0. 相关分享
Android-全面理解Binder原理
Android特别的数据结构(二)ArrayMap源码解析
1. 序列化 - Parcelable和Serializable的关系
如果我们需要传递一个Java对象,通常需要对其进行序列化,通过内核进行数据转发,可能转发到本地文件,也可能转发到其他进程。序列化的方式很多,只要定好序列化和反序列化的规则,就可以进行Java对象的传输。常见的就是通过Serializable接口进行序列化。
Serializable序列化
Serializable序列化接口,将Java对象转换为字节序列写入文件中,实现了持久化存储。下一次需要使用该Java对象时,可以直接通过Serializable的反序列化规范,将文件中的数据提取出来,转换回Java对象。
Serializable序列化不仅可以让Java对象在本地持久化存储,还可以将此对象数据二进制用于网络传输、进程之间传输。在Android中,为什么还需要设计一个Parcelable来进行序列化呢?对Java对象的序列化方式远不止Serializable、Parcelable,序列化与反序列化的本质目的就是让Java对象能够在不同程序(可能不在一个主机上)进行传输,其实现可能关注在编码,也可能关注在性能,也可能关注在多平台可用。Android中如果要进行进程间通信,使用Serializable并不会表现出良好的性能优势。Serializable序列化过程中会出现反射和IO操作,这对性能要求高的程序来说是不合适的。为针对性能,Android推出了Parcelable序列化接口:
Parcelable序列化
简而言之,Parcelable将Java对象序列化到内存中,其他进程可以通过内核访问到Parcelable序列化后的Java对象的数据,和Serializable不同的是,Parcelable不需要通过内核去进行IO、反射来反序列化,而是直接将序列化的数据写入到内存中。
Parcelable翻译也是“可打包的”,把Java对象的实例数据打包到一块连续的内存空间中(写到Parcel这个native层的对象中,它的大小是可变的,填充数据过程可能会发生扩容,但一定是连续空间)。我们本文主要探讨Parcelable的实现原理,及其在跨进程通信中的表现。
2. Parcelable和Parcel的关系
Parcelable是Android特有的序列化接口,序列化的数据需要存放到内存中,那么再内存中就需要一个Parcel对象来保存这些数据。Parcel对象的结构设计,就表现出了Parcelable序列化的原理。
3. Parcel的结构设计
Parcel是一个C++对象。当我们需要通过Parcelable接口序列化一个Java对象时,需要先通过JNI创建一个Parcel对象,创建Parcel对象时会在内存开辟一块连续的内存空间,Java对象的数据可以按顺序填充到这段内存空间,这样一来,只要知道这段内存空间的地址,就可以按同样的顺序取出数据,填充给另一个Java对象。它的结构大致如下,在内存空间开辟一个Parcel对象,会得到一个首地址。position指针用来表示下一个数据可以存放的位置,也可以表示下一个要读取数据的起始位置。
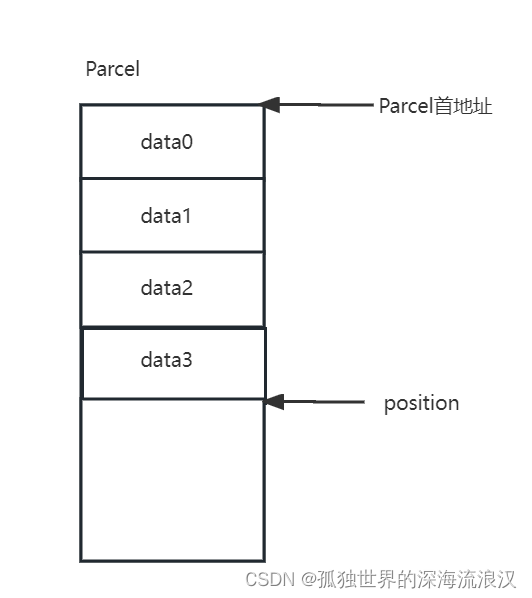
我们知道,不同数据占用的内存空间是不同的,例如Int类型需要占据 4 字节,而double类型则需要占据 8 字节。填入一个数据后,下一个数据可以填充的位置position就需要在原有基础上跨过刚填充数据的字节占用数量。例如上图,position指向了下一个可以插入数据的位置,接下来我要插入一个 int a = 3,将int类型的 3 写入后,将position后移 4 Byte,使之指向未来可以插入数据的位置。
我们来看一下其具体使用:
4. Parcel的使用方法
首先要进行序列化,就要对Java对象实现Parcelable接口,假设我们需要序列化一个User对象,且它的iconUrl属性不参与序列化。代码大致如下:
import android.os.Parcel;
import android.os.Parcelable;
public class User implements Parcelable {
long id;
String username;
String password;
String iconUrl;//不参与序列化
int age;
boolean sex;
//生成一个User对象,其实例数据,通过Parcel获取
protected User(Parcel in) {
id = in.readLong();
username = in.readString();
password = in.readString();
// iconUrl = in.readString();//不参与序列化
age = in.readInt();
sex = in.readByte() != 0;
}
//将User对象数据序列化存放到Parcel对象中
@Override
public void writeToParcel(Parcel dest, int flags) {
dest.writeLong(id);
dest.writeString(username);
dest.writeString(password);
// dest.writeString(iconUrl);//不参与序列化
dest.writeInt(age);
dest.writeByte((byte) (sex ? 1 : 0));
}
@Override
public int describeContents() {
return 0;
}
public static final Creator<User> CREATOR = new Creator<User>() {
@Override
public User createFromParcel(Parcel in) {
return new User(in);
}
@Override
public User[] newArray(int size) {
return new User[size];
}
};
}
writeToParcel()方法是序列化的核心,将需要序列化的属性通过 writeLong()、writeString() 等方法写入 Parcel 对象中。未来反序列化时,也需要与序列化时相同顺序进行 readLong()、readString() 进行数据提取。到这里我们只能在上层感受到Parcel对象数据的写入和读取是有序的,而且是有类型要求的,那么具体是如何实现的?我们还需要看到 write() 相关的代码:
5. Parcel实现原理
