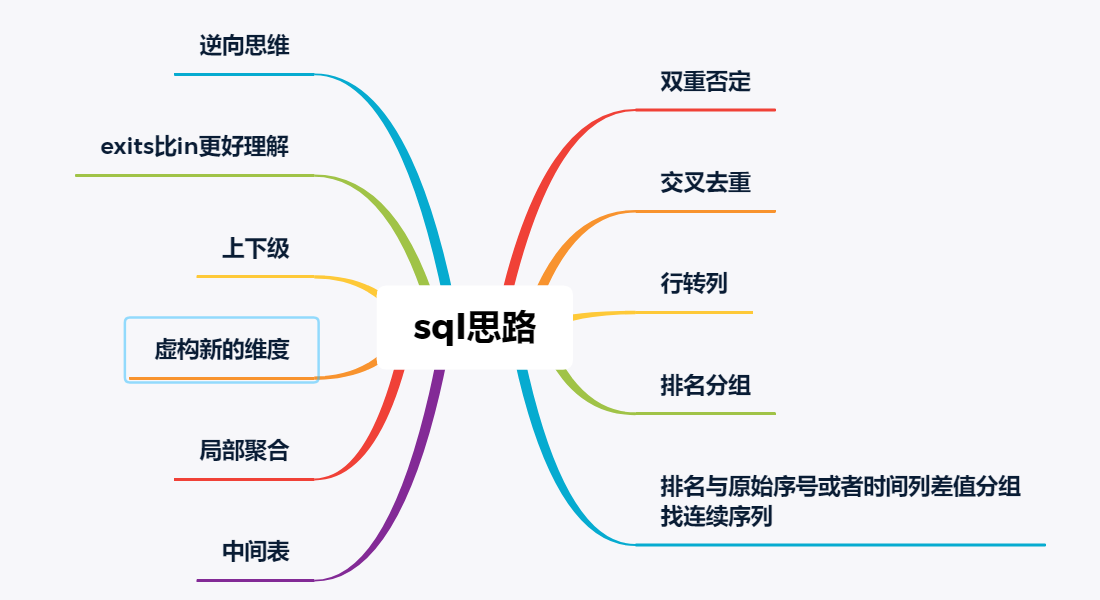
##一、通过排名或者范围条件连表筛选特殊行
- 第一行
- 最后一行
- 区间(第一行到第二行或者连续区间)
- 找中位数
- 通过
排名进行分组或者连续区间
######1.使用条件筛选连表找区间
Employee 表保存了一年内的薪水信息。
请你编写 SQL 语句,来查询每个员工每个月最近三个月的累计薪水(不包括当前统计月,不足三个月也要计算)。
结果请按 ‘Id’ 升序,然后按 ‘Month’ 降序显示。
示例:
输入:
| Id | Month | Salary |
|---|---|---|
| 1 | 1 | 20 |
| 2 | 1 | 20 |
| 1 | 2 | 30 |
| 2 | 2 | 30 |
| 3 | 2 | 40 |
| 1 | 3 | 40 |
| 3 | 3 | 60 |
| 1 | 4 | 60 |
| 3 | 4 | 70 |
| 输出: |
| Id | Month | Salary |
|---|---|---|
| 1 | 3 | 90 |
| 1 | 2 | 50 |
| 1 | 1 | 20 |
| 2 | 1 | 20 |
| 3 | 3 | 100 |
| 3 | 2 | 40 |
解释:
员工 ‘1’ 除去最近一个月(月份 ‘4’),有三个月的薪水记录:月份 ‘3’ 薪水为 40,月份 ‘2’ 薪水为 30,月份 ‘1’ 薪水为 20。
所以近 3 个月的薪水累计分别为 (40 + 30 + 20) = 90,(30 + 20) = 50 和 20。
| Id | Month | Salary |
|---|---|---|
| 1 | 3 | 90 |
| 1 | 2 | 50 |
| 1 | 1 | 20 |
| 员工 ‘2’ 除去最近的一个月(月份 ‘2’)的话,只有月份 ‘1’ 这一个月的薪水记录。 |
| Id | Month | Salary |
|---|---|---|
| 2 | 1 | 20 |
| 员工 ‘3’ 除去最近一个月(月份 ‘4’)后有两个月,分别为:月份 ‘4’ 薪水为 60 和 月份 ‘2’ 薪水为 40。所以各月的累计情况如下: |
| Id | Month | Salary |
|---|---|---|
| 3 | 3 | 100 |
| 3 | 2 | 40 |
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/find-cumulative-salary-of-an-employee
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
#代码中使用一个范围连表,在使用最小月份去重最后一个月
# Write your MySQL query statement below
select d1.Id,d1.Month,d1.Salary
from
(select a.Id,a.Month,sum(b.Salary) Salary
from Employee a
left join Employee b
on a.Id = b.Id and a.month >= b.month and b.month >=a.month-2
group by a.Id,a.Month
) d1
left join
(select c.Id,Max(c.Month) maxMonth
from Employee c
group by c.Id) d2
on d1.id = d2.id
where d1.Month < d2.maxMonth
order by d1.id asc,d1.Month desc
######2.使用排名来找中位数
Employee 表包含所有员工。Employee 表有三列:员工Id,公司名和薪水。
±----±-----------±-------+
|Id | Company | Salary |
±----±-----------±-------+
|1 | A | 2341 |
|2 | A | 341 |
|3 | A | 15 |
|4 | A | 15314 |
|5 | A | 451 |
|6 | A | 513 |
|7 | B | 15 |
|8 | B | 13 |
|9 | B | 1154 |
|10 | B | 1345 |
|11 | B | 1221 |
|12 | B | 234 |
|13 | C | 2345 |
|14 | C | 2645 |
|15 | C | 2645 |
|16 | C | 2652 |
|17 | C | 65 |
±----±-----------±-------+
请编写SQL查询来查找每个公司的薪水中位数。挑战点:你是否可以在不使用任何内置的SQL函数的情况下解决此问题。
±----±-----------±-------+
|Id | Company | Salary |
±----±-----------±-------+
|5 | A | 451 |
|6 | A | 513 |
|12 | B | 234 |
|9 | B | 1154 |
|14 | C | 2645 |
±----±-----------±-------+
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/median-employee-salary
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
#下面先进行排名,然后使用in()进行偶数个数组的中位数和奇数个数组的中位数
# Write your MySQL query statement below
select c1.id,c1.company,c1.salary
from
(select a.id,a.Company,a.salary,
case @cp when a.Company then @rk:=@rk+1 else @rk:=1 end rk,
@cp:=a.Company
from Employee a,(select @rk:=0,@cp:='') b
order by a.Company,a.salary) c1
left join
(select company,count(1)/2 p
from Employee
group by company ) c2
on c1.company=c2.company
where c1.rk in (c2.p+0.5,c2.p+1,c2.p)
######3.使用排名找特定的某一行
表: Users
