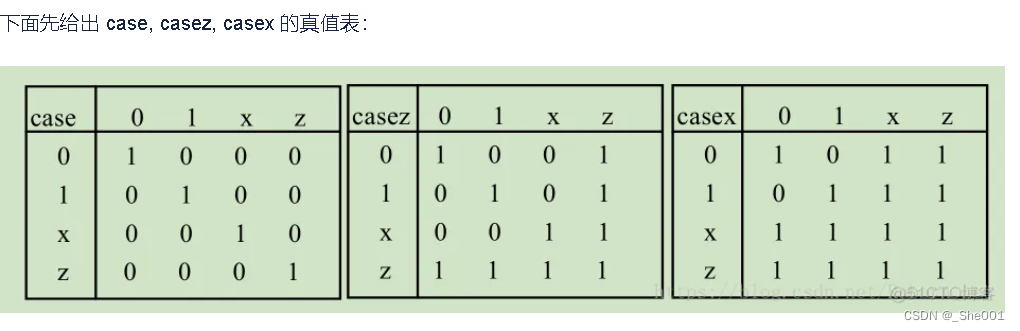
KindEditor是一个轻量级的富文本编辑器,应用于浏览器客户端。
一、首先是下载:http://kindeditor.net/down.php,如下图

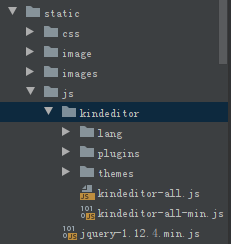
下载后是
解压缩后:

红框选中的都可以删除到,这些主要是针对不同的语言编写的示例,因为我们要在Python中使用,所以这些都没用,lang目录下是语言支持,plugins是扩展插件,themes是主题样式,即CSS文件,kindeditor-all.js是这个框架的源代码,后跟min的是压缩过的,适合于实际项目,主要是减少文件大小,减少传输量。
在我们的Django项目中的static目录下创建js/kindeditor目录,将上述红框以外的部分拷贝到刚创建的目录下:
二、编写网页,使用kindeditor编辑器,页面editor.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="/static/js/kindeditor/kindeditor-all-min.js"></script>
<script src="/static/js/kindeditor/lang/zh-CN.js"></script>
<script src="/static/js/kindeditor/themes/default/default.css"></script>
</head>
<body>
<div>
<h1>KindEditor演示</h1>
<hr/>
{{ con | safe }}
<hr/>
<img src="/static/images/video/p1.png" height="40" width="100%" />
</div>
<form method="post">
<h2>请输入内容:</h2>
{% csrf_token %}
<div style="width: 700px;margin: 10px 30px 0 0">
<textarea name="content" id="editor_id"></textarea>
</div>
<input type="submit" value="提交" />
</form>
<script>
var options = {
width:'100%',
height:'400px',
uploadJson:'/kind/upload_img/', // 文件上传处理路径
extraFileUploadParams:{
'csrfmiddlewaretoken':'{{ csrf_token }}'
},
fileManagerJson:'/kind/file_manager/',
allowImageUpload:true,
allowPreviewEmoticons: true,
}
KindEditor.ready(function (K) {
window.editor = K.create("#editor_id",options);
});
</script>
</body>
</html>三、编写路由项:
path('editor/',views.editor,name="editor"),
四、编写视图函数views.editor:
def editor(request):
CONTENT = "默认值"
if request.method == "POST":
content = request.POST.get('content')
CONTENT = content
print(CONTENT)
