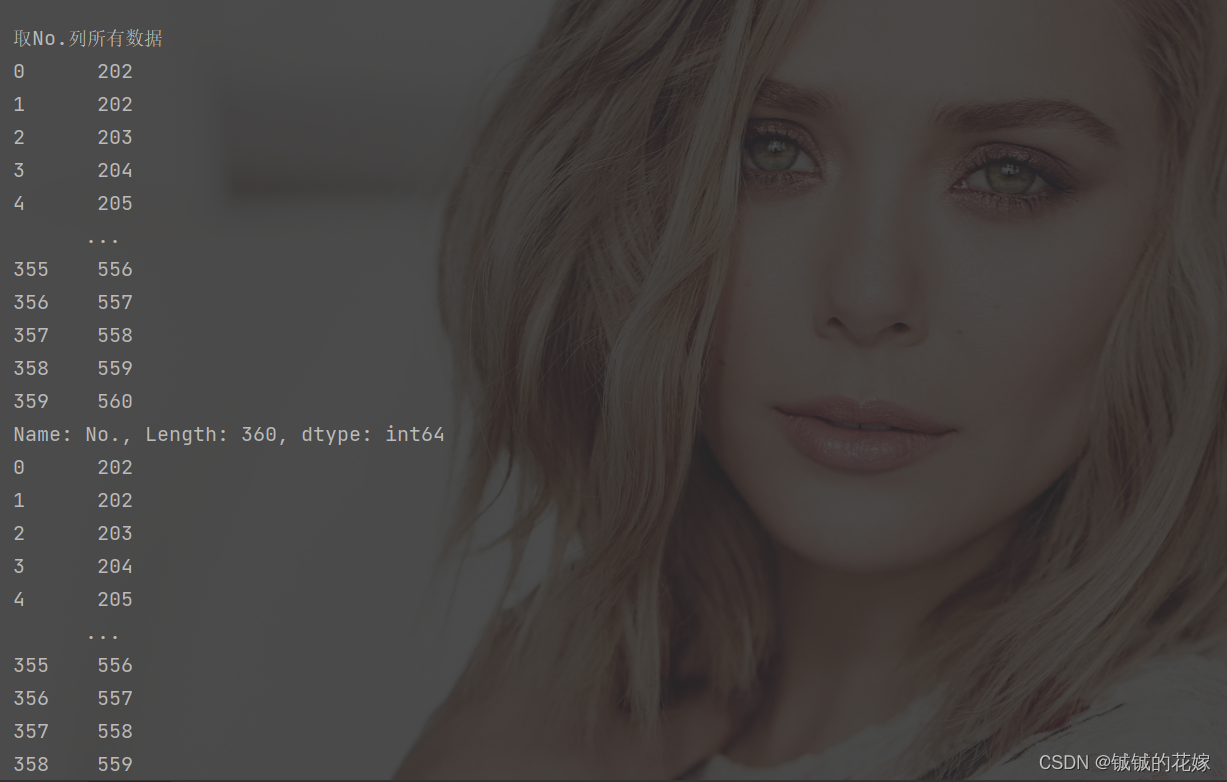
def get_line_col_cell(data):
data = data[["No.", "word", "1 try"]].copy()
print("\n取No.列所有数据")
print(data["No."])
print(data.loc[:, "No."])
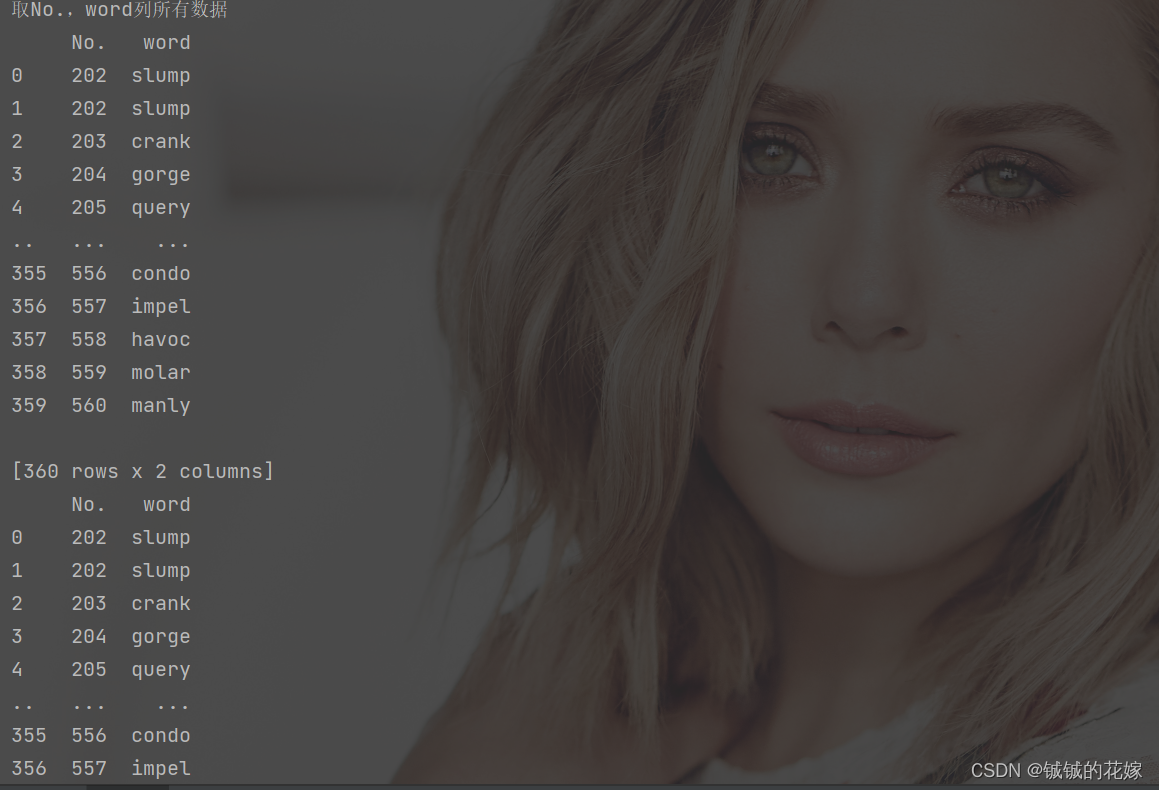
print("\n取No.,word列所有数据")
print(data[["No.", "word"]])
print(data.loc[:, ["No.", "word"]])
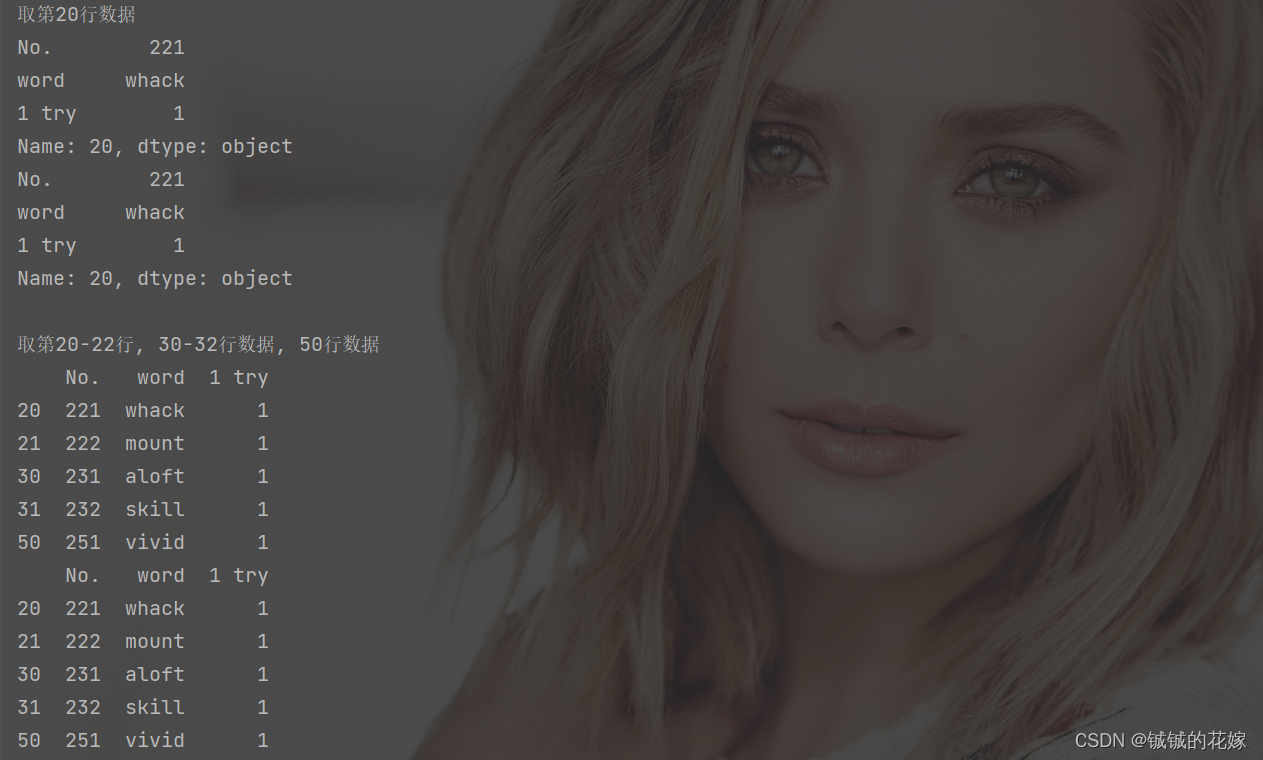
print("\n取第20行数据")
print(data.iloc[20])
print(data.loc[20])
print("\n取第20-22行, 30-32行数据, 50行数据")
print(data.iloc[np.r_[20:22, 30:32, 50]])
print(data.loc[np.r_[20:22, 30:32, 50]])
print("\n取word, 1 try 列第20-22行, 50行数据")
print(data.iloc[np.r_[20:22, 50], [1, 2]])
print(data.loc[np.r_[20:22, 50], ["word", "1 try"]])
print("\n分别取word列第20个单词,23个单词")
print(data.iloc[[20, 23], [1]].values[:, 0])
print(data.loc[[20, 23], "word"].values[:])
print(data.at[20, "word"], data.at[23, "word"])
print(data.iat[20, 1], data.at[23, "word"])
输出如下:

简单高阶函数
| 函数 | 效果 |
|---|---|
| map | 一般针对单列问题, 映射,说白了就是通过字典用一个东西替换另一个 |
| apply | 一般针对多列问题,比 map 更细,对于指定元素集使用我们自定义的函数或者np等其他包的函数 |
| applymap | 一般针对全元素问题, 跟楼上不同,这货是Dataframe专属,对于所有单元格的操作 |
lambda另说,这个是搭配其他高阶函数用的,在例子中会用到。反正不是啥难的东西,感受一下就会了。
任务1:取tsne1\tsne2两位小数,并输出这两列
感觉这里的 applymap 用的比较刻意,感觉在每列数据类型一样的时候直接对所有的元素批量处理比较合适。

任务2:保留word中含a的样本,标记word中a开头的样
同样的感觉也比较刻意。
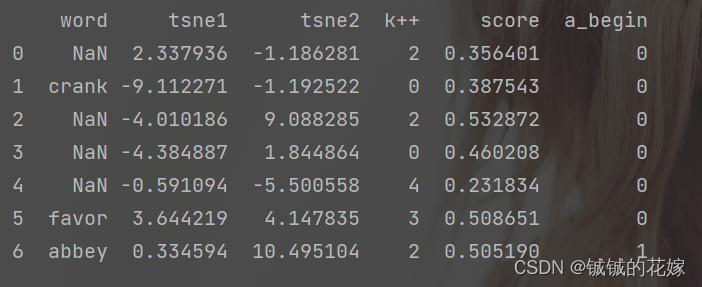
任务3:将k++的标签转化为数字
unique在知道有多少种取值是可以直接写死,在不知道的时候还是这么写比较好。
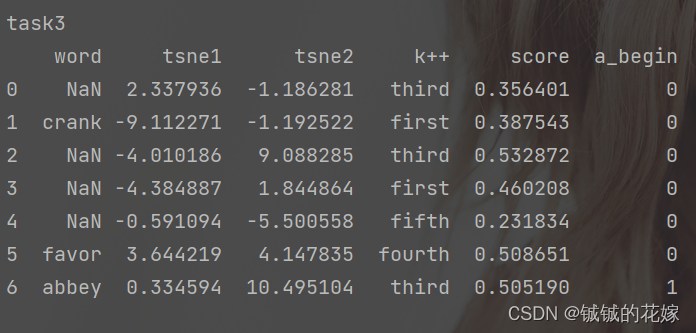
任务4:给socre上套一个sigmoid,并把小于0.5的标记为0
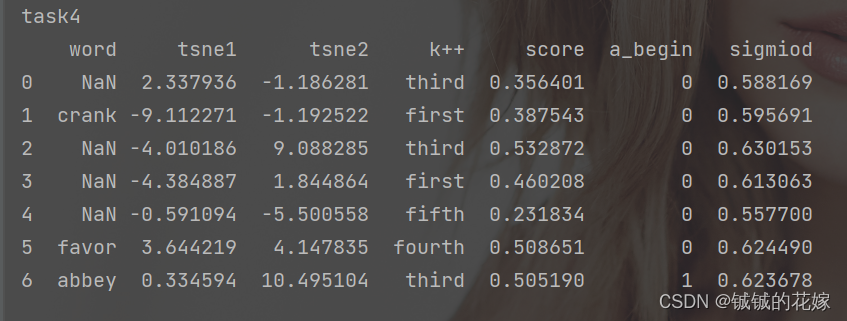
代码和注意点
代码如下:
# 高阶函数
def try_app_map_appmap(data):
# copy()不要忘记
data = data[["word", "tsne1", "tsne2", "k++", "score"]].copy()
print("\ntask1")
data_t = data[["tsne1", "tsne2"]]
data_t = data_t.applymap(lambda x: "%.2f" % x)
print(data_t.head(3))
# 楼上的操作多少有点刻意炫技,直接round也可以
print(data[["tsne1", "tsne2"]].round(2).head(3))
print("\ntask2")
data_w = data[["word"]]
bool_w = data_w.applymap(lambda x: "a" in x)
# 提一嘴,这样赋值等效 data["word"] = data_w[bool_w]
data.loc[:, "word"] = data_w[bool_w]
data["a_begin"] = data_w.applymap(lambda x: int("a" == x[0]))
print(data.head(7))
print("\ntask3")
name = ["first", "second", "third", "fourth", "fifth", "sixth"]
data.loc[:, "k++"] = data["k++"].map({i: name[i] for i in data["k++"].unique()})
print(data.head(7))
print("\ntask4")
def sig(series):
t = 1+np.exp(-series)
return 1/t
data.loc[:, "sigmiod"] = data["score"].apply(lambda x: sig(x))
print(data.head(7))
对于可能出现的错误:

注意一开始要加.copy(),原因这篇讲的非常透彻,大概意思是 data[["word", "tsne1", "tsne2", "k++", "score"]] 变量有点像C中的指针,它仅仅是指向地址的一个东西,如果你对这个指针的列或者行赋值,就会出现 warning ——因为指针没有行列,python 决定自作主张帮你 copy 一份 data 中的数据用着先。
去重
一开始造数据的时候忘记造重复数据了,现在重新造一份重复行和列的,重复单元格的反正随处可见就不搞了。
一般都是行去重
这里一招打通 df.drop_duplicates(subset,keep,inplace)
| 参数 | subset(列名) | keep(留哪个) | inplace(副本) |
|---|---|---|---|
| 默认值 | None | ‘first’ 留第一个重复的 | Flase 去重后返回副本 |
| 其他常见取值 | [“名1”, “名2”, “名n”] 都重复才扔 | ‘last’ 留最后一个重复的 ‘False’ 全删除 | True 直接在原数据上改 |
任务1:删除全部重复的行
data.drop_duplicates(keep=False, inplace=True)
任务2:删除 1 try 和 5 tries 都重复的行
data.drop_duplicates(subset=["1 try", "5 tries"], inplace=True)
任务2:删除 1 try 和 5 tries 有一个重复的行
# 没招了,只能一项一项来了
for col in ["1 try", "5 tries"]:
data.drop_duplicates(subset=col, keep="first", inplace=True)
print(data.shape)
任务4:删除 1 try 中重复 且 5 tries 中大于平均数的行(条件去重)
data = data[data["5 tries"] <= data["5 tries"].mean()].drop_duplicates(["1 try"])
代码及结果
# 去重
def drop_null(data_source):
data = data_source[["word", "sentence", "1 try", "2 tries", "3 tries", "4 tries", "5 tries"]].copy()
print("源数据\n", data.shape)
data.drop_duplicates(keep=False, inplace=True)
print("去完全重复行\n", data.shape)
data.drop_duplicates(subset=["1 try", "5 tries"], keep="first", inplace=True)
print("去 1, 5 都重复行\n", data.shape)
# 没招了,只能一项一项来了
for col in ["1 try", "5 tries"]:
data.drop_duplicates(subset=col, keep="first", inplace=True)
print("去 1, 5 重复行\n", data.shape)
data = data_source[["word", "sentence", "1 try", "2 tries", "3 tries", "4 tries", "5 tries"]].copy()
data = data[data["5 tries"] <= data["5 tries"].mean()].drop_duplicates(["1 try"])
print("条件去重\n", data.shape)
print("看看结果\n", data.head(4))
# 有的时候需要重置一下索引
print("重置索引\n", data.reset_index())
结果如下:
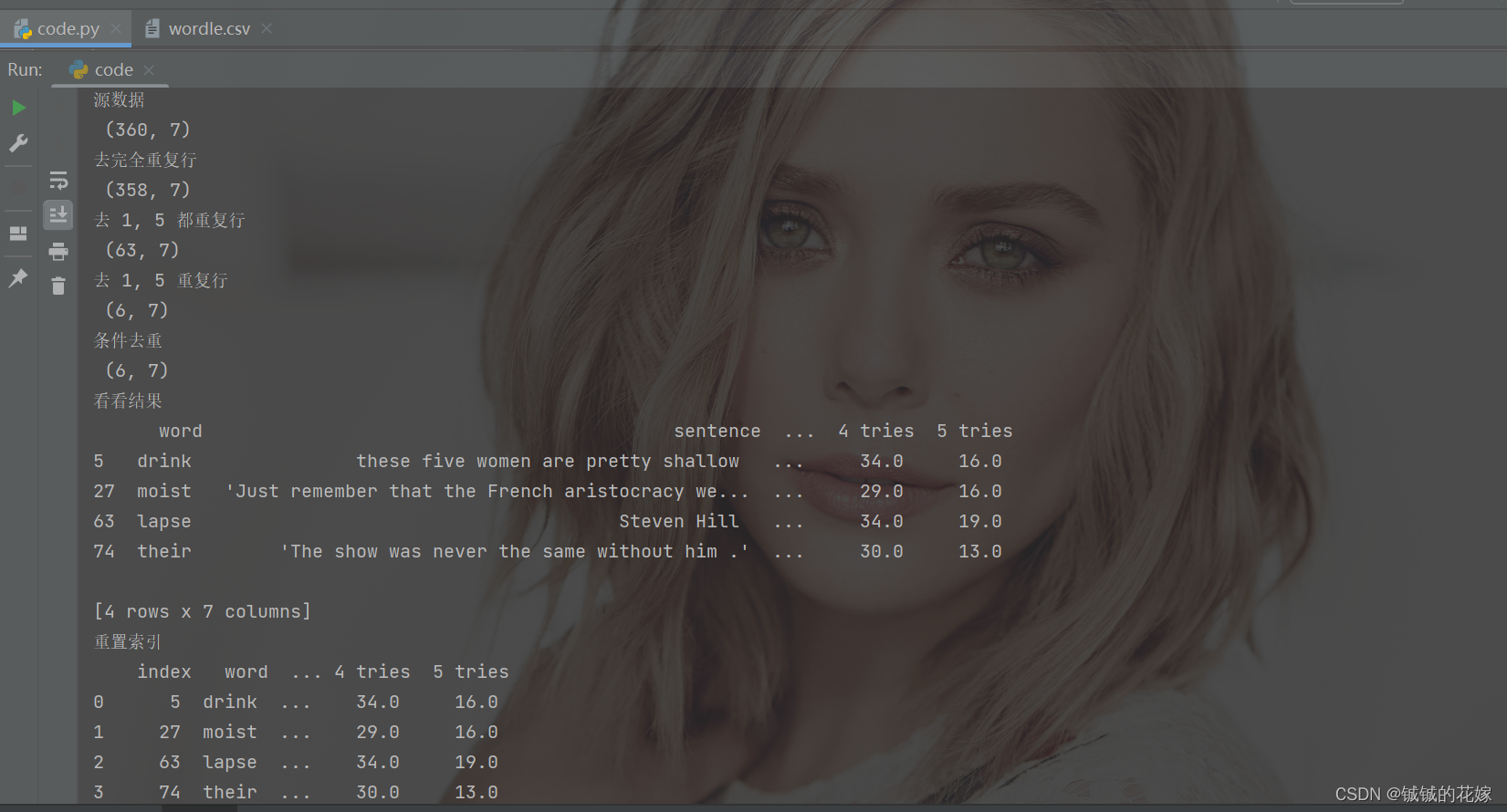
2维转1维/1维转2维
torch 用多了,对维度数据还是比较敏感的,不说高维转化,先记录下最常用的一维二维。
pivot & melt 方法不介绍,因为不太适用高维的情况,我们减少记忆负担,用 stack & unstack
# 维度变换
def stack_unstack(data):
print(data.shape, type(data), "\n\n")
data = data.stack()
print(data.shape, type(data))
print(data)
print(data.reset_index(), "\n\n")
data = data.unstack()
print(data.shape, type(data))
print(data)
结果如下:

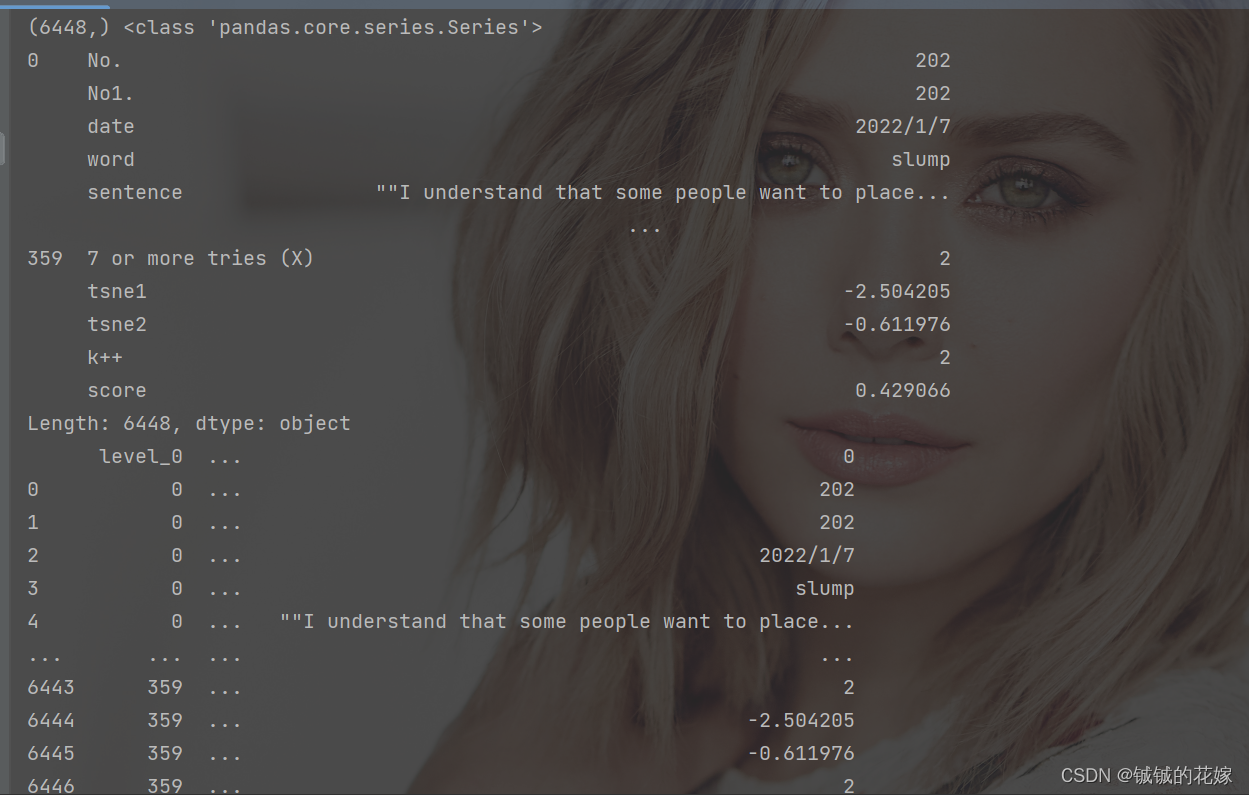
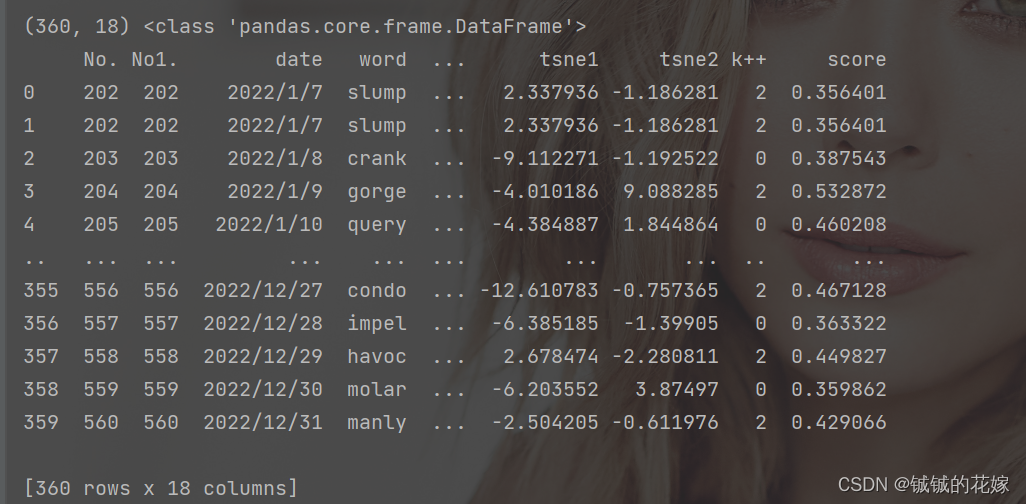
个人觉得第二张图里面 series 的索引还是比较有意思的。
保存
一般来说都是csv,有的时候tsv,区别是sep,tsv长这样:
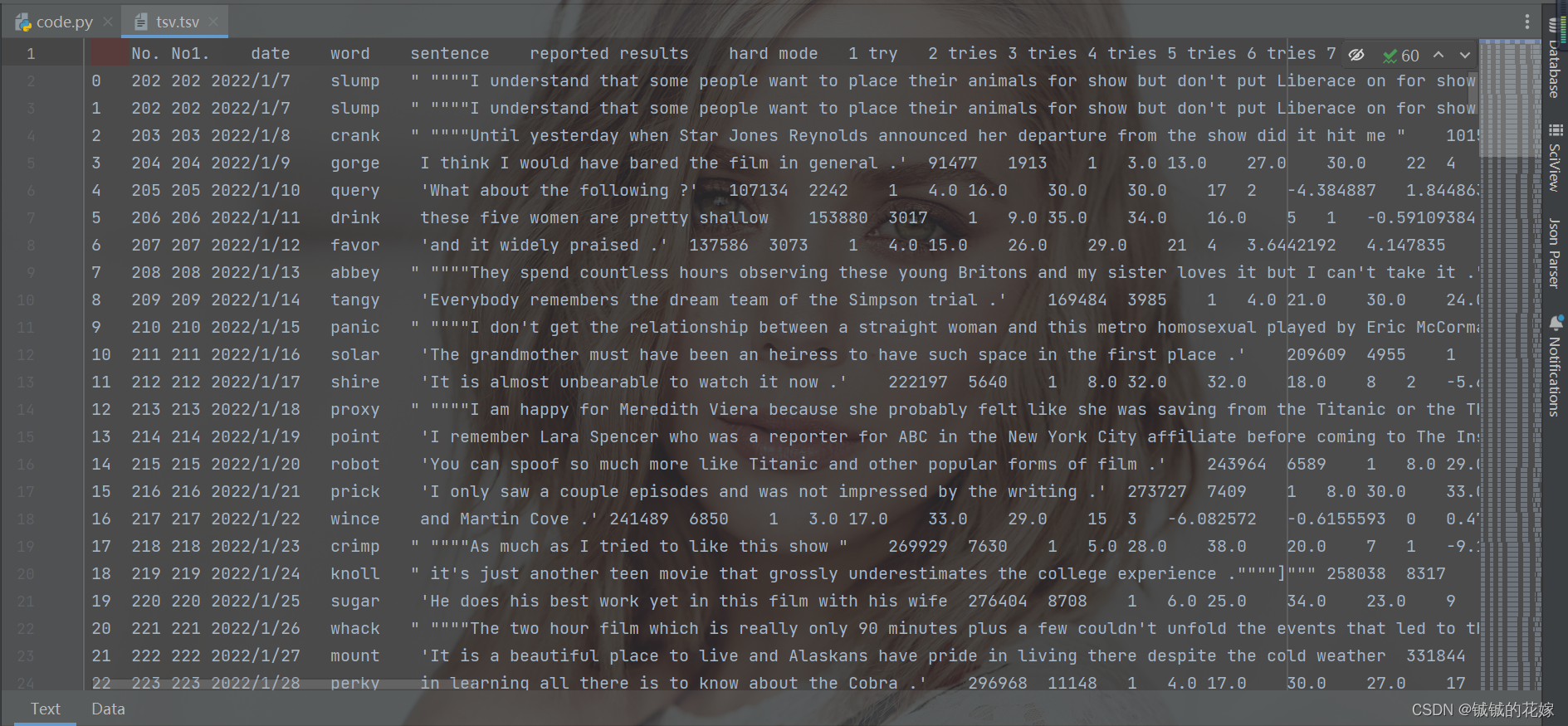
有的时候我会用excel看csv,但是编码离谱,这个需要注意,一般来说是 utf-8,但是想用 excel 看可以用 utf-8-sig, 这个也可以用 utf-8 读取而且在 excel 中也不会乱码。
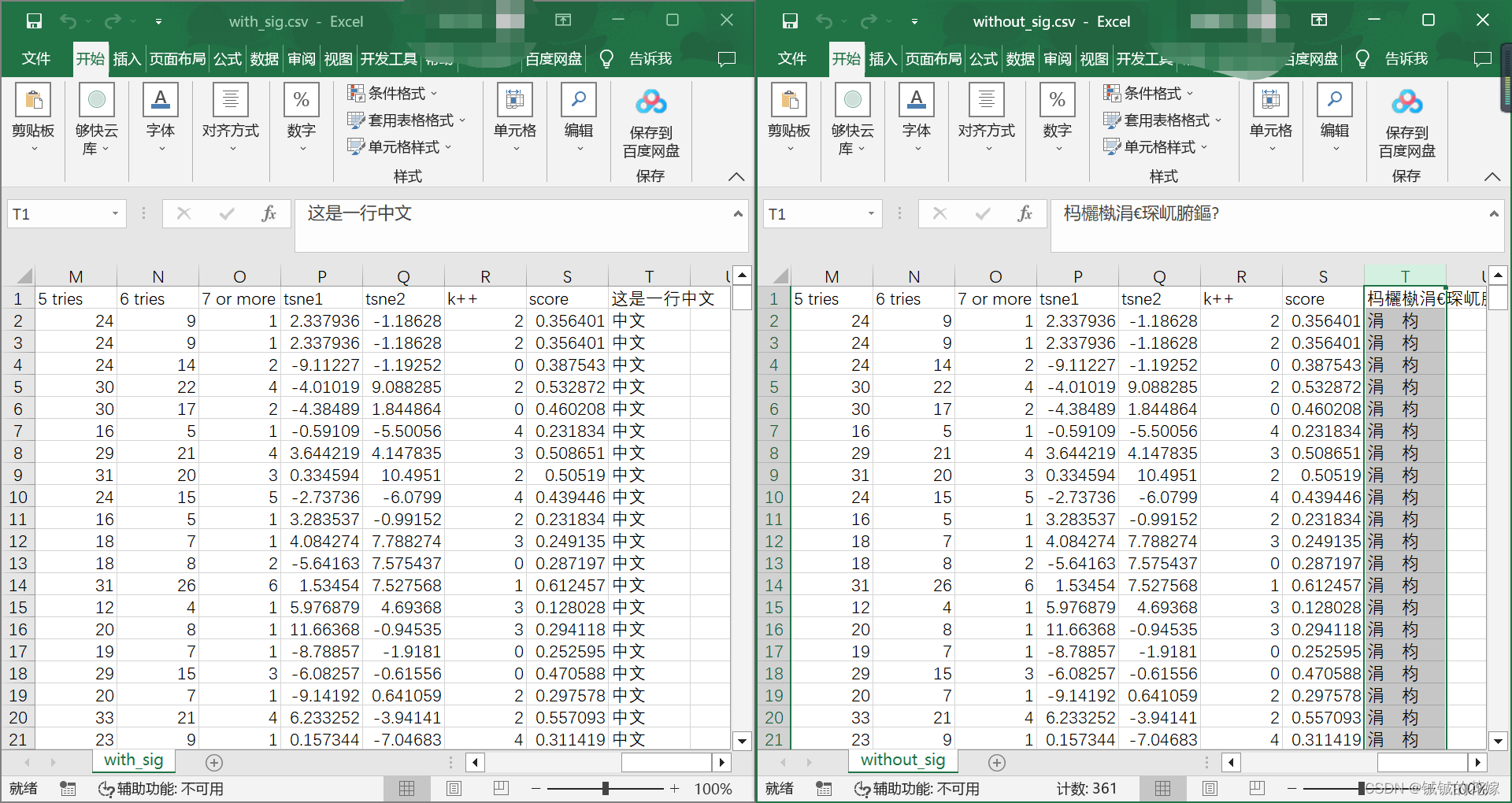
有的时候数据处理做着做着就多出来一列未命名列,大概率是保存和读取操作失误,没有搞 index 列,一读一存就多了一列。
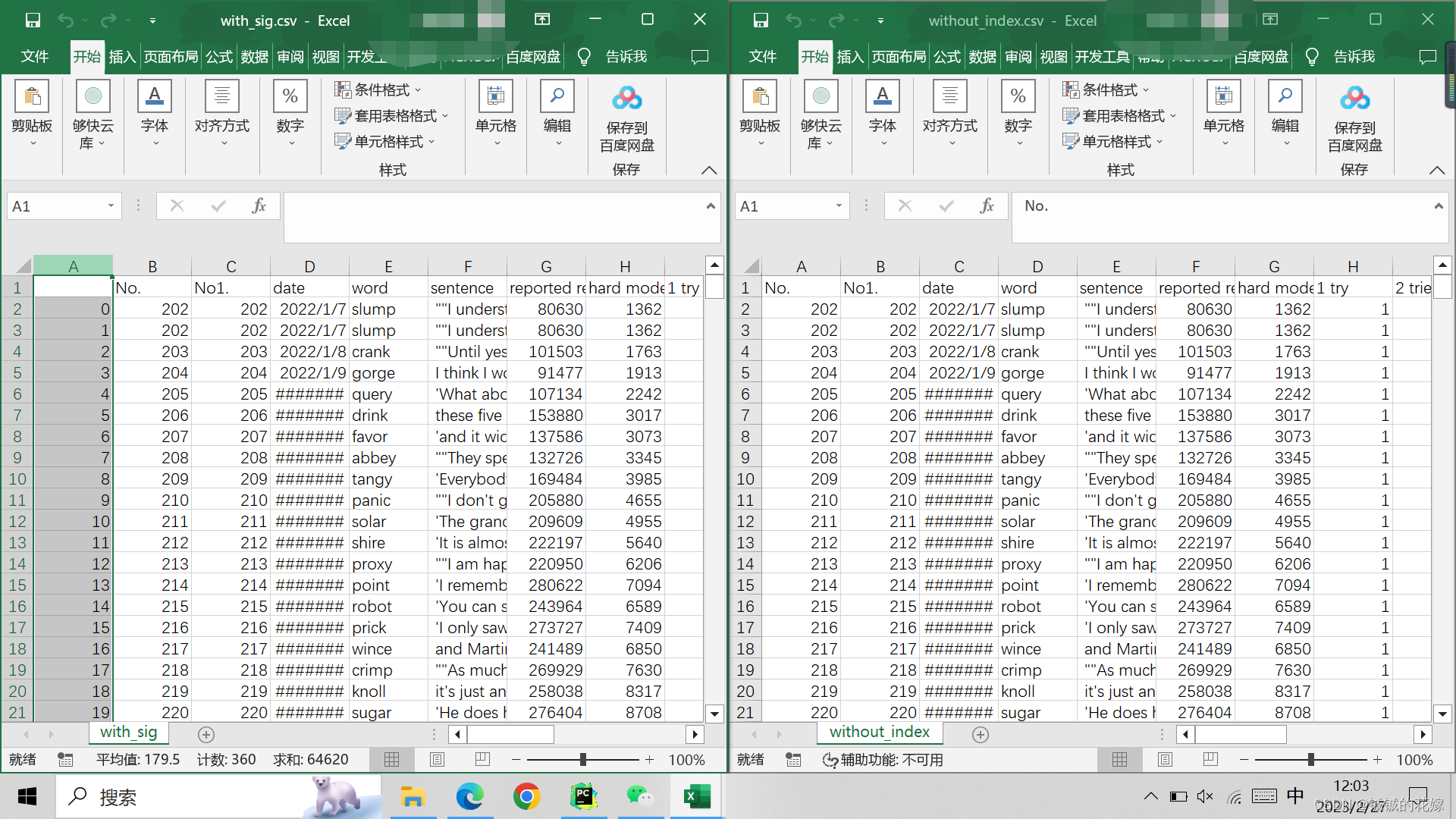
代码如下:
# 保存数据
def save_data(data):
data.loc[:, "这是一行中文"] = ["中文"] * data.shape[0]
data.to_csv("without_sig.csv", encoding="utf-8")
data.to_csv("with_sig.csv", encoding="utf-8-sig")
data.to_csv("tsv.tsv", encoding="utf-8-sig", sep="\t")
data.to_csv("without_index.csv", encoding="utf-8-sig", index=0)
全部显示(行/列)
有的时候我真的是想看全部结果,不想看被隐藏的。
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#设置value的显示长度为100,默认为50
pd.set_option('max_colwidth', 100)
任务1:去标点(引号)
因为数据集比较脏,里面的句子鱼龙混杂的,sentence 列里面混入了一大堆没用的引号,去掉!
这里有一个注意点,就是对空数据的处理。一般情况下我们的数据集中室友空数据存在的,而我们在做数据预处理的时候会删掉这些数据,在这里我们没有删,就会在做正则的时候报错。
# 去标点
def de_punctuation(data):
# 正则表达式去除两种引号,直接写会报错,因为空数据集存在,这里补一个try:
def app_fun(series):
try:
series = re.sub(r'[\'\"]', '', series)
except TypeError:
return np.nan
return series
data["sentence"] = data["sentence"].apply(lambda x: app_fun(x))
print(data["sentence"])
return data
去除之后 sentence 列还算干净,可能还有些空格问题,这边就无所谓了。
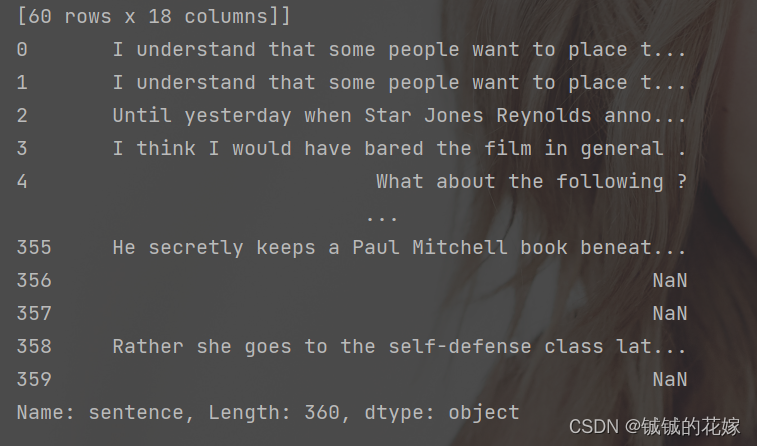
任务2:获取词数
对于英文来说,很多情况下直接统计空格数就好了,但是我们未来处理的不一定都是英文,还有中文之类的,保险起见这边就随便拿个分词包先分词后统计,我用的是 jieba,当然用 斯坦福 和 nltk 什么的也是差不多的。
# 算词数
def cul_wordcount(data):
def counting(series):
import jieba
try:
seg_list = jieba.cut(series)
# 返回的是一个迭代器直接循环遍历算了,反正之后还是要用的
# 顺便去个空
ret = [x for x in seg_list if x != " "]
except:
return []
return ret
ret = data["sentence"].apply(lambda x: counting(x))
return ret.apply(lambda x: len(x)), ret
结果如下图所示,其中 taken_word是切词之后的结果,因为后面有用到,这里先放着。
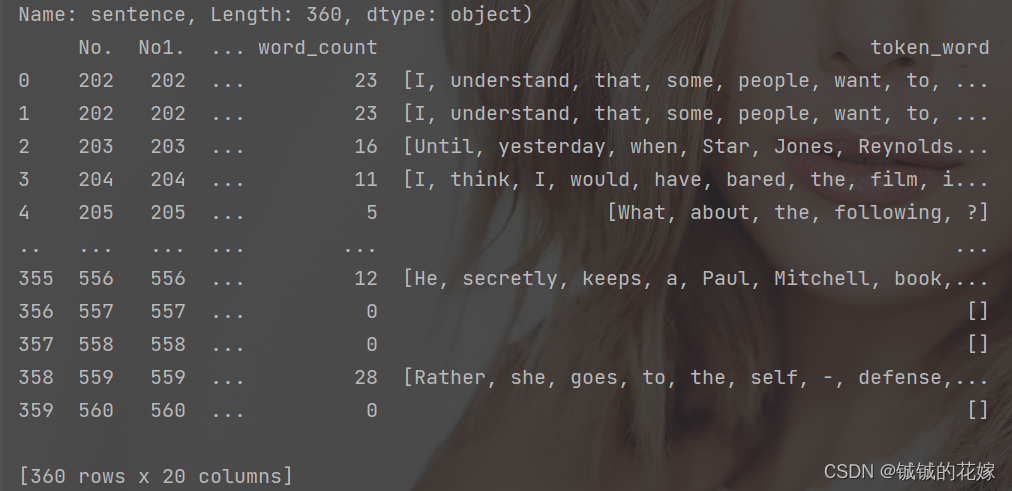
任务3:建立词典
这个就正常练手吧,大家其实写法都差不多,之前自己的写法反而还慢了。
# 建词典
def build_dic(data):
dict = {}
def counting(series):
for key in series:
dict[key] = dict.get(key, 0) + 1
data["token_word"].apply(counting)
return sorted(dict.items(), key=lambda x: x[1], reverse=True)
排序后结果是这样的,调用的时候记得元组转换一下

