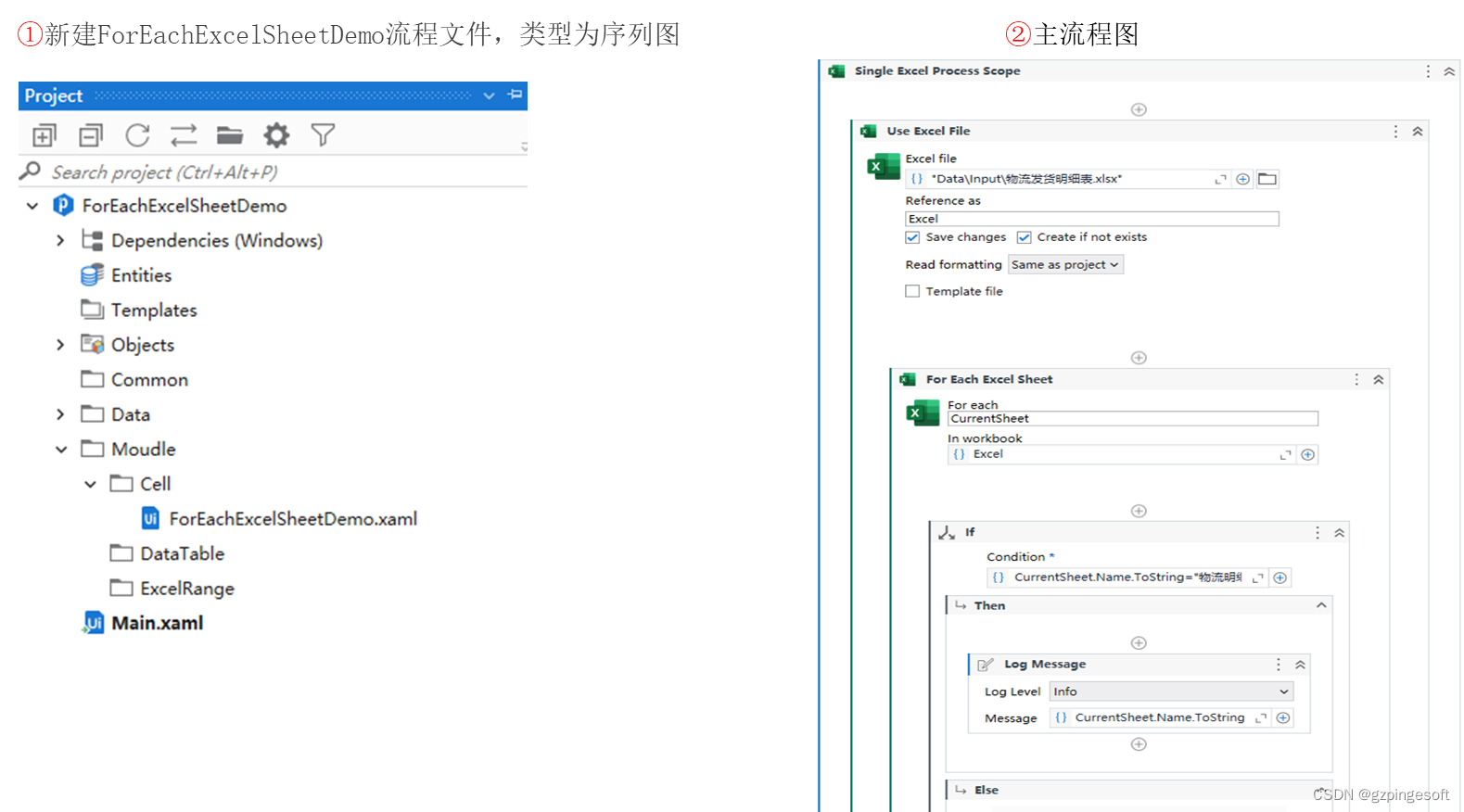
万字长文:Stable Diffusion 保姆级教程
2022年绝对是人工智能爆发的元年,前有 stability.ai 开源 Stable Diffusion 模型,后有 Open AI 发布 ChatGPT,二者都是里程碑式的节点事件,其重要性不亚于当年苹果发布iPhone,Google推出Android。它们让AI不再是一个遥不可及的技术名词,而是触手可及、实实在在的智能应用工具。
不同于ChatGPT可以直接体验,Stable Diffusion需要自己部署后才能使用,所以国内了解的人还不多。但Stable Diffusion绝对是AI图像生成领域的ChatGPT级的杀手产品——它使用超级简单、完全开源免费,生成的图片以假乱真、震惊四座。今天,我将用万字保姆级教程教你如何一步一步在本地运行起Stable Diffusion,并手把手教你如何生成以假乱真的AI生成图片。
文章目录
- 什么是Stable Diffusion
- 核心概念
- 自动编码器
- U-Net
- 文本编码器
- 推理过程
- 快速体验Stable Diffusion
- 1. Dream Studio
- 2. Replicate
- 3. Playground AI
- 4. Google Colab
- 5. BaseTen
- 本地部署Stable Diffusion
- 系统配置需求
- 环境准备
- 安装Git
- 安装Python
- 配置国内源
- 安装Stable Diffusion Web Ui
- 模型安装
- 使用Stable Diffusion Web Ui
- 界面介绍
- txt2img
- img2img
- 界面汉化
- prompt语法
- 示例
- 模型
- Prompt
- Negative prompt
- 参数设置
- 生成
- Stable Diffusion资源列表
- 1. Hugging Face
