0、前言
| 参数名和默认值 |
|---|
| spark.default.parallelism=Default number of partitions in RDDs |
| spark.executor.cores=1 in YARN mode 一般默认值 |
| spark.files.maxPartitionBytes=134217728(128M) |
| spark.files.openCostInBytes=4194304 (4 MiB) |
| spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version=1 不同版本算法task提交数据 |
【重点】在spark sql中有对应参数为:
spark.sql.files.maxPartitionBytes=134217728(128M) 本次重点源码分析
spark.sql.files.openCostInBytes=4194304 (4 MiB) 本次重点源码分析
spark.default.parallelism = math.max(totalCoreCount.get(), 2)
对应源码位置如下:
org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend#defaultParallelism
org.apache.spark.sql.internal.SQLConf#FILES_MAX_PARTITION_BYTES
org.apache.spark.sql.internal.SQLConf#FILES_OPEN_COST_IN_BYTES
1、 环境准备
create database bicoredata;
CREATE TABLE bicoredata.dwd_start_log_dm(
`device_id` string,
`area` string,
`uid` string,
`app_v` string,
`event_type` string,
`os_type` string,
`channel` string,
`language` string,
`brand` string,
`entry` string,
`action` string,
`error_code` string
)
comment 'dwd用户启动日志信息'
partitioned by (`dt` string)
stored as orc
tblproperties("orc.compress"="ZLIB")
location '/bicoredata/dwd_start_log_dm';
-- 解析ods日志到dwd表
insert overwrite table bicoredata.dwd_start_log_dm
partition(dt='20220721')
select get_json_object(line, '$.attr.device_id'),
get_json_object(line, '$.attr.area'),
get_json_object(line, '$.attr.uid'),
get_json_object(line, '$.attr.app_v'),
get_json_object(line, '$.attr.event_type'),
get_json_object(line, '$.attr.os_type'),
get_json_object(line, '$.attr.channel'),
get_json_object(line, '$.attr.language'),
get_json_object(line, '$.attr.brand'),
get_json_object(line, '$.app_active.json.entry'),
get_json_object(line, '$.app_active.json.action'),
get_json_object(line, '$.app_active.json.error_code')
from
(
select split(str, ' ')[7] as line
from biods.ods_start_log
where dt='20220721'
)t
2、 代码准备
package org.example.sparksql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object SparkSqlHive {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
// 动态分配参数必须 在 yarn环境下才能生效,client/cluster
val ss = SparkSession.builder().master("yarn").appName("the test of SparkSession")
.config("spark.deploy.mode","cluster")
.config("yarn.resourcemanager.hostname", "hadoop2")
// 注意只有设置为true,才是文件读取算子,否则是表读取算子。
.config("spark.sql.hive.convertMetastoreOrc", "true")
.config("spark.sql.files.maxPartitionBytes","34008864") //注意不是spark.files.maxPartitionBytes
.config("spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version","2")
.config("spark.dynamicAllocation.enabled","true")
.config("spark.shuffle.service.enabled","true")
.config("spark.driver.host","192.168.150.1")
.enableHiveSupport().getOrCreate()
ss.sql("DROP TABLE IF EXISTS temp.temp_ods_start_log");
val df = ss.sql("insert overwrite table bicoredata.dwd_start_log_dm " +
"partition(dt='20210721') " +
"select get_json_object(line, '$.attr.device_id')," +
"get_json_object(line, '$.attr.area')," +
"get_json_object(line, '$.attr.uid')," +
"get_json_object(line, '$.attr.app_v')," +
"get_json_object(line, '$.attr.event_type')," +
"get_json_object(line, '$.attr.os_type')," +
"get_json_object(line, '$.attr.channel')," +
"get_json_object(line, '$.attr.language')," +
"get_json_object(line, '$.attr.brand')," +
"get_json_object(line, '$.app_active.json.entry')," +
"get_json_object(line, '$.app_active.json.action')," +
"get_json_object(line, '$.app_active.json.error_code') " +
"from " +
"(" +
"select split(str, ' ')[7] as line " +
"from biods.ods_start_log " +
"where dt='20210721'" +
")t")
Thread.sleep(1000000)
ss.stop()
}
}
输入:
hdfs中该日期分区存有2个文件,大小分别为245M和94M

输出:
最终结果分区中,有6个文件。

可见缩小spark.sql.files.maxPartitionBytes值,增大了读取task数量。
3 、源码分析
3.1 、物理执行计划如下
Execute InsertIntoHadoopFsRelationCommand hdfs://hadoop1:9000/bicoredata/dwd_start_log_dm, Map(dt -> 20210721), false, [dt#55], ORC, Map(orc.compress -> ZLIB, serialization.format -> 1, partitionOverwriteMode -> dynamic), Overwrite, CatalogTable(
Database: bicoredata
Table: dwd_start_log_dm
Owner: root
Created Time: Sun Dec 11 17:47:33 CST 2022
Last Access: UNKNOWN
Created By: Spark 2.2 or prior
Type: MANAGED
Provider: hive
Comment: dwd????????