±---------------±--------+
| Column Name | Type |
±---------------±--------+
| user_id | int |
| join_date | date |
| favorite_brand | varchar |
±---------------±--------+
user_id 是该表的主键
表中包含一位在线购物网站用户的个人信息,用户可以在该网站出售和购买商品。
表: Orders
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| order_id | int |
| order_date | date |
| item_id | int |
| buyer_id | int |
| seller_id | int |
±--------------±--------+
order_id 是该表的主键
item_id 是 Items 表的外键
buyer_id 和 seller_id 是 Users 表的外键
表: Items
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| item_id | int |
| item_brand | varchar |
±--------------±--------+
item_id 是该表的主键
写一个 SQL 查询确定每一个用户按日期顺序卖出的第二件商品的品牌是否是他们最喜爱的品牌。如果一个用户卖出少于两件商品,查询的结果是 no 。
题目保证没有一个用户在一天中卖出超过一件商品
下面是查询结果格式的例子:
Users table:
±--------±-----------±---------------+
| user_id | join_date | favorite_brand |
±--------±-----------±---------------+
| 1 | 2019-01-01 | Lenovo |
| 2 | 2019-02-09 | Samsung |
| 3 | 2019-01-19 | LG |
| 4 | 2019-05-21 | HP |
±--------±-----------±---------------+
Orders table:
±---------±-----------±--------±---------±----------+
| order_id | order_date | item_id | buyer_id | seller_id |
±---------±-----------±--------±---------±----------+
| 1 | 2019-08-01 | 4 | 1 | 2 |
| 2 | 2019-08-02 | 2 | 1 | 3 |
| 3 | 2019-08-03 | 3 | 2 | 3 |
| 4 | 2019-08-04 | 1 | 4 | 2 |
| 5 | 2019-08-04 | 1 | 3 | 4 |
| 6 | 2019-08-05 | 2 | 2 | 4 |
±---------±-----------±--------±---------±----------+
Items table:
±--------±-----------+
| item_id | item_brand |
±--------±-----------+
| 1 | Samsung |
| 2 | Lenovo |
| 3 | LG |
| 4 | HP |
±--------±-----------+
Result table:
±----------±-------------------+
| seller_id | 2nd_item_fav_brand |
±----------±-------------------+
| 1 | no |
| 2 | yes |
| 3 | yes |
| 4 | no |
±----------±-------------------+
id 为 1 的用户的查询结果是 no,因为他什么也没有卖出
id为 2 和 3 的用户的查询结果是 yes,因为他们卖出的第二件商品的品牌是他们自己最喜爱的品牌
id为 4 的用户的查询结果是 no,因为他卖出的第二件商品的品牌不是他最喜爱的品牌
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/market-analysis-ii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
#代码中先进行排序,直接使用序号进行过滤
# Write your MySQL query statement below
select u.user_id seller_id,if(i.item_brand=u.favorite_brand,'yes','no') 2nd_item_fav_brand
from Users u left join
(select d.seller_id,d.order_date,d.rank
from
(select c.seller_id,c.order_date,case when @seller=c.seller_id then @rk:=@rk+1 else @rk:=1 end rank, @seller:=c.seller_id temp
from
(select * from Orders order by seller_id,order_date) c,(select @seller:=-1,@rk:=-1) b
) d
where d.rank =2) o
on u.user_id = o.seller_id
left join Orders t on o.seller_id = t.seller_id and o.order_date = t.order_date
left join Items i on t.item_id = i.item_id
order by u.user_id
##二、通过排名进行分组或者连续区间
######为什么要使用这种方式分组,因为有时候你的分组维度是不存在的,你必须自己制造这个维度!比如如下这题:
Table: Failed
±-------------±--------+
| Column Name | Type |
±-------------±--------+
| fail_date | date |
±-------------±--------+
该表主键为 fail_date。
该表包含失败任务的天数.