- 2. Civitai
- 3. Discord
- 4. Rentry for SD
什么是Stable Diffusion
Stable Diffusion是一种潜在扩散模型(Latent Diffusion Model),能够从文本描述中生成详细的图像。它还可以用于图像修复、图像绘制、文本到图像和图像到图像等任务。简单地说,我们只要给出想要的图片的文字描述在提Stable Diffusion就能生成符合你要求的逼真的图像!
Stable Diffusion将“图像生成”过程转换为逐渐去除噪声的“扩散”过程,整个过程从随机高斯噪声开始,经过训练逐步去除噪声,直到不再有噪声,最终输出更贴近文本描述的图像。这个过程的缺点是去噪过程的时间和内存消耗都非常大,尤其是在生成高分辨率图像时。Stable Diffusion引入潜在扩散来解决这个问题。潜在扩散通过在较低维度的潜在空间上应用扩散过程而不是使用实际像素空间来减少内存和计算成本。
与DALL·E和Midjourney相比,Stable Diffusion最大的优势是开源,这就意味着Stable Diffusion的潜力巨大、发展飞快。Stable Diffusion已经跟很多工具和平台进行了集成,且可用预训练模型数量众多(参见Stable Diffusion资源列表)。正是由于社区的活跃,使得Stable Diffusion在各种风格的图像生成上都有着出色的表现,随便给大家看几张我生成的图片:
 |  |  |
 |  |  |
 |  |  |
核心概念
为了方便大家更好地理解后面的内容,下面对Stable Diffusion中的几个核心概念做简单的说明。Stable Diffusion的详细原理请参考《Stable Diffusion原理详解》。
自动编码器
自动编码器 (VAE) 由两个主要部分组成:编码器和解码器。编码器会将图像转换为低维潜在表示(像素空间–>潜在空间),该表示将作为输入传递给U_Net。解码器做的事情刚好相反,将潜在表示转换回图像(潜在空间–>像素空间)。