Table Properties: [orc.compress=ZLIB, transient_lastDdlTime=1670752053]
Location: hdfs://hadoop1:9000/bicoredata/dwd_start_log_dm
Serde Library: org.apache.hadoop.hive.ql.io.orc.OrcSerde
InputFormat: org.apache.hadoop.hive.ql.io.orc.OrcInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat
Storage Properties: [serialization.format=1]
Partition Provider: Catalog
Partition Columns: [`dt`]
Schema: root
|-- device_id: string (nullable = true)
|-- area: string (nullable = true)
|-- uid: string (nullable = true)
|-- app_v: string (nullable = true)
|-- event_type: string (nullable = true)
|-- os_type: string (nullable = true)
|-- channel: string (nullable = true)
|-- language: string (nullable = true)
|-- brand: string (nullable = true)
|-- entry: string (nullable = true)
|-- action: string (nullable = true)
|-- error_code: string (nullable = true)
|-- dt: string (nullable = true)
), org.apache.spark.sql.execution.datasources.CatalogFileIndex@df5f9368, [device_id, area, uid, app_v, event_type, os_type, channel, language, brand, entry, action, error_code, dt]
+- Project [ansi_cast(get_json_object(split(str#1, , -1)[7], $.attr.device_id) as string) AS device_id#43, ansi_cast(get_json_object(split(str#1, , -1)[7], $.attr.area) as string) AS area#44, ansi_cast(get_json_object(split(str#1, , -1)[7], $.attr.uid) as string) AS uid#45, ansi_cast(get_json_object(split(str#1, , -1)[7], $.attr.app_v) as string) AS app_v#46, ansi_cast(get_json_object(split(str#1, , -1)[7], $.attr.event_type) as string) AS event_type#47, ansi_cast(get_json_object(split(str#1, , -1)[7], $.attr.os_type) as string) AS os_type#48, ansi_cast(get_json_object(split(str#1, , -1)[7], $.attr.channel) as string) AS channel#49, ansi_cast(get_json_object(split(str#1, , -1)[7], $.attr.language) as string) AS language#50, ansi_cast(get_json_object(split(str#1, , -1)[7], $.attr.brand) as string) AS brand#51, ansi_cast(get_json_object(split(str#1, , -1)[7], $.app_active.json.entry) as string) AS entry#52, ansi_cast(get_json_object(split(str#1, , -1)[7], $.app_active.json.action) as string) AS action#53, ansi_cast(get_json_object(split(str#1, , -1)[7], $.app_active.json.error_code) as string) AS error_code#54, 20210721 AS dt#55]
+- *(1) ColumnarToRow
+- FileScan orc biods.ods_start_log[str#1,dt#2] Batched: true, DataFilters: [], Format: ORC, Location: InMemoryFileIndex[hdfs://hadoop1:9000/bi/ods/ods_start_log/dt=20210721], PartitionFilters: [isnotnull(dt#2), (dt#2 = 20210721)], PushedFilters: [], ReadSchema: struct<str:string>
如上所示,本质上分三部分:
(1)读取表
FileScan orc biods.ods_start_log
(2)转换
Project [ansi_cast(get_json_object(split(str#1, , -1)[7]
(3)写入目标表
Execute InsertIntoHadoopFsRelationCommand