任务4:正则表达式把日期转化为标准日期和年月日列
复习下高阶函数和正则表达式,再拓展下正则表达式在 pandas 里的应用。
# 转日期
def date_T(data):
def fun(x):
ret = re.findall(r'(\d{4})/(\d{1,2})/(\d{1,2})', x)[0]
return "{}/{:0>2d}/{:0>2d}".format(ret[0], int(ret[1]), int(ret[2]))
# 标准日期
ret = data["date"].apply(fun)
print(ret)
# 这里实在没想到什么好看快速的写法,土方法吧
splitt = ret.str.split("/", expand=True)
print(splitt)
data["date"], data[["year", "month", "day"]] = ret, splitt
return data
修改了 date 列, 增加了 year month day 列。
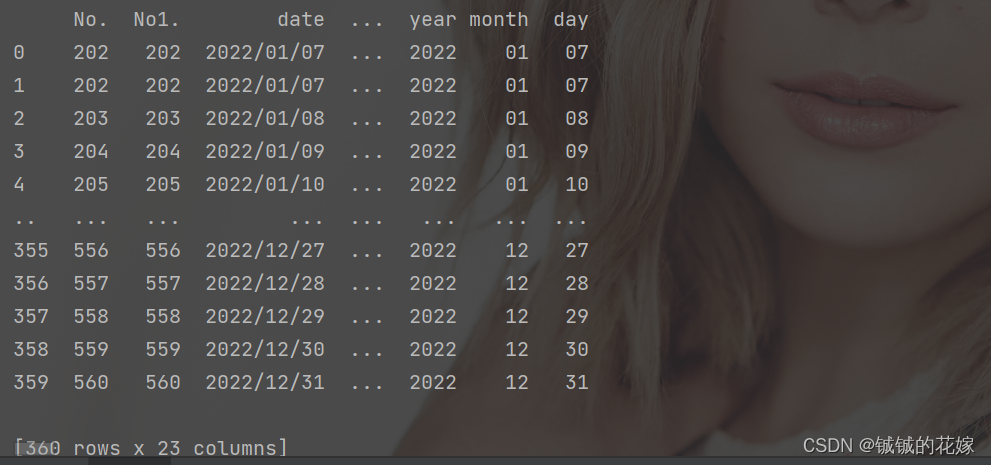
任务代码
这四个任务是连起来的。
# 去标点
def de_punctuation(data):
# 正则表达式去除两种引号,直接写会报错,因为空数据集存在,这里补一个try:
def app_fun(series):
try:
series = re.sub(r'[\'\"]', '', series)
except TypeError:
return np.nan
return series
data["sentence"] = data["sentence"].apply(lambda x: app_fun(x))
print(data["sentence"])
return data
# 算词数
def cul_wordcount(data):
def counting(series):
import jieba
try:
seg_list = jieba.cut(series)
# 返回的是一个迭代器直接循环遍历算了,反正之后还是要用的
# 顺便去个空
ret = [x for x in seg_list if x != " "]
except:
return []
return ret
ret = data["sentence"].apply(lambda x: counting(x))
return ret.apply(lambda x: len(x)), ret
# 建词典
def build_dic(data):
dict = {}
def counting(series):
for key in series:
dict[key] = dict.get(key, 0) + 1
data["token_word"].apply(counting)
return sorted(dict.items(), key=lambda x: x[1], reverse=True)
# 转日期
def date_T(data):
def fun(x):
ret = re.findall(r'(\d{4})/(\d{1,2})/(\d{1,2})', x)[0]
return "{}/{:0>2d}/{:0>2d}".format(ret[0], int(ret[1]), int(ret[2]))
# 标准日期
ret = data["date"].apply(fun)
print(ret)
# 这里实在没想到什么好看快速的写法,土方法吧
splitt = ret.str.split("/", expand=True)
print(splitt)
data["date"], data[["year", "month", "day"]] = ret, splitt
return data
if __name__ == '__main__':
data = get_data("wordle.csv", "utf-8-sig")
data = de_punctuation(data)
print(cul_wordcount(data))
data["word_count"], data["token_word"] = cul_wordcount(data)
print(data)
print(build_dic(data))
data = date_T(data)
print(data)
1.2. 增删改查空
空
这个任务特别常见,几乎所有未处理过的数据的使用都需要经过这步。需要处理缺失值,首先我们得看有没有缺失值,再定位缺失值,分析缺失值的分布等特性,最后处理缺失值(删除、替换)。个人感觉比较常见的操作就是下面的这些任务:
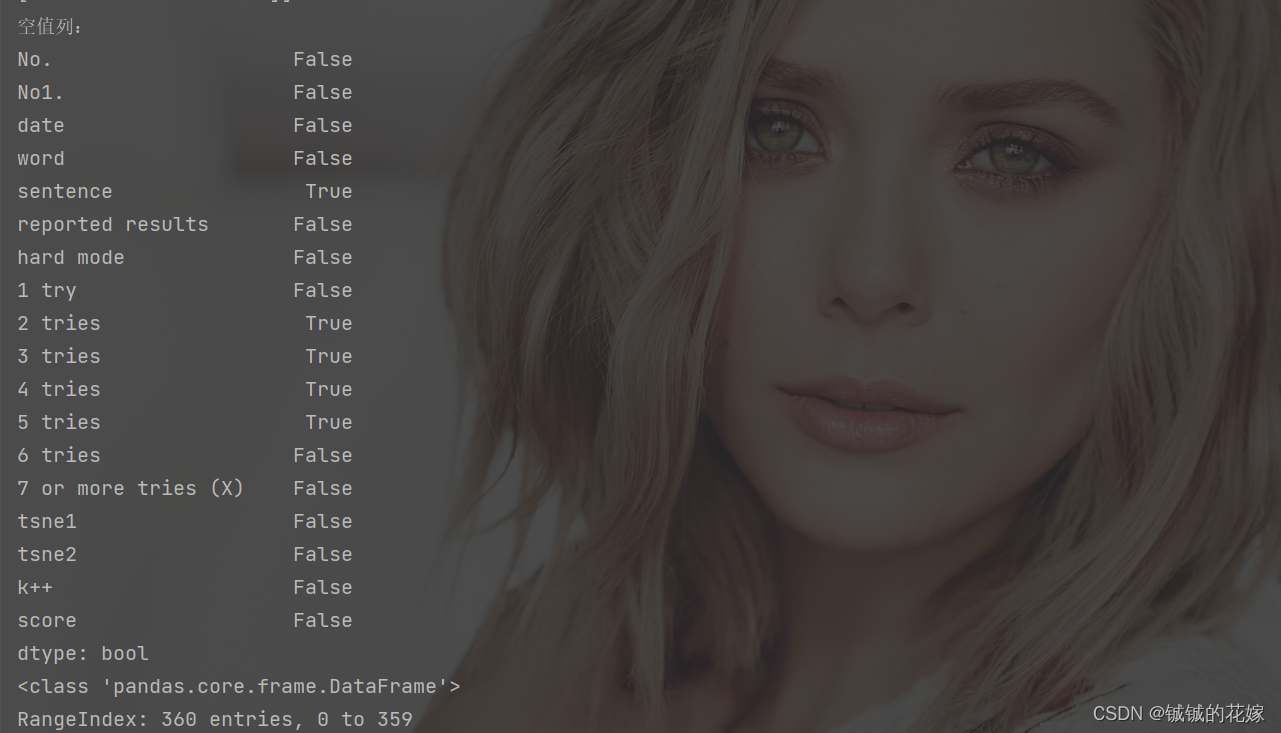
任务1:定位某列空
isnull和转置的熟练应用:
# 输出含有空值的列
print("空值列:")
print(data.isnull().any())
print(data.info())
效果图:
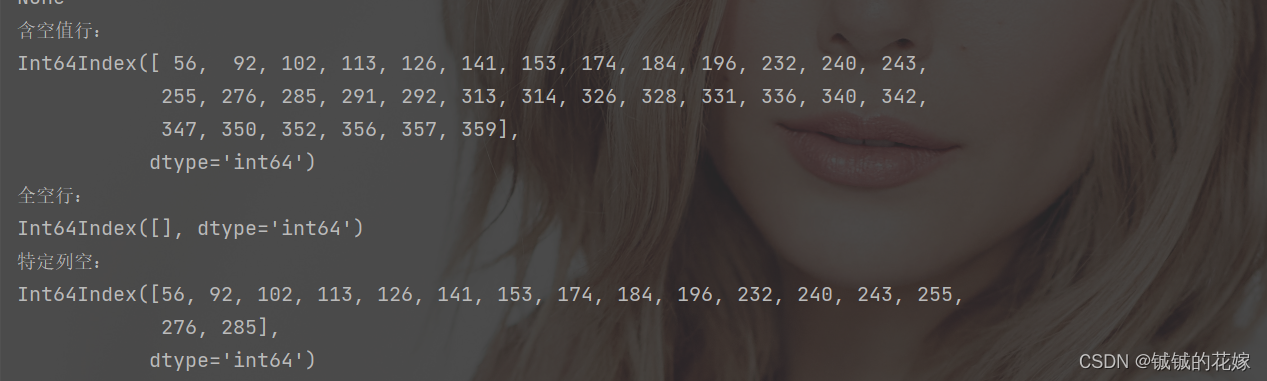
任务2:定位含有空的行
属于基本用法的熟练运用:
# 输出含有空值的行
print("含空值行:")
null_row = data.T.isnull().any()
print(null_row[null_row == True].index)
# 输出全空的行、特定列空的行
null_row_1 = data.T.isnull().all()
null_row_2 = data[["2 tries", "3 tries", "4 tries", "5 tries"]].T.isnull().any()
# 输出全空的行、特定列空的行
null_row_1 = data.T.isnull().all()
null_row_2 = data[["2 tries", "3 tries", "4 tries", "5 tries"]].T.isnull().any()
print("全空行:")
print(null_row_1[null_row_1 == True].index)
print("特定列空:")
print(null_row_2[null_row_2 == True].index)
运行结果:
任务3:统计有空行
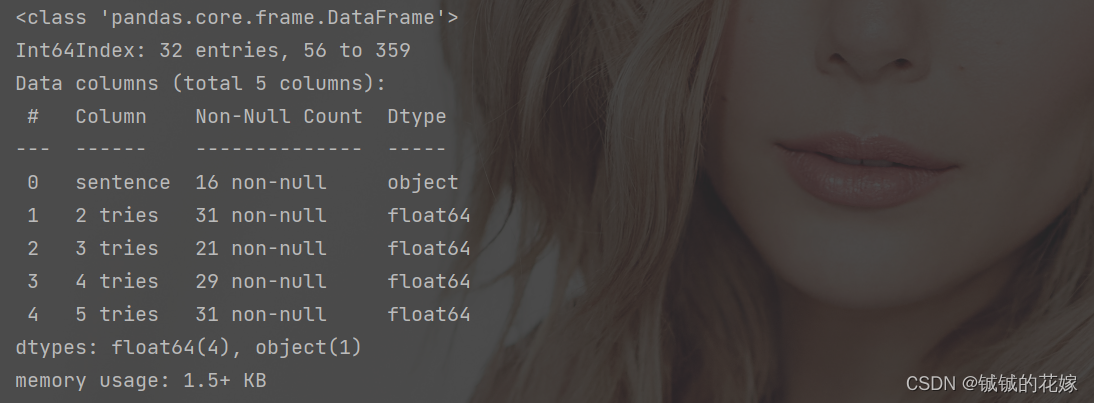
这个简单,定位完之后直接info(),关键是定位
# 看看空行
print("空行查看:")
null_row = data.loc[null_row == True, data.columns[data.isnull().any()]]
print(null_row)
print(null_row.info())
效果如下:
任务4:删除有空行
用到 dropna(),那就浅浅总结下参数:
| 参数 | how 什么情况删删 | axis 删哪个维度 | thresh 保留 | subset 删维度中的谁 |
|---|---|---|---|---|
| 默认值 | any:有空就删 | 0:删除行 | None:不管 | None:考虑所有行/列 |
| 其他取值 | all:全空才删 | int(n):删除 n 对应的维度 | int(n):表示保留至少含有 n 个非空数值的 | [col_1, …, col_n]:考虑 col_1, …, col_n 这些列 |
代码如下:
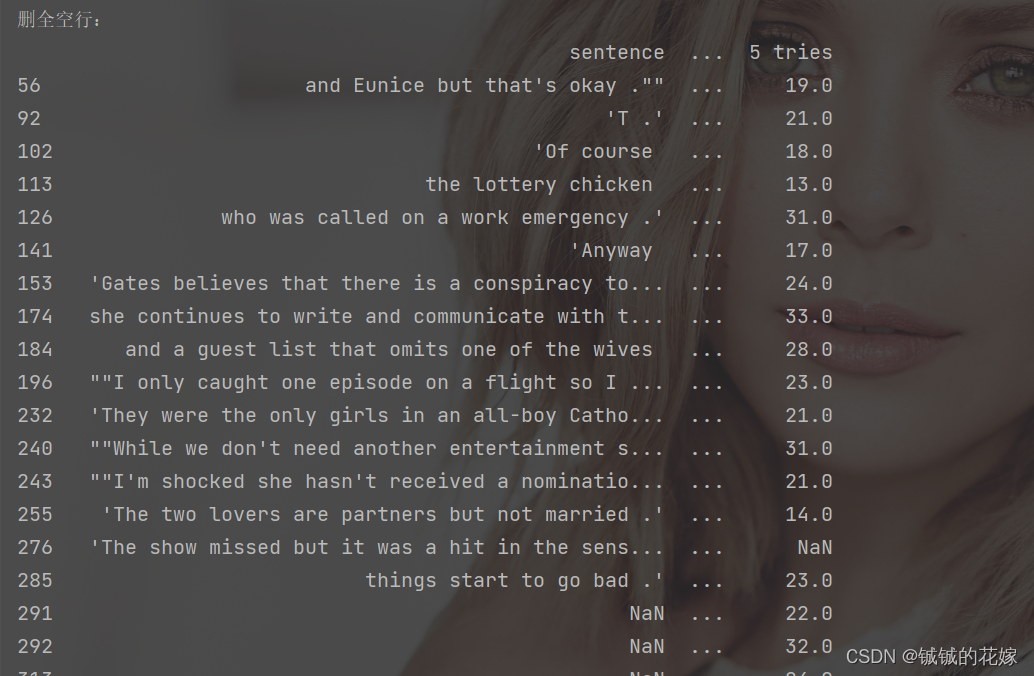
# 删除空行
print("删全空行:")
print(null_row.dropna(how="all"))
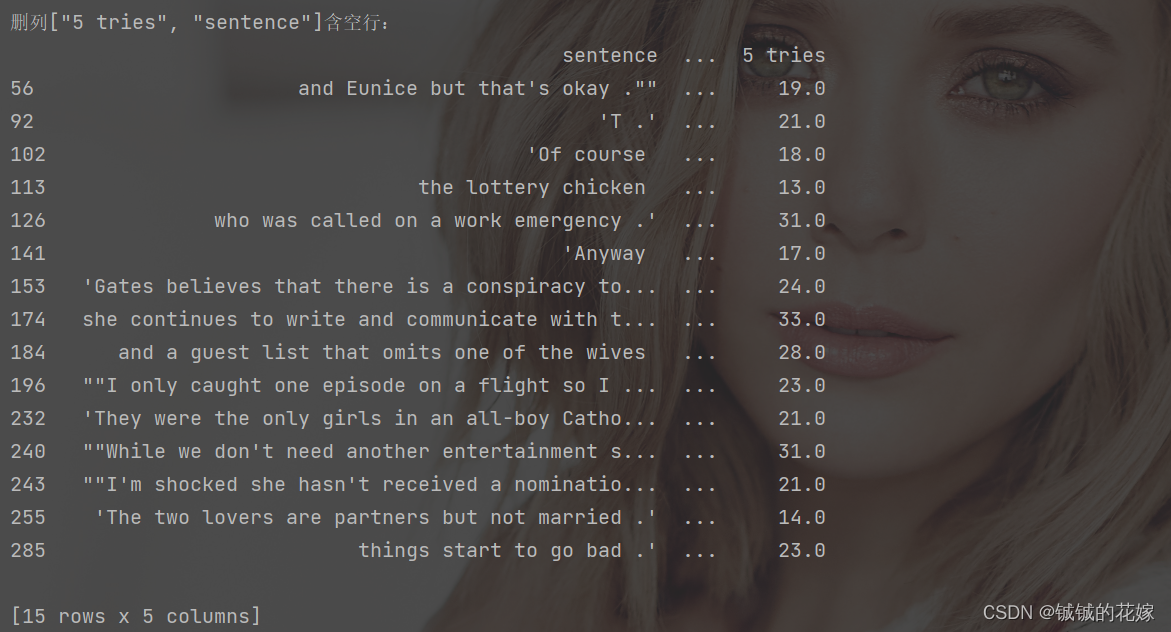
print("删列[\"5 tries\", \"sentence\"]含空行:")
print(null_row.dropna(subset=["5 tries", "sentence"]))
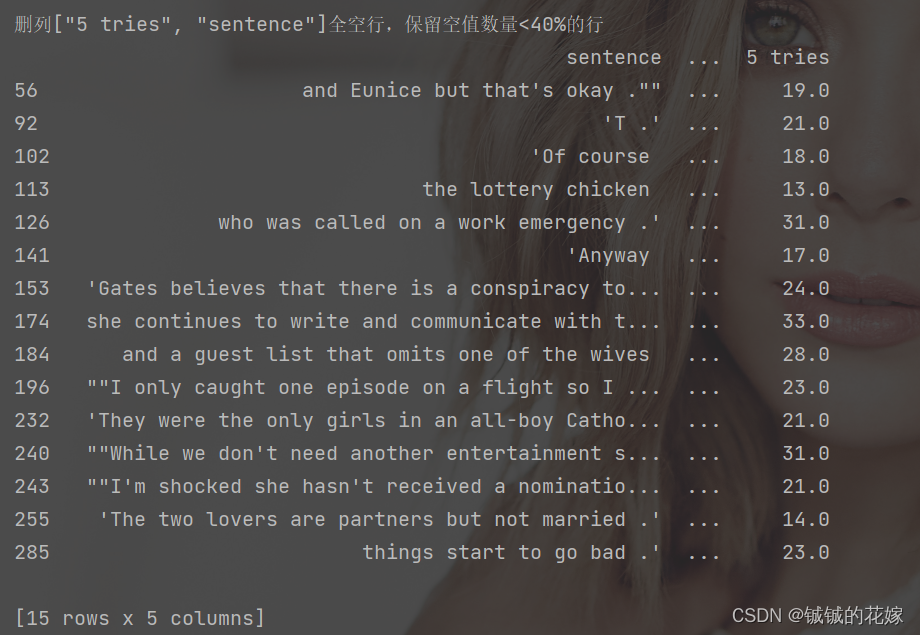
print("删列[\"5 tries\", \"sentence\"]全空行,保留空值数量<40%的行")
print(null_row.dropna(how="all", thresh=int(0.4*len(null_row.columns)), subset=["5 tries", "sentence"]))
看下效果:
任务5:替换空值
fillna要会用:
# 空值替换:
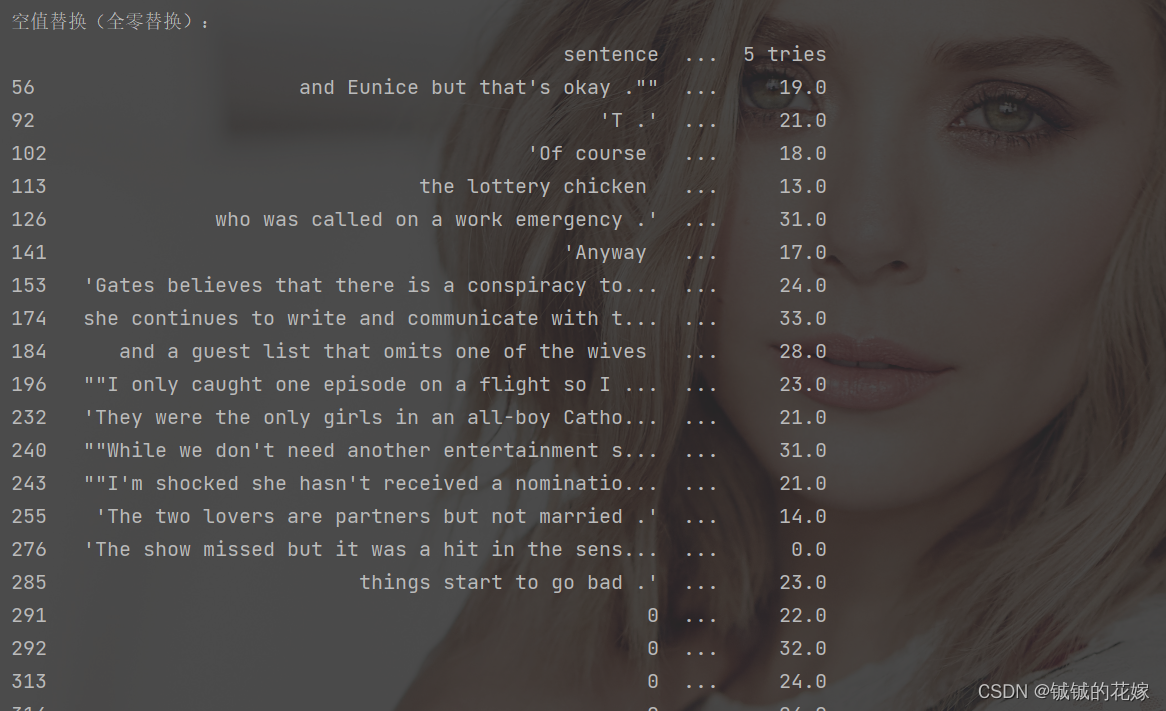
print("空值替换(全零替换):")
print(null_row.fillna(0))
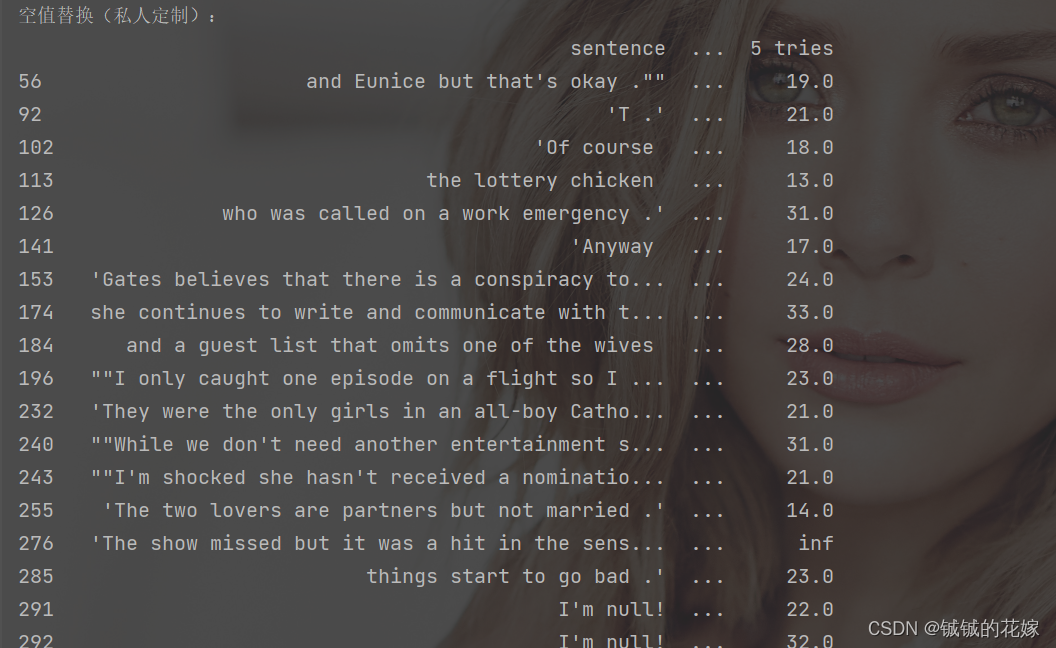
print("空值替换(私人定制):")
print(null_row.fillna({'sentence': 'I\'m null!', '2 tries': 0, '3 tries': 100, '5 tries': np.inf}))
效果如下:
全部代码
这部分 print 太多了,感觉看着乱,贴整个函数:
# 空
def deal_with_null(data):
# 输出含有空值的列
print("空值列:")
print(data.isnull().any())
print(data.info())
# 输出含有空值的行
print("含空值行:")
null_row = data.T.isnull().any()
print(null_row[null_row == True].index)
# 输出全空的行、特定列空的行
null_row_1 = data.T.isnull().all()
