ZAB是什么
ZAB(Zookeeper Atomic Broadcast):Zookeeper原子广播
ZAB是为了保证Zookeeper数据一致性而产生的算法(指的是Zookeeper集群模式)。它不仅能解决正常情况下的数据一致性问题,还可以保证主节点发生宕机后的数据一致性问题。
Zookeeper集群模式
Zookeeper集群模式为"主从复制"模型,即有一个主节点,其他的都为从节点。主、从节点在数据读写场景下满足以下三条规则:
1. 所有的数据更新操作都只能由主节点完成;
2. 主节点更新完数据后,将副本发送给从节点进行更新;
3. 任何从节点都可进行数据的读操作。
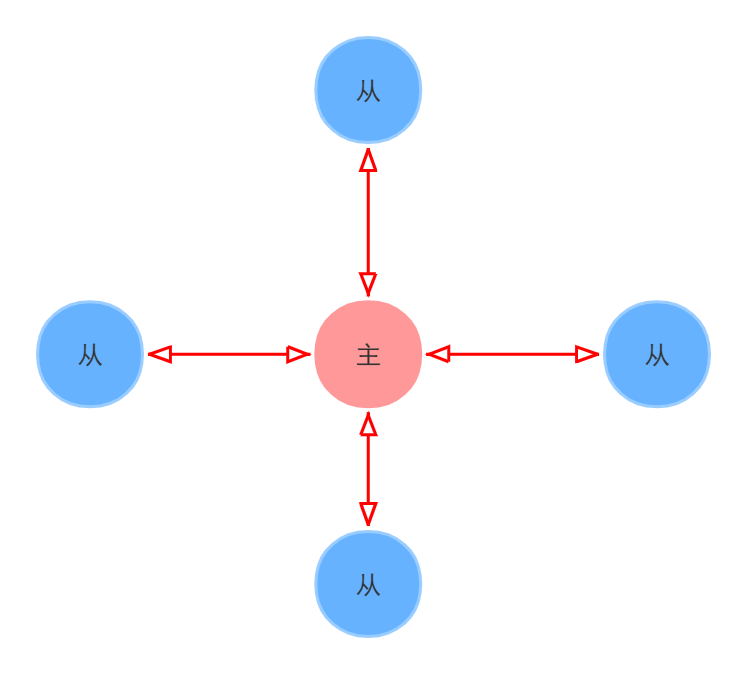
图1 Zookeeper主从复制模型图
由图1可得,Zookeeper有两种节点。
1. 主节点:也称Leader
2. 从节点:也称Follower
Zookeeper启动时选取Leader
讲选举前先讲一下Zookeeper的数据存储结构,对理解下文有前置知识印象。
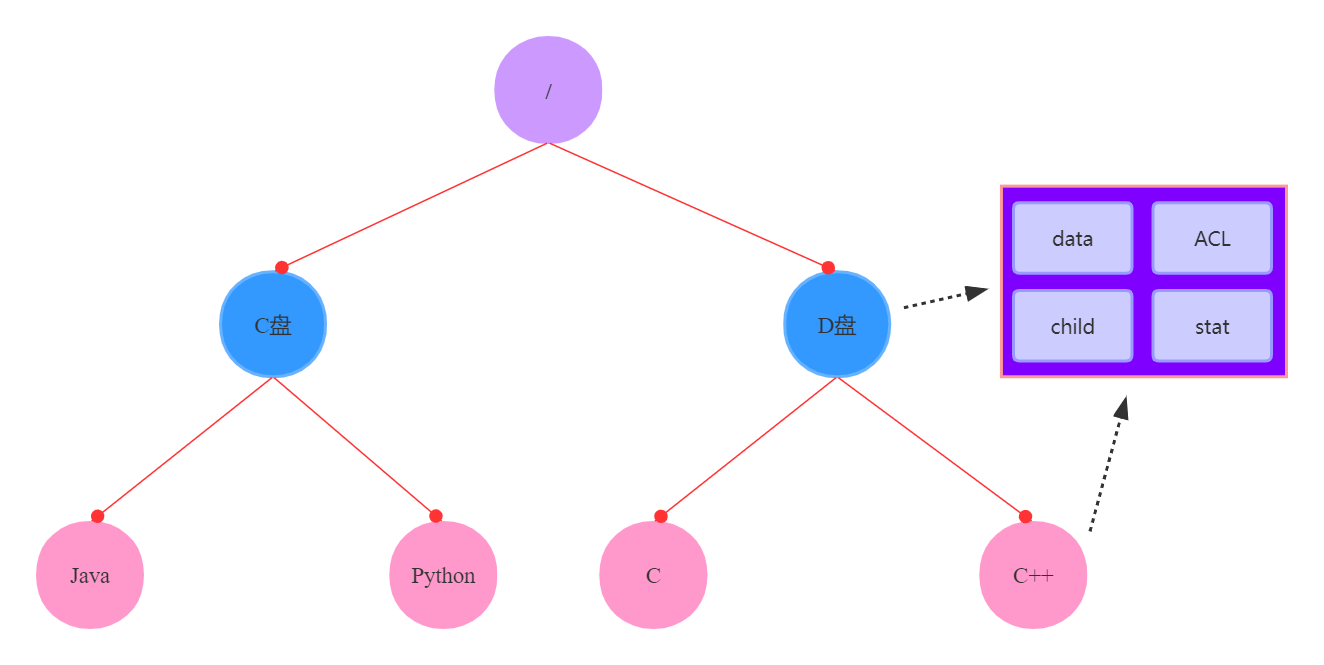