3.2 、FileScan和InsertIntoHadoopFsRelationCommand 算子
从InsertIntoHadoopFsRelationCommand 开始源码分析如下:
org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand#run
org.apache.spark.sql.execution.datasources.FileFormatWriter$#write
org.apache.spark.sql.execution.FileSourceScanExec#inputRDD
FileSourceScanExec#createNonBucketedReadRDD
org.apache.spark.sql.execution.FileSourceScanExec#createNonBucketedReadRDD
首次出现3个相关参数
private def createNonBucketedReadRDD(
readFile: (PartitionedFile) => Iterator[InternalRow],
selectedPartitions: Array[PartitionDirectory],
fsRelation: HadoopFsRelation): RDD[InternalRow] = {
// 对应spark.sql.files.openCostInBytes 参数
val openCostInBytes = fsRelation.sparkSession.sessionState.conf.filesOpenCostInBytes
// 基于3个参数计算出来
val maxSplitBytes =
FilePartition.maxSplitBytes(fsRelation.sparkSession, selectedPartitions)
logInfo(s"Planning scan with bin packing, max size: $maxSplitBytes bytes, " +
s"open cost is considered as scanning $openCostInBytes bytes.")
// 逻辑分割orc文件,返回分区的文件对象PartitionedFile
val splitFiles = selectedPartitions.flatMap { partition =>
partition.files.flatMap { file =>
// getPath() is very expensive so we only want to call it once in this block:
val filePath = file.getPath
// orc文件是可以分割的,对应org.apache.spark.sql.hive.orc.OrcFileFormat#isSplitable函数,返回true
val isSplitable = relation.fileFormat.isSplitable(
relation.sparkSession, relation.options, filePath)
PartitionedFileUtil.splitFiles(
sparkSession = relation.sparkSession,
file = file,
filePath = filePath,
isSplitable = isSplitable,
maxSplitBytes = maxSplitBytes,
partitionValues = partition.values
)
}
}.sortBy(_.length)(implicitly[Ordering[Long]].reverse)
// 基于分区文件对象,最大分割尺寸,返回文件分区FilePartition对象(逻辑层面)
val partitions =
FilePartition.getFilePartitions(relation.sparkSession, splitFiles, maxSplitBytes)
// 返回rdd
new FileScanRDD(fsRelation.sparkSession, readFile, partitions)
}
FilePartition和PartitionedFile区别
(1)FilePartition对象:会被单个任务读取的PartitionedFile集合
对应源码在 org.apache.spark.sql.execution.datasources.FilePartition
--》特点是,一个FilePartition对应1个task
(2)PartitionedFile对象:用于读取的单个文件的部分,包含文件路径,开始偏移量,读取长度偏移量
-->特点是,一个PartitionedFile对应1个文件的部分,有对应的开始偏移量和读取偏移量
FilePartition#maxSplitBytes
org.apache.spark.sql.execution.datasources.FilePartition#maxSplitBytes
综合以上3个关键参数,计算出最大分割大小。
def maxSplitBytes(
sparkSession: SparkSession,
selectedPartitions: Seq[PartitionDirectory]): Long = {
// 对应 spark.sql.files.maxPartitionBytes 参数,默认128M
val defaultMaxSplitBytes = sparkSession.sessionState.conf.filesMaxPartitionBytes
// 对应spark.sql.files.openCostInBytes 参数 ,默认4M
val openCostInBytes = sparkSession.sessionState.conf.filesOpenCostInBytes
// 对应 spark.default.parallelism参数,默认应该会取到2(yarn cluster集群默认环境下测试结果)