Parcel实现原理主要关注到它的写入和读出,是如何写入到一个连续内存空间的,以及如何从连续内存空间有序地提取数据出来的。写入Java对象时,通过writeToParcel()方法将Java对象的实例数据写入到Parcel对象中。先来关注一下Parcel是何时被调用writeToParcel()的。如果我们通过AIDL实现一个跨进程通信,会生成一个Binder实体类和代理类,代理类中,就调用了writeToParcel()。如下是定义的一个AIDL:
//IFyService.aidl
import com.company.binderstudy.javabean.User;
interface IFyService{
int addUser(in User user);
}
我们可以通过Binder代理来调用这个addUser:
//IFyService.java
private static class Proxy implements com.company.binderstudy.IFyService{
@Override public int addUser(com.company.binderstudy.javabean.User user) throws android.os.RemoteException
{
//复用或者创建一个Parcel对象用于序列化发送数据
android.os.Parcel _data = android.os.Parcel.obtain();
//复用或者创建一个Parcel对象用于接收返回数据
android.os.Parcel _reply = android.os.Parcel.obtain();
int _result;
try {
//往parcel中写入token
_data.writeInterfaceToken(DESCRIPTOR);
if ((user!=null)) {
//如果传入参数user不为空,就开始对其序列化
//写入一个标志,表示对象不为null
_data.writeInt(1);
//调用其writeToParcel方法,进行序列化,将数据写入parcel
user.writeToParcel(_data, 0);
}
else {
//如果传入参数为null,写入一个标志位0,表示对象为null
_data.writeInt(0);
}
//调用远程服务的addUser方法
boolean _status = mRemote.transact(Stub.TRANSACTION_addUser, _data, _reply, 0);
if (!_status && getDefaultImpl() != null) {
return getDefaultImpl().addUser(user);
}
_reply.readException();
_result = _reply.readInt();
}
finally {
_reply.recycle();
_data.recycle();
}
return _result;
}
}
可以看到,通过Proxy进行远程通信的时候,需要做几件事:
- 复用或者创建一个Parcel对象_data用于序列化发送数据
- 复用或者创建一个Parcel对象_reply用于接收返回数据
- 往 _data 中写入token,标识着这个parcel来自哪个服务(服务的全路径)
- 将方法的若干个传入参数序列化到_data中
- 将_data 发送给远程服务,发起事务。
我们主要关注Parcel对象的复用或创建,与序列化。
5.1 Parcel对象的复用与创建
Parcel.obtain()方法,进行Parcel对象的复用与创建。Parcel对象的实例化过程,除了C++层的Parcel对象创建,还包括了其Java层外壳Parcel对象的创建。Java层的Parcel对象主要用于对Java应用提供接口,以及提供复用池设计:
//Parcel.java
private static final Object sPoolSync = new Object();
//单链表形式的复用池
private Parcel mPoolNext;
static protected final Parcel obtain(long obj) {
Parcel res = null;
//1. 在复用池获取
synchronized (sPoolSync) {
if (sHolderPool != null) {
res = sHolderPool;
sHolderPool = res.mPoolNext;
res.mPoolNext = null;
sHolderPoolSize--;
}
}
//2. 如果没有可复用的,就new一个Parcel
if (res == null) {
res = new Parcel(obj);
} else {
if (DEBUG_RECYCLE) {
res.mStack = new RuntimeException();
}
res.init(obj);
}
return res;
}
//2. 构造函数,调用native层的方法,通过JNI在本地内存中创建一个C++层的Parcel对象
private Parcel(long nativePtr) {
if (DEBUG_RECYCLE) {
mStack = new RuntimeException();
}
init(nativePtr);
}
private void init(long nativePtr) {
if (nativePtr != 0) {
mNativePtr = nativePtr;
mOwnsNativeParcelObject = false;
} else {
mNativePtr = nativeCreate();
mOwnsNativeParcelObject = true;
}
}
//4. native层的方法,通过JNI调用
private static native long nativeCreate();
因为在本地内存中开辟一块连续内存空间是耗时的(使用过程中可能需要扩容,一开始创建Parcel对象的时候并不是确定长度的),所以尽量不要频繁地创建、删除native层的Parcel对象,通过复用池来保存复用对象。Java层的Parcel对象是如何持有native层的Parcel对象引用的?其实从nativeCreate()方法的返回值就能猜出来,将native层的Parcel的内存地址,将会交给mNativePtr。
我们来到native层看一下Parcel的创建:
//android_os_Parcel.cpp
static jlong android_os_Parcel_create(JNIEnv* env, jclass clazz)
{