图2 Zookeeper数据存储结构
由图2可得,Zookeeper的数据存储结构是一棵树,更准确地说:底层使用文件目录格式对数据进行存储,同时Zookeeper将这种存储数据的节点称为Znode。
Znode包含图中所指的四个部分:
1. data:存储数据
2. child:存储所有的子节点引用
3. ACL:存储访问权限(例如哪些IP可以访问该节点)
4. stat:存储元数据(SID、ZXID【epoch+counter】等)
SID、ZXID在选举Leader中起决定性作用,因此我详细解释一下它们是什么!
SID:Zookeeper节点的标识符(节点指的是服务器,不是上面的Znode),相当于数据库表的唯一ID;
ZXID:最新事务标识符,值越大说明数据越新。它由两部分组成:
epoch:指当前leader为第 ${epoch} 任
counter:每交互一条proposal,counter值就会+1(proposal可以理解成更新操作)
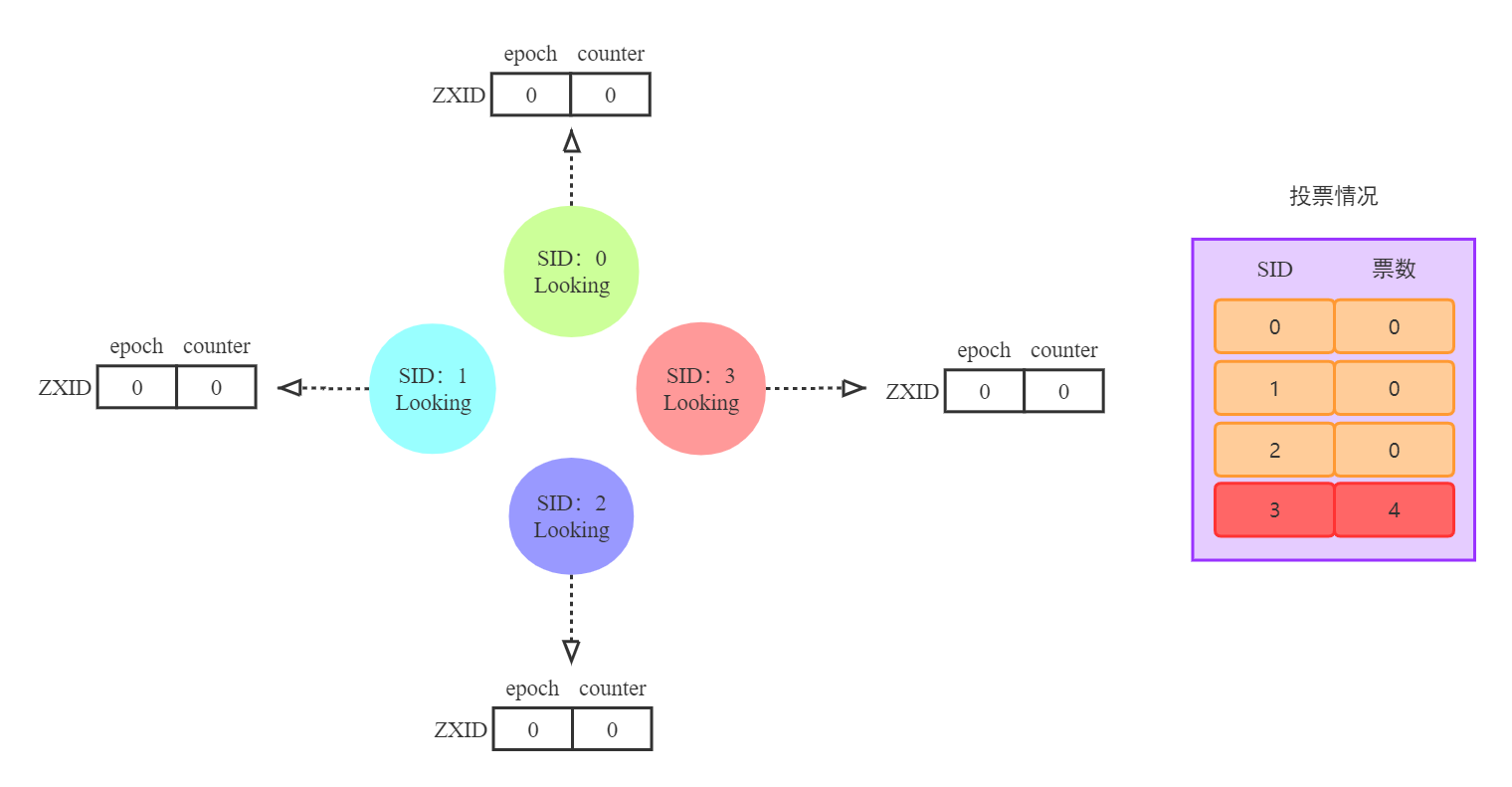
图3 初始的Zookeeper节点
由图3可得,初始Zookeeper集群有3个服务节点,选举Leader过程如下:
(Leader选举优先级:epoch>counter>SID)
1. 节点与集群中的各个节点进行拉票操作(此时节点处于Looking状态)
2. 投票以SID值大小为标准,每个节点都会投票给SID最大的那个
3. 当服务节点获得的票数超过集群节点数一半时,Leader产生(Leader节点状态变为Leading、Follower节点状态变为Following)
自此,Leader的选举过程就结束了,后面新加入的节点也只能作为Follower节点,不会再次进行Leader选举,除非Leader出现意外!
Zookeeper故障时选举Leader
上一章了解了启动时Leader的选举过程。那么,当集群中Leader出现问题时,又该如何选举新的Leader呢?
讲选举新的Leader之前,什么时候触发选举?
1. 心跳检测:Leader会周期性的给每个Follower发送心跳机制。同时,Follower在收到Leader心跳检测信息时,会给予Leader一个回复。如果Leader此时收到的恢复少于集群节点的一半,此时则会触发新的Leader选举(为什么是少于一半就会触发?因为成为Leader必须满足赞成票为集群节点的一半以上。少于一半有理由怀疑那些不回应的节点是不是重新拉帮派,然后选举了一个新的Leader)。
2. proposal检测:客户端发出的数据更新操作都会给到Leader去执行,Leader更新数据且写入本地日志后,会发送proposal给Follower(其实就是数据副本,叫Follower节点也更新数据),Follower收到后,会发送ACK给到Leader,表示已经更新副本数据。Leader节点收到ACK报文超过集群节点一半时,会通知Follower将proposal状态改为commit状态;如果收到ACK报文少于集群节点一半,会触发新的Leader选举。
图4为正常情况下的proposal阶段
图5为ACK回复报文少于集群节点一半的proposal阶段
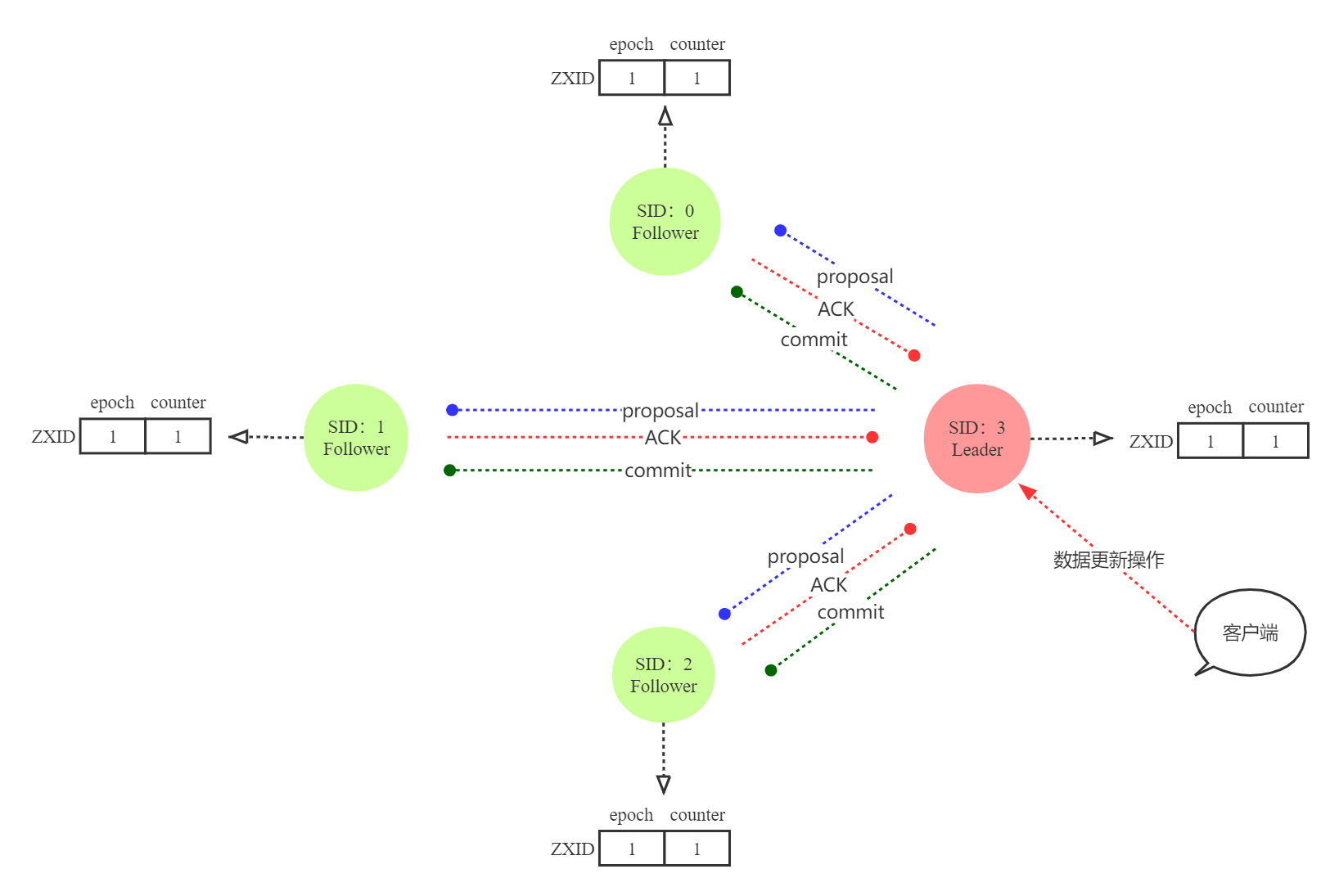
图4 正常的集群proposal阶段
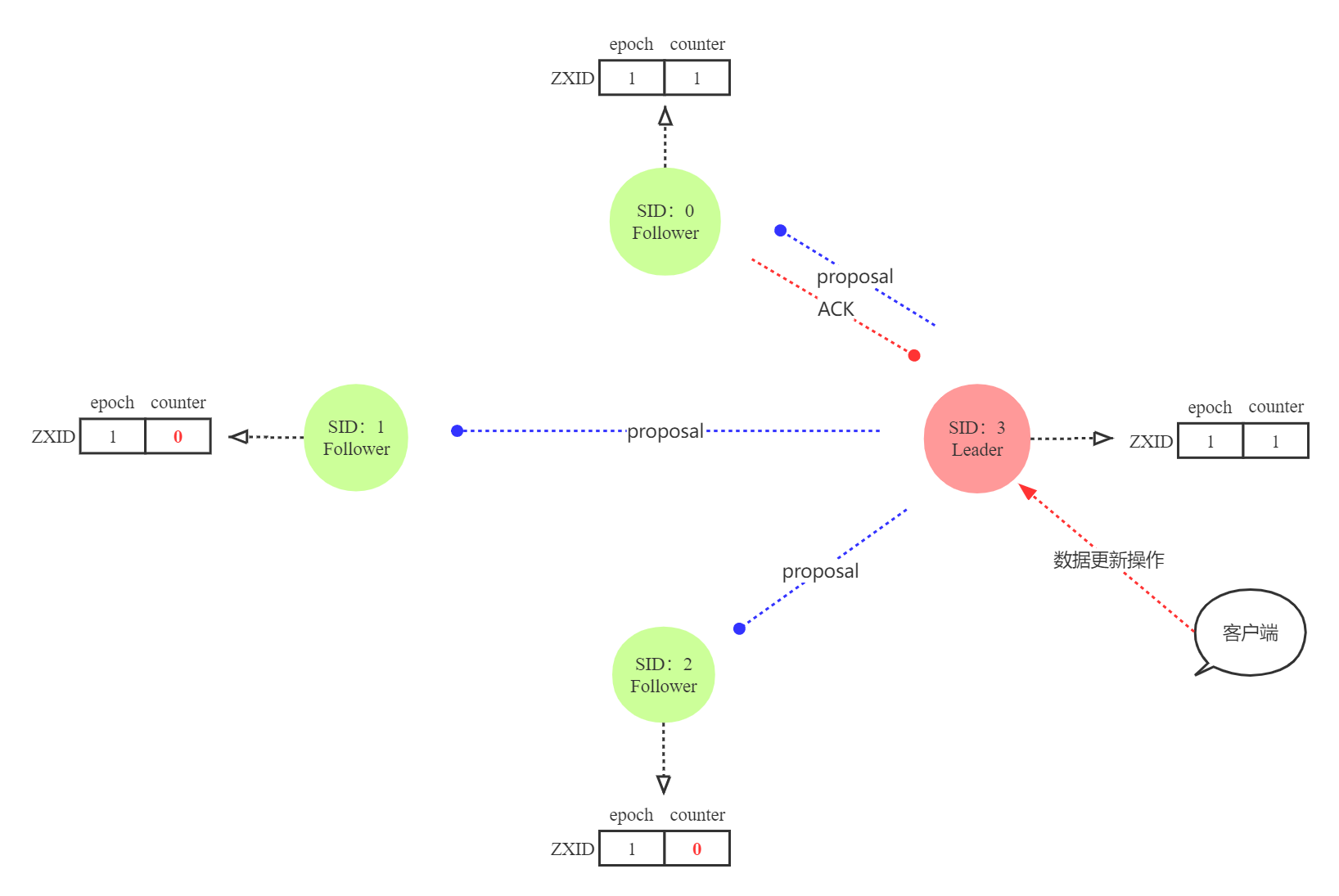
图5 非正常ACK情况下的集群proposal阶段
了解了何时触发新的Leader选举之后,接下来就是如何选举新的Leader过程。
