SpiderFlow爬虫获取网页节点
一、SpiderFlow 文档地址:https://www.spiderflow.org/
二、问题:获取一篇文章的标题、来源、发布时间、正文、下载附件该怎么获取?
举例:【公示】第三批智能光伏试点示范名单公示

三、抓取网页步骤(简单版,分页、循环、多分支暂不涉及,具体看文档)
1.设置抓取网页链接
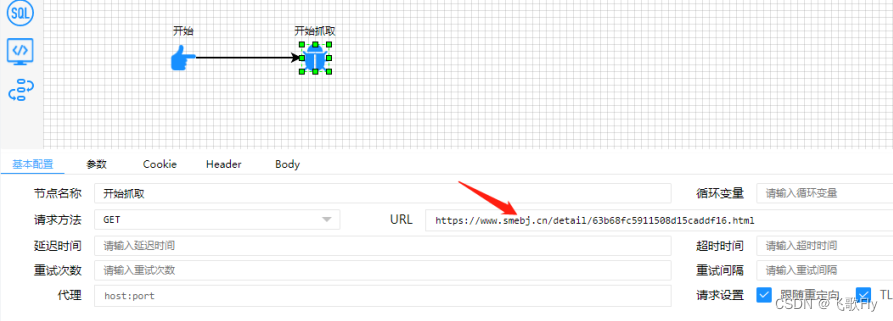
2.设置参数,如果需要设置参数的话(上面例子不需要参数)

3.执行抓取
抓取后返回抓取结果,结果默认就叫resp。可以在Var变量中定义具体的数值,定义的变量后面的流程都可以使用,使用方法为${变量名},此时定义了一个变量叫responseData,这个变量代表resp.html

- resp都有什么?
resp.html 为页面的HTML
resp.json 为json结果
具体区分看下图,文档地址:https://www.spiderflow.org/course/variable.html#%E7%88%AC%E5%8F%96%E7%BB%93%E6%9E%9C
4.输出结果,检查返回的结果是否正确

可以看到在测试窗口中已经展现了resp.html完整的页面结构,也就是 在浏览器中 按F12看到的前端页面完整的节点结构
四、要获取标题、公示时间、地址、正文等内容还需要学习了解如何获取节点
1.获取节点
(1)抽取函数 extract,文档地址https://www.spiderflow.org/function/extra.html#selector
获取单个节点 使用 selector
获取多个节点使用 selectors
举例 获取 标题

标题只有一个,所有用 selector,可以看到 标题所在的层级如下 #app/.artDetail/.ant-row/.artDetail_content/h2 ,那需不需要一级一级往下找呢?
${extract.selector(resp.html,'#app .artDetail .ant-row .artDetail_content h2')}
答案是不需要,只要能保证父级唯一就行,如果父级不唯一则继续往上找
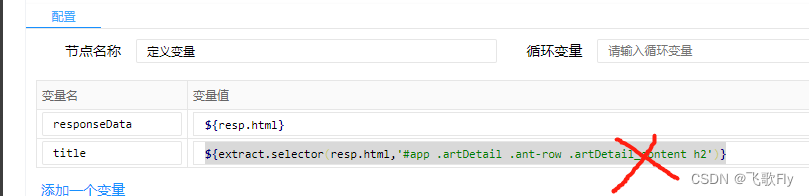
两级就可以
${extract.selector(resp.html,'.artDetail_content h2')}
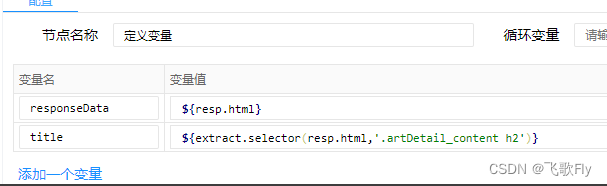
可以看到标题已经输入成功了

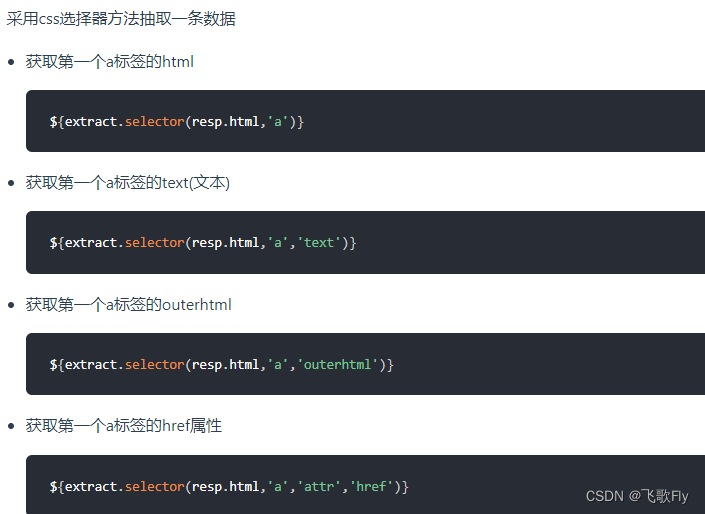
2.获取 html、文本、href链接
3.css 选择器
Css 选择器 包括 元素选择器、类选择器、id选择器、后代选择器、子代选择器等等
具体用法可以参考 css选择器 文档
https://www.runoob.com/cssref/css-selectors.html




![[Openwrt]procd实现hotplug机制介绍](https://img-blog.csdnimg.cn/img_convert/2bf4f636d1c52333ea30e498301762e9.png)