Parcel* parcel = new Parcel();
return reinterpret_cast<jlong>(parcel);
}
//Parcel.cpp
//构造函数
Parcel::Parcel()
{
LOG_ALLOC("Parcel %p: constructing", this);
initState();
}
//用来释放内存
Parcel::~Parcel()
{
freeDataNoInit();
LOG_ALLOC("Parcel %p: destroyed", this);
}
void Parcel::initState()
{
LOG_ALLOC("Parcel %p: initState", this);
mError = NO_ERROR;
mData = nullptr;
mDataSize = 0;
mDataCapacity = 0;
mDataPos = 0;
ALOGV("initState Setting data size of %p to %zu", this, mDataSize);
ALOGV("initState Setting data pos of %p to %zu", this, mDataPos);
mObjects = nullptr;
mObjectsSize = 0;
mObjectsCapacity = 0;
mNextObjectHint = 0;
mHasFds = false;
mFdsKnown = true;
mAllowFds = true;
mDeallocZero = false;
mOwner = nullptr;
clearCache();
//...
}
至此,Java层的Parcel对象的mNativePtr就指向了native层的Parcel对象的地址。刚创建的nateive层的Parcel对象占用空间很小,只有在不断写入数据的过程中,才会发生扩容。
5.2 Parcel对象序列化数据的写入
创建好Parcel对象之后,就可以往里写入序列化数据,通过调用需要序列化的Java对象的writeToParcel()方法进行写入,仍然还是上面的 User 类的例子:
@Override
public void writeToParcel(Parcel dest, int flags) {
dest.writeLong(id);
dest.writeString(username);
dest.writeString(password);
// dest.writeString(iconUrl);//不参与序列化
dest.writeInt(age);
dest.writeByte((byte) (sex ? 1 : 0));
}
这些写入的方法大同小异,我们就看writeString():
//Parcel.java
public final void writeString16(@Nullable String val) {
mReadWriteHelper.writeString16(this, val);
}
//最终调用到ReadWriteHelper的writeString16方法
public void writeString16(Parcel p, String s) {
p.writeString16NoHelper(s);
}
//最后来到Parcel的nativeWriteString16
private static native void nativeWriteString16(long nativePtr, String val);
来到native层的Parcel对象数据写入:
//android_os_parcel
static void android_os_Parcel_writeString16(JNIEnv *env, jclass clazz, jlong nativePtr,
jstring val) {
//根据mNativePtr反向获取到native层的Parcel对象
Parcel* parcel = reinterpret_cast<Parcel*>(nativePtr);
if (parcel != nullptr) {
status_t err = NO_ERROR;
if (val) {
//获取String数据的长度(char数组的长度)
const size_t len = env->GetStringLength(val);
//计算需要申请的控件长度
const size_t allocLen = len * sizeof(char16_t);
//先写入长度再写入数据
err = parcel->writeInt32(len);
//先判断空间,写入对齐填充
char *data = reinterpret_cast<char*>(parcel->writeInplace(allocLen + sizeof(char16_t)));
if (data != nullptr) {
//将数据填充到data指针指向的地址,写入val数据
env->GetStringRegion(val, 0, len, reinterpret_cast<jchar*>(data));
*reinterpret_cast<char16_t*>(data + allocLen) = 0;
} else {
err = NO_MEMORY;
}
} else {
err = parcel->writeString16(nullptr, 0);
}
if (err != NO_ERROR) {
signalExceptionForError(env, clazz, err);
}
}
}
在写入字符串之前,先写入字符串的长度(便于反序列化的时候,确认要从内存中连续读取多少内容),然后再写入数据。
首先通过 witeInt32() 写入字符串长度:
//Parcel.cpp
status_t Parcel::writeInt32(int32_t val)
{
return writeAligned(val);
}
template<class T>
status_t Parcel::writeAligned(T val) {
static_assert(PAD_SIZE_UNSAFE(sizeof(T)) == sizeof(T));
if ((mDataPos+sizeof(val)) <= mDataCapacity) {
restart_write:
//通过mData基地址+mDataPos偏移量,在可以写入的位置写入新的值
*reinterpret_cast<T*>(mData+mDataPos) = val;
//更新下一个可以写入的位置,即更新mDataPos的值