return render(request,'editor.html',{'con':CONTENT})添加图片上传处理的路由项,即KE的uploadJson:'/kind/upload_img/'选项定义的路由项/kind/upload_img/
path('kind/upload_img/',views.upload_img,),
五、编写处理函数views.upload_img:
def upload_img(request):
'''
文件上传
:param request:
:return:
'''
import os
dic = {
'error':0,
'url':'/static/images/video/p1.png',
'message':'错误了。。。'
} # 这是返回给前端KE的结果,如果error为0,表示没有错误,然后图片保存的路径就是url的值,否则,上传有错误,返回的是message
obj = request.FILES.get('imgFile') # KE默认上传文件的key是imgFile,可以通过KE的初始化参数filePostName参数设定其他名字
img_path = os.path.join('static/image/',obj.name)
print(img_path)
with open(img_path,'wb') as f:
for chunk in obj.chunks():
f.write(chunk)
dic['url'] = '/'+ img_path
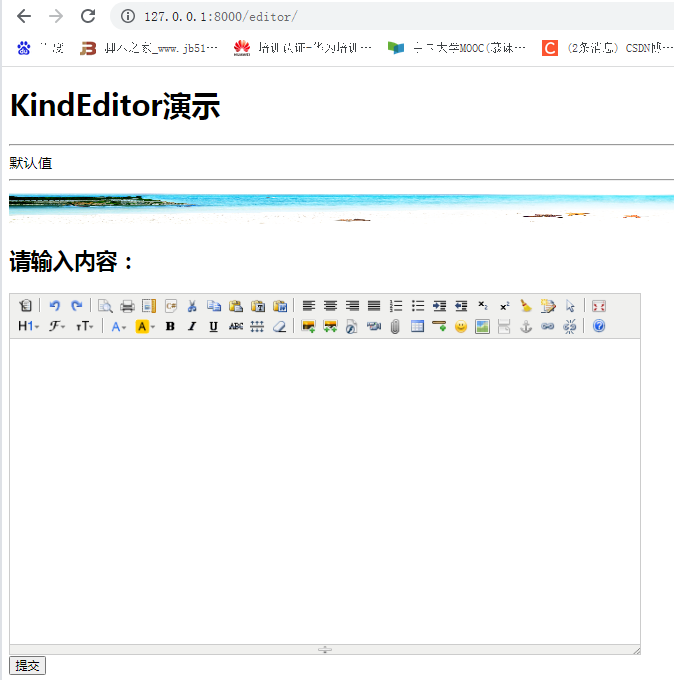
return JsonResponse(dic)在浏览器中访问,http://127.0.0.1:8000/editor/,结果如下
views.editor获得content内容,就是编辑器的全部内容。将此内容保存在数据库中,然后在显示即可。
在同一页面中的显示:

在上面的使用中,如果编辑器做的不够完善,是很容易引起XSS安全的,如在输入内容中包含恶意的脚本代码(前端也可以过滤一下,但是效果有限)。所以,最好是在后台,即views.editor函数中对content进行过滤,排除这些危险的标签或属性。
这里过滤本质上是对html或xml的分析。
爬虫初步-BeautifulSoup4,BeautifulSoup一个可以从HTML或XML文件中提取数据的Python库,它接收一个HTML或XML字符串,然后进行格式化,之后它能够通过你喜欢的解析器实现文档导航,查找,修改文档中的指定元素,使得操作变得简单。
解释器:
对文档的分析,可以使用Python自己的解析器(html.parser),也可以使用专用的第三方库解析器(如lxml)
这里学习BeautifulSoup4和解析器,主要是为了下一步进行网络爬虫的学习,因为网络爬虫爬到的都是HTML代码,需要从中分析提取数据。
安装: pip3 install beautifulsoup4 pip3 install lxml
解释器:
解析器 | 使用方法 | 优势 | 劣势 |
Python标准库 | BeautifulSoup(markup, "html.parser") | Python的内置标准库执行速度适中文档容错能力强 | Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
lxml HTML 解析器 | BeautifulSoup(markup, "lxml") | 速度快文档容错能力强 | 需要安装C语言库 |
lxml XML 解析器 | BeautifulSoup(markup, ["lxml", "xml"]) BeautifulSoup(markup, "xml") | 速度快唯一支持XML的解析器 | 需要安装C语言库 |