val defaultParallelism = sparkSession.sparkContext.defaultParallelism
val totalBytes = selectedPartitions.flatMap(_.files.map(_.getLen + openCostInBytes)).sum
val bytesPerCore = totalBytes / defaultParallelism
Math.min(defaultMaxSplitBytes, Math.max(openCostInBytes, bytesPerCore))
}
org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend#defaultParallelism
override def defaultParallelism(): Int = {
conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2))
}
PartitionedFileUtil#splitFiles
org.apache.spark.sql.execution.PartitionedFileUtil#splitFiles
def splitFiles(
sparkSession: SparkSession,
file: FileStatus,
filePath: Path,
isSplitable: Boolean,
maxSplitBytes: Long,
partitionValues: InternalRow): Seq[PartitionedFile] = {
if (isSplitable) {
(0L until file.getLen by maxSplitBytes).map { offset =>
val remaining = file.getLen - offset
val size = if (remaining > maxSplitBytes) maxSplitBytes else remaining
val hosts = getBlockHosts(getBlockLocations(file), offset, size)
// 基于偏移量,size构造分区file对象
PartitionedFile(partitionValues, filePath.toUri.toString, offset, size, hosts)
}
} else {
Seq(getPartitionedFile(file, filePath, partitionValues))
}
}
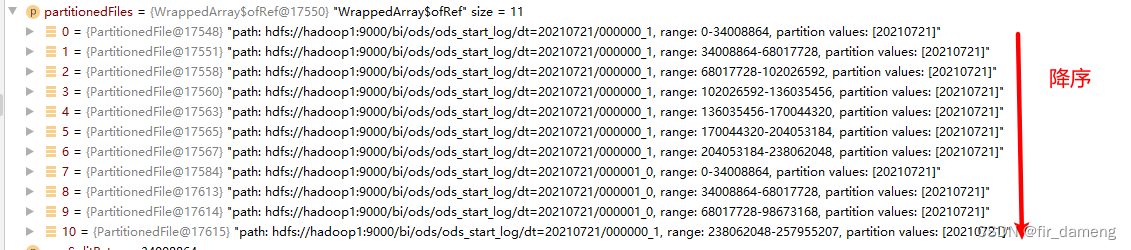
逻辑分割结果,11个文件,降序排列:
FilePartition#getFilePartitions
org.apache.spark.sql.execution.datasources.FilePartition#getFilePartitions
def getFilePartitions(
sparkSession: SparkSession,
partitionedFiles: Seq[PartitionedFile],
maxSplitBytes: Long): Seq[FilePartition] = {
val partitions = new ArrayBuffer[FilePartition]
val currentFiles = new ArrayBuffer[PartitionedFile]
var currentSize = 0L
/** Close the current partition and move to the next. */
def closePartition(): Unit = {
if (currentFiles.nonEmpty) {
// 将PartitionedFile文件数组封装成1个FilePartition对象
val newPartition = FilePartition(partitions.size, currentFiles.toArray)
partitions += newPartition
}
currentFiles.clear()
currentSize = 0
}
val openCostInBytes = sparkSession.sessionState.conf.filesOpenCostInBytes
// Assign files to partitions using "Next Fit Decreasing"
partitionedFiles.foreach { file =>
if (currentSize + file.length > maxSplitBytes) {
closePartition()
}
// Add the given file to the current partition.
currentSize += file.length + openCostInBytes
currentFiles += file
}
// 处理最后1个分区文件
closePartition()
partitions
}
总体调用流程
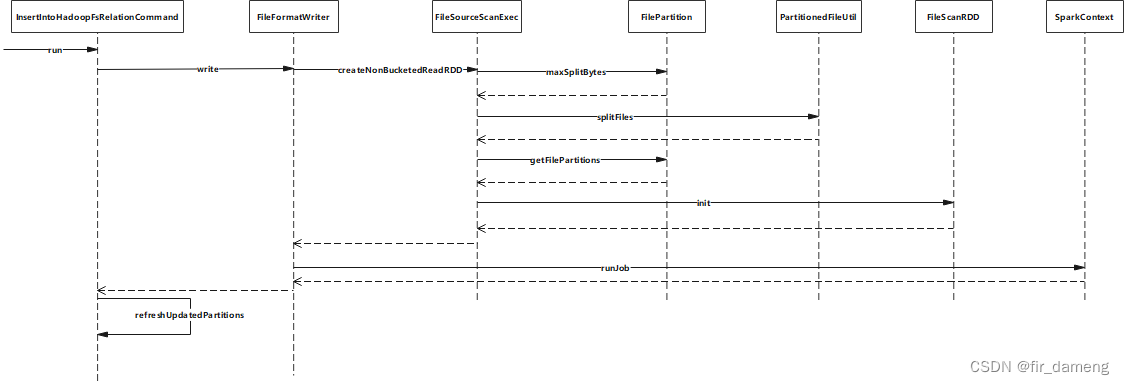
InsertIntoHadoopFsRelationCommand为物理逻辑计划的最后1个算子,其run方法,包含写入数据和更新元数据过程;其中写入数据又包含生成FileScanRDD(11个分区)和提交job过程。
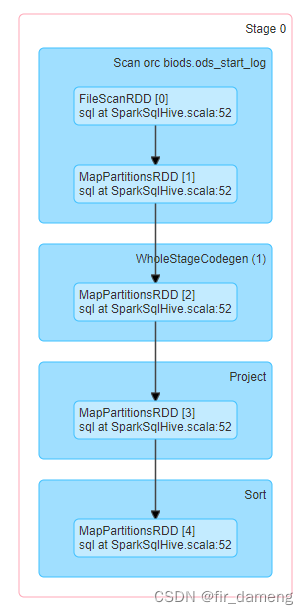
stage0的初始rdd,即为FileScanRDD。
由于FileScanRDD包含11个FilePartition,所以 最终生成11个task
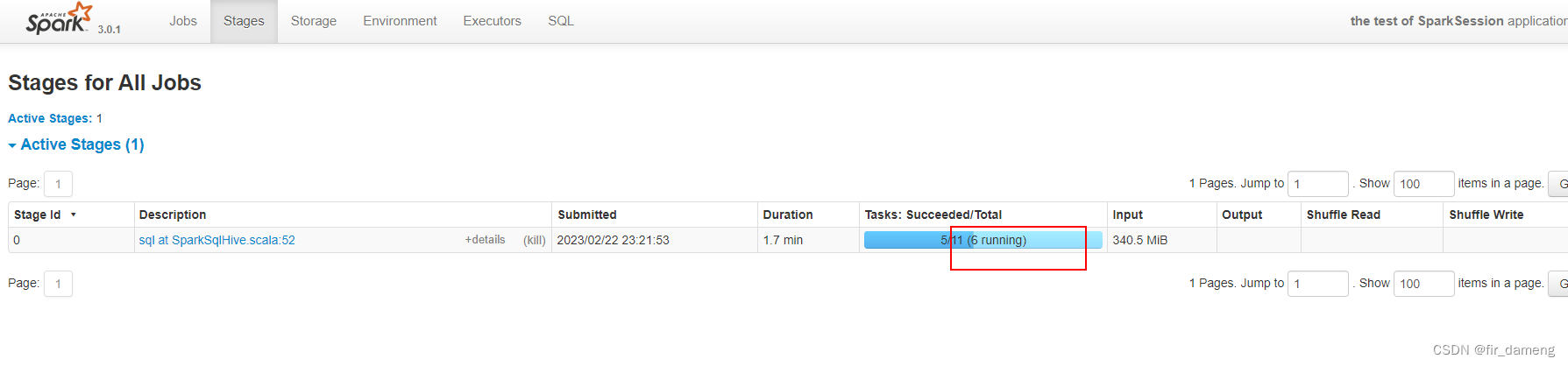
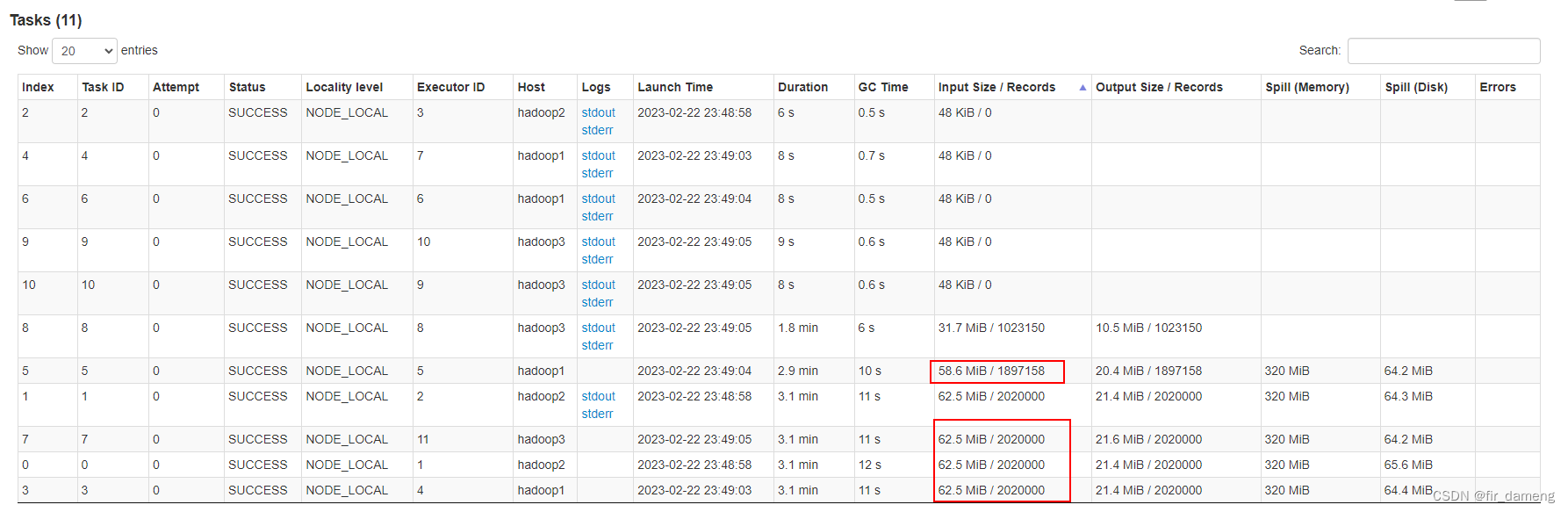
4、疑问
4.1、预期11 个task 大小均匀分布 32M左右,但为什么实际存在一些task空跑,其他task输入大小为62M多?