return finishWrite(sizeof(val));
}
//如果需要扩容,先扩容,然后通过goto回到写入部分再次写入
status_t err = growData(sizeof(val));
if (err == NO_ERROR) goto restart_write;
return err;
}
//完成写入,更新mDataPos位置
status_t Parcel::finishWrite(size_t len)
{
//写入长度太长就报错
if (len > INT32_MAX) {
return BAD_VALUE;
}
//更新mDataPos位置
mDataPos += len;
//mDataSize记录的是现有数据个数
//mDataPos有可能会回撤用于重写之前填入的数据,所以还需要mDataSize来记录现有全部数据个数
if (mDataPos > mDataSize) {
mDataSize = mDataPos;
}
return NO_ERROR;
}
//扩容
status_t Parcel::growData(size_t len)
{
if (len > INT32_MAX) {
return BAD_VALUE;
}
if (len > SIZE_MAX - mDataSize) return NO_MEMORY;
if (mDataSize + len > SIZE_MAX / 3) return NO_MEMORY;
size_t newSize = ((mDataSize+len)*3)/2;
//在continueWrite()中进行了alloc申请新空间
return continueWrite(newSize);
}
可以看到,在真正数据写入的时候,会进行扩容判断,如果容量不够了,会先通过 growData() 进行扩容,然后再进行写入。注意几个指针:
- mData - 表示 native层Parcel的数据的起始地址
- mDataPos - 类似于游标,可以用来表示下一个插入数据的位置,也可以用来遍历提取数据
- mDataSize - 表示当前被序列化的元素总大小
写入数据后,会更新mDataPos。写入字符串首先写入完int类型表示长度之后,就写入字符串的char[]数据,首先会根据字符串长度计算,并做对齐填充,同样的,也可能会通过growData()进行扩容,然后通过env->GetStringRegion(val, 0, len, reinterpret_cast<jchar*>(data))将val的数据写入data。
5.3 并不是所有类型都能写入Parcel
写入Parcel的类型判断在Java层的Parcel完成。我们可以看到方法列表中,都给出了可以写入的类型。
比较特别的是Map类型的数据写入,我们知道Map的Value类型是不确定的,Parcel当然也在对Map遍历写入的过程中会进行类型判断,只允许写入规范内的类型,以写入ArrayMap为例:
//Parcel.java
//写入ArrayMap
public void writeArrayMap(@Nullable ArrayMap<String, Object> val) {
writeArrayMapInternal(val);
}
void writeArrayMapInternal(@Nullable ArrayMap<String, Object> val) {
if (val == null) {
writeInt(-1);
return;
}
final int N = val.size();
writeInt(N);
int startPos;
for (int i=0; i<N; i++) {
//先写入Key,在写入Value,Key必须是String类型
writeString(val.keyAt(i));
writeValue(val.valueAt(i));
}
核心看到这里的writeValue()是如何做判断的:
//Parcel.java
public final void writeValue(@Nullable Object v) {
if (v instanceof LazyValue) {
LazyValue value = (LazyValue) v;
value.writeToParcel(this);
return;
}
//拿到Value的类型,在这类做类型判断,如果类型不符合要求,会抛异常
int type = getValueType(v);
//如果没有抛异常,就继续执行下去,先写入类型
writeInt(type);
//如果是一个有长度的type,除了写入value,还要写入长度
if (isLengthPrefixed(type)) {
// Length
int length = dataPosition();
writeInt(-1); // Placeholder
// Object
int start = dataPosition();
writeValue(type, v);
int end = dataPosition();
// Backpatch length
setDataPosition(length);
writeInt(end - start);
setDataPosition(end);
} else {
//writeValue写入的时候只能写入确定类型的,如果不在范围内,将会报错,即无法Parcel打包
//例如你写了一个Object的子类例如Student,但是没有实现Parcelable接口,或者没有符合Parcel写入规约,将会在writeValue的时候报错
writeValue(type, v);
}
}
写入value的时候,首先会对Value的类型进行判断,如果不是规范类型,将会抛出异常,如果是规范类型,还会分成不定长度的类型和定长类型。比如String、Map就是不定长,Integer这类的就是定长数据。
//Parcel.java
//获取Value的类型
public static int getValueType(@Nullable Object v) {
if (v == null) {
return VAL_NULL;
} else if (v instanceof String) {
return VAL_STRING;
} else if (v instanceof Integer) {
return VAL_INTEGER;
} else if (v instanceof Map) {
return VAL_MAP;
} else if (v instanceof Bundle) {
// Must be before Parcelable
return VAL_BUNDLE;
}
//...
