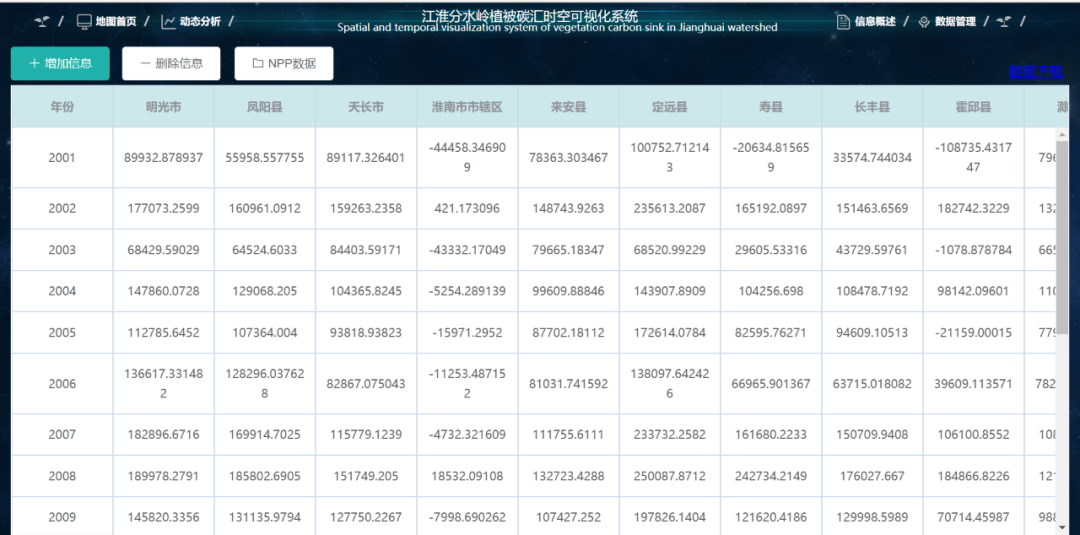
一、论文简述
1. 第一作者:Ao Luo
2. 发表年份:2022
3. 发表期刊:CVPR
4. 关键词:光流、局部注意力、空间关联、上下文关联
5. 探索动机:现有方法主要将光流估计视为特征匹配任务,即学习在特征空间中将相似度高的像素进行匹配。然而,运动理解相关任务的另一个重要组成部分--空间相似性(平滑度约束)被忽视了。
However, most contemporary works address the cross-image matching problem by learning and measuring feature similarities, overlooking another core component for motion understanding — the spatial relations which reveal the underlying affinities during motion.
6. 工作目标:明确地考虑特征相似性和空间关系将有助于建立一个强大的深度模型,可以在更高的层次上理解运动。
Using deep learning techniques to capture and model local relations is challenging.
- First, because the motion of object(s) appears locally in the visual scene, effectively capturing the local relations (affinities) is vital for motion analysis. However, common relation modeling approaches, such as non-local operations and graph reasoning, focus on solving the global or long-range dependencies. How to reasonably model the local relations is still under-explored.
- Second, the local relations should be end-to-end learnable, so as to best mine pairwise relationships described by the affinity value. Third, optical flow estimation is a per-pixel matching task, thus it is difficult to efficiently obtain the pixel-wise relations.
- Last but not the least, the designed module is expected to be easily plugged into contemporary optical flow architectures.
7. 核心思想:本文提出了基于块注意力的光流估计方法(Kernel Patch Attention, KPA),对特征图的每个局部块进行操作,通过显式地利用局部场景内容和空间关系信息来缓解由像素特征匹配困难造成的误差。
- A fully-differentiable approach for explicitly conducting the smooth constraint. To the best of our knowledge, we are the first to explicitly handle the local relations for optical flow based on the context and spatial affinities. We present a kernel-based function to effectively mine local relations and use the mined information to infer the flow fields.
- A novel operator for comprehensive optical flow estimation. We propose kernel patch attention (KPA) operator with a specific patch-based sliding window strategy, which is simple yet effective for reliable motion understanding.
8. 实验结果:通过实验验证该方法可以充分利用局部特征关联性进行更准确的运动分析,在标准光流估计数据集上达到 SOTA 效果。
State-of-the-art results on widely-used benchmarks. The fully-equipped KPA-Flow can reliable infer the optical flow in challenging scenes, which sets new records on both Sintel and KITTI benchmarks with limited extra computational cost.
