前言
📅大四是整个大学期间最忙碌的时光,一边要忙着准备考研,考公,考教资或者实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
本次分享的课题是
🎯远程监督的跨语言实体关系抽取
课题背景与意义
知识就是力量。使人类及机器能够更好地利用知识是提升工作效率及实现人工智能的关键所在,也催生了包括知识表示、知识推理在内的一系列研究。作为一切对知识的利用的基础,我们首先要获取知识,即知识抽取。
课题实现技术思路
与我们一般通过阅读书籍来获取知识一样,知识抽取的主要数据来源是文本(如新闻、小说、维基百科等)。通常来讲,我们可以直接从文本中获取的知识包含两类:实体 (entity) 和关系 (relation) [1],这也对应了两类知识抽取任务:实体识别 (entity recognition) 和关系抽取 (relation extraction)。下表给出了一个从句子中进行知识抽取的示例。在本文中,我们将主要关注「关系抽取」。
| ID | 文本 | 实体 | 关系 |
|---|---|---|---|
| 1 | 北京是中国的首都,具有悠久的历史。 | 北京,中国 | 首都 |
| 2 | 比尔盖茨是微软的创始人。 | 比尔盖茨,微软 | 创始人 |
| 3 | 合肥位于安徽中部,是安徽省会。 | 合肥,安徽 | 位于,是省会 |
顾名思义,关系抽取的目的就是从文本数据中抽取出关系。直观来讲,关系必然存在于两个(或多个实体)之间,比如在“合肥位于安徽中部”这一文本中,“位于”是“合肥”和“安徽”之间的关系,而撇开实体或者单看某单一实体时不会有关系这一概念的出现。从上表第三个例子又可以看出,”合肥“和”安徽“之间同时具有”位于“和”省会“两个关系,即一个文本中的实体对之间事实上可以存在多个不同的关系。因此,在不考虑发现未知的新关系时,我们可以将关系抽取定义成一个「给定实体对」情况下的「多标签分类」 (multi-label classification) 任务,其中的标签即为实体对之间的关系。
关系抽取的难点
从上一节对关系抽取任务的定义可以看出,要训练一个关系抽取模型,数据中应同时包含对实体对和关系的标注。实体的标注对应了实体识别任务,目前可以通过较为成熟的命名实体识别 (NER) 等技术来进行高质量自动标注。但关系的标注通常较为困难,一些句子中甚至不会显式的出现定义好的关系的相近描述。如“合肥是安徽的省会”一句中事实上是蕴含了“位于”这一关系,但句子中并没有显式地出现“位于”的相关描述,我们需要通过一些人类的常识进行推断。因此,在构建精确标注的关系抽取数据集时,大量人工标注通常是必不可少的,这就导致数据集的构建成本非常高昂。
此外,如 Mintz 等人指出,在特定领域的语料上进行关系标注而训练得到的关系抽取模型通常具有偏置 (bias) [2]。比如,发表于 ACL2020 的一篇文章 [3] 中对关系抽取中存在的性别偏见 (Gender Bias) 进行了讨论,感兴趣的读者可以去读一下这篇文章。
在上文中我们提到了仅利用给定语料上精确标注数据集进行关系抽取模型训练存在的两个问题,即「标注成本高」和存在「偏置」。那么该怎样解决这些问题呢?