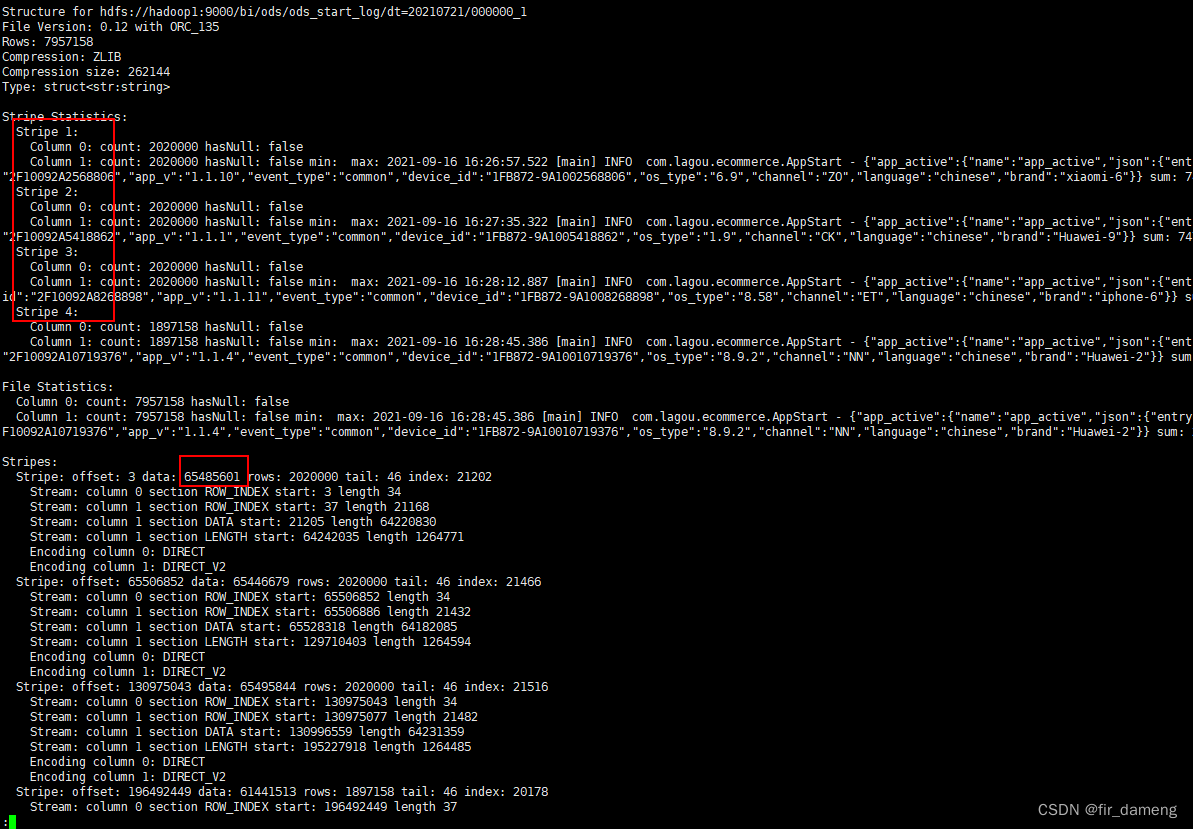
经了解发现,以hdfs://hadoop1:9000/bi/ods/ods_start_log/dt=20210721/000000_1orc文件为例,其由4个stripe组成,大小刚好为62.5M,62.5M,62.5M,58.6M,且不可分割,这就与task中大小和数量不谋而合。
orc原理参考: https://www.jianshu.com/p/0ba4f5c3f113
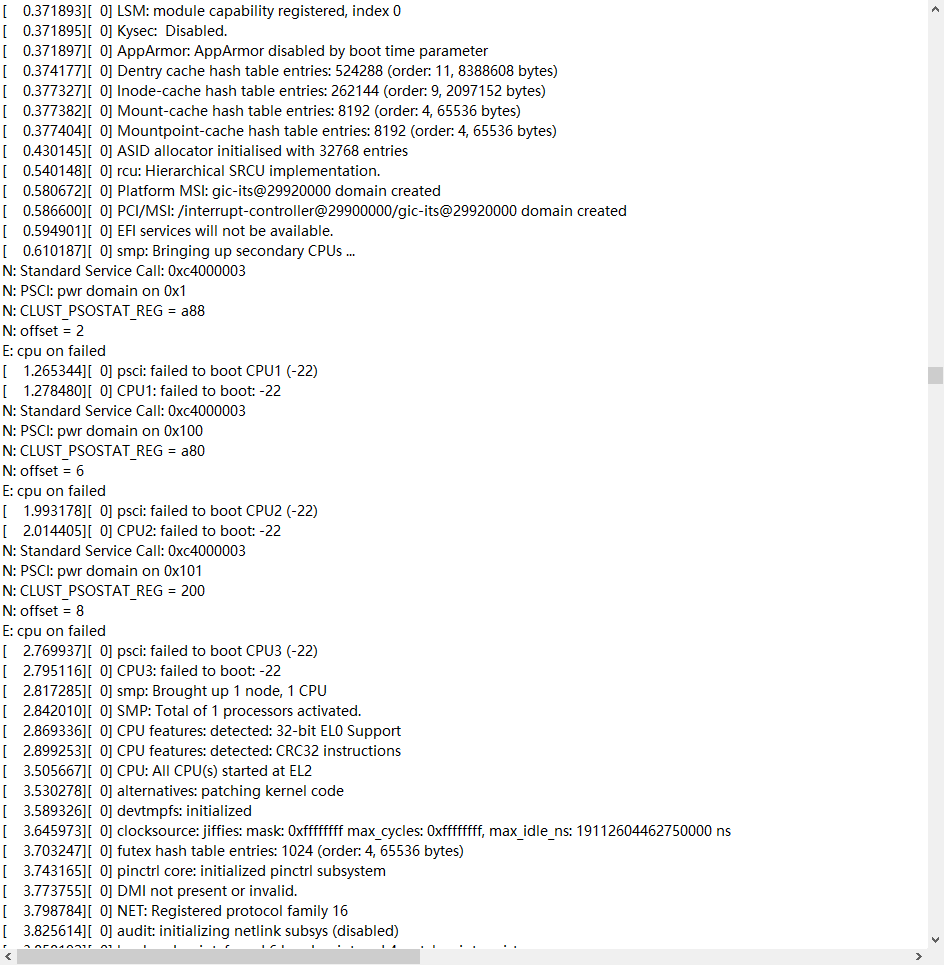
查看orc文件的stripe个数等信息
hive --orcfiledump hdfs://hadoop1:9000/bi/ods/ods_start_log/dt=20210721/000001_0 | less
结果如下
4.2、测试sql中不涉及join,group by等shuffle操作,为什么会溢出到内存,甚至磁盘?