9.论文&代码下载:
https://openaccess.thecvf.com/content/CVPR2022/papers/Luo_Learning_Optical_Flow_With_Kernel_Patch_Attention_CVPR_2022_paper.pdf
https://github.com/megvii-research/KPAFlow
二、实现过程
1. 方法
给定一对输入的连续图像,即源图像I1和目标图像I2,光流估计的任务是预测源图像I1和目标图像I2之间的密集位移场。基于深度学习的光流网络通常采用编码器-解码器管道,首先提取上下文特征fc和运动特征fm,然后基于这两个特征的组合,以循环/粗到细的方式进行光流预测。
本文提出核块注意力(KPA),并将其插入到特征融合过程中,其表述为fm= FKPA (fc,fm)。具体而言,KPA算子明确地考虑了场景上下文和空间密切性,并利用学习到的特征相关更好地推断光流场。在运动特征改进后,上下文和更新的运动特征被输入到解码器模块中,进行几次残差光流估计。
2. 光流的核块注意力
KPA-Flow结构如图。基于RAFT以循环优化方案开发的模型。“C”表示连接,“×”表示乘法。“CV”表示4D相关体。Dec表示光流解码过程。具体来说,给定一个输入图像对(I1,I2),首先使用两个基于基于6个残差块构建的编码器来提取特征对(f1,f2),上下文编码器与运动编码器共享相同的结构,提取特征fc,输出特征映射的通道维数设置为256。然后,建立4个尺度的4D相关体。基于预定义的搜索窗口,通过在分割的匹配代价上应用运动编码器来获得运动特征fm。
在残差更新方案中,利用运动编码器从匹配代价中获取运动特征fm。上下文特征和运动特征的通道C均设置为128,空间维度为输入形状的1/8。然后将上下文和运动特征输入到所提出的KPA算子中进行特征改进。设置循环迭代N = 12进行训练。

2.1. 基于核函数的定义
基于编码器网络提取的Fc∈c×h×w中的上下文特征fc和Fm∈c×h×w中的运动特征fm,设计KPA从场景上下文中提取特征相关,并将挖掘出的相关作为平滑约束来指导运动特征的学习。具体来说,受图像卷积和点卷积的启发,将KPA表述为基于核的算子,一般为:
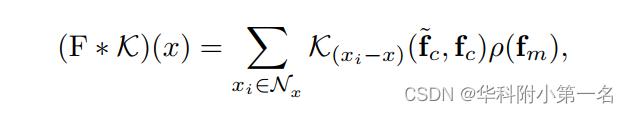
其中xi表示x周围邻域Nx(也称为核窗口)在二维网格空间中的位置i。K(xi−x)(·)是以相邻点作为输入的核函数,ρ(·)是将输入运动特征映射到嵌入空间的线性投影。~fc表示Nx的中心块窗口中的上下文特征。从注意力机制来看,使用~fc生成查询向量,对应的键和值向量可以从Nx中fc和fm嵌入。
核函数是KPA中的核心组件,通常可以定义为:
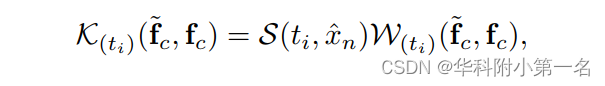
其中ti = xi−x, x^n表示核区域n位置的坐标。然后,S(ti,x^n)表示尺度函数,它根据网格空间中ti和x^n之间的欧氏距离生成尺度图。权函数W(ti)(~fc,fc)用于生成核权重。