null_row_2 = data[["2 tries", "3 tries", "4 tries", "5 tries"]].T.isnull().any()
print("全空行:")
print(null_row_1[null_row_1 == True].index)
print("特定列空:")
print(null_row_2[null_row_2 == True].index)
# 看看空行
print("空行查看:")
null_row = data.loc[null_row == True, data.columns[data.isnull().any()]]
print(null_row)
print(null_row.info())
# 删除空行
print("删全空行:")
print(null_row.dropna(how="all"))
print("删列[\"5 tries\", \"sentence\"]含空行:")
print(null_row.dropna(subset=["5 tries", "sentence"]))
print("删列[\"5 tries\", \"sentence\"]全空行,保留空值数量<40%的行")
print(null_row.dropna(how="all", thresh=int(0.4*len(null_row.columns)), subset=["5 tries", "sentence"]))
增加行/列
这个是需要注意性能的,个人不建议循环等方法遍历添加,但是有的时候不得不这么做。
此外,如果知道最后要构造的 dataframe 的 shape,建议先创一个这么大的 dataframe,再往里面填数据,pandas 做这样的“填空题”相对快一点。
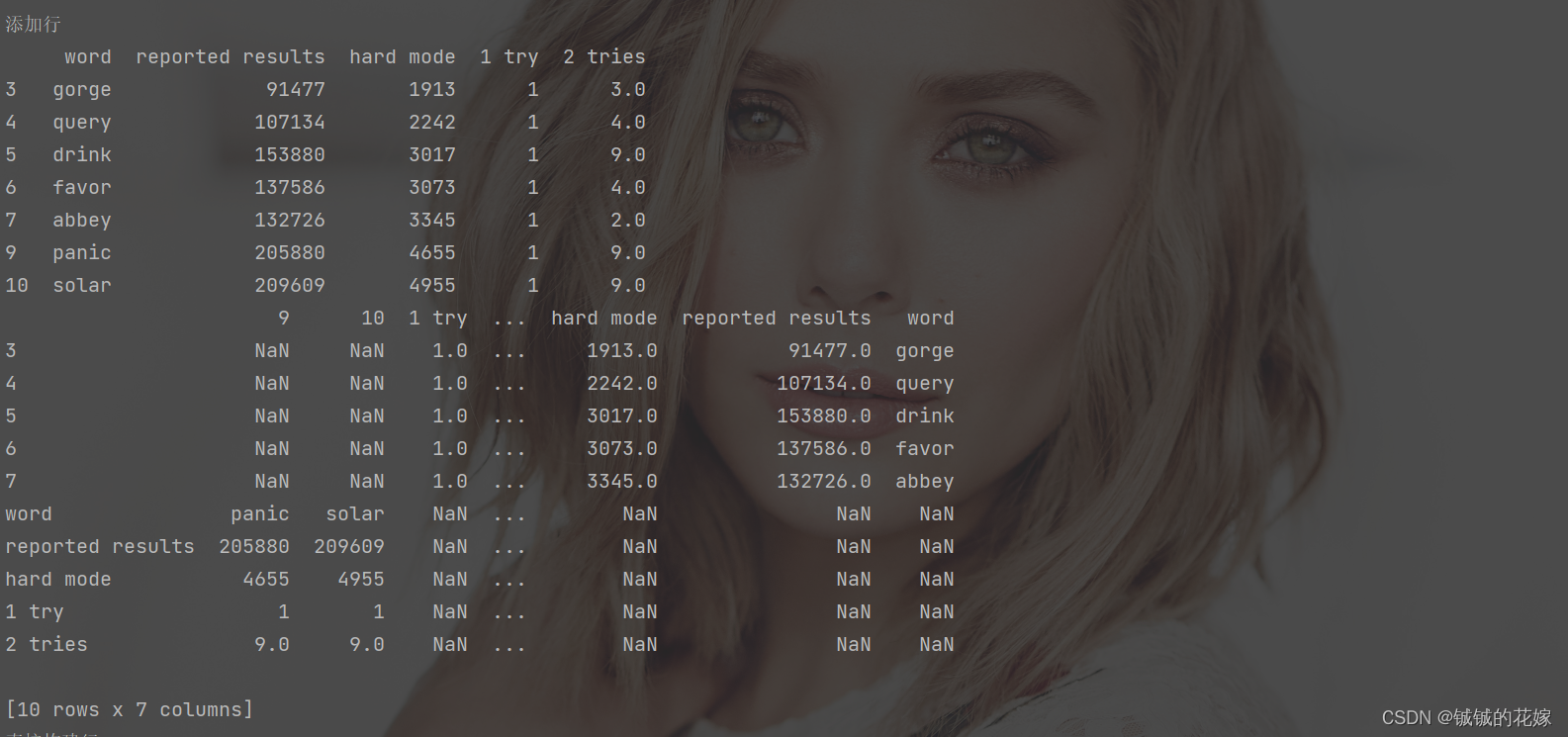
-
append方法真的不建议,一行两行搞还行,很多行一个一个就真的很慢,多行的话直接合并算了。不过我也承认真的很方便,毕竟简单好理解。 -
concat也方便,个人认为这个更适合多行。 -
字典,如果你想一行一行生成一个 dataframe,不建议在 dataframe 上一层一层加,直接生成一个字典的列表,再转化为 dataframe 比较好。毕竟 pandas 擅长的是各种数据的转换。
-
加列,开个新列名直接写就好。
-
加列,也可以用
insert,蛮灵活的,还可以去重,不过我用的很少(不示范了),平时都是直接开个新列名加列的。
示范代码:
# 取一部分,方便输出
data_1 = data.iloc[3:8, np.r_[3, 5:9]].copy()
data_add = data.iloc[9:11, np.r_[3, 5:9]].copy()
# append
print("添加行")
print(data_1.append(data_add))
# concat做(多列数据)
print(pd.concat([data_1, pd.DataFrame(data_add).T], axis=0))
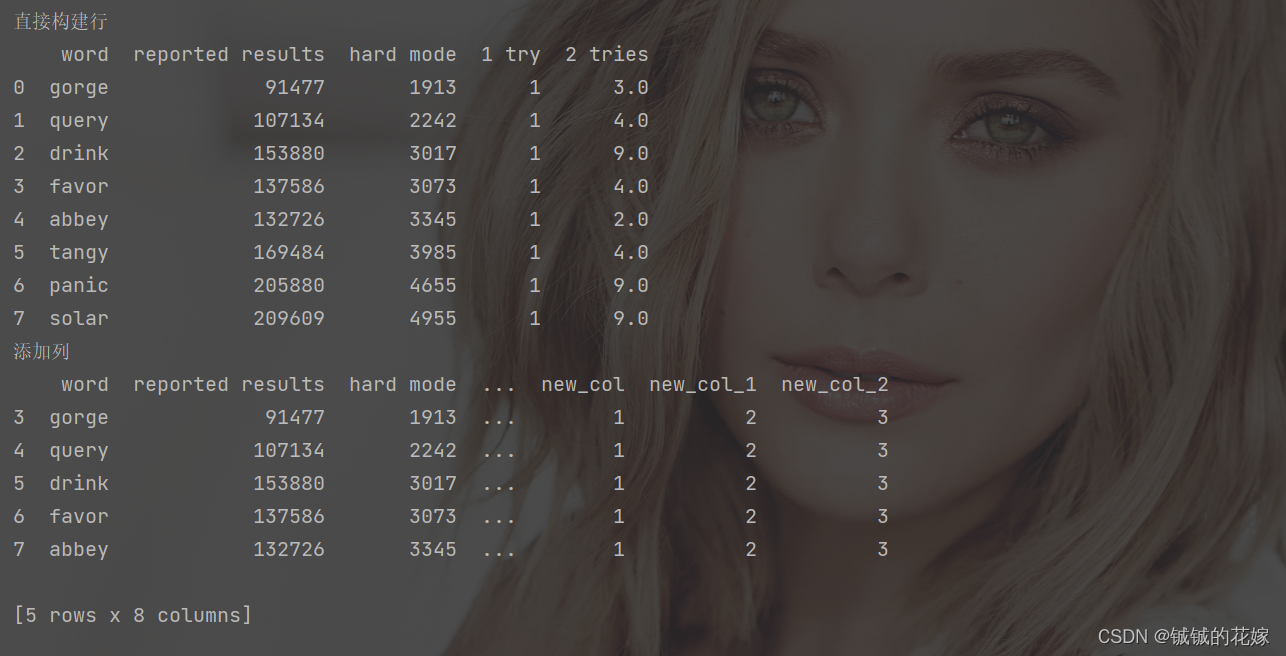
print("直接构建行")
# 字典(提前知道数据了)
data_add = []
for i in range(3, 11): # 循环跑完我们就准备好了要加入的数据
dict = {}
for col in data_1.columns:
dict[col] = data.at[i, col]
data_add.append(dict)
print(pd.DataFrame(data_add))
print("添加列")
# 列操作
data_1["new_col"] = [1 for i in range(data_1.shape[0])]
data_1[["new_col_1", "new_col_2"]] = [[2, 3] for i in range(data_1.shape[0])]
print(data_1)
结果:
合并行/列
网上的方法真的花里胡哨多的不行,我认为大多方法做了解就好了,先精通一种,做到能解决问题。
concat:沿一个轴将多个dataframe对象连接在一起, 形成一个新的dataframe对象merge:数据融合,将两个 dataframe 拼接并对内部的数据处理hstack/vstack:是numpy的操作,以前特别喜欢用的,后来逐渐不用了。主要是只能处理 2 维的数据,有点局限。
一些个区别:
- 个人理解和 merge 相比,concat 仅仅是简单的拼接,而 merge 是 dataframe 的融合,比 concat 多了些功能(去重、取空之类的)。
- hstack/vstack 倒是跟 concat很像,都是轴向拼接,直接拼就完事了。
- merge 因为是融合,所以在完成任务时需要选定一个或者多个键作为标准,有一说一,多少有点数据库里的表合并,若不是有 concat 对比,这妥妥应该放到下一大章讲。
- concat 可以一堆dataframe 一起拼接,merge一般只针对两个(left,right)对应左右连接。
- merge 只能进行列拼接,不能处理行的问题,如果需要行拼接,要么用 concat,要么用 join(不解释)。
简单放下 concat 的主要参数:
| 参数 | join 怎么拼 | axis 在哪个维度拼 | ignore_index 重不重排index | sort 排序嘛 |
|---|---|---|---|---|
| 默认值 | outer:拼出表的并集,没有的补空 | 0:行拼接 | False:就这个index | False:不排序 |
| 其他取值 | inner:按照表格交集拼 | int(n):在第 n 维拼接 | True:重新生成一个升序index | True:排序 |
再放下 merge 的主要参数:
| 参数 | how 怎么拼 | on 根据谁拼 |
|---|---|---|
| 默认值 | inner(内连接):拼出表的交集 | None:直接拼 |
| 其他取值 | outer(外连接):按照表格并集拼 left(左连接):以左边的数据为准连接,左边没有的补nan right(右连接):以右边的数据为准连接,右边没有的补nan | index_name:根据 index_name 拼 |
数据准备
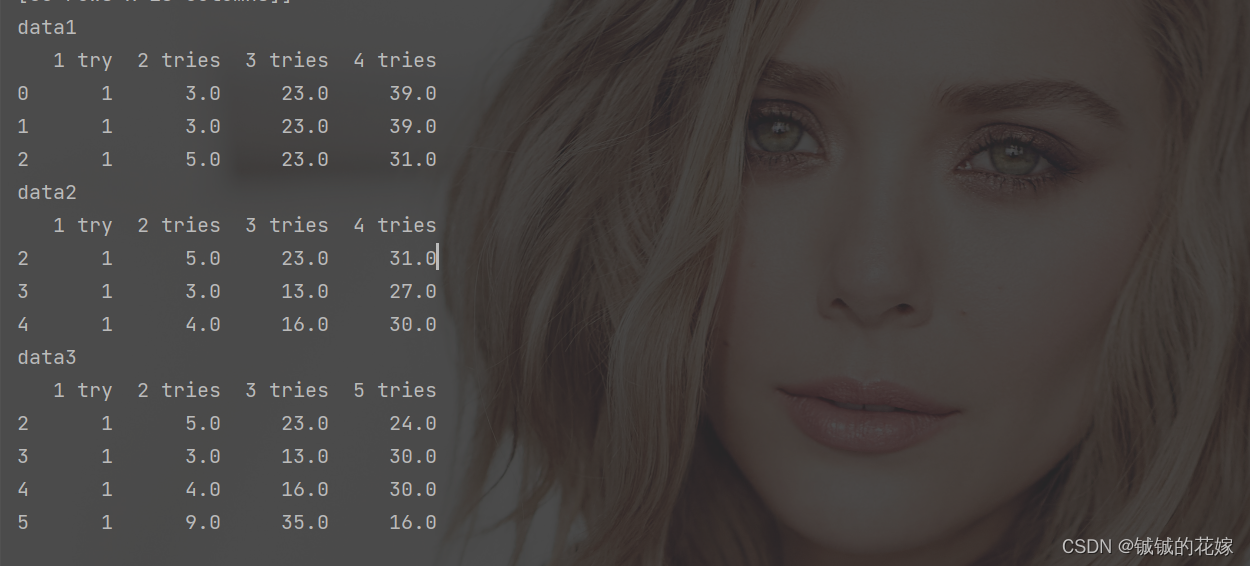
行合并
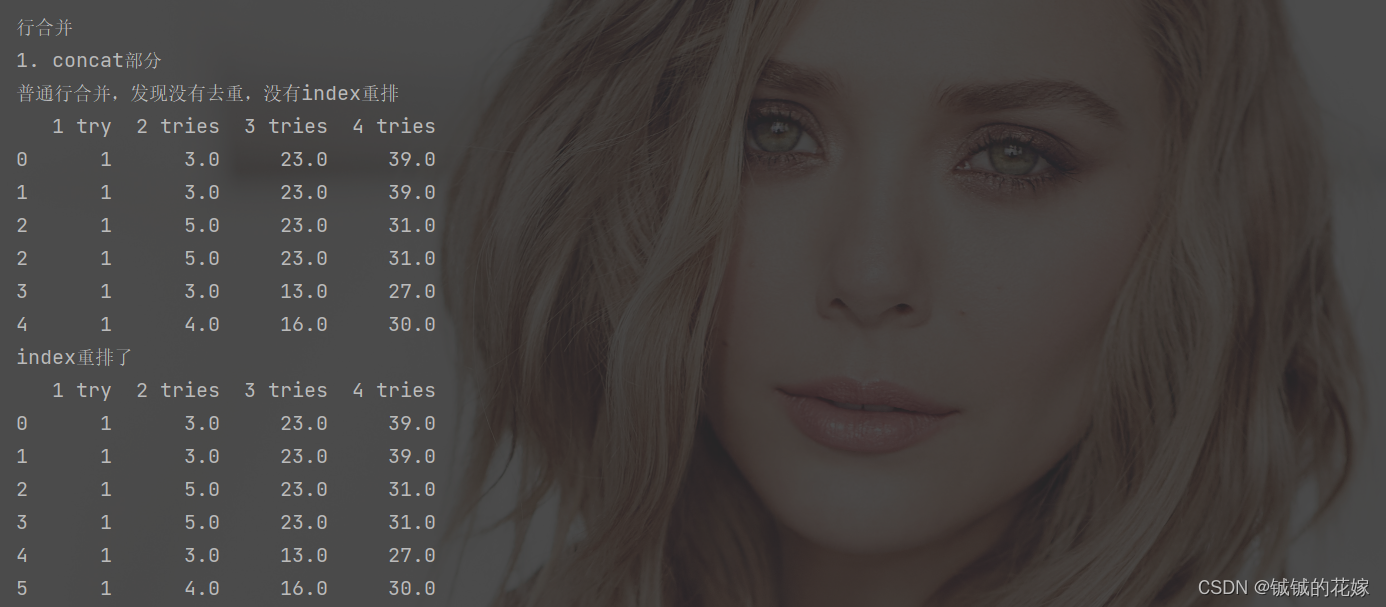
熟悉concat的两个参数
print("\n\n行合并")
print("1. concat部分")
print("普通行合并,发现没有去重,没有index重排")
print(pd.concat([data_1, data_2]))
print("index重排了")
print(pd.concat([data_1, data_2], ignore_index=True))
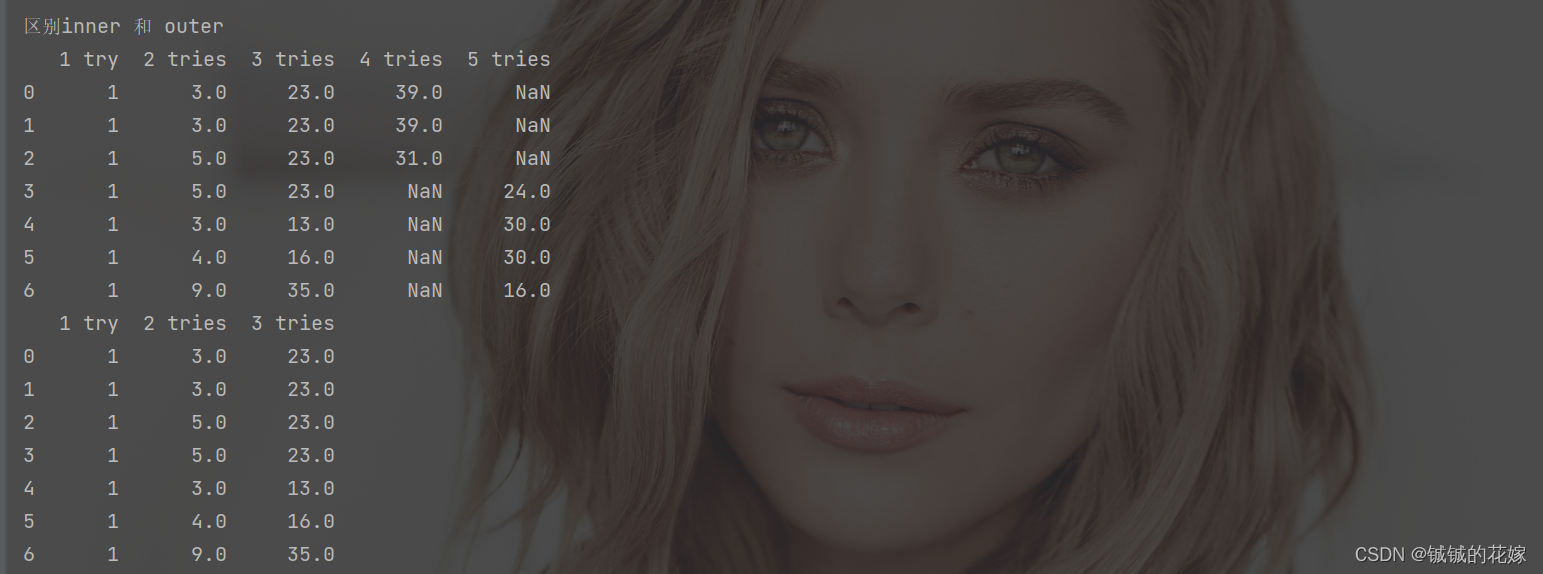
print("区别inner 和 outer")
print(pd.concat([data_1, data_3], join="outer", ignore_index=True))
print(pd.concat([data_1, data_3], join="inner", ignore_index=True))
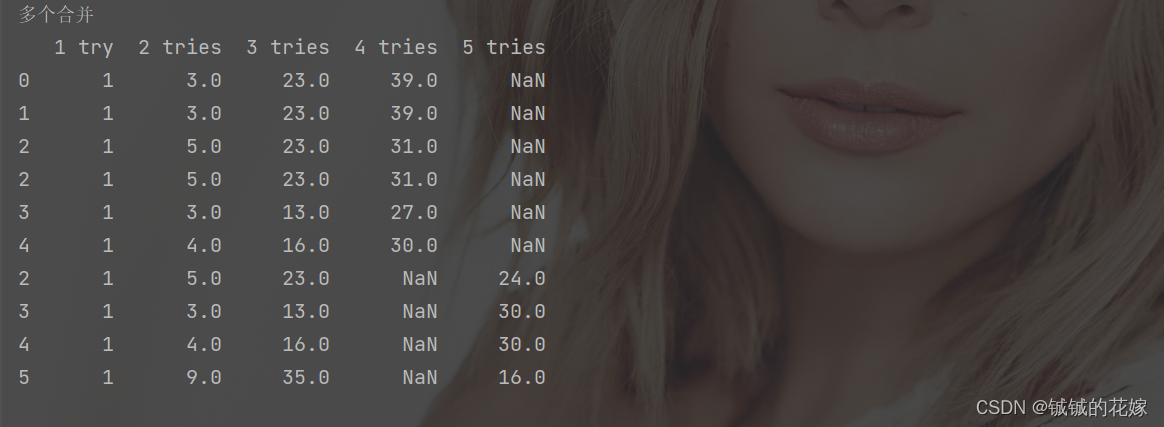
print("多个合并")
print(pd.concat([data_1, data_2, data_3], join="outer"))
一些个运行结果:
列合并
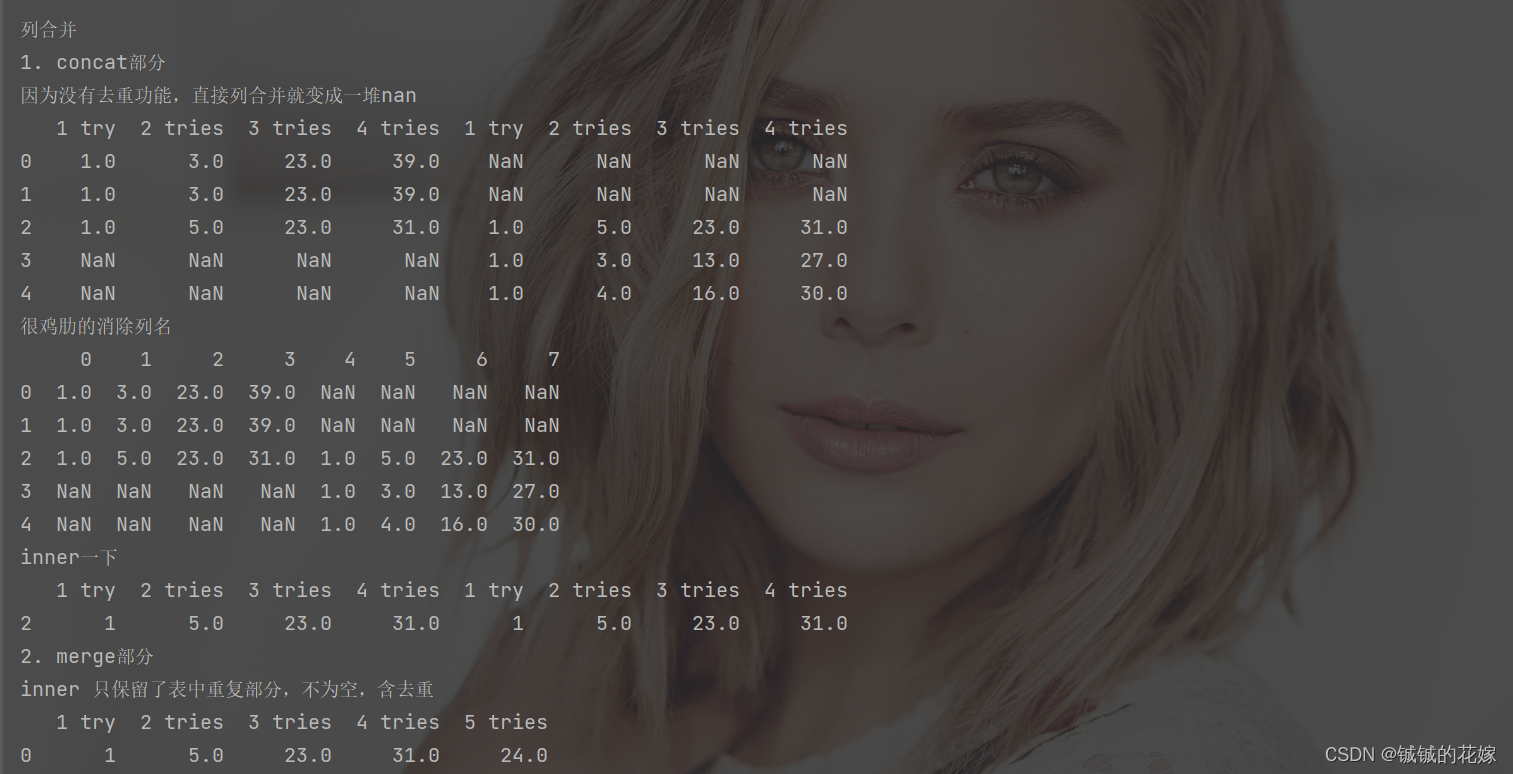
列操作没多少,基本都被行操作占完了,根据方法分为merge部分和concat部分:
print("\n\n列合并")
print("1. concat部分")
print("因为没有去重功能,直接列合并就变成一堆nan")
print(pd.concat([data_1, data_2], axis=1))
print("很鸡肋的消除列名")
print(pd.concat([data_1, data_2], axis=1, ignore_index=True))
print("inner一下")
print(pd.concat([data_1, data_2], axis=1, join="inner"))
print("2. merge部分")
print("inner 只保留了表中重复部分,不为空,含去重")
print(pd.merge(data_1, data_3))
print("outer 全部保留,补空,含去重")
print(pd.merge(data_1, data_3, how="outer"))
print("left 只留data_1有的样本")
print(pd.merge(data_1, data_3, how="left"))
print("right 只留data_3有的样本")
print(pd.merge(data_1, data_3, how="right"))
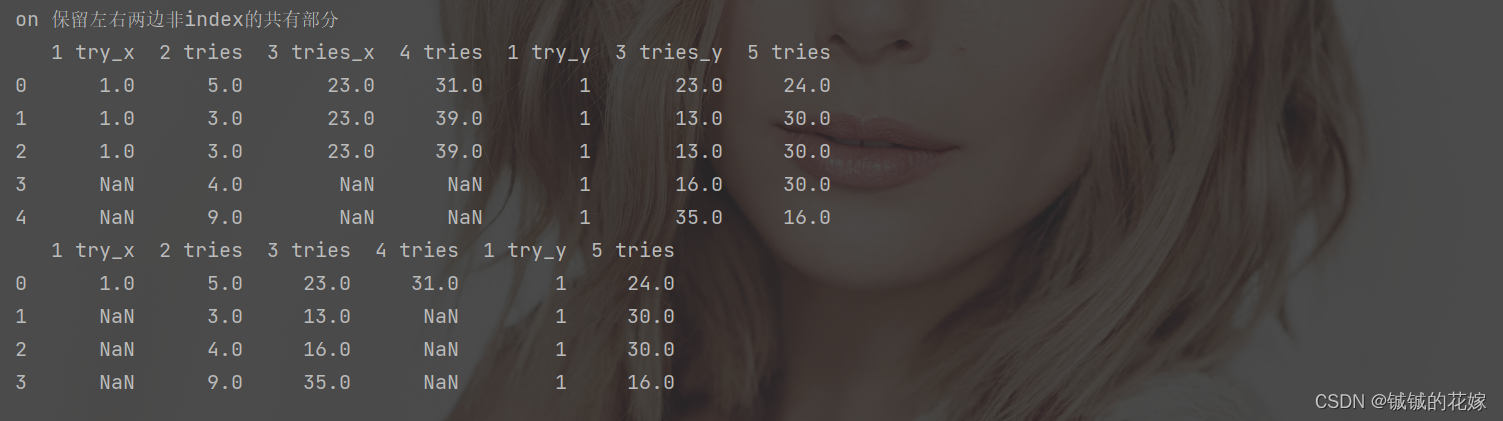
print("on 保留左右两边非index的共有部分")
print(pd.merge(data_1, data_3, how="right", on="2 tries"))
print(pd.merge(data_1, data_3, how="right", on=["2 tries", "3 tries"]))
运行结果:

全部代码
# 合并
def hebing_row_col(data):
# 数据准备
# [3, 4]
data_1 = data.loc[:2, ["1 try", "2 tries", "3 tries", "4 tries"]].copy()
# [3, 4]
data_2 = data.loc[2:4, ["1 try", "2 tries", "3 tries", "4 tries"]].copy()
# [3, 4]
data_3 = data.loc[2:5, ["1 try", "2 tries", "3 tries", "5 tries"]].copy()
print("data1\n{}\ndata2\n{}\ndata3\n{}".format(data_1, data_2, data_3))
print("\n\n行合并")
print("普通行合并,发现没有去重,没有index重排")
print(pd.concat([data_1, data_2]))
print("index重排了")
print(pd.concat([data_1, data_2], ignore_index=True))
print("区别inner 和 outer")
print(pd.concat([data_1, data_3], join="outer", ignore_index=True))
print(pd.concat([data_1, data_3], join="inner", ignore_index=True))
print("多个合并")
print(pd.concat([data_1, data_2, data_3], join="outer"))
print("\n\n列合并")
print("1. concat部分")
print("因为没有去重功能,直接列合并就变成一堆nan")
print(pd.concat([data_1, data_2], axis=1))
print("很鸡肋的消除列名")
print(pd.concat([data_1, data_2], axis=1, ignore_index=True))
print("inner一下")
print(pd.concat([data_1, data_2], axis=1, join="inner"))
print("2. merge部分")
print("inner 只保留了表中重复部分,不为空,含去重")
print(pd.merge(data_1, data_3))
print("outer 全部保留,补空,含去重")
print(pd.merge(data_1, data_3, how="outer"))
print("left 只留data_1有的样本")
print(pd.merge(data_1, data_3, how="left"))
print("right 只留data_3有的样本")
print(pd.merge(data_1, data_3, how="right"))
print("on 保留左右两边非index的共有部分")
print(pd.merge(data_1, data_3, how="right", on="2 tries"))
print(pd.merge(data_1, data_3, how="right", on=["2 tries", "3 tries"]))
删除行/列
drop函数,需要掌握的就是按照index删除行、列,批量删除行、列。其他的我感觉就没怎么用到了。
提一下drop函数也有replace参数,懒得赋值可以直接在源数据上操作。
有的时候删的太多了咱就直接取得了。
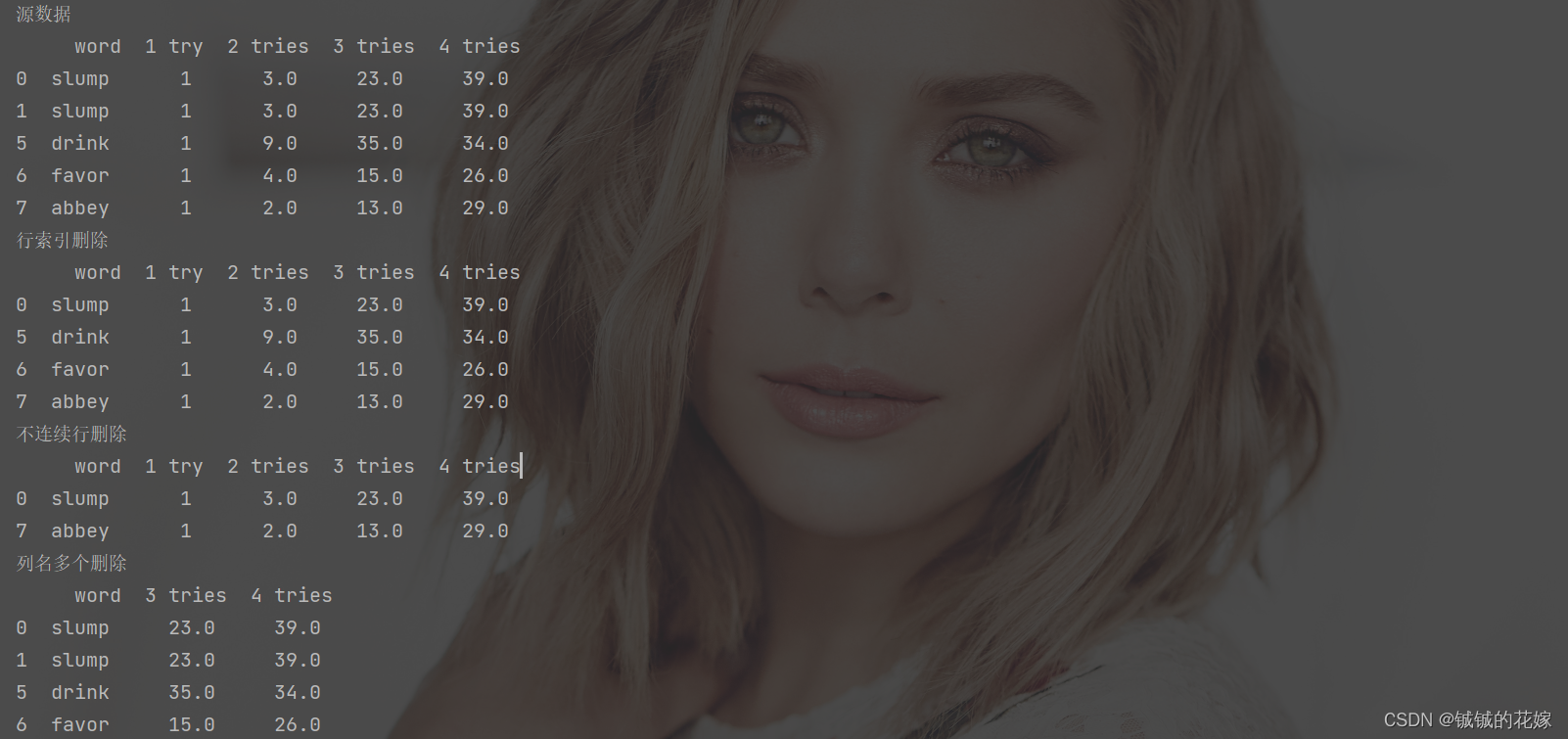
def delete_row_col(data):
data = data.loc[np.r_[:2, 5:8], ["word", "1 try", "2 tries", "3 tries", "4 tries"]].copy()
print("源数据\n", data)
print("行索引删除\n", data.drop(1))
print("不连续行删除\n", data.drop(np.r_[1, 5:7]))
print("列名多个删除\n", data.drop(["1 try", "2 tries"], axis=1))
print("列不连续行不连续删除\n", data.drop(index=np.r_[1, 5:7], columns=["1 try", "2 tries", "4 tries"]))
print("转换思路,直接取,而不是删除\n", data.loc[[0,7], ["word", "3 tries"]])
运行结果