html5lib | BeautifulSoup(markup, "html5lib") | 最好的容错性以浏览器的方式解析文档生成HTML5格式的文档 |
学习测试:
from bs4 import BeautifulSoup
from bs4.element import Tag,NavigableString
html_doc ='''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="/static/js/kindeditor/kindeditor-all-min.js"></script>
<script src="/static/js/kindeditor/lang/zh-CN.js"></script>
<script src="/static/js/kindeditor/themes/default/default.css"></script>
</head>
<body>
<a href="#">ok-=tag-a1</a>
<div style="color:red;" class='myc'>
<h1>KindEditor演示</h1>
<hr/>
默认值
<hr/>
</div>
<a href="#" class=“a2”>ok-=tag-a2</a>
<form method="post">
<h2>请输入内容:</h2>
<input type="hidden" name="csrfmiddlewaretoken" value="MQj3AaoGY0csIOLSG5kyGTvqWkGpt5PEzs3eL8Zv7hhhjpdC8C0yxZI1PROK4xJI">
<div style="width: 700px;margin: 10px 30px 0 0">
<textarea name="content" id="content"></textarea>
</div>
<input type="submit" value="提交" />
</form>
</body>
</html>
'''
# 使用BeautifulSoup,先生成一个object
soup = BeautifulSoup(html_doc,features="html.parser")
#找到第一个a标签
tag = soup.find(name='a')
print(tag) # 结果: <a href="#">ok-=tag-a1</a>
#循环打印出所有的标签
for tag in soup.html.children:
print("==>",tag) # 这里要注意,html标签后的空格,回车换行都算是html标签的一个孩子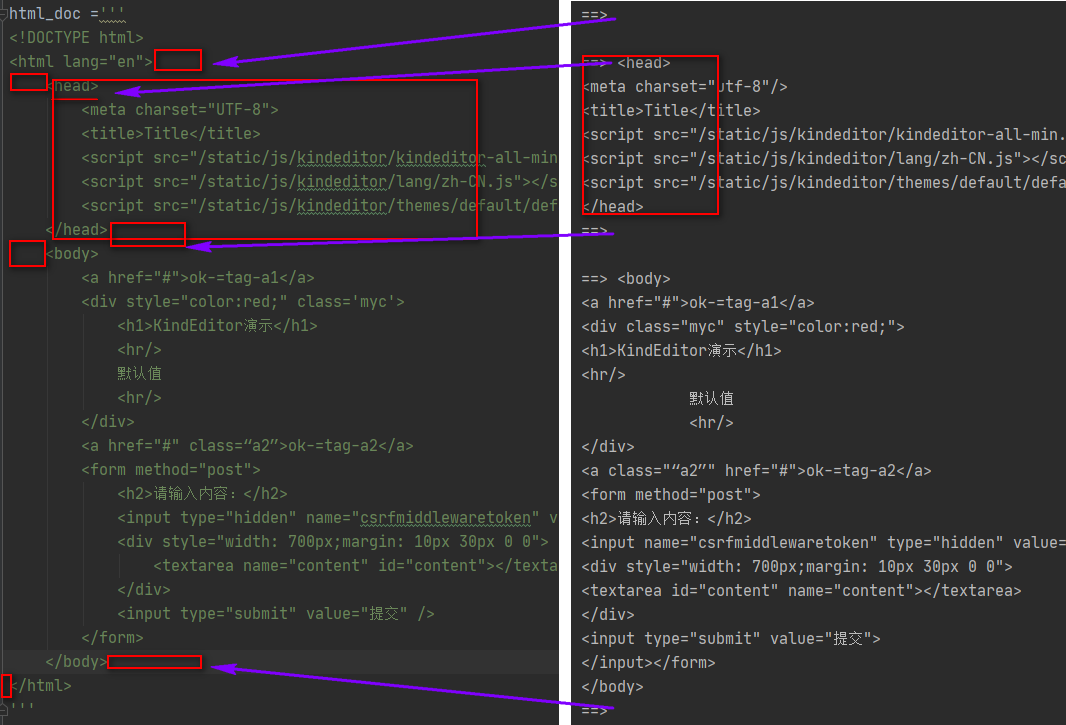
注意,打印出的空行,都是对应的小红框。
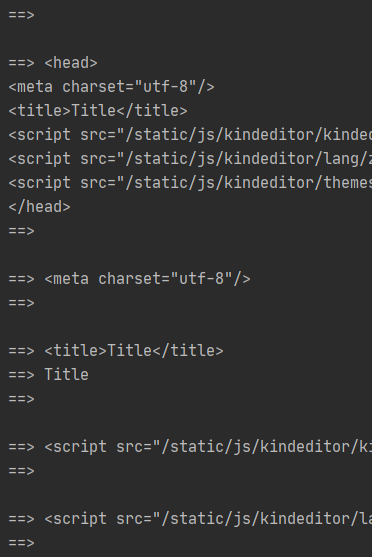
for tag in soup.html.descendants:
print("==>",tag)打印所有的孩子,即子子孙孙都打印出,孩子,孩子的孩子。。。都一一列出,看打印结果,会出现很多重复的内容,看打印的部分内容
标签名字:name
for tag in soup.html.descendants:
print("==>",tag.name)
标签属性:attrs
for tag in soup.html.descendants:
print("==>",tag.attrs)对于一些None的标签,会出现:AttributeError: 'NavigableString' object has no attribute 'attrs'错误,即如果标签没有属性,就会报此错误。
# 标签属性测试,进行判断
from bs4.element import Tag