类似于广泛使用的二维卷积核,设计W(ti)(·)为ti的每个位置提供不同的权值。然而,与仅仅定义一个可学习矩阵Wi的图像卷积核不同,本文进一步考虑了核区域的上下文关系。具体地说,给定上下文特性~fc和fc,使用归一化的嵌入高斯函数来测量它们之间所有对之间的相关性,可以表示为:
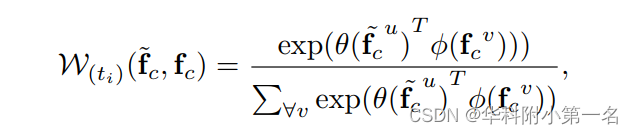
其中θ(f)=Wθf和φ(f)=Wφf是两个线性投影,用于进行特征嵌入。生成的自适应权重的维数为N×K,其中N=h×w表示整个特征图的像素级空间维数,K=K×K表示核窗口的大小。
核函数的另一个分量是尺度函数S(ti,x^n)。在图像卷积中,对于核中的所有位置,标量都简单地设置为1。一个原因是W(ti)(·)的可学习权重可以被训练成适合进行加权和,它固有地包含了所有点的尺度平衡。此外,VGG和ResNet等广泛使用的网络通常倾向于堆栈几个卷积,其核大小为1×1和3×3,因此ti和x^n之间的距离应该很小,不能提供额外的独特信息。相反,单个KPA操作符能够获得一个大的感受野,以覆盖实例级别的信息。因此,它应该配备一个基于ti和x^n之间距离的比例因子掩码,以满足空间限制。具体来说,采用线性相关,将尺度函数表示为:
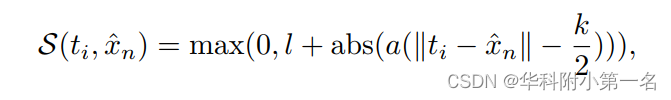
其中k表示核窗口的大小,l是基本标量,a是一个可学习的参数,表示点距离的影响。该函数生成一个标量图,其中每个点的值与欧几里得距离||ti−x^n||成反比。
2.2. 滑动窗口的核块注意力
以往的研究表明,利用全局运动约束进行光流特征改进是一种有效的光流估计策略。但是,直接应用基于上下文特征的非局部方法对运动特征的改进可能会有一些不可靠的指导。
在此,KPA使光流模型有一个合适的感受野来平滑约束运动特征,并避免来自远距离上下文的误导信息。具体来说,设计了一种基于滑动窗口的运动特征平滑方案。给定特征图f∈c×h×w,首先将其分割成不重叠的块,每一个大小为p×p的块视为一个特征组。因此,特征图中的所有特征向量被划分为h¯×w¯块窗口,其中h¯=d/p和w¯= d/p。将块窗口内的每一组特征向量视为一个大小为c×p×p的基元素¯f。就像图像卷积通常使用奇数核大小的基本设置一样,将核窗口的大小定义为k=k¯×p,其中K¯∈1,3,2i+1。因此,块核形状被表示为(k¯×k¯)。
一个很小的样例实现了KPA的滑动窗口,如图所示,其中块大小p=2,核形状k¯×k¯为3×3, h¯和w¯分别设置为4和5。左边的子图描述了一个滑动的核窗口Nx(橙色的)在步骤t中处理一个分组的特征图。这里将每个块视为一个基本元素,并使用ej,其中j∈{1;2,……,9},表示在核窗口的每个元素(块)。可以看到,步骤t中的核心元素是e5,中间块窗口中的特征表示(红色的)将被更新。在实践中,我们首先在fc e5和fcE(其中E表示Nx中的所有ej)上使用权重函数W(ti)(·)来产生自适应权重,如Eqn. 3所示。具体来说,在这个过程中涉及到两种点积相似性度量,即一些块窗口之间的块内和块间的相似性。例如,e5中的特征向量可以与自身进行自注意力相似度测量,同时通过交叉注意力相互作用获得与其他8个块窗口中的特征的相关性。然后用构建核K(ti)。最后,我们用对运动特征进行核块注意力,即f0me5 = Pti2E K(ti)ρ(fm)。输出运动特征f^me5最终由残差操作产生,即f^me5 = fme5 + α f`me5,其中α表示一个可学习的参数,初始化为0,并逐渐执行加权求和。