标注成本高问题
如果我们继续采用监督学习 (supervised learning) 来对模型进行训练,那这个问题就很难回避。尽管我们可以通过少样本学习 (few shot learning) 等技术来充分利用已有的少量精确标注数据,但这些标注本身就更容易产生偏置,这就会导致第二个问题变得更加突出。
因此,要想从根本上缓解标注成本高问题,我们应该考虑放弃监督学习,转而采用弱监督、无监督,或者探索一种新的学习方式。
偏置问题
偏置问题产生的主要原因是在若干个特定领域的标注语料库上进行训练,因此解决偏置问题最简单粗暴的做法自然是选择覆盖面较广的数据。幸运地是,我们并不缺少这种数据:现在网络、书刊等媒体上充斥着大量文本,这些文本获取成本低且覆盖领域广,如果能够有效利用这些数据,那偏置问题将在很大程度上得到缓解。然而,这些数据又转而面临标注成本高问题。
远程监督
为同时解决以上两个问题,Mintz 等人于 2009 年提出一种能够在未经精确标注的文本上进行关系抽取的新学习框架---「远程监督」 (distant supervision) [2]。
何为远程监督
远程监督通过文本之外的、由大量实体对与关系构成的知识库来对文本进行关系标注。其中,“远程”可以理解为利用了文本之外的知识库,而“监督”可以理解为提供了关系标签(即监督信息)。
远程监督的基本假设
远程监督具有如下假设 [2]:
「如果一对实体之间具有某种关系,那么所有包含这对实体的句子都将表达这个关系的含义。」
因此,对于一个已经识别出某实体对的句子,知识库中所有该实体对之间具有的关系都可以被看成句子的标签。
远程监督的基本流程
从上文介绍中可以看出,利用远程监督进行关系抽取模型的学习,我们只需要收集文本,在文本中识别实体对,然后与知识库中进行比对以标注关系即可。需要注意,根据远程监督的基本假设,实体对之间所有能够成立的关系都会成为句子的标签。其基本流程可用下例来表示。

很明显,远程监督方法极大地扩充了关系抽取能够利用的数据量,其标注成本极低,覆盖面可以极广。如果标注的每个句子都是正确的,那么问题就归结于一个相对较为简单的文本分类任务。
但是,细心的读者可能已经发现了,我们假定存在给定实体对的句子就能表示这对实体之间的所有关系,这势必会「引入错误的标注」。如“合肥”和“安徽”之间同时存在“位于”、“是省会”两个关系,那对于“合肥位于安徽”这一句子,我们也会同时给他标注“位于”和“是省会”两个关系。但很明显,这句话并没有表达”是省会“这一关系的含义。如果模型在这错误的标注上进行训练并将这个模式“记住”,即”A位于B“蕴含了A是B的省会,那在遇到”黄山位于安徽“这一句子时,它就会认为”黄山“和”安徽“之间也具有”是省会“这一关系,这明显是不合理的。因此,利用远程监督进行关系抽取的关键在于「如何消除错误标注样本对模型训练的影响」。
远程监督关系抽取模型
为了消除错误标注样本的影响,远程监督关系抽取模型主要采用了两种方法:错误标注样本「筛除」法和错误标注样本「转正确标注」法。
在本节中,我们将从上述两种方法出发简单介绍几个经典的模型。受篇幅限制,我们在本文中仅介绍这些模型的核心思路,技术细节请参照原文。因此类模型大都考虑句子级文本,在下文中涉及到数据的描述时我们不再对“句子”和“文本”进行区分。
错误标注样本筛除
PCNN