else {
Class<?> clazz = v.getClass();
if (clazz.isArray() && clazz.getComponentType() == Object.class) {
return VAL_OBJECTARRAY;
} else if (v instanceof Serializable) {
// Must be last
return VAL_SERIALIZABLE;
} else {
//如果类型不对,抛异常
throw new IllegalArgumentException("Parcel: unknown type for value " + v);
}
}
}
至此,将Java对象的数据序列化写入native层的Parcel对象的过程以及跟通了。小小感受一下它和Serializable的区别,Serializable将序列化的数据直接写入文件,而Parcelable接口则将序列化的数据写入内存,更加适用于跨进程通信。既然Parcelable适用于跨进程通信,我们就来看一下Parcel在跨进程通信过程中的表现:
6. Parcel在Bundle中的使用
通常我们使用Intent来发起进程间通信,传递的数据可以放到Intent中,其实最终都是放到Intent的Bundle类型的mExtras中:
//Intent.java
private Bundle mExtras;
public Intent putExtra(String name, Charsequence value){
if (mExtras == null) {
mExtras = new Bundle();
}
mExtras.putCharSequence(name, value);
return this;
}
public Intent putExtra(String name, Parcelable value){
if (mExtras == null) {
mExtras = new Bundle();
}
mExtras.putParcelable(name, value);
return this;
}
//...
放到Intent中的数据将通过Bundle类型的mExtras.putXXX()存放到Bundle中,这个方法在Bundle的父类BaseBundle中实现:
//BaseBundle.java
ArrayMap<String, Object> mMap = null;
volatile Parcel mParcelledData = null;//如果mParcelledData不为空,那么mMap将为空,并且数据存储为包含Bundle的Parcel。但数据被拆封时,mParcelledData将会被设置为null
void putBoolean(String key, boolean value){
unparcel();//数据拆封,放到mMap中
mMap.put(key,value);
}
void putString(String key, String value){
unparcel();//数据拆封,放到mMap中
mMap.put(key,value);
}
//...
其中,如果mParcelledData不为空,那么mMap将为空,并且数据存储为包含Bundle的Parcel。但数据被拆封时,mParcelledData将会被设置为null。
正常情况下,ArrayMap的存储容量只受堆大小影响。但如果将数据打包到Parcel中进行进程间通信,就需要考虑Binder的mmap映射内存空间的大小了,一般情况下,内存大小不能超过 1M - 8K。再大也不能超过 4M。
binder驱动给每个进程分配最多4M的buffer空间(一般从Zygote孵化出来的APP默认分配 1M-8K大小,servicemanager默认分配128K).
当然可以突破这个 1M-8K 的限制,可以自己手动调用open和mmap即可:
int main(int argc,char **argv){ ... bs = binder_open("/dev/binder",【自定义大小】); }但是还是无法突破 binder_mmap() 中 SM_4M 的限制
如果还要再深究,其实binder_mmap中害设置了最大值的另外设置:
static int binder_mmap(...){ proc->free_async_space = proc->buffer_size/2; }对于oneway和非oneway来说:
手写mmap初始化binder服务 ProcessState初始化Binder服务 oneway 4M/2 (1M-8K)/2 非oneway 4M 1M-8K 一般情况下,Intent传输数据的上限是1M,因为 Intent 传输数据的机制中,用到了Binder。Intent 中的数据,会被作为 Parcel被存储在 Binder的事务缓冲区(Binder transaction buffer)中的对象进行传输。而 1M 并不是安全的上限,还是推荐不要通过Intent传递太大的数据。
解决办法:
- 减少传输数据量
- Intent 通过绑定一个 Bundle 来传输,这个可以超过 1M,不过也不能过大
- 通过内存共享
- 通过文件共享,如这里说到的 binder通信中进行传输文件句柄fd
这里不做 Bundle 的知识补充
7. Parcel在Binder通信中的表现
Parcel在Binder通信中,并不只序列化Java实例数据,还存了许多其他信息,包括但不限于Binder实体/远程引用:
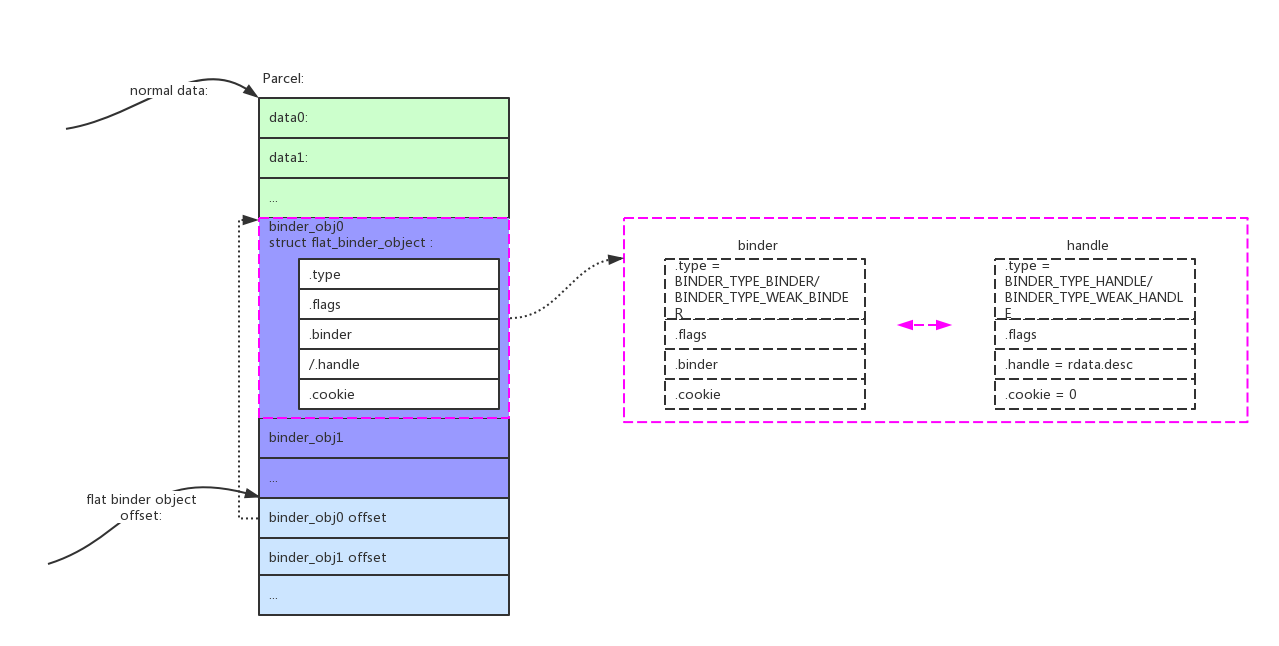
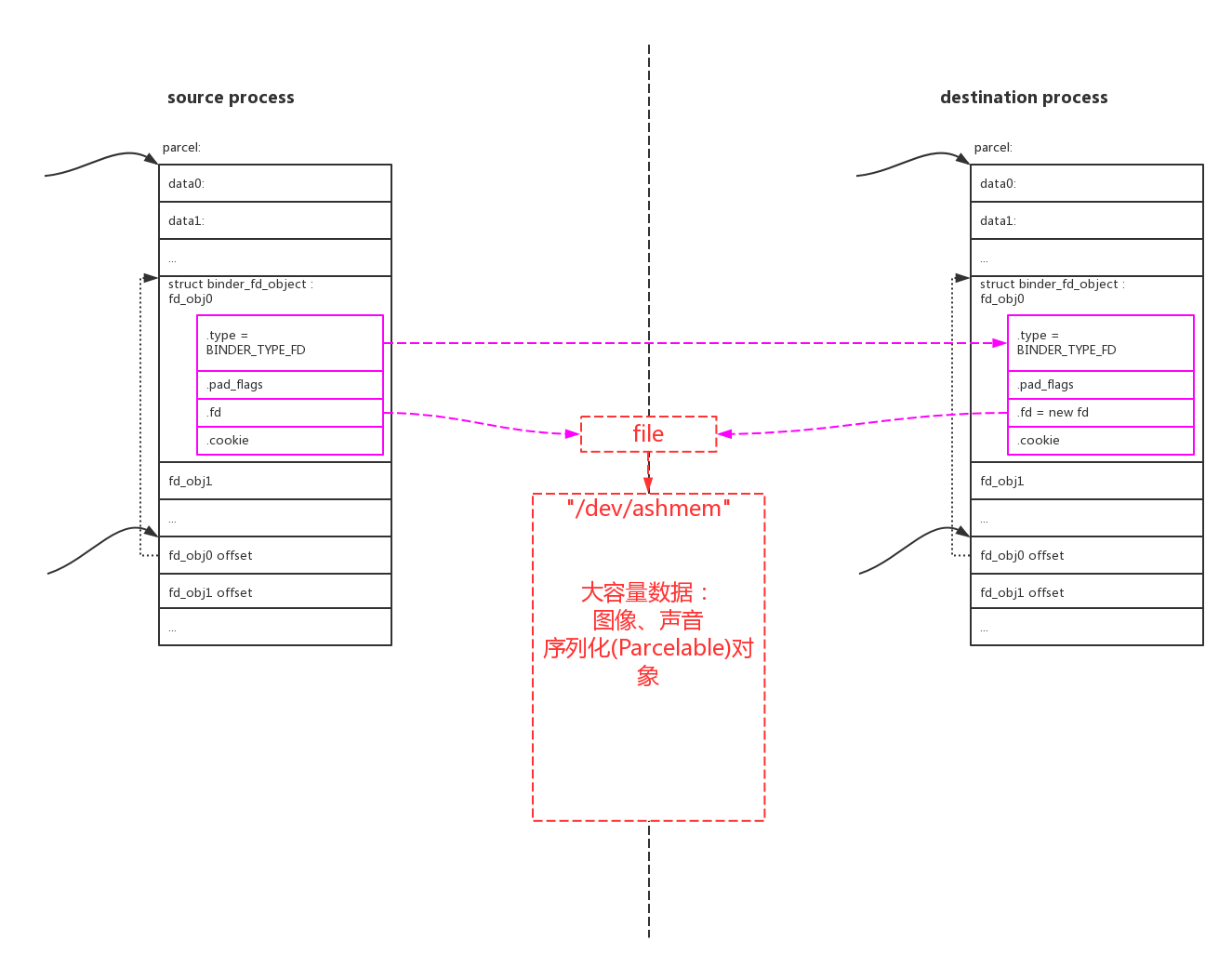
如果要传递大量数据,只能通过传递文件句柄fd,通过共享文件的方式来传递大数据:
那么Parcel写入数据的时候如何写入这些内容呢?显然入口是通过Parcel.java写入binder。对应的方法是nativeWriteStrongBinder(),来到native层:
//android_os_Parcel.cpp
static void android_os_Parcel_writeStrongBinder(JNIEnv* env, jclass clazz, jlong nativePtr, jobject object)
{
Parcel* parcel = reinterpret_cast<Parcel*>(nativePtr);
if (parcel != NULL) {
//交给Parcel对象来写入Binder
const status_t err = parcel->writeStrongBinder(ibinderForJavaObject(env, object));
if (err != NO_ERROR) {
signalExceptionForError(env, clazz, err);
}
}
}
native层的Parcel写入Binder,会将Binder“压扁打平”写入Parcel,这部分解析可以参考上图结构:
//Parcel.cpp
status_t Parcel::writeStrongBinder(const sp<IBinder>& val)
{
return flatten_binder(ProcessState::self(), val, this);
}
status_t flatten_binder(const sp<ProcessState>& /*proc*/,
const sp<IBinder>& binder, Parcel* out)
{
//Binder数据被拆分放入flat_binder_object对象中
flat_binder_object obj = {};
if (binder != nullptr) {
BHwBinder *local = binder->localBinder();
if (!local) {
//会进行一个判断,如果这个IBinder是远程服务,则会转换为Binder远程引用,也就是handle,存入Parcel中
BpHwBinder *proxy = binder->remoteBinder();
if (proxy == nullptr) {
ALOGE("null proxy");
}
//生成一个int类型的handle句柄- binder远程引用句柄
const int32_t handle = proxy ? proxy->handle() : 0;
//设置类型为handle
obj.hdr.type = BINDER_TYPE_HANDLE;
//给出标记
obj.flags = FLAT_BINDER_FLAG_ACCEPTS_FDS;
obj.binder = 0;
//由于是handle,只设置handle的值
obj.handle = handle;