U-Net
U-Net 也由编码器和解码器组成,两者都由 ResNet 块组成。编码器将图像表示压缩为较低分辨率的图像,解码器将较低分辨率解码回较高分辨率的图像。

为了防止 U-Net 在下采样时丢失重要信息,通常在编码器的下采样 ResNet 和解码器的上采样 ResNet 之间添加快捷连接。
此外,Stable Diffusion 中的 U-Net 能够通过交叉注意力层调节其在文本嵌入上的输出。 交叉注意力层被添加到 U-Net 的编码器和解码器部分,通常在 ResNet 块之间。
文本编码器
文本编码器会将输入提示转换为 U-Net 可以理解的嵌入空间。一般是一个简单的基于Transformer的编码器,它将标记序列映射到潜在文本嵌入序列。

好的提示(prompt)对输出质量直观重要,这就是为什么现在大家这么强调提示设计(prompt design)。提示设计就是要找到某些关键词或表达方式,让提示可以触发模型产生具有预期属性或效果的输出。
推理过程
Stable Diffusion的大致工作流程如下:
首先,Stable Diffusion模型将潜在种子和文本提示作为输入。 然后使用潜在种子生成大小为 64×64 的随机潜在图像表示,而文本提示通过 CLIP 文本编码器转换为 77×768 的文本嵌入。
接下来,U-Net 以文本嵌入为条件迭代地对随机潜在图像表示进行去噪。 U-Net 的输出是噪声残差,用于通过调度算法计算去噪的潜在图像表示。 调度算法根据先前的噪声表示和预测的噪声残差计算预测的去噪图像表示。这里可选用的调度算法很多,每个算法各有优劣,对Stable Diffusion来说建议用以下几个:
- PNDM scheduler(默认)
- DDIM scheduler
- K-LMS scheduler
去噪过程重复大约 50 次以逐步检索更好的潜在图像表示。 完成后,潜在图像表示由变分自动编码器的解码器部分解码。
整体流程可以用下面的流程图表示:

快速体验Stable Diffusion
如果你不想自己搭建Stable Diffusion环境,或者你想在自己动手部署Statble Diffusion之前,先体验一下Stable Diffusion的威力,可以尝试如下5个免费的工具:
1. Dream Studio
DreamStudio 是Stable Diffusion的创造者Stability AI的官方网络应用程序。

最大的优势是官方出品,支持stability.ai旗下的所有模型,包括最新发布的Stable Diffusion v2.1。

用Dream Studio生成图片需要消耗积分,注册是会免费赠送积分,用来体验基本够用。如果想生成更多图片可以花10美元购买积分,大约可以生成1000张图片。
2. Replicate
Replicate是一个机器学习模型共享平台,你可以通过API来分享或使用上面的模型。
大神cjwbw在Replicate上共享了Stable Diffusion v2.0模型,你可以免费测试。

3. Playground AI
Playground AI是一个专注AI图像生成的网站,功能丰富、模型众多。最近也上线了最新的Stable Diffusion v2.1,可以免费使用,但限制每个用户每天最多生成1000张图片。

4. Google Colab
如果你是数据工程师或算法工程师,可能你更希望在Jupyter Notebook中使用Stable Diffusion。Anzor Qunash在Google Colab上共享了Stable Diffusion 2.0 Colab(已更新到2.1),你可以直接复制过来使用。

该Notebook用gradio搭建了界面,只需点击运行按钮,就会显示Gradio UI界面。然后,您就可以在上面生成任意数量的图像,并且可以调节参数,控制生成效果。
5. BaseTen
Baseten是一个MLOps平台,用于创业公司在生产阶段快速开发、部署和测试模型。BaseTen最近发布了对Stable Diffusion的API支持,并提供了一个演示页面。

这个工具非常简单,只有一个文本框和一个生成按钮,没有其他参数可以调节,也没有生成数量的限制。
本地部署Stable Diffusion
本地部署Stable Diffusion最简单的方法是使用Stable Diffusion Web Ui。
Stable Diffusion Web Ui是一套无代码、可视化的Stable Diffusion集成运行环境。它将Stable Diffusion的安装部署集成打包,提供一键安装脚本,并提供Web界面操作界面,极大简化了Stable Diffusion的操作和使用,让没有不懂代码的小白也能轻松上手使用Stable Diffusion模型。

系统配置需求
Stable Diffusion还是比较吃资源的,因此对基础硬件有一定要求。
- NVIDIA GPU 至少 4GB 显存
- 至少 10GB 可用硬盘空间
上面的配置是Stable Diffusion运行起来的基础要求,如果想要生成速度快,显卡配置自然是越高越好,显存最好也上到8G。推荐配置最好不低于:
- NVIDIA RTX GPU 至少 8GB 显存
- 至少 25GB 可用硬盘空间
如果本地机器配置达不到,可以考虑用云虚拟主机。目前最经济的是AWS的g4dn.xlarge,¥3.711元/小时。
环境准备
Stable Diffusion Web Ui用Python开发,完全开源,因此在运行Stable Diffusion Web Ui前,我们需要安装Git来拉取Stable Diffusion Web Ui源代码,并安装Python。
安装Git
Git是一个开源的分布式版本控制系统。这里安装Git是为了获取Stable Diffusion Web Ui的代码。当然,如果不安装Git,我们也可以通过代码打包下载链接直接下载Stable Diffusion Web Ui的代码,但是这样获取的代码无法后续更新,每次Stable Diffusion Web Ui升级都要重新下载代码覆盖老版本代码。用Git就很方便,可以通过clone命令从代码库获取代码,通过git pull更新到最新版代码。
Git安装很简单,只需到Git下载页面下载对应平台安装包安装即可(Linux发行版一般自带Git可以不用安装)。
Windows用户请注意,安装时在安装配置界面勾选上“Add a Git Bash Profile to Windows Terminal”选项。