查询修改行/列/单元格
这个之前的操作如果仔细看,肯定是很熟悉了的,查询操作就是之前的取操作,这边就看情况示范一下赋值好了(单行,单列,表格中的一部分,单元格)。
稍微需要注意的是如果复制对象 index 或者列名相匹配的东西没被填上去,直接补 nan。
# 查询并修改
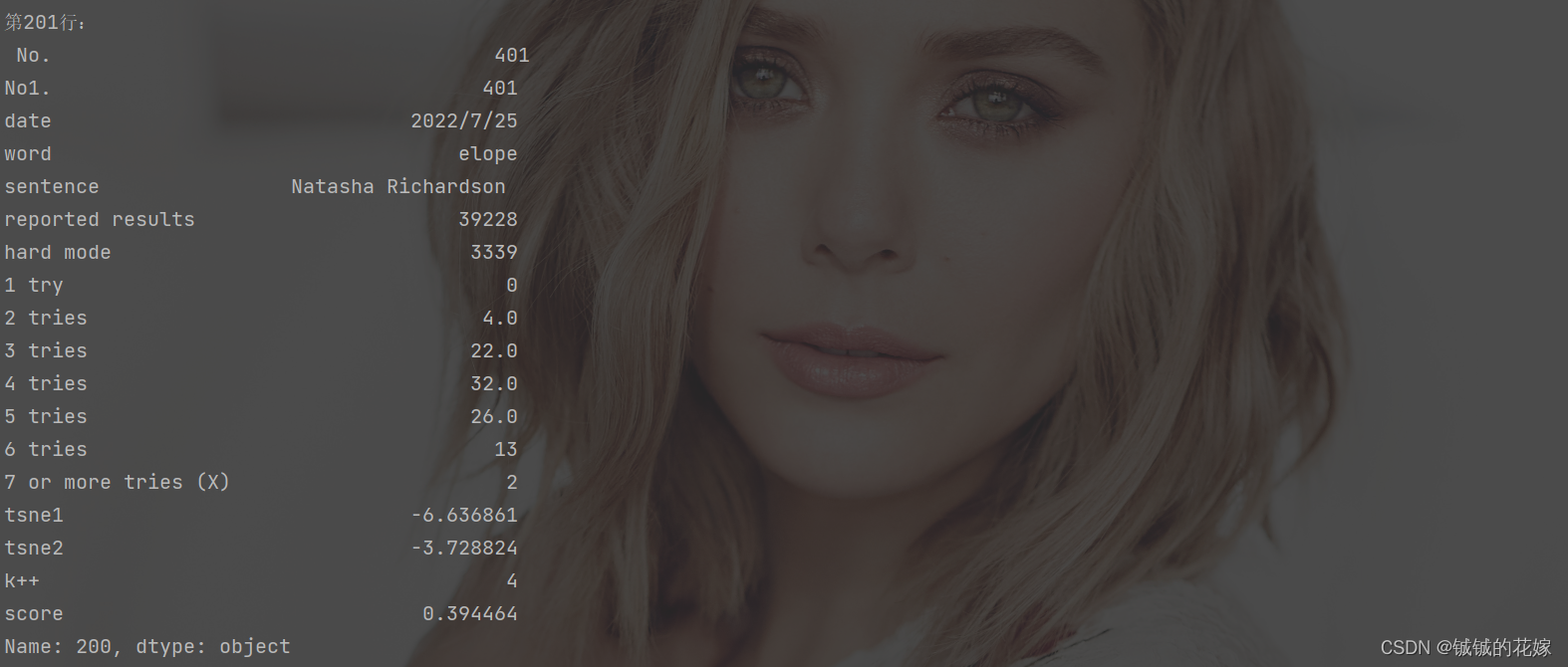
def get_modify(data):
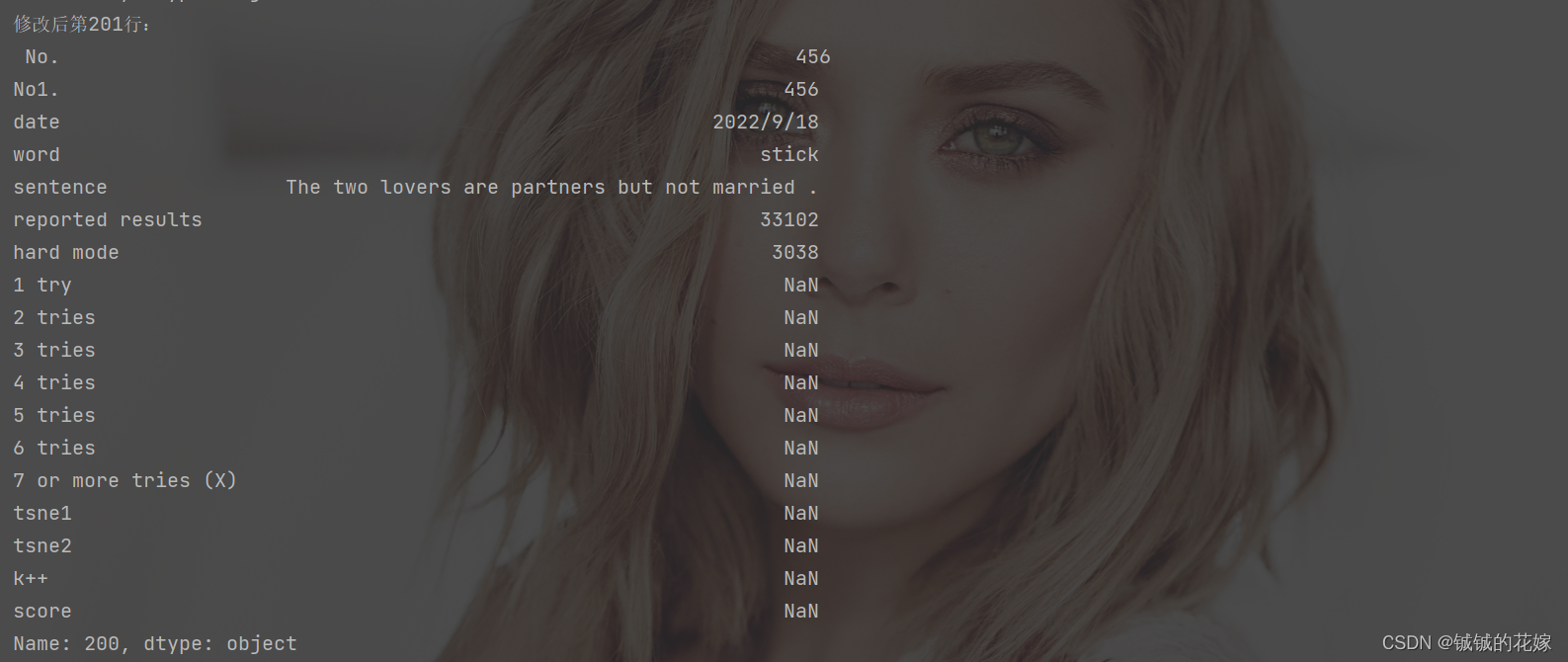
print("第201行:\n", data.loc[200])
data.loc[200] = {"No.":"456","No1.":"456","date":"2022/9/18","word":"stick", "sentence":'The two lovers are partners but not married .',"reported results":"33102","hard mode":"3038"}
print("修改后第201行:\n", data.loc[200])
print("No.列:\n", data["No."])
data.loc[:, "No."] = 1*data.shape[0]-1
print("修改后No.列:\n", data.loc[:, "No."])
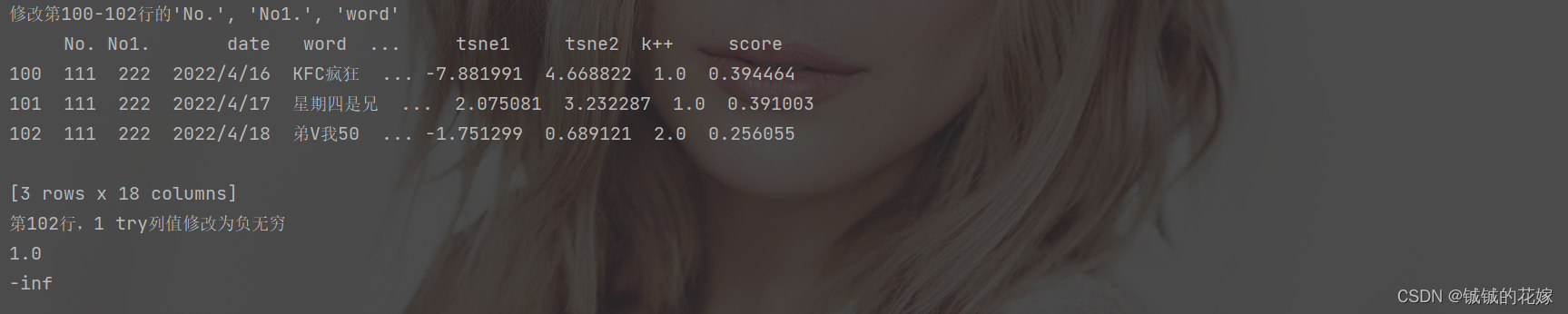
print("修改第100-102行的\'No.\', \'No1.\', \'word\'")
new = [
[111, 222, "KFC疯狂"],
[111, 222, "星期四是兄"],
[111, 222, "弟V我50"]
]
data.loc[100:102, ['No.', 'No1.', 'word']]=new
print(data.loc[100:102])
print("第102行,1 try列值修改为负无穷")
print(data.at[102, "1 try"])
data.at[102, "1 try"] = -np.inf
print(data.at[102, "1 try"])
截图

1.3. 类似数据库操作
必须知道一些高阶函数:
| 函数 | 效果 | 参数 |
|---|---|---|
| groupby | 分组:把df按照列的取值分组为多个df的元组组合(不能直接print) | |
| agg | 聚合操作,很擅长求均值,最大最小,方差中位数标准差之类的 | 指定聚合:{“col1”: “mean”, “col2”: “median”} |
| transform | 聚合计算后直接按照原索引返回结果 | |
| filter | 筛选符合条件的,可以直接使用也可以搭配 groupby 使用 | |
| resample | 时间上的分组操作 | 切分频率:季度Q、月度M、星期W、N天ND,时H(6时:6H)、分T |
这里按照任务做,实际上就是之前的一些方法的组合:
任务0:数据清洗(去含空去全重,计算sentence特征)
def task_0(data):
# 去含空行、去全重复行、去全重复列
data = data.dropna(how="any").drop_duplicates(keep=False).T.drop_duplicates(keep='first').T
# 统计词数之类的sentence操作
data = task_nlp(data)
# 去掉多出来的不要的吉列
data = data.drop(columns=["year", "month", "day", "token_word"])
task_sql(data)
return data
任务1:把数据按照列 k++ 的取值分成多个df。(超常用groupby)
def task_1(data):
data_g = data.groupby("k++")
return [i for i in data_g]
结果:

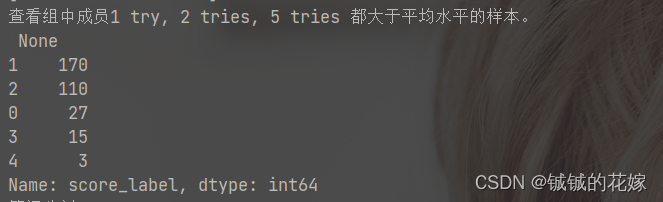
任务2:把数据按照 score 的四分位数分成 4 个label 并 查看组中成员1 try, 2 tries, 5 tries 都大于平均水平的样本。(等比分割)
def task_2(data):
# 原来想用describe算的,后来发现这不就一个sort的事情嘛
data = data.sort_values("score").reset_index()
data["score_label"] = (data.index / data.shape[0] * 4).astype(int)
# 用cut直接等分为四位,不知道为什么没有成功,但是思路上面还是上面这种更直接,这个有点为了cut而绕一下的感觉
# cut_boundary = [data.at[int(data.shape[0]/4*i), "score"] for i in range(0, 4)]
# cut_boundary.append(data.at[data.shape[0]-1, "score"])
# data["score_label"] = pd.cut(x=data["score"], bins=cut_boundary, labels=[i for i in range(len(cut_boundary)-1)])
# print(data["score_label"].value_counts())
data_g = data.groupby("score_label")
for i in data_g:
mean = i[1][["1 try", "2 tries", "5 tries"]].mean()
# 这里的all 或者是 any 不可以省略,因为会返回多个值,pandas不能有多索引
print(i[1].loc[(i[1][["1 try", "2 tries", "5 tries"]] > mean).all(axis='columns')])
结果:
任务3:把数据按照 score 的取值区间等分成 5 个label。(等间分割)
def task_3(data):
max_data = data["score"].max()
min_data = data["score"].min()
cut_boundary = [min_data + i * (max_data - min_data) / 5 for i in range(5)]
cut_boundary.append(max_data)
data["score_label"] = pd.cut(x=data["score"], bins=cut_boundary, labels=[i for i in range(len(cut_boundary) - 1)])
print(data["score_label"].value_counts())
# 可以直接
# data["score_label"] = pd.cut(x=data["score"], bins=5, labels=[1, 2, 3, 4, 5])
结果:

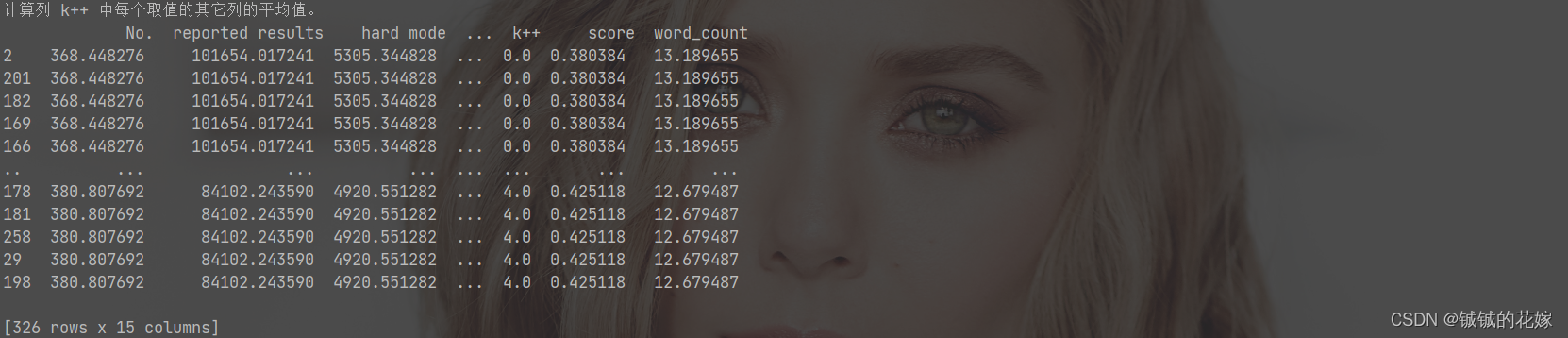
任务4:计算列 k++ 中每个取值的其它列的平均值。(聚类常用)
def task_4(data):
# 方法1:
column = data.columns.tolist()
data_g = data.groupby("k++")[column].transform('mean')
# transform 里面啥都能放 np.log、lambda s: (s - s.mean()) / s.std()等等
# 其实做到这里就可以了
data_g = data_g.sort_values("k++")
# 方法2:
column.remove("k++")
avg_salary_dict = data.groupby('k++')[column].mean().to_dict()
print(avg_salary_dict)
return data_g
结果:
任务5:把列 3 tries 和 2 tries 列中都低于平均值的数据去掉/把列 3 tries 或 2 tries 列中低于平均值的数据去掉。(基础,数据筛选常用)
def task_5(data):
# 前面task2用了该方法
# 不建议用filter,这个东西一般在df种对index或者列名操作的,搞正则的;在groupby里面倒是这种筛选挺多
mean = data[["2 tries", "3 tries"]].mean()
data_f_1 = data.loc[(data[["2 tries", "3 tries"]] > mean).any(axis='columns')]
# 第一次听说这里只能用&不能用and,还一定要括号
data_f_2 = data[(data['2 tries'] > mean[0]) & (data["3 tries"] > mean[1])]
return (data_f_1, data_f_2)
结果:

任务6:把score列内容转化为 int 型的数据;把date转为时间数据。(时间序列)
def task_6(data):
data["score"] = data["score"].astype(int)
data["date"] = pd.to_datetime(data["date"])
return data
结果:

任务7:统计word列内每个元素(字符串)含[‘a’, ‘b’, ‘c’]中字符的个数总和,并将其存为一个新列。(nlp常用)
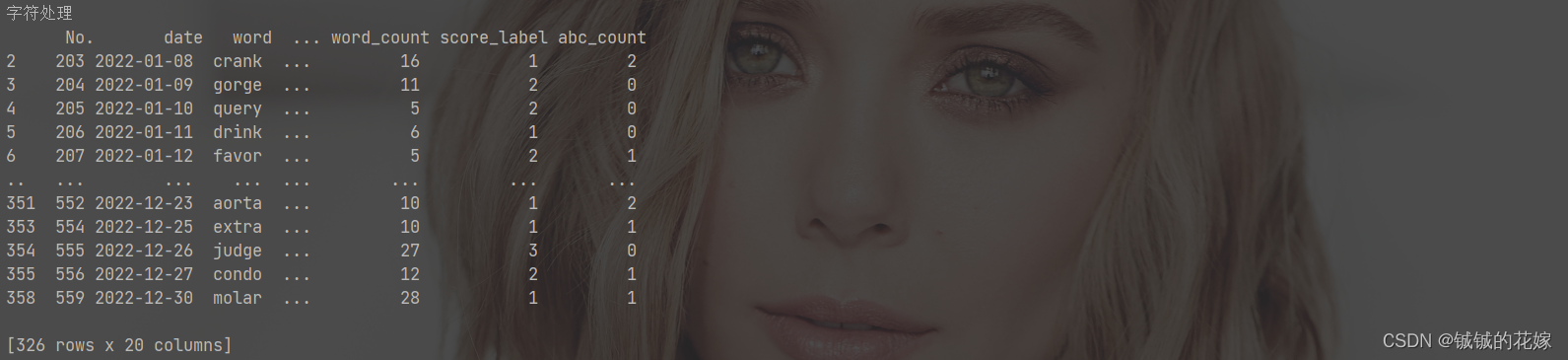
def task_7(data):
def count(x):
ret = 0
for i in x:
if i in ['a', 'b', 'c']:
ret+=1
return ret
data["abc_count"] = data["word"].apply(count)
return data
结果:
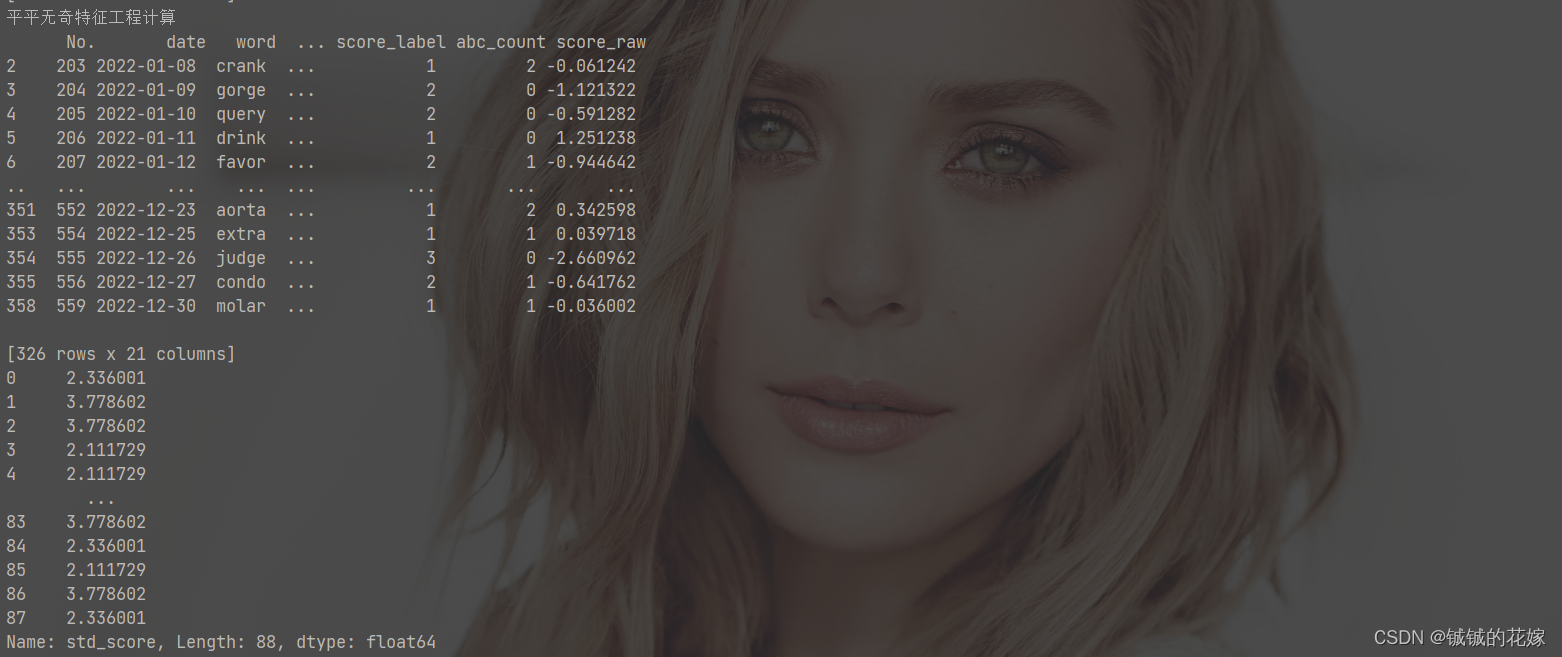
任务8:按照季度统计score_raw( ∑ i = 1 7 i t r i e s ∗ ( 7 − i ) \sum_{i=1}^{7}{i\ tries *(7-i)} ∑i=17i tries∗(7−i))并.Z-score标准化。(平平无奇特征工程计算)
def task_8(data):
# 没必要迷恋高阶函数,直接加减乘除也很香,特别是这种直接对整列操作的
data["score_raw"] = data['1 try']*6
for index, col in enumerate(['2 tries', '3 tries', '4 tries', '5 tries', '6 tries', '7 or more tries (X)']):
data["score_raw"] += data[col] * (5-index)
# 归一化
data["score_raw"] = (data["score_raw"]-data["score_raw"].mean())/data["score_raw"].std()
return data
结果:
任务9:将 sentence 长度在中位数之上或者 word 含[‘a’, ‘b’, ‘c’]中字符的样本按照 k++ 分类统计(tsne1,tsne2)的欧式距离和,并去除距离最短和最长的样本后计算 score 的标准差,并赋给这些样本(没有什么意义就是练手)
def task_9(data):
data = data.copy()
mid = data["word_count"].describe()["50%"]
data_1 = data[data["word_count"]>mid]
data_2 = data.query("word.str.contains('a|b|c')", engine="python")
data_merge = pd.merge(data_1, data_2, how="inner")
data_merge["dis"] = (data_merge["tsne1"]**2+data_merge["tsne2"]**2)**0.5
print(data_merge)
data_merge["dis"] = data_merge["dis"].astype(float)
data_merge_list = data_merge.groupby("k++").apply(lambda x: x.drop([x["dis"].idxmax(), x["dis"].idxmin()])).rename_axis([None,None]).groupby("k++")["dis"].describe()["std"].to_dict()
print(data_merge_list)
data_merge["std_score"] = data_merge["k++"].map(data_merge_list)
print(data_merge["std_score"])
# 思考题,后面这几部怎么用transform一步到位
return data
结果:

代码合集
我transform感觉用的一般,求路过的大神指点。
# 数据库方法汇总
def task_sql(data):
def task_0(data):
# 去含空行、去全重复行、去全重复列
data = data.dropna(how="any").drop_duplicates(keep=False).T.drop_duplicates(keep='first').T
# 统计词数之类的sentence操作
data = task_nlp(data)
# 去掉多出来的不要的吉列
data = data.drop(columns=["year", "month", "day", "token_word"])
return data
def task_1(data):
data_g = data.groupby("k++")
return [i for i in data_g]
def task_2(data):
# 原来想用describe算的,后来发现这不就一个sort的事情嘛
data = data.sort_values("score").reset_index()
data["score_label"] = (data.index / data.shape[0] * 4).astype(int)
# 用cut直接等分为四位,不知道为什么没有成功,但是思路上面还是上面这种更直接,这个有点为了cut而绕一下的感觉
# cut_boundary = [data.at[int(data.shape[0]/4*i), "score"] for i in range(0, 4)]
# cut_boundary.append(data.at[data.shape[0]-1, "score"])
# data["score_label"] = pd.cut(x=data["score"], bins=cut_boundary, labels=[i for i in range(len(cut_boundary)-1)])
# print(data["score_label"].value_counts())
data_g = data.groupby("score_label")
for i in data_g:
mean = i[1][["1 try", "2 tries", "5 tries"]].mean()
# 这里的all 或者是 any 不可以省略,因为会返回多个值,pandas不能有多索引
print(i[1].loc[(i[1][["1 try", "2 tries", "5 tries"]] > mean).all(axis='columns')])
def task_3(data):
max_data = data["score"].max()
min_data = data["score"].min()
cut_boundary = [min_data + i * (max_data - min_data) / 5 for i in range(5)]
cut_boundary.append(max_data)
data["score_label"] = pd.cut(x=data["score"], bins=cut_boundary, labels=[i for i in range(len(cut_boundary) - 1)])
print(data["score_label"].value_counts())
# 可以直接
# data["score_label"] = pd.cut(x=data["score"], bins=5, labels=[1, 2, 3, 4, 5])
def task_4(data):
# 方法1:
column = data.columns.tolist()
data_g = data.groupby("k++")[column].transform('mean')
# transform 里面啥都能放 np.log、lambda s: (s - s.mean()) / s.std()等等
# 其实做到这里就可以了
data_g = data_g.sort_values("k++")
# 方法2:
column.remove("k++")
avg_salary_dict = data.groupby('k++')[column].mean().to_dict()
print(avg_salary_dict)
return data_g
def task_5(data):
# 前面task2用了该方法
# 不建议用filter,这个东西一般在df种对index或者列名操作的,搞正则的;在groupby里面倒是这种筛选挺多
mean = data[["2 tries", "3 tries"]].mean()
data_f_1 = data.loc[(data[["2 tries", "3 tries"]] > mean).any(axis='columns')]
# 第一次听说这里只能用&不能用and,还一定要括号
data_f_2 = data[(data['2 tries'] > mean[0]) & (data["3 tries"] > mean[1])]
return (data_f_1, data_f_2)
def task_6(data):
data["score"] = data["score"].astype(int)
data["date"] = pd.to_datetime(data["date"])
return data
def task_7(data):
def count(x):
ret = 0
for i in x:
if i in ['a', 'b', 'c']:
ret+=1
return ret
data["abc_count"] = data["word"].apply(count)
return data
def task_8(data):
# 没必要迷恋高阶函数,直接加减乘除也很香,特别是这种直接对整列操作的
data["score_raw"] = data['1 try']*6
for index, col in enumerate(['2 tries', '3 tries', '4 tries', '5 tries', '6 tries', '7 or more tries (X)']):
data["score_raw"] += data[col] * (5-index)
# 归一化
data["score_raw"] = (data["score_raw"]-data["score_raw"].mean())/data["score_raw"].std()
return data
def task_9(data):
data = data.copy()
mid = data["word_count"].describe()["50%"]
data_1 = data[data["word_count"]>mid]
data_2 = data.query("word.str.contains('a|b|c')", engine="python")
data_merge = pd.merge(data_1, data_2, how="inner")
data_merge["dis"] = (data_merge["tsne1"]**2+data_merge["tsne2"]**2)**0.5
# print(data_merge)
data_merge["dis"] = data_merge["dis"].astype(float)
data_merge_list = data_merge.groupby("k++").apply(lambda x: x.drop([x["dis"].idxmax(), x["dis"].idxmin()])).rename_axis([None,None]).groupby("k++")["dis"].describe()["std"].to_dict()
# print(data_merge_list)
data_merge["std_score"] = data_merge["k++"].map(data_merge_list)
print(data_merge["std_score"])
# s思考题,后面这几部怎么用transform一步到位
return data
data = task_0(data)
task1 = task_1(data)
print("类别:\n{}\n类别大小:\n{}\n".format([i[0]for i in task1], [i[1].shape for i in task1]))
print("查看组中成员1 try, 2 tries, 5 tries 都大于平均水平的样本。\n",task_2(data))
print("等间分割score\n", task_3(data))
print("计算列 k++ 中每个取值的其它列的平均值。\n", task_4(data))
print("与条件或条件筛选数据\n", task_5(data)[0].shape, task_5(data)[1].shape)
print("数据转型\n",task_6(data))
# 转一下,之后有用
data["date"] = task_6(data)["date"]
print("字符处理\n",task_7(data))
print("平平无奇特征工程计算\n", task_8(data))
print("纯粹练手\n",task_9(data))
1.4. 计算
个人觉得计算这方面 numpy 更厉害一点,很多pandas的计算都是转移到 numpy 上做的,可能未来有空的时候会出numpy的计算博客。
当然计算不擅长不代表不能计算,pandas 的计算能力日常用用绝对是够的,所以个人认为整理一个大熊猫计算合集还是有必要的。
加减乘除方log
- 这里我们不止强调实现,还强调速度。别人已经试验过了,算这些的时候最好还是用pandas或者numpy的数组操作,什么apply啊什么iteration啊都被吊打。
- 还有就是注意被除数为0,我之前做实验的时候被坑惨了。
# 加减乘除
def add_mult(data, column1, column2):
# apply 和 迭代器速度被吊打
# data[[column1, column2]].apply(lambda x: x[column1] * x[column2], axis=1)
# for index, rows in data.iterrows():
# rows[column1] * rows[column2]
# pandas 数组操作
print(data[column1] + data[column2])
# numpy 数组操作
print(data[column1].values + data[column2].values)
# pandas 数组操作
print(data[column1] * data[column2])
# numpy 数组操作
print(data[column1].values * data[column2].values)
# 被除数为0
data_1 = data[column1] / data[column2]
data_1.replace([np.inf, -np.inf, "", np.nan], 0, inplace=True)
# or
def get_benrate(series, column1, column2):
shouru = series[column1]
chengben = series[column2]
if shouru == 0:
return 0
else:
return chengben / shouru
data_1 = data.apply(lambda x: get_benrate(x, column1, column2), axis=1)
print(data_1)
# 乘方
data_1 = data[column2]**2
print(data_1)
# log 直接 numpy 感觉会快一点
data_1 = pd.DataFrame(np.log(data[column2]))
print(data_1)
皮尔逊、余弦相似度
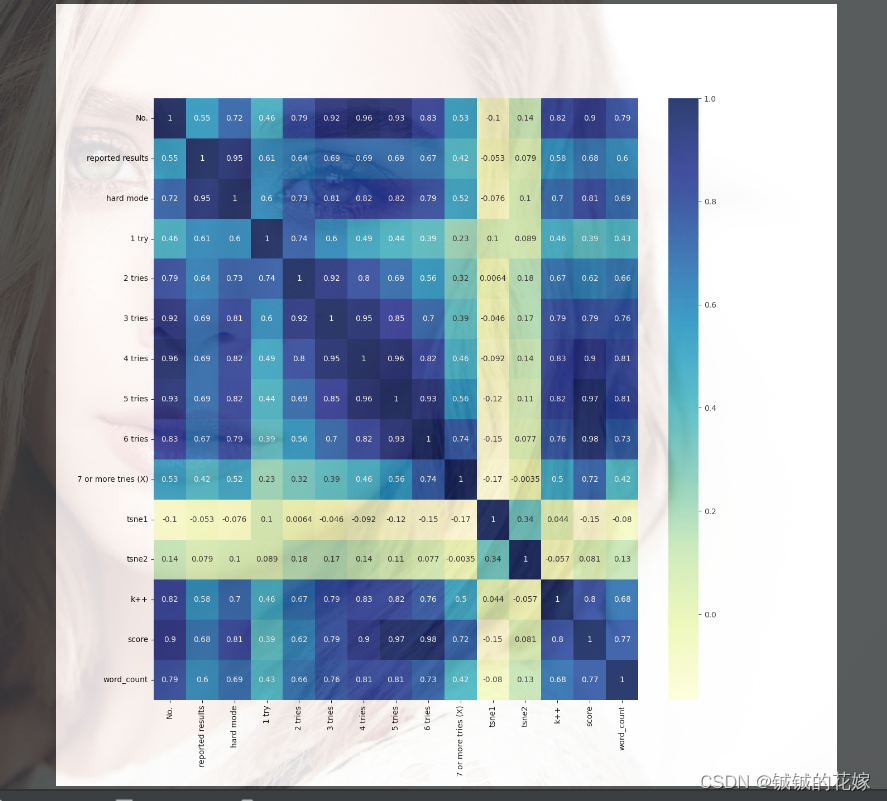
除了楼上那几个之外,就剩这些比较常用的系数之类的了。因为 pandas 功能重点确实不在计算上,所以要适度用下其他包。
皮尔逊这个表格应该是经典的
| 相关系数 | 相关度 |
|---|---|
| 0.8-1.0 | 极强相关 |
| 0.6-0.8 | 强相关 |
| 0.4-0.6 | 中等程度相关 |
| 0.2-0.4 | 弱相关 |
| 0.0-0.2 | 极弱相关或无相关 |
直接numpy计算加一波可视化带走。
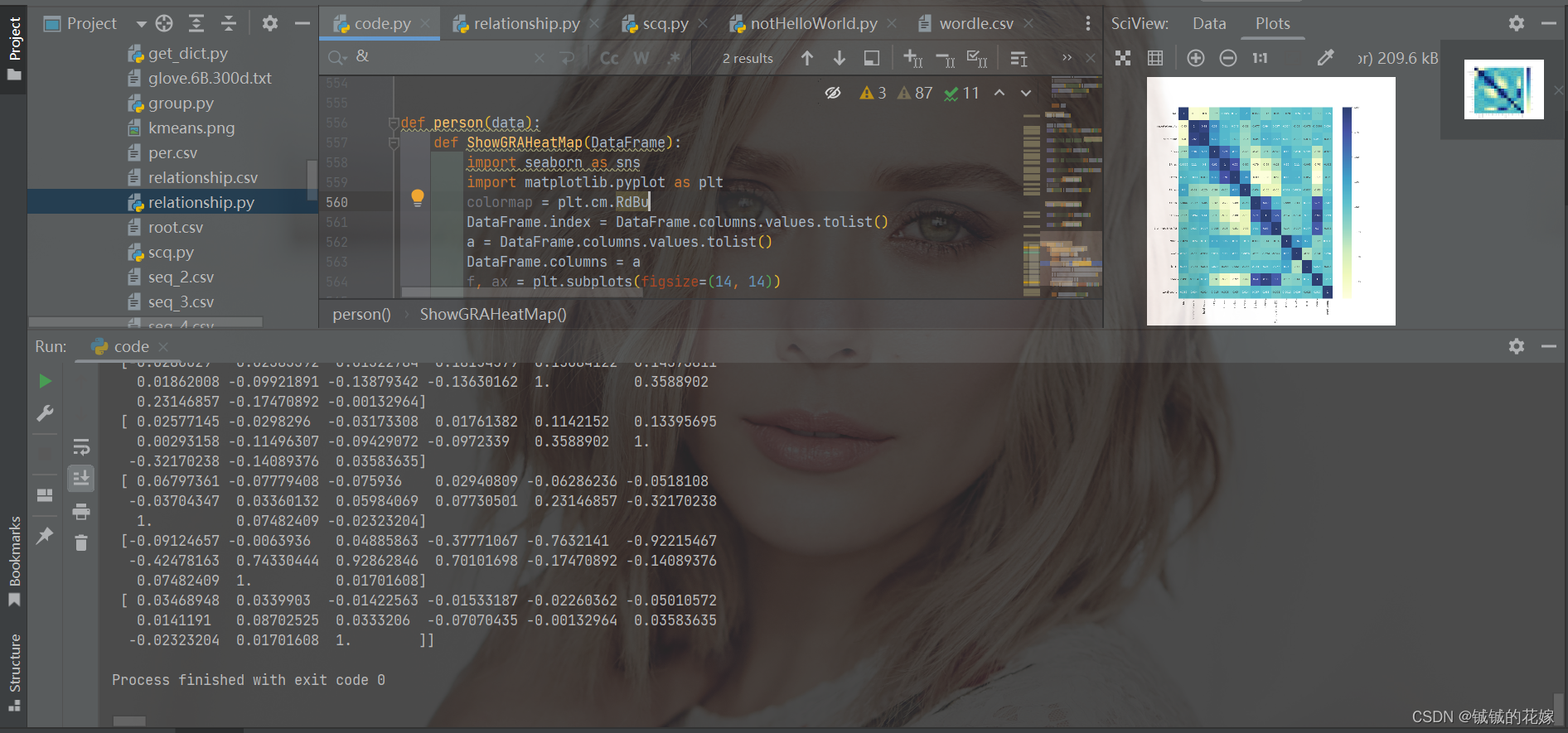
def person(data):
def ShowGRAHeatMap(DataFrame):
import seaborn as sns
import matplotlib.pyplot as plt
colormap = plt.cm.RdBu
DataFrame.index = DataFrame.columns.values.tolist()
a = DataFrame.columns.values.tolist()
DataFrame.columns = a
f, ax = plt.subplots(figsize=(14, 14))
with sns.axes_style("white"):
sns.heatmap(DataFrame,
cmap="YlGnBu",
annot=True,
# mask=mask,
# ylabels =
)
plt.show()
# 去含空行、去全重复行、去全重复列
types = data.dtypes
data = data.dropna(how="any").T.drop_duplicates(keep='first').T.drop_duplicates(keep=False)
# 楼上一波操作,数据莫名其妙地全变object了,变回来。
data = data.astype(types.loc[data.columns.tolist()])
# 统计词数之类的sentence操作
data = task_nlp(data)
# 非数值的不要
data = data.loc[:, (data.head(1).dtypes == np.int64) | (data.head(1).dtypes == np.float64)]
pccs = np.corrcoef(data.T)
print(pccs)
ShowGRAHeatMap(pd.DataFrame(pccs, columns=data.columns))
效果还可以吧,主要是不知道为什么下面那个输出不把run占满。。。
余弦相似度跟上面那个很像,但是懒得合并了,这个专栏做太久都没心思了。这里顺便再画一个散点图。
def cos(data:pd.DataFrame):
def ShowGRAHeatMap(DataFrame):
import seaborn as sns
import matplotlib.pyplot as plt
colormap = plt.cm.RdBu
DataFrame.index = DataFrame.columns.values.tolist()
a = DataFrame.columns.values.tolist()
DataFrame.columns = a
f, ax = plt.subplots(figsize=(14, 14))
with sns.axes_style("white"):
sns.heatmap(DataFrame,
cmap="YlGnBu",
annot=True,
# mask=mask,
# ylabels =
)
plt.show()
from sklearn.metrics.pairwise import cosine_similarity
types = data.dtypes
data = data.dropna(how="any").T.drop_duplicates(keep='first').T.drop_duplicates(keep=False)
data = data.astype(types.loc[data.columns.tolist()])
data = task_nlp(data)
data = data.loc[:, (data.head(1).dtypes == np.int64) | (data.head(1).dtypes == np.float64)]
cos_sim = cosine_similarity(data.T)
ShowGRAHeatMap(pd.DataFrame(cos_sim, columns=data.columns))
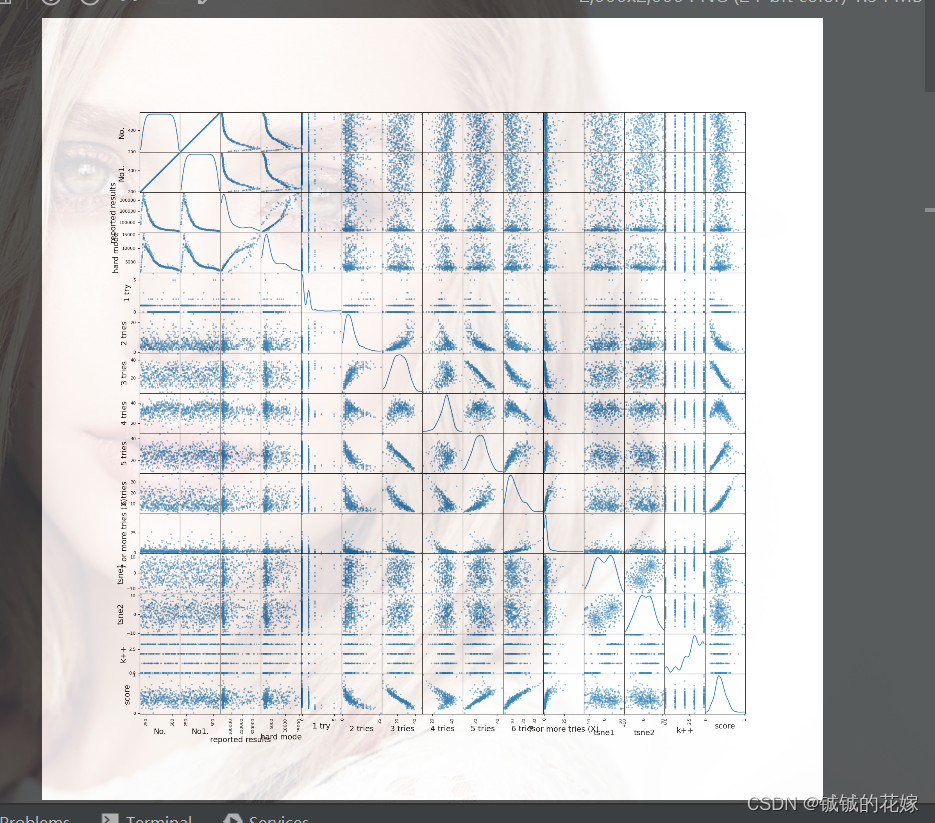
pd.plotting.scatter_matrix(data,figsize=(20,20),diagonal='kde')
plt.show()
图片倒是听壮观的,就是特征有点多
散点图同理
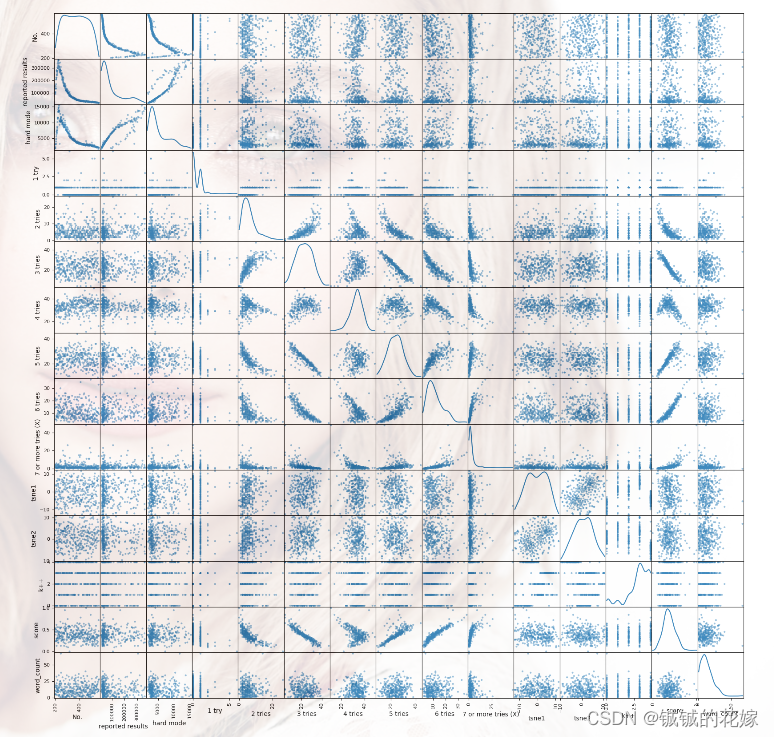
2. 数据概览
2.1. 统计
查看数据特性
这5个是必须要掌握的。
# 查看数据情况
def first_view(data):
print("数据规模:\n", data.shape)
print("10样本:\n", data.head(10))
print("数据类型:\n", data.dtypes)
print("数据分布:\n", data.describe())
print("数据为空:\n", data.info())
效果自己尝试,图太长放不下。
按照某列的值排序
sort_values() 就特别好用,掌握几点:
- 主次要关键字排序
- 升序降序排序
- 缺失值
对照着写了个函数:
data = data[["2 tries", "No."]].copy()
print(data.sort_values("2 tries"))
print(data.sort_values("2 tries", ascending=False))
print(data.sort_values(["2 tries", "No."], ascending=False))
print(data.sort_values(["2 tries", "No."], ascending=False, na_position="first"))
四个输出分别为:


查看属性中元素为特定值的个数
value_counts() 也特别好用,掌握几点:
- value组合count
- 占比
- 排序
- 等分
- 空值
def countvalue(data:pd.DataFrame):
data = data[["1 try", "2 tries" ,"k++"]].copy()
print(data.value_counts())
print(data["1 try"].value_counts(ascending=True))
print(data["1 try"].value_counts(bins=5))
print(data["1 try"].value_counts(sort=False))
print(data["2 tries"].value_counts(dropna=False))
正常排序:

结果降序:
比例显示:

等分:

不排序:

留空值:

2.2. 画图
不用 plt,或者说不直接用,这里采用 pandas 内置的 plot,虽然原理一样,但是没有 plt 那个灵活,不过自己看看还是没有问题的,这里的关键词是迅速。
图片的背景是我的pycharm的不是图片的。
饼图
一些个简单代码
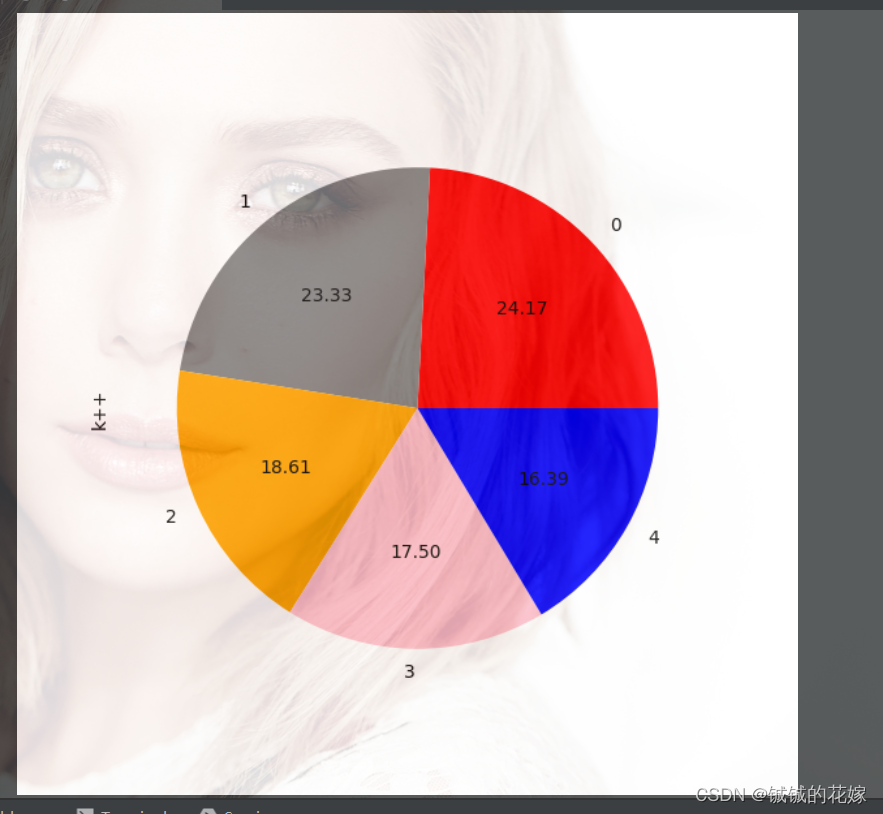
def pie_plot(data:pd.DataFrame):
a = data["k++"].value_counts(normalize=True)
a.plot.pie(labels=data.index, colors=["red", "gray", "orange", "pink", "blue", "green"], autopct='%.2f', fontsize=10, figsize=(6, 6))
plt.show()
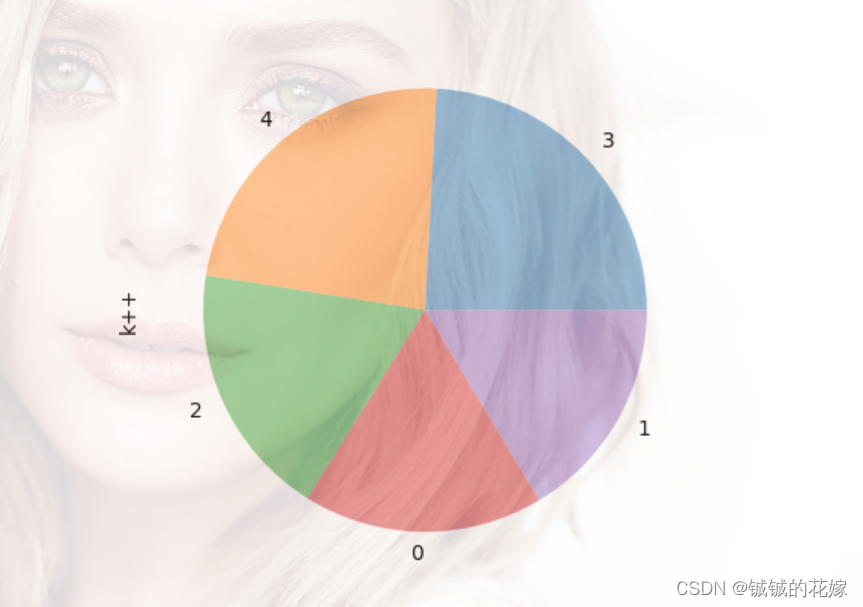
data["k++"].value_counts(normalize=True).plot(kind='pie', wedgeprops={'alpha': 0.5})
plt.show()
这张图没透明度,透明度是我的背景自带的
这个是有透明度设置的
柱状图
有就行,不求多高级,几个常调整的参数改了一下:
def col_plot(data:pd.DataFrame):
a = data["k++"].value_counts(normalize=True)
a.plot.bar(a.index, a.values, color=["red", "gray", "orange", "pink", "blue", "green"][3], fontsize=10, figsize=(6, 6))
plt.show()
平平无奇
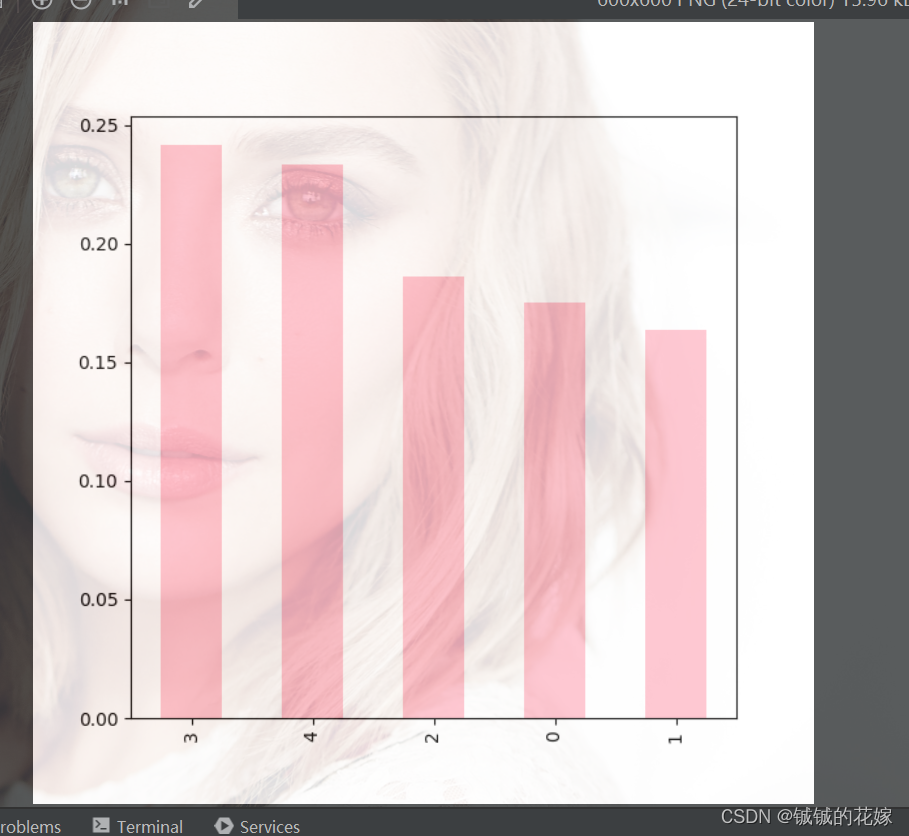
散点图
def scatter_plot(data:pd.DataFrame):
plt.rcParams["font.size"] = 14
colors = np.array(["red", "gray", "orange", "pink", "blue", "green"])
data.plot.scatter(x='tsne1', y='tsne2', marker='x', s=500, color=colors[data["k++"]], alpha=0.4)
# s: 大小
# marker: 点样式
# alpha: 点透明
plt.show()
两张图
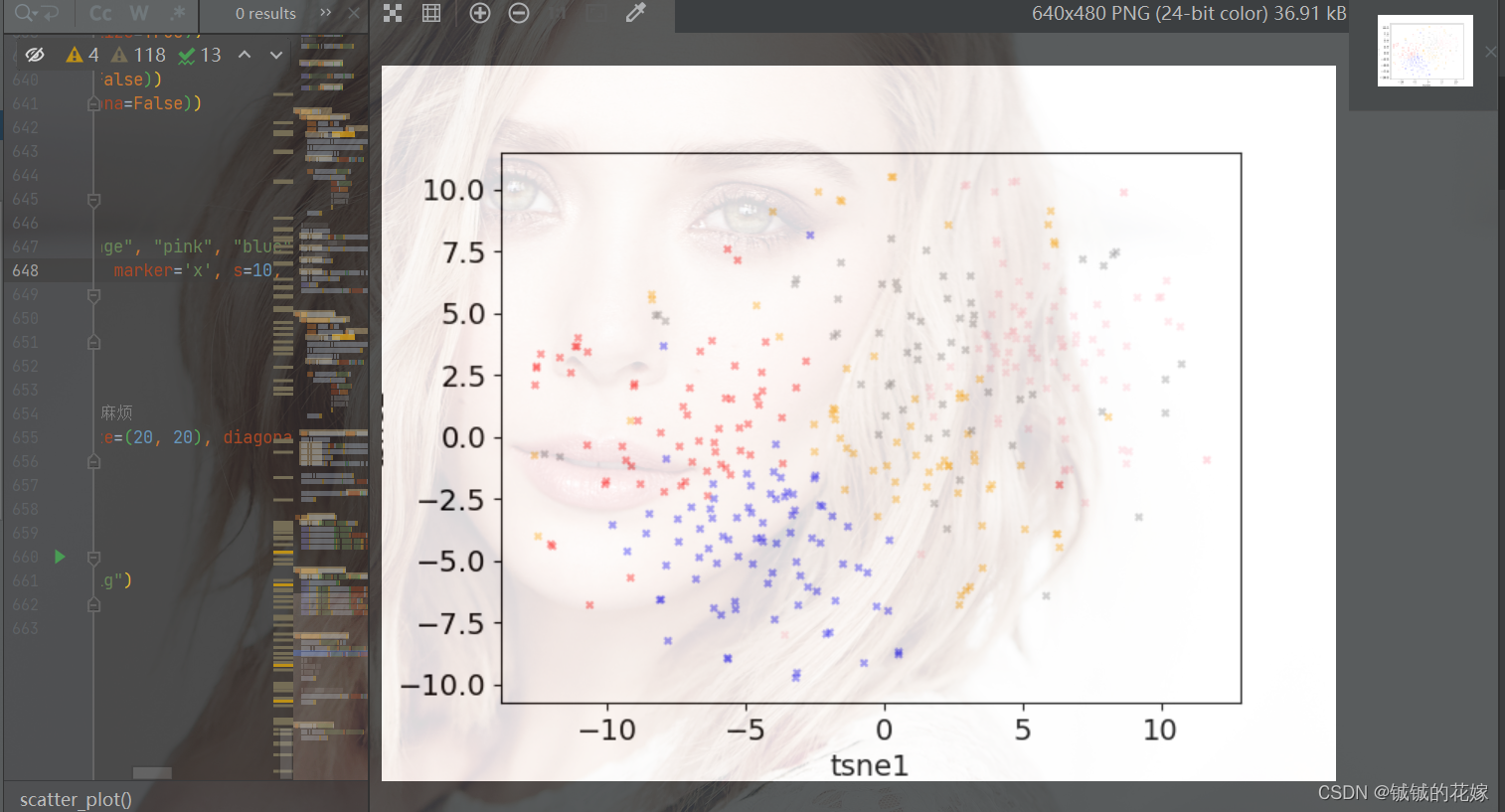
总结与感想
网上总说在csdn中找找东西就像在垃圾堆中淘宝,有一说一其实在网上检索信息其实感觉都类似,除了直接 chatGPT(我chat哥确实逆天)之外,很难准确找到自己想要的东西。很多知识,特别是应用型的知识,如果仅仅停留在完成任务或者“用过”,则很难内化为自己的东西,下次想用的时候便需要返回纷繁丛杂的互联网,效率极低且对个人能力毫无提升。
回想曾经做过的任务:新闻小说识别、作者识别、语体风格分析、话语分析、学生画像、异常店铺商品识别、知识图谱、飞机坠落模拟、移动用户行为分析、塞罕坝林场预测分析、亚马逊商品销售分析、中国青年人婚姻状态分析、黄金美元比特币股票模拟……感觉数据分析机器学习这块杂七杂八的做的真的非常多,但是还是没有得心应手的感觉。
为何?
缺少整理
很多报错,很多功能,解决或者实现了之后就直接抛掷脑后了。一开始是对网上信息杂乱无章的不满,决定写一篇自己的整理文,就算当字典查效果也不会差。整理后发现不仅巩固了之前的知识,还发现了很多自己之前没实现的功能或者优化了之前的写法。受益颇多,故未来可能会出更多的整理文。
全部代码
import re
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# #显示所有列
# pd.set_option('display.max_columns', None)
# #显示所有行
# pd.set_option('display.max_rows', None)
# #设置value的显示长度为100,默认为50
# pd.set_option('max_colwidth', 100)
# 获取数据
def get_data(file_name, encode):
file = pd.read_csv(file_name, encoding=encode)
# 读前100行,指定列
file1 = pd.read_csv(file_name, encoding=encode, nrows=100, usecols=['No.', 'word', 'reported results'])
# 特别大的csv我们分块读取分块处理(chunksize)
table = pd.read_csv(file_name, encoding=encode, chunksize=100)
for chunk in table:
# 该干嘛干嘛
print(type(chunk), chunk.shape)
# 迭代着读
reader = pd.read_csv(file_name, encoding=encode, iterator=True)
ret = [] # 结果存这
while 1:
try:
chunk = reader.get_chunk(100)
# 该干嘛干嘛
print(type(chunk), chunk.shape)
ret.append(chunk)
except StopIteration:
print("Iteration is stopped.")
break
print(ret)
# 超级超级大的数据(亿级别) 快跑~~
return file
# 查看数据情况
def first_view(data):
print("数据规模:\n", data.shape)
print("10样本:\n", data.head(10))
print("数据类型:\n", data.dtypes)
print("数据分布:\n", data.describe())
print("数据为空:\n", data.info())
# 行/列/遍历
def read_row_column_cell(data):
data = data[data.columns[:3]]
data = data.head(3)
print("原数据:\n", data)
print("\ninterrows遍历:")
for index, row in data.iterrows():
print(index, row['No.'], row['date'])
print("\nitertuples遍历:")
for row in data.itertuples():
print(row)
print(getattr(row, 'Index'), getattr(row, 'date'))
print("\niteritems列遍历:")
for row in data.iteritems():
# 0是列名,1是列内容
print(row[0], row[1])
# 取行列单元格
def get_line_col_cell(data):
data = data[["No.", "word", "1 try"]].copy()
print("\n取No.列所有数据")
print(data["No."])
print(data.loc[:, "No."])
print("\n取No.,word列所有数据")
print(data[["No.", "word"]])
print(data.loc[:, ["No.", "word"]])
print("\n取第20行数据")
print(data.iloc[20])
print(data.loc[20])
print("\n取第20-22行, 30-32行数据, 50行数据")
print(data.iloc[np.r_[20:22, 30:32, 50]])
print(data.loc[np.r_[20:22, 30:32, 50]])
print("\n取word, 1 try 列第20-22行, 50行数据")
print(data.iloc[np.r_[20:22, 50], [1, 2]])
print(data.loc[np.r_[20:22, 50], ["word", "1 try"]])
print("\n分别取word列第20个单词,23个单词")
print(data.iloc[[20, 23], [1]].values[:, 0])
print(data.loc[[20, 23], "word"].values[:])
print(data.at[20, "word"], data.at[23, "word"])
print(data.iat[20, 1], data.at[23, "word"])
# 高阶函数
def try_app_map_appmap(data):
# copy()不要忘记
data = data[["word", "tsne1", "tsne2", "k++", "score"]].copy()
print("\ntask1")
data_t = data[["tsne1", "tsne2"]]
data_t = data_t.applymap(lambda x: "%.2f" % x)
print(data_t.head(3))
# 楼上的操作多少有点刻意炫技,直接round也可以
print(data[["tsne1", "tsne2"]].round(2).head(3))
print("\ntask2")
data_w = data[["word"]]
bool_w = data_w.applymap(lambda x: "a" in x)
# 提一嘴,这样赋值等效 data["word"] = data_w[bool_w]
data.loc[:, "word"] = data_w[bool_w]
data["a_begin"] = data_w.applymap(lambda x: int("a" == x[0]))
print(data.head(7))
print("\ntask3")
name = ["first", "second", "third", "fourth", "fifth", "sixth"]
data.loc[:, "k++"] = data["k++"].map({i: name[i] for i in data["k++"].unique()})
print(data.head(7))
print("\ntask4")
def sig(series):
t = 1 + np.exp(-series)
return 1 / t
data.loc[:, "sigmiod"] = data["score"].apply(lambda x: sig(x))
print(data.head(7))
# 去重
def drop_null(data_source):
data = data_source[["word", "sentence", "1 try", "2 tries", "3 tries", "4 tries", "5 tries"]].copy()
print("源数据\n", data.shape)
data.drop_duplicates(keep=False, inplace=True)
print("去完全重复行\n", data.shape)
data.drop_duplicates(subset=["1 try", "5 tries"], keep="first", inplace=True)
print("去 1, 5 都重复行\n", data.shape)
# 没招了,只能一项一项来了
for col in ["1 try", "5 tries"]:
data.drop_duplicates(subset=col, keep="first", inplace=True)
print("去 1, 5 重复行\n", data.shape)
data = data_source[["word", "sentence", "1 try", "2 tries", "3 tries", "4 tries", "5 tries"]].copy()
data = data[data["5 tries"] <= data["5 tries"].mean()].drop_duplicates(["1 try"])
print("条件去重\n", data.shape)
print("看看结果\n", data.head(4))
# 有的时候需要重置一下索引
print("重置索引\n", data.reset_index())
# 维度变换
def stack_unstack(data):
print(data.shape, type(data), "\n\n")
data = data.stack()
print(data.shape, type(data))
print(data)
print(data.reset_index(), "\n\n")
data = data.unstack()
print(data.shape, type(data))
print(data)
# 保存数据
def save_data(data):
data.loc[:, "这是一行中文"] = ["中文"] * data.shape[0]
data.to_csv("without_sig.csv", encoding="utf-8")
data.to_csv("with_sig.csv", encoding="utf-8-sig")
data.to_csv("tsv.tsv", encoding="utf-8-sig", sep="\t")
data.to_csv("without_index.csv", encoding="utf-8-sig", index=0)
# nlp的几个任务
def task_nlp(data):
# 去标点
def de_punctuation(data):
# 正则表达式去除两种引号,直接写会报错,因为空数据集存在,这里补一个try:
def app_fun(series):
try:
series = re.sub(r'[\'\"]', '', series)
except TypeError:
return np.nan
return series
data["sentence"] = data["sentence"].apply(lambda x: app_fun(x))
print(data["sentence"])
return data
# 算词数
def cul_wordcount(data):
def counting(series):
import jieba
try:
seg_list = jieba.cut(series)
# 返回的是一个迭代器直接循环遍历算了,反正之后还是要用的
# 顺便去个空
ret = [x for x in seg_list if x != " "]
except:
return []
return ret
ret = data["sentence"].apply(lambda x: counting(x))
return ret.apply(lambda x: len(x)), ret
# 建词典
def build_dic(data):
dict = {}
def counting(series):
for key in series:
dict[key] = dict.get(key, 0) + 1
data["token_word"].apply(counting)
return sorted(dict.items(), key=lambda x: x[1], reverse=True)
# 转日期
def date_T(data):
def fun(x):
ret = re.findall(r'(\d{4})/(\d{1,2})/(\d{1,2})', x)[0]
return "{}/{:0>2d}/{:0>2d}".format(ret[0], int(ret[1]), int(ret[2]))
# 标准日期
ret = data["date"].apply(fun)
print(ret)
# 这里实在没想到什么好看快速的写法,土方法吧
splitt = ret.str.split("/", expand=True)
print(splitt)
data["date"], data[["year", "month", "day"]] = ret, splitt
return data
data = de_punctuation(data)
print(cul_wordcount(data))
data["word_count"], data["token_word"] = cul_wordcount(data)
print(data)
print(build_dic(data))
data = date_T(data)
print(data)
return data
# 空
def deal_with_null(data):
# 输出含有空值的列
print("空值列:")
print(data.isnull().any())
print(data.info())
# 输出含有空值的行
print("含空值行:")
null_row = data.T.isnull().any()
print(null_row[null_row == True].index)
# 输出全空的行、特定列空的行
null_row_1 = data.T.isnull().all()
null_row_2 = data[["2 tries", "3 tries", "4 tries", "5 tries"]].T.isnull().any()
print("全空行:")
print(null_row_1[null_row_1 == True].index)
print("特定列空:")
print(null_row_2[null_row_2 == True].index)
# 看看空行
print("空行查看:")
null_row = data.loc[null_row == True, data.columns[data.isnull().any()]]
print(null_row)
print(null_row.info())
# 删除空行
print("删全空行:")
print(null_row.dropna(how="all"))
print("删列[\"5 tries\", \"sentence\"]含空行:")
print(null_row.dropna(subset=["5 tries", "sentence"]))
print("删列[\"5 tries\", \"sentence\"]全空行,保留空值数量<40%的行")
print(null_row.dropna(how="all", thresh=int(0.4 * len(null_row.columns)), subset=["5 tries", "sentence"]))
# 加行列
def add_row_col(data):
# 取一部分,方便输出
data_1 = data.iloc[3:8, np.r_[3, 5:9]].copy()
data_add = data.iloc[9:11, np.r_[3, 5:9]].copy()
# append
print("添加行")
print(data_1.append(data_add))
# concat做(多列数据)
print(pd.concat([data_1, pd.DataFrame(data_add).T], axis=0))
print("直接构建行")
# 字典(提前知道数据了)
data_add = []
for i in range(3, 11): # 循环跑完我们就准备好了要加入的数据
dict = {}
for col in data_1.columns:
dict[col] = data.at[i, col]
data_add.append(dict)
print(pd.DataFrame(data_add))
print("添加列")
# 列操作
data_1["new_col"] = [1 for i in range(data_1.shape[0])]
data_1[["new_col_1", "new_col_2"]] = [[2, 3] for i in range(data_1.shape[0])]
print(data_1)
# 合并
def hebing_row_col(data):
# 数据准备
# [3, 4]
data_1 = data.loc[:2, ["1 try", "2 tries", "3 tries", "4 tries"]].copy()
# [3, 4]
data_2 = data.loc[2:4, ["1 try", "2 tries", "3 tries", "4 tries"]].copy()
# [3, 4]
data_3 = data.loc[2:5, ["1 try", "2 tries", "3 tries", "5 tries"]].copy()
print("data1\n{}\ndata2\n{}\ndata3\n{}".format(data_1, data_2, data_3))
print("\n\n行合并")
print("普通行合并,发现没有去重,没有index重排")
print(pd.concat([data_1, data_2]))
print("index重排了")
print(pd.concat([data_1, data_2], ignore_index=True))
print("区别inner 和 outer")
print(pd.concat([data_1, data_3], join="outer", ignore_index=True))
print(pd.concat([data_1, data_3], join="inner", ignore_index=True))
print("多个合并")
print(pd.concat([data_1, data_2, data_3], join="outer"))
print("\n\n列合并")
print("1. concat部分")
print("因为没有去重功能,直接列合并就变成一堆nan")
print(pd.concat([data_1, data_2], axis=1))
print("很鸡肋的消除列名")
print(pd.concat([data_1, data_2], axis=1, ignore_index=True))
print("inner一下")
print(pd.concat([data_1, data_2], axis=1, join="inner"))
print("2. merge部分")
print("inner 只保留了表中重复部分,不为空,含去重")
print(pd.merge(data_1, data_3))
print("outer 全部保留,补空,含去重")
print(pd.merge(data_1, data_3, how="outer"))
print("left 只留data_1有的样本")
print(pd.merge(data_1, data_3, how="left"))
print("right 只留data_3有的样本")
print(pd.merge(data_1, data_3, how="right"))
print("on 保留左右两边非index的共有部分")
print(pd.merge(data_1, data_3, how="right", on="2 tries"))
print(pd.merge(data_1, data_3, how="right", on=["2 tries", "3 tries"]))
# 删除
def delete_row_col(data):
data = data.loc[np.r_[:2, 5:8], ["word", "1 try", "2 tries", "3 tries", "4 tries"]].copy()
print("源数据\n", data)
print("行索引删除\n", data.drop(1))
print("不连续行删除\n", data.drop(np.r_[1, 5:7]))
print("列名多个删除\n", data.drop(["1 try", "2 tries"], axis=1))
print("列不连续行不连续删除\n", data.drop(index=np.r_[1, 5:7], columns=["1 try", "2 tries", "4 tries"]))
print("转换思路,直接取,而不是删除\n", data.loc[[0, 7], ["word", "3 tries"]])
# 查询并修改
def get_modify(data):
print("第201行:\n", data.loc[200])
data.loc[200] = {"No.": "456", "No1.": "456", "date": "2022/9/18", "word": "stick",
"sentence": 'The two lovers are partners but not married .', "reported results": "33102",
"hard mode": "3038"}
print("修改后第201行:\n", data.loc[200])
print("No.列:\n", data["No."])
data.loc[:, "No."] = 1 * data.shape[0] - 1
print("修改后No.列:\n", data.loc[:, "No."])
print("修改第100-102行的\'No.\', \'No1.\', \'word\'")
new = [
[111, 222, "KFC疯狂"],
[111, 222, "星期四是兄"],
[111, 222, "弟V我50"]
]
data.loc[100:102, ['No.', 'No1.', 'word']] = new
print(data.loc[100:102])
print("第102行,1 try列值修改为负无穷")
print(data.at[102, "1 try"])
data.at[102, "1 try"] = -np.inf
print(data.at[102, "1 try"])
# 加减乘除
def add_mult(data, column1, column2):
# apply 和 迭代器速度被吊打
# data[[column1, column2]].apply(lambda x: x[column1] * x[column2], axis=1)
# for index, rows in data.iterrows():
# rows[column1] * rows[column2]
# pandas 数组操作
print(data[column1] + data[column2])
# numpy 数组操作
print(data[column1].values + data[column2].values)
# pandas 数组操作
print(data[column1] * data[column2])
# numpy 数组操作
print(data[column1].values * data[column2].values)
# 被除数为0
data_1 = data[column1] / data[column2]
data_1.replace([np.inf, -np.inf, "", np.nan], 0, inplace=True)
# or
def get_benrate(series, column1, column2):
shouru = series[column1]
chengben = series[column2]
if shouru == 0:
return 0
else:
return chengben / shouru
data_1 = data.apply(lambda x: get_benrate(x, column1, column2), axis=1)
print(data_1)
# 乘方
data_1 = data[column2] ** 2
print(data_1)
# log 直接 numpy 感觉会快一点
data_1 = pd.DataFrame(np.log(data[column2]))
print(data_1)
# 数据库方法汇总
def task_sql(data):
def task_0(data):
# 去含空行、去全重复行、去全重复列
data = data.dropna(how="any").drop_duplicates(keep=False).T.drop_duplicates(keep='first').T
# 统计词数之类的sentence操作
data = task_nlp(data)
# 去掉多出来的不要的吉列
data = data.drop(columns=["year", "month", "day", "token_word"])
return data
def task_1(data):
data_g = data.groupby("k++")
return [i for i in data_g]
def task_2(data):
# 原来想用describe算的,后来发现这不就一个sort的事情嘛
data = data.sort_values("score").reset_index()
data["score_label"] = (data.index / data.shape[0] * 4).astype(int)
# 用cut直接等分为四位,不知道为什么没有成功,但是思路上面还是上面这种更直接,这个有点为了cut而绕一下的感觉
# cut_boundary = [data.at[int(data.shape[0]/4*i), "score"] for i in range(0, 4)]
# cut_boundary.append(data.at[data.shape[0]-1, "score"])
# data["score_label"] = pd.cut(x=data["score"], bins=cut_boundary, labels=[i for i in range(len(cut_boundary)-1)])
# print(data["score_label"].value_counts())
data_g = data.groupby("score_label")
for i in data_g:
mean = i[1][["1 try", "2 tries", "5 tries"]].mean()
# 这里的all 或者是 any 不可以省略,因为会返回多个值,pandas不能有多索引
print(i[1].loc[(i[1][["1 try", "2 tries", "5 tries"]] > mean).all(axis='columns')])
def task_3(data):
max_data = data["score"].max()
min_data = data["score"].min()
cut_boundary = [min_data + i * (max_data - min_data) / 5 for i in range(5)]
cut_boundary.append(max_data)
data["score_label"] = pd.cut(x=data["score"], bins=cut_boundary, labels=[i for i in range(len(cut_boundary) - 1)])
print(data["score_label"].value_counts())
# 可以直接
# data["score_label"] = pd.cut(x=data["score"], bins=5, labels=[1, 2, 3, 4, 5])
def task_4(data):
# 方法1:
column = data.columns.tolist()
data_g = data.groupby("k++")[column].transform('mean')
# transform 里面啥都能放 np.log、lambda s: (s - s.mean()) / s.std()等等
# 其实做到这里就可以了
data_g = data_g.sort_values("k++")
# 方法2:
column.remove("k++")
avg_salary_dict = data.groupby('k++')[column].mean().to_dict()
print(avg_salary_dict)
return data_g
def task_5(data):
# 前面task2用了该方法
# 不建议用filter,这个东西一般在df种对index或者列名操作的,搞正则的;在groupby里面倒是这种筛选挺多
mean = data[["2 tries", "3 tries"]].mean()
data_f_1 = data.loc[(data[["2 tries", "3 tries"]] > mean).any(axis='columns')]
# 第一次听说这里只能用&不能用and,还一定要括号
data_f_2 = data[(data['2 tries'] > mean[0]) & (data["3 tries"] > mean[1])]
return (data_f_1, data_f_2)
def task_6(data):
data["score"] = data["score"].astype(int)
data["date"] = pd.to_datetime(data["date"])
return data
def task_7(data):
def count(x):
ret = 0
for i in x:
if i in ['a', 'b', 'c']:
ret+=1
return ret
data["abc_count"] = data["word"].apply(count)
return data
def task_8(data):
# 没必要迷恋高阶函数,直接加减乘除也很香,特别是这种直接对整列操作的
data["score_raw"] = data['1 try']*6
for index, col in enumerate(['2 tries', '3 tries', '4 tries', '5 tries', '6 tries', '7 or more tries (X)']):
data["score_raw"] += data[col] * (5-index)
# 归一化
data["score_raw"] = (data["score_raw"]-data["score_raw"].mean())/data["score_raw"].std()
return data
def task_9(data):
data = data.copy()
mid = data["word_count"].describe()["50%"]
data_1 = data[data["word_count"]>mid]
data_2 = data.query("word.str.contains('a|b|c')", engine="python")
data_merge = pd.merge(data_1, data_2, how="inner")
data_merge["dis"] = (data_merge["tsne1"]**2+data_merge["tsne2"]**2)**0.5
# print(data_merge)
data_merge["dis"] = data_merge["dis"].astype(float)
data_merge_list = data_merge.groupby("k++").apply(lambda x: x.drop([x["dis"].idxmax(), x["dis"].idxmin()])).rename_axis([None,None]).groupby("k++")["dis"].describe()["std"].to_dict()
# print(data_merge_list)
data_merge["std_score"] = data_merge["k++"].map(data_merge_list)
print(data_merge["std_score"])
# s思考题,后面这几部怎么用transform一步到位
return data
data = task_0(data)
task1 = task_1(data)
print("类别:\n{}\n类别大小:\n{}\n".format([i[0]for i in task1], [i[1].shape for i in task1]))
print("查看组中成员1 try, 2 tries, 5 tries 都大于平均水平的样本。\n",task_2(data))
print("等间分割score\n", task_3(data))
print("计算列 k++ 中每个取值的其它列的平均值。\n", task_4(data))
print("与条件或条件筛选数据\n", task_5(data)[0].shape, task_5(data)[1].shape)
print("数据转型\n",task_6(data))
# 转一下,之后有用
data["date"] = task_6(data)["date"]
print("字符处理\n",task_7(data))
print("平平无奇特征工程计算\n", task_8(data))
print("纯粹练手\n",task_9(data))
def person(data):
def ShowGRAHeatMap(DataFrame):
import seaborn as sns
import matplotlib.pyplot as plt
colormap = plt.cm.RdBu
DataFrame.index = DataFrame.columns.values.tolist()
a = DataFrame.columns.values.tolist()
DataFrame.columns = a
f, ax = plt.subplots(figsize=(14, 14))
with sns.axes_style("white"):
sns.heatmap(DataFrame,
cmap="YlGnBu",
annot=True,
# mask=mask,
# ylabels =
)
plt.show()
# 去含空行、去全重复行、去全重复列
types = data.dtypes
data = data.dropna(how="any").T.drop_duplicates(keep='first').T.drop_duplicates(keep=False)
# 楼上一波操作,数据莫名其妙地全变object了,变回来。
data = data.astype(types.loc[data.columns.tolist()])
# 统计词数之类的sentence操作
data = task_nlp(data)
# 非数值的不要
data = data.loc[:, (data.head(1).dtypes == np.int64) | (data.head(1).dtypes == np.float64)]
pccs = np.corrcoef(data.T)
print(pccs)
ShowGRAHeatMap(pd.DataFrame(pccs, columns=data.columns))
def cos(data:pd.DataFrame):
def ShowGRAHeatMap(DataFrame):
import seaborn as sns
import matplotlib.pyplot as plt
colormap = plt.cm.RdBu
DataFrame.index = DataFrame.columns.values.tolist()
a = DataFrame.columns.values.tolist()
DataFrame.columns = a
f, ax = plt.subplots(figsize=(14, 14))
with sns.axes_style("white"):
sns.heatmap(DataFrame,
cmap="YlGnBu",
annot=True,
# mask=mask,
# ylabels =
)
plt.show()
from sklearn.metrics.pairwise import cosine_similarity
types = data.dtypes
data = data.dropna(how="any").T.drop_duplicates(keep='first').T.drop_duplicates(keep=False)
data = data.astype(types.loc[data.columns.tolist()])
data = task_nlp(data)
data = data.loc[:, (data.head(1).dtypes == np.int64) | (data.head(1).dtypes == np.float64)]
cos_sim = cosine_similarity(data.T)
ShowGRAHeatMap(pd.DataFrame(cos_sim, columns=data.columns))
pd.plotting.scatter_matrix(data,figsize=(20,20),diagonal='kde')
plt.show()
def sort(data:pd.DataFrame):
data = data[["2 tries", "No."]].copy()
print(data.sort_values("2 tries"))
print(data.sort_values("2 tries", ascending=False))
print(data.sort_values(["2 tries", "No."], ascending=False))
print(data.sort_values(["2 tries", "No."], ascending=False, na_position="first"))
def countvalue(data:pd.DataFrame):
data = data[["1 try", "2 tries" ,"k++"]].copy()
print(data.value_counts())
print(data["1 try"].value_counts(ascending=False))
print(data["1 try"].value_counts(normalize=True))
print(data["1 try"].value_counts(bins=5))
print(data["1 try"].value_counts(sort=False))
print(data["2 tries"].value_counts(dropna=False))
def scatter_plot(data:pd.DataFrame):
plt.rcParams["font.size"] = 14
colors = np.array(["red", "gray", "orange", "pink", "blue", "green"])
data.plot.scatter(x='tsne1', y='tsne2', marker='x', s=10, color=colors[data["k++"]], alpha=0.4)
# s: 大小
# marker: 点样式
# alpha: 点透明
plt.show()
# 这个散点图也是pandas内置的,但是调参真的好麻烦
pd.plotting.scatter_matrix(data, figsize=(20, 20), diagonal='kde')
plt.show()
def pie_plot(data:pd.DataFrame):
a = data["k++"].value_counts(normalize=True)
a.plot.pie(labels=data.index, colors=["red", "gray", "orange", "pink", "blue", "green"], autopct='%.2f', fontsize=10, figsize=(6, 6))
plt.show()
data["k++"].value_counts(normalize=True).plot(kind='pie', wedgeprops={'alpha': 0.5})
plt.show()
def col_plot(data:pd.DataFrame):
a = data["k++"].value_counts(normalize=True)
a.plot.bar(a.index, a.values, color=["red", "gray", "orange", "pink", "blue", "green"][3], fontsize=10, figsize=(6, 6))
plt.show()
if __name__ == '__main__':
data = get_data("wordle.csv", "utf-8-sig")
参考
为了出一期能看的博文,看过的文章太多了,主要参考的包括这些(互联网真伟大!!!)
数据读取:
https://blog.csdn.net/wld914674505/article/details/81431128
数据遍历:
https://zhuanlan.zhihu.com/p/97269320
https://zhuanlan.zhihu.com/p/29362983
https://zhuanlan.zhihu.com/p/506662488
计算:
https://blog.csdn.net/weixin_45903952/article/details/106151470
高阶函数:
https://zhuanlan.zhihu.com/p/100064394
不连续切片:
https://stackoverflow.com/questions/41256648/select-multiple-ranges-of-columns-in-pandas-dataframe
空值处理:
https://blog.csdn.net/happy_wealthy/article/details/108576944
https://blog.csdn.net/qq_18351157/article/details/104993254
添加数据:
https://www.zhihu.com/question/503434324/answer/2716876667
数据拼接:
https://blog.csdn.net/lxb_wyf/article/details/114120865
https://blog.csdn.net/sc179/article/details/108169436
数据库操作:
https://zhuanlan.zhihu.com/p/101284491
https://zhuanlan.zhihu.com/p/405694685
https://zhuanlan.zhihu.com/p/106675563
相关系数:
https://blog.csdn.net/zz_dd_yy/article/details/51926305
value_counts:
https://blog.csdn.net/Late_whale/article/details/103317396