obj.cookie = 0;
} else {
//如果这个IBinder是本地服务,将会转换为Binder实体,存入Parcel中
int policy = local->getMinSchedulingPolicy();
int priority = local->getMinSchedulingPriority();
//标志设置为本地服务
obj.flags = priority & FLAT_BINDER_FLAG_PRIORITY_MASK;
obj.flags |= FLAT_BINDER_FLAG_ACCEPTS_FDS | FLAT_BINDER_FLAG_INHERIT_RT;
obj.flags |= (policy & 3) << FLAT_BINDER_FLAG_SCHED_POLICY_SHIFT;
if (local->isRequestingSid()) {
obj.flags |= FLAT_BINDER_FLAG_TXN_SECURITY_CTX;
}
//类型设为Binder实体
obj.hdr.type = BINDER_TYPE_BINDER;
//设置实体的引用,根据名字可以猜到使用弱引用
obj.binder = reinterpret_cast<uintptr_t>(local->getWeakRefs());
obj.cookie = reinterpret_cast<uintptr_t>(local);
}
} else {
//如果根本就没有传递binder,我猜测传递的是ServiceManager这个handle为0的服务
obj.hdr.type = BINDER_TYPE_BINDER;
obj.binder = 0;
obj.cookie = 0;
}
//将obj写入out这个Parcel中
return finish_flatten_binder(binder, obj, out);
}
可以看到,flatten_binder的任务主要根据IBinder是本地服务还是远程引用,拼接 flat_binder_object。最后写入到Parcel中则是通过 finish_flatten_binder() 将这个 flat_binder_object 写入。
template <typename T>
status_t Parcel::writeObject(const T& val)
{
const bool enoughData = (mDataPos+sizeof(val)) <= mDataCapacity;
const bool enoughObjects = mObjectsSize < mObjectsCapacity;
if (enoughData && enoughObjects) {
//如果需要扩容,扩容后会根据这个标记goto到这里开始执行
restart_write:
//写入数据到mData+mDataPos,也就是下一个可以写入的位置
*reinterpret_cast<T*>(mData+mDataPos) = val;
//根据接入的对象,强转成 binder_object_header对象
const binder_object_header* hdr = reinterpret_cast<binder_object_header*>(mData+mDataPos);
//根据头部中的type信息来判断接下来需要写入什么内容
switch (hdr->type) {
//如果类型是Binder类型
case BINDER_TYPE_BINDER:
case BINDER_TYPE_WEAK_BINDER:
case BINDER_TYPE_HANDLE:
case BINDER_TYPE_WEAK_HANDLE: {
//强转回 flat_binder_object 类(就是刚传入的val)
const flat_binder_object *fbo = reinterpret_cast<const flat_binder_object*>(hdr);
//如果这是binder的实体
if (fbo->binder != 0) {
//将偏移量记录
mObjects[mObjectsSize++] = mDataPos;
//将这个 flat_binder_object 记录到 ProcessState中
acquire_binder_object(ProcessState::self(), *fbo, this);