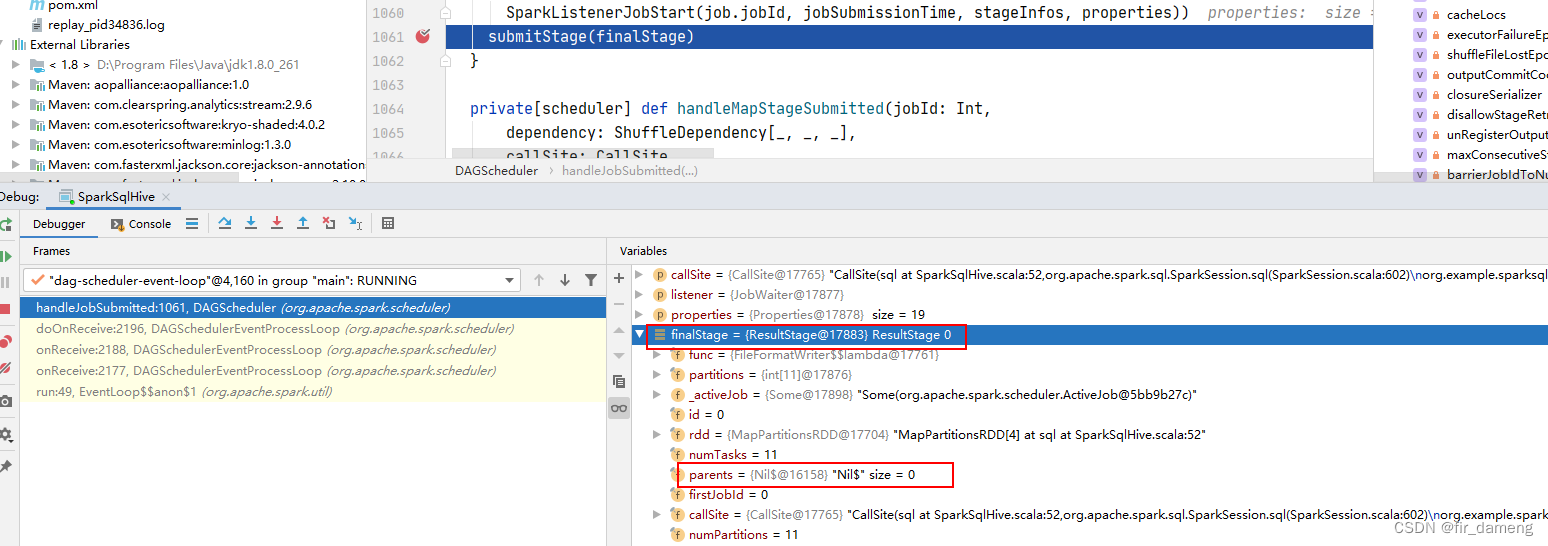
下面是exectuor中,spark task运行的线程dump中,可以发现有堆内存溢出的操作。
猜测:可能有shuffle或者排序,因为如果是纯map task任务,如果excutor内存不足,会直接报oom错误。
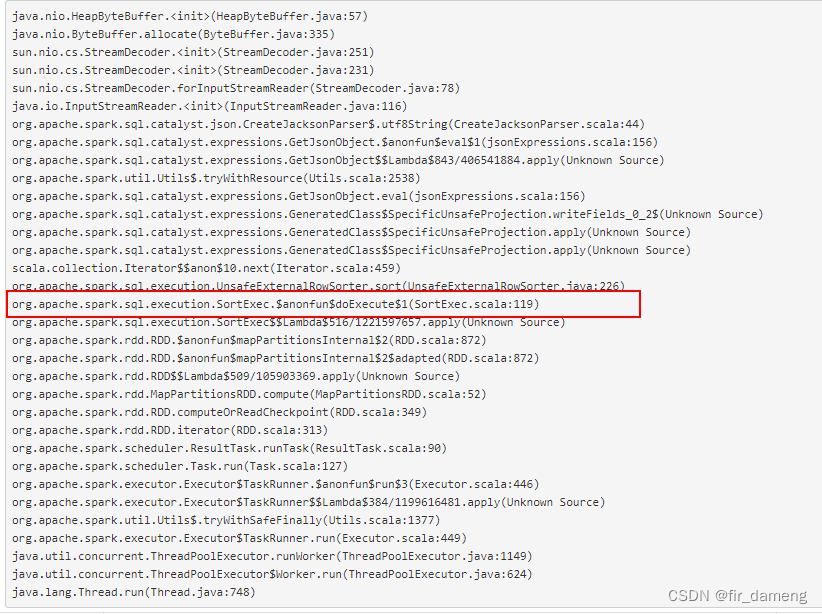
org.apache.spark.sql.execution.SortExec#doExecute
//task执行过程中,会到这一步。
protected override def doExecute(): RDD[InternalRow] = {
val peakMemory = longMetric("peakMemory")
val spillSize = longMetric("spillSize")
val sortTime = longMetric("sortTime")
child.execute().mapPartitionsInternal { iter =>
val sorter = createSorter()
val metrics = TaskContext.get().taskMetrics()
// Remember spill data size of this task before execute this operator so that we can
// figure out how many bytes we spilled for this operator.
