压缩 (compression) : 用时间换空间的思想
- 用较小的 CPU 开销获得磁盘少占用或网络 I/O 少传输
Kafka 消息分两层:
- 消息日志组成 : n 个消息集合
- 消息集合 (message set) 组成 : n 条日志项 (record item)
- 日志项封装了消息 (message)
- Kafka 在消息集合层上进行写入操作
消息格式
Kafka 消息格式的引入版本 :
- V0 版本 : Kafka 0.10.0.0 前
- V1 版本 : Kafka 0.10.0.0 后引入
- V2 版本 : Kafka 0.11.0.0 后引入
V0/V1
V0 消息格式 :
- CRC 在每个消息中
- 没有时间戳

V1 消息格式 :
- CRC 依然在每个消息中
- 增加了时间戳 , 记录该消息的事件时间
- attribute 的第4位 : 时间戳类型 : CREATE_TIME (Producer 创建时间) , LOG_APPEND_TIME (Broker 写入时间)

V0/V1的消息集合格式 :
- offset : 该消息的 offset (未压缩) ; 该批消息中最后一条消息的 offset (压缩)
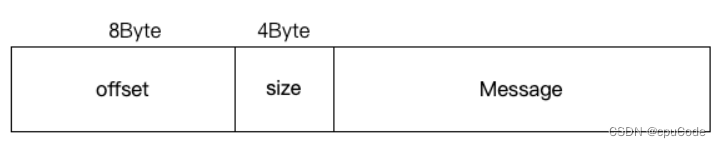
V0/V1的缺点 :
- 空间使用率低 : 固定 4 字节保存 key 或 value 的长度
- 消息总长度未保存 : 要实时计算总字节数
- 只保存最新消息位移 : 压缩后只保留最后一条 offset
- 冗余 CRC 校验 : 每条消息都有 CRC
V2
V2 消息格式 :
- 增加了消息总长度
- 改为可变长的时间增量 (以消息集合中的起始时间戳)
- 去除了 CRC 验证

V2 消息集合格式 :
- 增加 CRC 验证
- 增加支持幂等性及事务的 PID , producer epoch , 序列号

CRC
CRC 校验对比:
- V1 的每条消息都要执行 CRC 校验,当出现 CRC 变化时,对每条消息都执行 CRC 校验 ,会浪费空间还耽误 CPU 时间
- V2 把消息的 CRC 校验移到了消息集合层
CRC 变化情况 :
- Broker 对消息时间戳字段更新时,CRC 值会更新
- Broker 对消息格式转换时 (兼容老版本客户端),CRC 值会变化
压缩
各格式的压缩情况 :
- V1 :把多条消息进行压缩,再保存到外层消息的消息体字段中
- V2 :对整个消息集合进行压缩
V2 / V1 对比 :
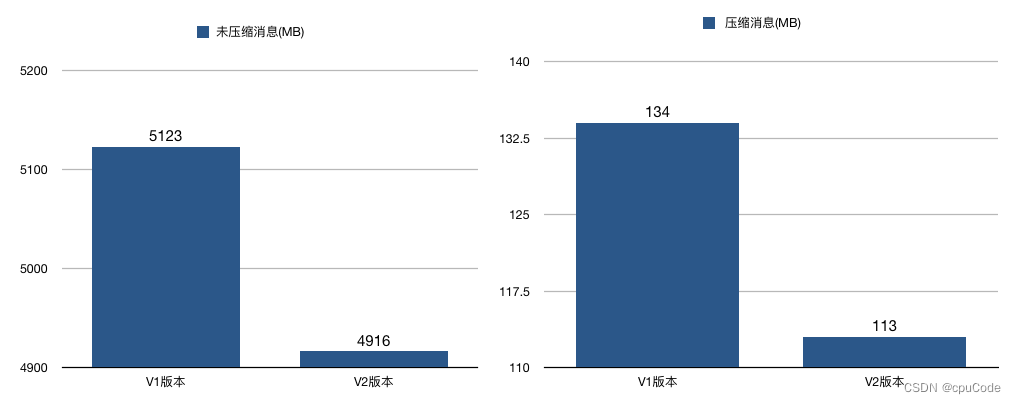
压缩
压缩的地方:生产者端和 Broker 端
- Broker 从 Producer 收到消息后 ,而不会重新压缩 (有特例)
开启 GZIP 的 Producer 对象 :
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//指定 GZIP 压缩
props.put("compression.type", "gzip");
Producer<String, String> producer = new KafkaProducer<>(props);
Broker 重新压缩消息情况 :
- Broker 和 Producer 用不同的压缩算法
- Broker 发生消息格式转换
不同算法 :
- 例子 :Producer 用 GZIP; Broker 用 Snappy
- Broker 接收到 GZIP 压缩消息后,只能解压缩后,用 Snappy 重新压缩一遍
- 不同算法会引发 Broker 端 CPU 使用率飙升
消息格式转换 : 为了兼容老版本的消费者
- Broker 会对新版本消息向老版本格式的转换
- 该过程会对消息的解压缩和重新压缩
- 这种消息格式转换对性能影响很大,失去压缩,Zero Copy 特性
零拷贝 (Zero Copy) :当数据在磁盘和网络进行传输时, 避免昂贵的内核态数据拷贝,而实现快速的数据传输
解压缩
信息压缩流程:
- Producer 发送压缩消息到 Broker 后 ,Broker 原样保存
- 当 Consumer 请求消息时,Broker 原样发送过去
- 当消息到达 Consumer 后,由 Consumer 自行解压成原来消息
Consumer 用那种压缩算法:
- 压缩算法封装在消息集合中,当 Consumer 读取到消息集合时,就得知消息用哪种压缩算法
Broker 端会解压缩 (与消息格式转换不同) :
- 每个压缩过的消息集合在 Broker 写入时,会发生解压缩
- 目的:为了对消息执行各种验证,会提高 CPU 的使用率
京东说明:去掉 Broker 消息校验而引入的解压缩 ,Broker 端的 CPU 使用率减少 50% ( Kafka 2.4 后实现)
压缩算法对比
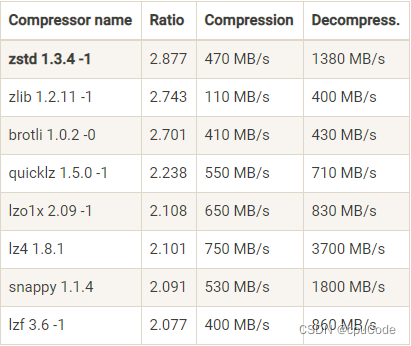
Kafka 2.1.0 前,支持 3 种压缩算法:GZIP、Snappy、LZ4
- 2.1.0 后,支持 Zstandard 算法 (zstd)
压缩算法的指标:
- 压缩比:原 100 空间压缩后占 20 空间,压缩比是 5。压缩比越高越好
- 压缩/解压缩吞吐量:每秒能压缩或解压缩多少 MB。吞吐量越高越好
压缩算法比较:
- 吞吐量:LZ4 > Snappy > zstd 和 GZIP
- 压缩比 : zstd > LZ4 > GZIP > Snappy
- 用 Snappy 占带宽最多,zstd 最少
启用压缩的时机 :
- Producer 的 机器 CPU 充足
- 带宽资源有限。当客户端机器 CPU 吊,建议用 zstd 压缩,能节省网络带宽



![[ 云计算 | Azure ] Episode 03 | 描述云计算运营中的 CapEx 与 OpEx,如何区分 CapEx 与 OpEx](https://img-blog.csdnimg.cn/c4eae026e1aa441e98964d75a7db81e5.png)