}
break;
}
//如果类型是文件描述符(共享文件)
case BINDER_TYPE_FD: {
// remember if it's a file descriptor
if (!mAllowFds) {
// fail before modifying our object index
return FDS_NOT_ALLOWED;
}
mHasFds = mFdsKnown = true;
mObjects[mObjectsSize++] = mDataPos;
break;
}
case BINDER_TYPE_FDA:
mObjects[mObjectsSize++] = mDataPos;
break;
case BINDER_TYPE_PTR: {
const binder_buffer_object *buffer_obj = reinterpret_cast<
const binder_buffer_object*>(hdr);
if ((void *)buffer_obj->buffer != nullptr) {
mObjects[mObjectsSize++] = mDataPos;
}
break;
}
default: {
ALOGE("writeObject: unknown type %d", hdr->type);
break;
}
}
//完成写入,更新mDataPos
return finishWrite(sizeof(val));
}
//如果空间不够,就进行扩容,最后通过 goto 回到写入数据的部分。
if (!enoughData) {
const status_t err = growData(sizeof(val));
if (err != NO_ERROR) return err;
}
if (!enoughObjects) {
if (mObjectsSize > SIZE_MAX - 2) return NO_MEMORY; // overflow
if (mObjectsSize + 2 > SIZE_MAX / 3) return NO_MEMORY; // overflow
size_t newSize = ((mObjectsSize+2)*3)/2;
if (newSize > SIZE_MAX / sizeof(binder_size_t)) return NO_MEMORY; // overflow
binder_size_t* objects = (binder_size_t*)realloc(mObjects, newSize*sizeof(binder_size_t));
if (objects == nullptr) return NO_MEMORY;
mObjects = objects;
mObjectsCapacity = newSize;
}
goto restart_write;
}
8. 总结
Android为了实现进程间通信,传递Java对象数据,需要对数据进行序列化。现有许多序列化工具,常用的就是Serializable接口,Serializable序列化的优点就是适用范围广,不仅可以持久化存储对象到本地,也可以进行网络传输,但最大的缺点就是使用了反射和IO,性能不高。进场间通信是一个聚焦的功能,使用Parcelable接口直接将对象序列化到内存中,相比之下减少了反射和IO的时间损耗。当然,我们也知道Zygote的通信是通过socket的,如果在socket场景下要进行进程间通信,仍然需要使用Serializable进行序列化。
此外,虽然说Parcelable接口将对象序列化到内存中,这个“内存”仍然是进程私有的,不是共享内存。一个APP进程除了有JVM虚拟机的内存空间,还有本地内存(包含了元空间、直接内存)。JNI创建的C++对象是在本地内存的,它将数据直接写在内存块中。通过Binder通信,Binder驱动将这个内存块的数据直接拷贝到接收方进程的映射内存空间中,接收方访问这部分内存可以直接根据Parcelable的约定来反序列化出数据,实现了跨进程数据通信。
注:JNI创建的C++对象到底在JVM堆内存还是本地内存的哪个位置笔者还没探究清除。



![[洛谷-P1272] 重建道路(树形背包DP)](https://img-blog.csdnimg.cn/57d78bd864a14d528d5ef1687bfe7df8.jpeg#pic_center)