val spillSizeBefore = metrics.memoryBytesSpilled
// 说明sort过程会 溢出数据到内存
val sortedIterator = sorter.sort(iter.asInstanceOf[Iterator[UnsafeRow]])
sortTime += NANOSECONDS.toMillis(sorter.getSortTimeNanos)
peakMemory += sorter.getPeakMemoryUsage
spillSize += metrics.memoryBytesSpilled - spillSizeBefore
metrics.incPeakExecutionMemory(sorter.getPeakMemoryUsage)
sortedIterator
}
sortExec工作原理 : https://zhuanlan.zhihu.com/p/582664919
当没有足够的内存来存储指针阵列列表或分配的内存页,或者UnsafeInMemorySorter的行数大于或等于溢出阈值numElementsForSpillThreshold时,内存中的数据将被分割到磁盘。
为什么会有sortExec算子?
在 InsertIntoHadoopFsRelationCommand 命令,提交job之前。
org/apache/spark/sql/execution/datasources/FileFormatWriter.scala:170
// 查看requiredChildOrderings针对排序有特殊需求的添加SortExec节点
val rdd = if (orderingMatched) {
empty2NullPlan.execute()
} else {
// SPARK-21165: the `requiredOrdering` is based on the attributes from analyzed plan, and
// the physical plan may have different attribute ids due to optimizer removing some
// aliases. Here we bind the expression ahead to avoid potential attribute ids mismatch.
val orderingExpr = bindReferences(
requiredOrdering.map(SortOrder(_, Ascending)), outputSpec.outputColumns)
// 这里绑定上了sortexec 算子,返回的是rdd,并非已经开始计算了
SortExec(
orderingExpr,
global = false,
child = empty2NullPlan).execute()
}
val rddWithNonEmptyPartitions = if (rdd.partitions.length == 0) {
sparkSession.sparkContext.parallelize(Array.empty[InternalRow], 1)
} else {
rdd
}
val jobIdInstant = new Date().getTime
val ret = new Array[WriteTaskResult](rddWithNonEmptyPartitions.partitions.length)
// 然后这里才提交了job
sparkSession.sparkContext.runJob(
rddWithNonEmptyPartitions,