可以设想,在远程监督框架下,如果我们每次都将一个带标注的句子作为模型训练的样本,那甚至可以说训练过程中所使用的大部分样本都是被错误标注的,这将会极大地影响模型在实际应用中的效果。
因此,Zeng 等 在 PCNN [4] 一文中提出将多实例学习 (multi-instance learning) 应用于远程监督中。其采用 expressed-at-least-once [5] 假设:
「当一对实体之间存在某个关系,那么包含这对实体的句子中至少有一个能够表达这个关系。」
在上述假设下,Zeng 等不再将带标注的句子逐个送入模型进行训练,而是将具有相同实体对和关系标注的所有(也可以是一部分,但直观上来讲越多越好)句子看成一个整体,称为「包 (bag)」,然后将标注的关系作为整个包的标签进行训练。如下图
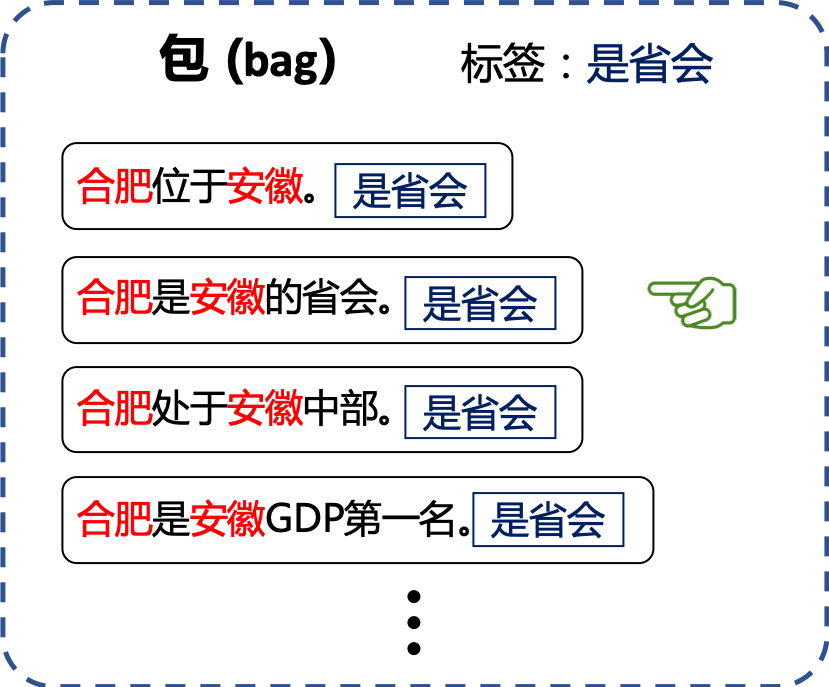
这样一来,即便存在句子是被错误标注为了某关系的,但包中有这么多句子,我们总能找到一个句子是具有这个关系的吧!再退一步,就算包中所有句子都不表达所标注的关系,那结果也不会变得更坏了。因此从整体上来看,错误标注的几率被降低。
显然,接下来的工作就是如何「从包中选择」出那个被正确标注的样本来进行接下来的训练了。PCNN 一文中采取的方式是挑选使得条件概率 p(包的标签|句子) 最大的那个句子作为正确标注样本,具体实现细节在此不再赘述。
其他模型
PCNN 每次只选取包中一个句子作为正确标注样本的做法存在一个问题:如果包中有多个句子是被正确标注的,那么它们中的大部分都将被舍弃,从而造成了数据的浪费。为此,一系列基于「注意力机制」 (attention mechanism) 的模型被提出 [6,7,8],它们通过对包中的句子进行注意力权重的分配来同时选择多个句子。若包中存在多个被正确标注的句子,那么它们的注意力权重都会较高,从而都会在最终关系预测中发挥作用;此外,被正确标注的置信度(即注意力权重)越高,发挥的作用将越大。这种软选择 (soft selection) 机制有效地缓解了 PCNN 中硬选择 (hard selection) 带来的数据浪费问题,从而可能在相同样本量的情况下达到更高的性能。
错误标注样本转正确标注
无论怎样进行样本的筛选,部分确定被错误标注的样本总是可以被看成在数据集中剔除掉了。那么,这些错误标注的样本真的对远程监督关系抽取不起作用吗?(此句借用了 Shang 等论文 [9] 的题目)至少在一些论文的作者看来,答案是否定的。
比如,Shang 等 [9] 利用无监督聚类的方法来为错误标注的样本重新分配新的标签;而 Wu 等 [10] 认为每个句子的现有标注和其应有标注之间存在映射关系,于是通过学习转移矩阵来模拟该映射,进而将每个句子的标注都转换成其应有标注。
通过将错误标注样本转换为正确标注,此类模型在一定程度上扩充了数据量,也为提升关系抽取的质量提供了新的可能性。但要注意的是,转换后的样本标注可能还是错的,有时仍需要进行进一步的筛选。
🚀海浪学长的作品示例:
大数据算法项目
机器视觉算法项目


微信小程序项目
Unity3D游戏项目

最后💯
🏆为帮助大家节省时间,如果对开题选题,或者相关的技术有不理解,不知道毕设如何下手,都可以随时来问学长,我将根据你的具体情况,提供帮助。