from bs4.element import NavigableString
for tag in soup.html.descendants:
if isinstance(tag,Tag): # 判断是否是标签
print("==>",tag.name,tag.attrs) # 打印的标签名字是None,其不是Tag,即不是标签,无属性
tag1 = soup.find(name='a')
print(tag1)
del tag1.attrs['href'] # 删除属性
print(tag1)
清空标签内容,clear
tag1 = soup.find(name='a')
print(tag1)
tag1.clear() # 清空内容
print(tag1)
清空标签,hidden
上面的clear只清空标签内的内容,标签本身还在,hidden则将标签本身清除,而标签内的内容还在。
tag1 = soup.find('div')
print(tag1)
tag1.clear()
print(tag1)
tag1.hidden = True
print(tag1)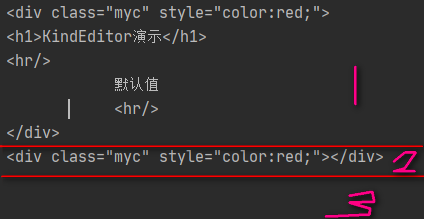
对kindeditor编辑器上传的内容进行过滤,使用类实现。使用单例模式
from bs4 import BeautifulSoup
class XSSFilter: # 单例模式
__instance = None
def __init__(self):
# XSS白名单
self.valide_tags = {
"font":['color','size','face','style'],
"b":[],
"div":[],
"span":[],
"a":['href','target','name'],
"img":['src','alt','title'],
"p":['align'],
"pre": ['class'],
"hr": ['class'],
"strong": []
}
def __new__(cls, *args, **kwargs):
'''
单例模式
:param cls
:param args:
:param kwargs:
:return:
'''
if not cls.__instance:
obj = object.__new__(cls, *args, **kwargs)
cls.__instance = obj
return cls.__instance
def process(self,content):
soup = BeautifulSoup(content,'lxml')
# 遍历所有HTML标签
for tag in soup.find_all(recursive=True):
# 判断标签名是否在白名单中
if tag.name not in self.valide_tags:
tag.hidden = True # 不在白名单,标签本身先去掉
# lxml解析器会将不含html和body的内容增加上这两个标签,所以要去掉,不要造成嵌套
# html.parser不会自动添加html和body
if tag.name not in ['html','body']:
tag.hidden = True
tag.clear()
continue
# 当前标签的所有属性白名单,即在白名单中的标签,进行属性处理
attr_rules = self.valide_tags[tag.name]
keys = list(tag.attrs.keys())
for key in keys:
if key not in attr_rules:
del tag[key]
return soup.decode()