安装Python
Python的安装方法有很多,这里推荐大家通过Miniconda来安装。用Miniconda有几个好处:
- 方便创建和管理多个Python虚拟环境。我建议每个Python项目都创建一套自己独立的Python虚拟环境,防止python环境或库版本不对导致代码运行出错。
- Miniconda体积很小,只有conda+python+pip+zlib和一些其他常用的包,小巧灵活。
大家只要到Miniconda下载页面下载对应平台的安装包即可,最新的Miniconda包含Python 3.10.9。
下载完安装包直接双击安装即可(Linux版本在Shell中运行下载下来的shell脚本)。Windows用户请注意,当看到下面界面时,请务必勾选第一个选项,将Miniconda添加到环境变量PATH中。

配置国内源
由于 Python 第三方库的来源是国外源,使用国内网络安装库时会出现下载缓慢、卡顿等现象,不仅耽误时间,而且很容易安装失败。因此我们需要将 conda 的安装源替换成国内镜像,这样可以大幅提升下载速度,提高安装成功率。这里推荐清华源,执行下方命令即可添加:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
添加成功后可以通过conda config --show-sources查看当前源
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- defaults
show_channel_urls: True
除了清华源,还可以添加中科大源或阿里云源
中科大的源
conda config –add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
阿里云的源
conda config --add channels http://mirrors.aliyun.com/pypi/simple/
最后,运行conda clean -i清除索引缓存,保证用的是镜像站提供的索引。
安装Stable Diffusion Web Ui
环境配置好后,我们就可以开始安装Stable Diffusion Web Ui了。
首先从GitHub上下载Stable Diffusion Web Ui的源代码:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
下载完成后,cd stable-diffusion-webui进入Stable Diffusion Web Ui的项目目录,在项目目录里会看到webui.bat和webui.sh这两个文件,这两个文件就是Stable Diffusion Web Ui的安装脚本。
- 如果你是Windows系统,直接双击运行
webui.bat文件 - 如果你是Linux系统,在控制台运行
./webui.sh - 如果你是Mac系统,使用方法跟Linux相同
安装脚本会自动创建Python虚拟环境,并开始下载安装缺失的依赖库。这个过程可能会有点久,请耐心等待。如果中途安装失败,多半是网络连接超时,此时可以重新执行安装脚本,脚本会接着上次的下载安装位置继续安装。直到看到
Running on local URL: http://127.0.0.1:7860
说明Stable Diffusion Web Ui安装成功。
用浏览器打开http://127.0.0.1:7860就会看到Stable Diffusion Web Ui的界面。

模型安装
Stable Diffusion Web Ui安装过程中会默认下载Stable Diffusion v1.5模型,名称为v1-5-pruned-emaonly。如果想用最新的Stable Diffusion v2.1,可以从Hugging Face上下载官方版本stabilityai/stable-diffusion-2-1。下载后将模型复制到models目录下的Stable-diffusion目录即可。完成后点击页面左上角的刷新按钮,即可在模型下拉列表中看到新加入的模型。

除了标准模型外,Stable Diffusion还有其他几种类型的模型,models目录下每一个子目录就是一种类型的模型,其中用的最多的是LoRA模型。
LoRA(Low-Rank Adaptation)模型是小型稳定扩散模型,可对标准模型进行微调。它通常比标准模型小10-100倍,这使得LoRA模型在文件大小和训练效果之间取得了很好平衡。LoRA无法单独使用,需要跟标准模型配合使用,这种组合使用方式也为Stable Diffusion带来了强大的灵活性。
LoRA模型下载后需要放到Lora目录中,使用时在提示中加入LoRA语法,语法格式如下:
<lora:filename:multiplier>
filename是LoRA模型的文件名(不带文件后缀)
multiplier 是LoRA 模型的权重,默认值为1,将其设置为 0 将禁用该模型。
关于Stable Diffusion提示的使用规则请参考这里。
使用Stable Diffusion Web Ui
界面介绍
Stable Diffusion Web Ui整体上分为2个部分,最上面是模型选择,可以从下拉列表中选择已下载的预训练模型
模型选择下面是一个Tab栏,这里是Stable Diffusion Web Ui提供的所有功能。