(Leader选举优先级:epoch>counter>SID)
1. 集群中每个节点的epoch都是相同的,因此比较counter值,发现SID-0最大,所以SID当选新的Leader,新Leader产生后,会将epoch+1,然后通知每个Follower也进行epoch更新(选举/发现阶段)
2. 此时存在未提交的proposal,SID-0解决前任Leader遗留下来的proposal工作(数据同步阶段)
3. 当收到正常的ACK报文少于集群节点数一半时,继续1、2阶段;反之Leader则进入监听客户端更新操作(广播阶段)。
ZAB三阶段解决故障Leader选举:选举/发现、同步、广播
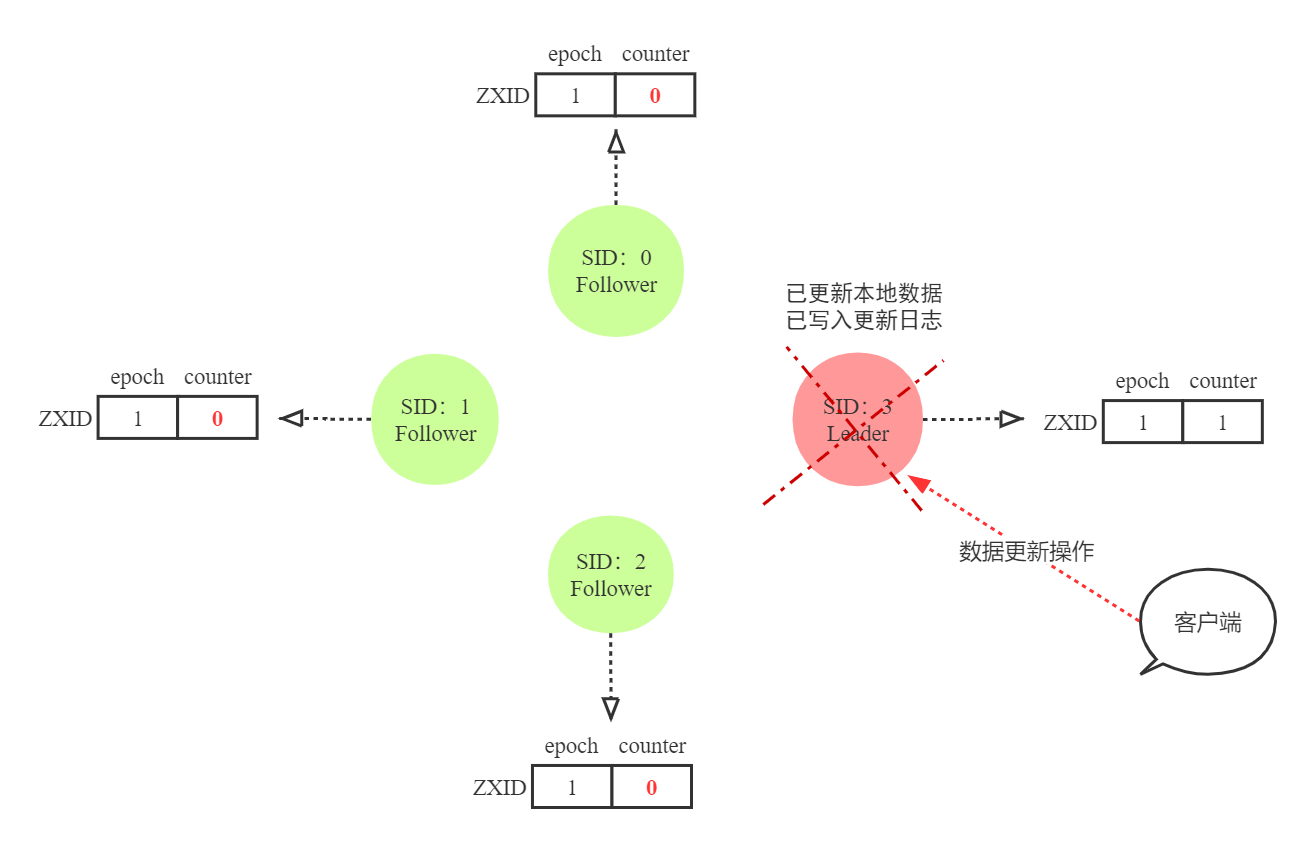
图6 Leader来不及发送proposal宕机了图

图7 新Leader丢弃未得到的proposal图
上面提到的是前任Leader将proposal发给了一个Follower,如果Leader在收到客户端的更新操作,更新本地数据且写入日志后,宕机了。新的Leader又该如何解决这个问题呢?
ZAB数据同步规则:新的Leader需先解决上一任Leader遗留下来的proposal,才可进行新的数据更新。
然而新的Leader并未收到上一任Leader输送过来的proposal,因此会通知上一任Leader将proposal进行回滚。然后才可以处理新的proposal。
总结
1. ZAB保证了Zookeeper集群环境下的数据同步问题。
2. 当Leader出现问题时,通过三阶段(选举/发现、同步、广播)恢复集群。
3. 故障时选举新Leader的数据同步问题:
3.1上一任Leader发出proposal,但是不满足ACK数量条件。新Leader应该重新向集群中的Follower发送给proposal到commit阶段,才可以进行新的客户端更新操作;
3.2 上一任Leader未发出proposal,只在本地做了数据更新。新Leader通知上一任Leader丢弃该proposal,然后进行新的客户端更新操作。
文章编写不易,你的点赞、收藏、转发是我认真编写下一篇文章的动力。




![[洛谷-P1272] 重建道路(树形背包DP)](https://img-blog.csdnimg.cn/57d78bd864a14d528d5ef1687bfe7df8.jpeg#pic_center)