Table: Succeeded
±-------------±--------+
| Column Name | Type |
±-------------±--------+
| success_date | date |
±-------------±--------+
该表主键为 success_date。
该表包含成功任务的天数.
系统 每天 运行一个任务。每个任务都独立于先前的任务。任务的状态可以是失败或是成功。
编写一个 SQL 查询 2019-01-01 到 2019-12-31 期间任务连续同状态 period_state 的起止日期(start_date 和 end_date)。即如果任务失败了,就是失败状态的起止日期,如果任务成功了,就是成功状态的起止日期。
最后结果按照起始日期 start_date 排序
查询结果样例如下所示:
Failed table:
±------------------+
| fail_date |
±------------------+
| 2018-12-28 |
| 2018-12-29 |
| 2019-01-04 |
| 2019-01-05 |
±------------------+
Succeeded table:
±------------------+
| success_date |
±------------------+
| 2018-12-30 |
| 2018-12-31 |
| 2019-01-01 |
| 2019-01-02 |
| 2019-01-03 |
| 2019-01-06 |
±------------------+
Result table:
±-------------±-------------±-------------+
| period_state | start_date | end_date |
±-------------±-------------±-------------+
| succeeded | 2019-01-01 | 2019-01-03 |
| failed | 2019-01-04 | 2019-01-05 |
| succeeded | 2019-01-06 | 2019-01-06 |
±-------------±-------------±-------------+
结果忽略了 2018 年的记录,因为我们只关心从 2019-01-01 到 2019-12-31 的记录
从 2019-01-01 到 2019-01-03 所有任务成功,系统状态为 “succeeded”。
从 2019-01-04 到 2019-01-05 所有任务失败,系统状态为 “failed”。
从 2019-01-06 到 2019-01-06 所有任务成功,系统状态为 “succeeded”。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/report-contiguous-dates
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
#####代码中使用一个排名的序号和最小值得差值,进行分组!只要是连续的区间的,这个差值一定是相同
/* Write your PL/SQL query statement below */
SELECT *
FROM (
SELECT 'failed' AS period_state, to_char(MIN(fail_date), 'yyyy-MM-dd') AS start_date
, to_char(MAX(fail_date), 'yyyy-MM-dd') AS end_date
FROM (
SELECT a.fail_date, fail_date - minDate - rn AS groupId
FROM (
SELECT a.fail_date, rownum AS rn, MIN(fail_date) OVER (ORDER BY fail_date) AS minDate
FROM Failed a
WHERE a.fail_date >= '2019-01-01'
AND a.fail_date <= '2019-12-31'
) a
) a
GROUP BY a.groupId
UNION ALL
SELECT 'succeeded' AS period_state, to_char(MIN(success_date), 'yyyy-MM-dd') AS start_date
, to_char(MAX(success_date), 'yyyy-MM-dd') AS end_date
FROM (
SELECT a.success_date, success_date - minDate - rn AS groupId
FROM (
SELECT a.success_date, rownum AS rn, MIN(success_date) OVER (ORDER BY success_date) AS minDate
FROM Succeeded a
WHERE a.success_date >= '2019-01-01'
AND a.success_date <= '2019-12-31'
) a
) a
GROUP BY a.groupId
) a
ORDER BY a.start_date
######找连续区间
表:Logs
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| log_id | int |
±--------------±--------+
id 是上表的主键。
上表的每一行包含日志表中的一个 ID。
后来一些 ID 从 Logs 表中删除。编写一个 SQL 查询得到 Logs 表中的连续区间的开始数字和结束数字。
将查询表按照 start_id 排序。
查询结果格式如下面的例子:
Logs 表:
±-----------+
| log_id |
±-----------+
| 1 |
| 2 |
| 3 |
| 7 |
| 8 |
| 10 |
±-----------+
结果表:
±-----------±-------------+
| start_id | end_id |
±-----------±-------------+
| 1 | 3 |
| 7 | 8 |
| 10 | 10 |
±-----------±-------------+
结果表应包含 Logs 表中的所有区间。
从 1 到 3 在表中。
从 4 到 6 不在表中。
从 7 到 8 在表中。
9 不在表中。
10 在表中。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/find-the-start-and-end-number-of-continuous-ranges
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
# Write your MySQL query statement below
select Min(b.log_id) start_id,Max(b.log_id) end_id
from
(select l.log_id,if(@last_vaule=-1 or l.log_id-@last_vaule<>1,@group_id:=@group_id+1,@group_id) group_id,@last_vaule:=l.log_id
from Logs l,(select @last_vaule:=-1,@group_id:=0) a) b
group by b.group_id