- txt2img — 根据文本提示生成图像;
- img2img — 根据提供的图像作为范本、结合文本提示生成图像;
- Extras — 优化(清晰、扩展)图像;
- PNG Info — 显示图像基本信息
- Checkpoint Merger — 模型合并
- Train — 根据提供的图片训练具有某种图像风格的模型
- Settings — 系统设置
平时使用最多的是txt2img 和 img2img,下面针对这2大块功能详细讲解。
txt2img
txt2img有三个区域:
- 提示区
- 参数调节区
- 输出浏览区

提示区主要是2个文本框,可以输入提示文本。其中:
prompt: 主要是对于图像进行描述。prompt对Stable Diffusion图像生成质量至关重要,因此如果想生成高质量图片,一定要在提示设计上下功夫。一个好的提示需要详细和具体,后面会专门讲解如何设计一个好的提示。
Negative prompt:主要是告诉模型我不想要什么样的风格或元素;
参数调节区提供了大量参数用于控制和优化生成过程:
Sampling method:扩散去噪算法的采样模式,不同采样模式会带来不一样的效果,具体需要在实际使用中测试;
Sampling steps:模型生成图片的迭代步数,每多一次迭代都会给 AI 更多的机会去对比 prompt 和 当前结果,从而进一步调整图片。更高的步数需要花费更多的计算时间,但却不一定意味着会有更好的结果。当然迭代步数不足肯定会降低输出的图像质量;
Width、Height:输出图像宽高,图片尺寸越大越消耗资源,显存小的要特别注意。一般不建议设置的太大,因为生成后可以通过 Extras 进行放大;
Batch count、 Batch size:控制生成几张图,前者计算时间长,后者需要显存大;
CFG Scale:分类器自由引导尺度,用于控制图像与提示的一致程度,值越低产生的内容越有创意;
Seed:随机种子,只要种子一样,参数和模型不变,生成的图像主体就不会剧烈变化,适用于对生成图像进行微调;
Restore faces:优化面部,当对生成的面部不满意时可以勾选该选项;
Tiling:生成一张可以平铺的图像;
Highres. fix:使用两个步骤的过程进行生成,以较小的分辨率创建图像,然后在不改变构图的情况下改进其中的细节,选中该选项会有一系列新的参数,其中重要的是:
Upscaler:缩放算法;
Upscale by:放大倍数;
Denoising strength:决定算法对图像内容的保留程度。0什么都不会改变,1会得到一个完全不同的图像;
img2img
img2img跟txt2img界面类似,不同的是没有了txt2img中的参数调节区,取而代之的是图像范本区。

我们可以上传范本图片让Stable Diffusion模仿,其他地方跟txt2img相同
界面汉化
通过这里下载简体中文语言文件,下载完成后将其复制到项目文件夹的“localizations”目录中。之后在Settings -> User interface -> Localization (requires restart),在下拉菜单中选择zh_CN。如果下拉列表中看不到zh_CN,请先点击右侧的刷新按钮,然后就能在下拉列表中看到了。设置完成后记得点击页面上方的“Apply settings”按钮保存设置。

语言设置需要重启才能生效。Ctrl + C先终止Stable Diffusion Web Ui服务,然后再运行webui.bat或webui.sh,重启后刷新浏览器页面就能看到语言变成了简体中文了。