(taskContext: TaskContext, iter: Iterator[InternalRow]) => {
executeTask(
description = description,
jobIdInstant = jobIdInstant,
sparkStageId = taskContext.stageId(),
sparkPartitionId = taskContext.partitionId(),
sparkAttemptNumber = taskContext.taskAttemptId().toInt & Integer.MAX_VALUE,
committer,
iterator = iter)
},
rddWithNonEmptyPartitions.partitions.indices,
(index, res: WriteTaskResult) => {
committer.onTaskCommit(res.commitMsg)
ret(index) = res
})
参考:https://developer.aliyun.com/article/679260
4.3、resulttask
不涉及shuffle的sql 最终生成的只有resultTask, 当然也只有resultstage。
org.apache.spark.rdd.RDDCheckpointData$
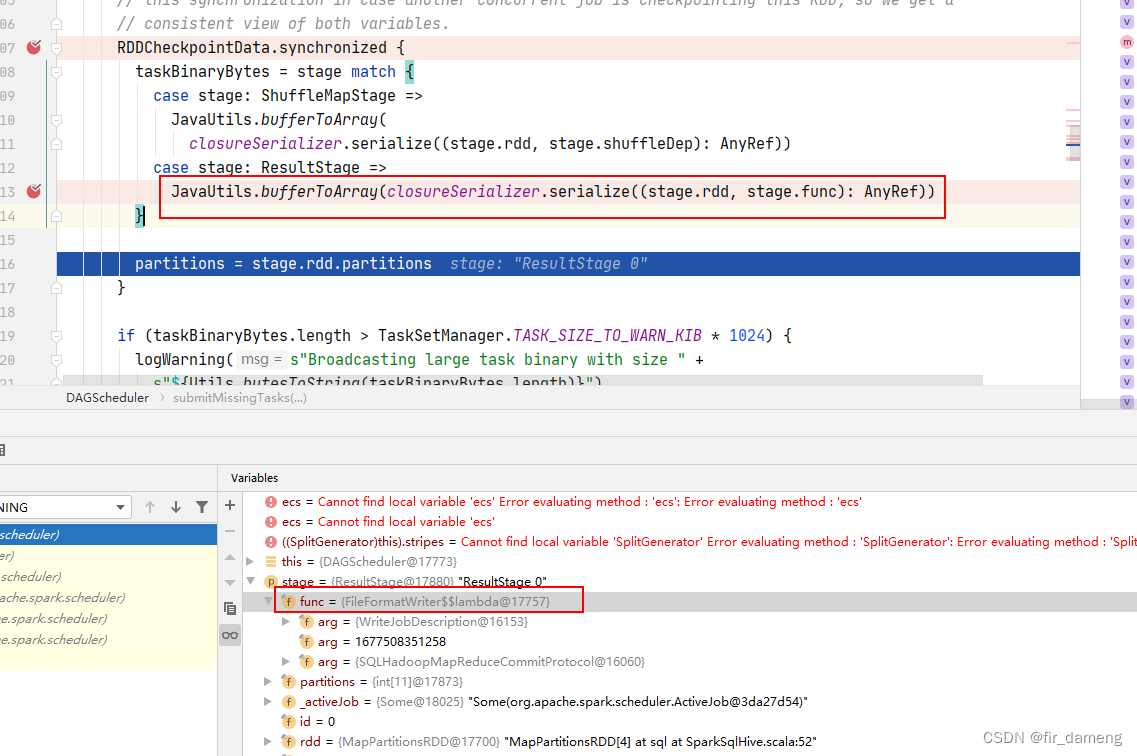
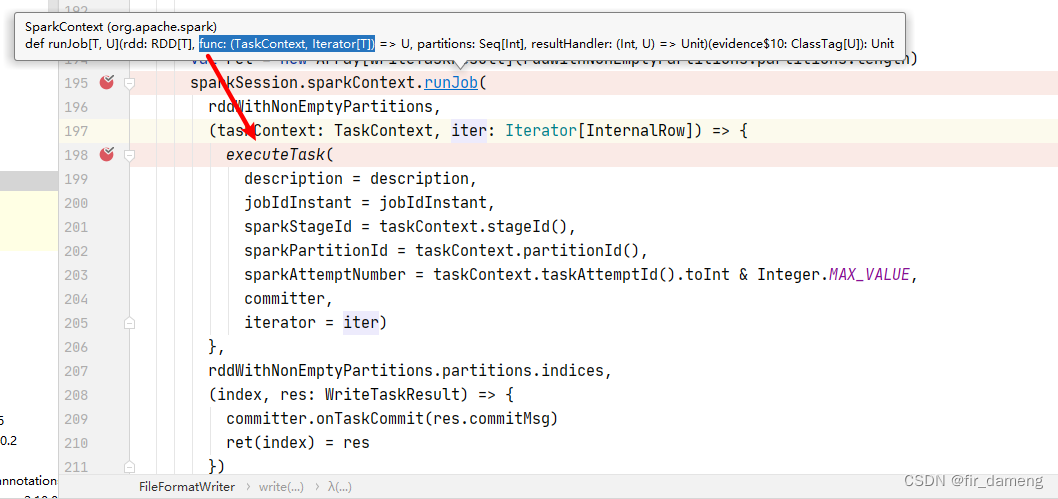
executetask即 传入 rdd上执行的func
org.apache.spark.scheduler.ResultTask#runTask
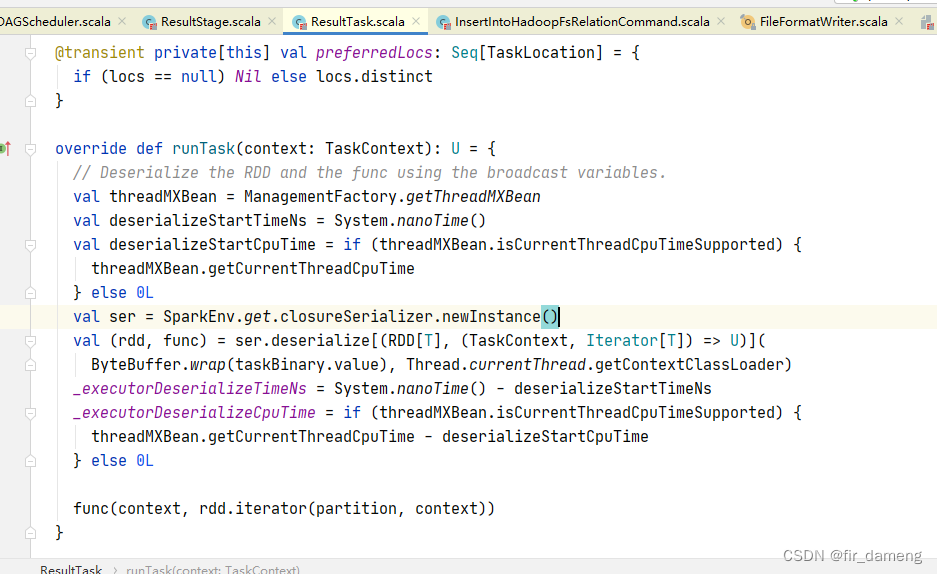
org.apache.spark.sql.execution.datasources.FileFormatWriter#executeTask
里面包含提交task的过程
参考:https://blog.csdn.net/weixin_42588332/article/details/122440644#:~:text=%E5%AF%B9%E4%BA%8E%20Aggregate%20%E6%93%8D%E4%BD%9C%EF%BC%8CSpark%20UI%20%E4%B9%9F%E8%AE%B0%E5%BD%95%E7%9D%80%E7%A3%81%E7%9B%98%E6%BA%A2%E5%87%BA%E4%B8%8E%E5%B3%B0%E5%80%BC%E6%B6%88%E8%80%97%EF%BC%8C%E5%8D%B3%20Spill%20size%20%E5%92%8C,%E7%9A%84%E5%B3%B0%E5%80%BC%E6%B6%88%E8%80%97%EF%BC%8C%E8%AF%81%E6%98%8E%E5%BD%93%E5%89%8D%203GB%20%E7%9A%84%20Executor%20Memory%20%E8%AE%BE%E7%BD%AE%EF%BC%8C%E5%AF%B9%E4%BA%8E%20Aggregate%20%E8%AE%A1%E7%AE%97%E6%9D%A5%E8%AF%B4%E6%98%AF%E7%BB%B0%E7%BB%B0%E6%9C%89%E4%BD%99%E7%9A%84%E3%80%82
https://zhuanlan.zhihu.com/p/431015932
https://blog.csdn.net/chongqueluo2709/article/details/101006130