⚠注意:该汉化可能不完美,个别地方会漏汉化或汉化表达不准确,欢迎大家反馈错误和优化建议。有能力的朋友建议用英文界面。
prompt语法
为了产生具有特定风格的图像,必须以特定格式提供文本提示。 这通常需要添加提示修饰符或添加更多关键字或关键短语来实现。下面为大家介绍一下Stable Diffusion的prompt语法规则。
Stable Diffusion提示文本中的关键字或关键短语通过半角逗号分割,一般越靠前权重越高。我们可以通过提示修饰符来认为修改权重。
- (tag):增加权重5%
- [tag]:降低权重5%
- (tag: weight):设置具体权重值
括号可以嵌套使用,例如:(tag)的权重为 1 × 1.05 = 1.05 1 \times 1.05 = 1.05 1×1.05=1.05,((tag))的权重为 1 × 1.05 × 1.05 = 1.1025 1 \times 1.05 \times 1.05 = 1.1025 1×1.05×1.05=1.1025。同理[tag]的权重为 1 1.05 = 0.952 \frac{1}{1.05} = 0.952 1.051=0.952,[[tag]]的权重为 1 1.0 5 2 = 0.907 \frac{1}{1.05^2} = 0.907 1.0521=0.907 。
-
[tag1 | tag2]:将tag1和tag2混合;
-
{tag1 | tag2 | tag3}:从标签集合中随机选择一个标签;
-
[tag1 : tag2 : 0.5 ]:表示先用tag1生成,当生成进程到50%时,改用tab2生成;如果输入整数的话表示步长,比如10,意思是生成10步后改用tag2;
-
<lora:filename:multiplier>:LoRA模型引用语法
示例
模型
这里我将使用chilloutmix + KoreanDollLikeness生成写实风韩系偶像小姐姐。
首先需要下载chilloutmix模型(我用的是chilloutmix_NiPrunedFp32Fix.safetensors),将其拷贝到Stable-diffusion目录,还需要下载KoreanDollLikeness这个LoRA模型,将其拷贝到Lora目录。
然后在Stable Diffusion Web Ui主界面的模型选择中下拉选择chilloutmix_NiPrunedFp32Fix.safetensors。如果找不到该模型,可以点击右侧刷新按钮刷新一下。
Prompt
选择好模型后,我们开始设计prompt。首先我们引入LoRA
<lora:koreanDollLikeness_v10:0.66>
然后定义生成图片的风格,我们希望超写实风,可以用如下关键词:
best quality, ultra high res, (photorealistic:1.4)
其中photorealistic我们赋予较高的权重1.4。
接着来定义图片的主体内容,这里我将希望图片中出现的元素都做个权重增强:
1girl, thighhighs, ((school uniform)),((pleated skirt)), ((black stockings)), (full body), (Kpop idol), (platinum blonde hair:1), ((puffy eyes))
最后,修饰一些表情、姿势的细节:
smiling, solo focus, looking at viewer, facing front
这样我们完整的promt是:
<lora:koreanDollLikeness_v10:0.66>, best quality, ultra high res, (photorealistic:1.4), 1girl, thighhighs, ((school uniform)),((pleated skirt)), ((black stockings)), (full body), (Kpop idol), (platinum blonde hair:1), ((puffy eyes)), smiling, solo focus, looking at viewer, facing front
Negative prompt
我们还需要提供Negative prompt去除我们不想要的风格和元素:
paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glan
这里主要剔除了绘画风、简笔画、低质量、灰度图,同时去除雀斑、痤疮等皮肤瑕疵。
参数设置
为了让图片生成得更加真实自然,我们需要对参数做一些调整,需要调整的参数如下:
- Sampler: DPM++ SDE Karras
- Sample Steps: 28
- CFG scale: 8
- Size: 512x768
这里鼓励大家多尝试其他取值,上面只是我认为效果最好的一组参数。
生成
完成上面所有设置后,就可以点击Generate按钮生成图片了。生成速度由你的设备性能决定,在我的电脑上大约30s生成一张图片。
Stable Diffusion资源列表
好的生成质量离不开好的模型,这里为大家列出了Stable Diffusion预训练模型资源的获取来源。
1. Hugging Face
Hugging Face是一个专注于构建、训练和部署先进开源机器学习模型的网站。
HuggingFace是Stable Diffusion模型创作的首选平台,目前平台上有270多个与Stable Diffusion相关的模型,用"Stable Diffusion"作为关键字就能搜到。

推荐Dreamlike Photoreal 2.0这个模型,这是一个由Dreamlike.art制作的基于Stable Diffusion v1.5的真实感模型,生成效果非常接近真实照片。

另一个热门模型是Waifu Diffusion,推荐尝试。
2. Civitai
Civitai是一个专为Stable Diffusion AI艺术模型设计的网站。该平台目前有来自250+创作者上传的1700个模型。这是迄今为止我所知的最大的AI模型库。你可以在上面分享自己的模型或生成作品。

3. Discord
在Stable Diffusion的Discord页面中有一个名为“Models-Embeddings”的专属频道,里面提供了很多可以免费下载的各种模型。

4. Rentry for SD
Rentry网站上有一个保存Stable Diffusion模型的页面sdmodels,上面由70多个模型可以免费下载。

使用这些模型资源的时候要注意:下载自定义AI模型会带来危险。例如,某些可能包含NSFW(不安全)内容。
另一个风险是,这些自定义AI模型可能包含恶意代码或恶意脚本,特别是CKPT文件。如果想要更安全地使用AI模型,请尽量选择safetensor文件类型。