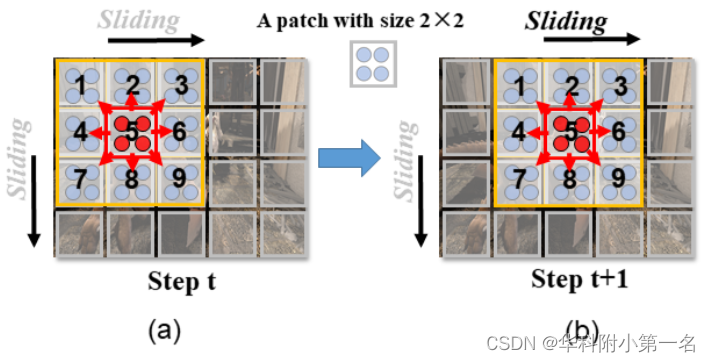
图3中的右子图说明了核窗口在步骤t + 1中滑动到下一个区域。由于将每个块视为基本元素,因此核窗口的滑动步幅应该相当于块大小p。此外,为了保证特征图的大小可以被p整除,并且中心块窗口能够滑动覆盖整个特征图中的所有位置,对特征进行了零填充。因此,运动特征fm中的所有块都可以通过KPA算子进行改进平滑。值得注意力的是,每一个KPA操作中的滑动步不依赖于其他的结果。因此,像图像卷积一样,整个算子可以并行处理,进行端到端训练。
讨论:与卷积的比较。图像卷积函数一般可以表述为:
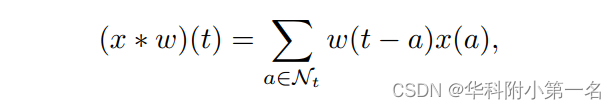
其中,a表示核区域Nt中的所有像素,w(·)表示核函数。虽然KPA与基于核的运算具有相同的图像卷积模式,但固有的公式完全不同。首先,图像卷积简单地将核函数w(·)定义为可学习的权重w,而KPA用一个scale函数来定义它,以提供可学习的标量和一个基于上下文关系的自适应权重函数。在推理过程中,我们的权函数W(ti)(~fc,fc)能够提供动态核映射,其中每个权重随相应的上下文特征而变化。相比之下,W是一个静态的权重,在训练后的所有滑动位置中共享。其次,图像卷积在通道维度和空间维度上都需要更多的参数。然而,我们的KPA只需要在通道维度上进行线性投影,这有助于在核区域较大时显著减少计算开销。
讨论:与类NL算子的比较。本文提出的KPA算子能够捕捉基于区域的场景上下文,以指导运动特征的学习。因此,与全局非类局部操作符相比,KPA消耗的计算开销更少。例如,给定一个维数为c×h×w的特征,我们的KPA和NL的计算复杂度为:

N = h × w表示空间维度,K = k × k表示核窗口的尺寸。特征大小通常比内核大小大很多,即:N 》K。此外,KPA中注意力图的形状为N×K,小于NL的注意力N×N,表示GPU内存成本更低。此外,NL注意力图可能包含许多来自无约束场景上下文的全局噪声,不适合用于运动引导。
3. 实验
3.1. 数据集
FlyingThings、Sintel、KITTI-2015、HD1K
3.2. 实现
基于PyTorch工具箱实现。核形状k¯× k¯设置为3 × 3。在sinintel和KITTI上,块大小p分别设置为19和9。使用4个GeForce GTX 2080Ti gpu来训练型,并采用一个gpu进行评估和时间测试。批大小分别设置为8和1。
3.3. 基准结果:SOTA
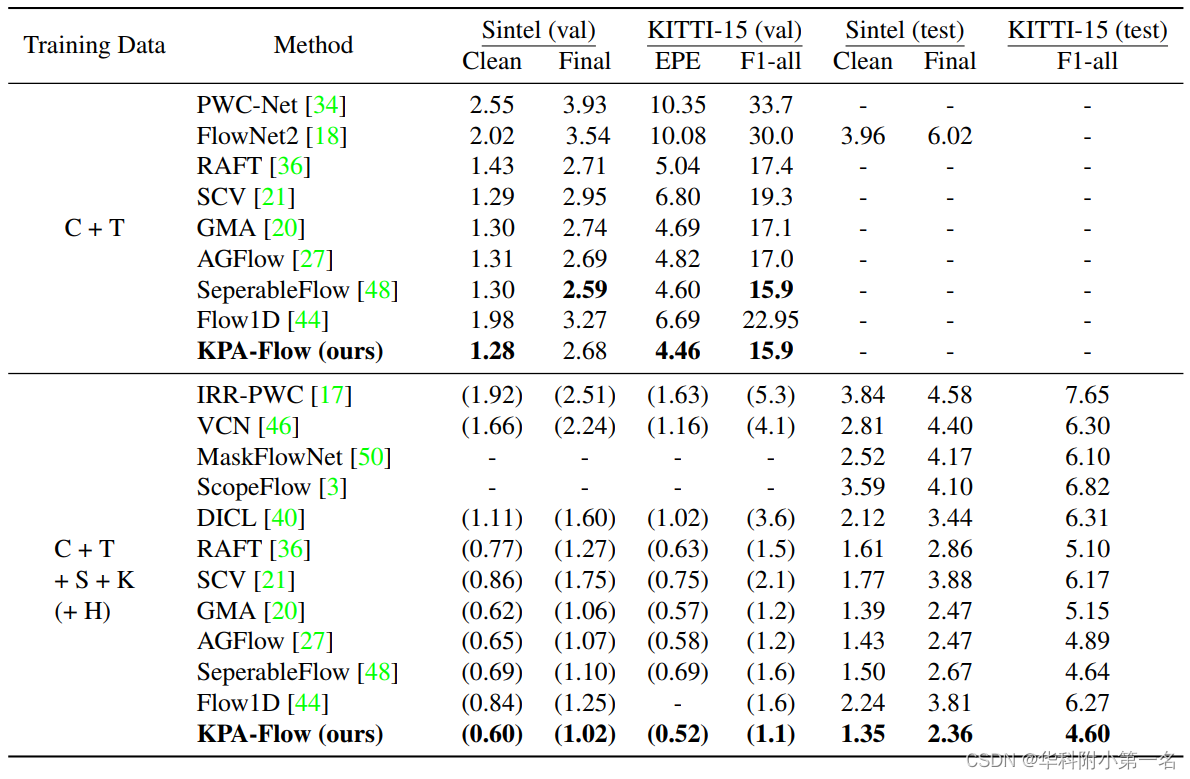 3.4. 方法比较
3.4. 方法比较
局限性是,固定的核形状对于处理一些具有挑战性的情况是不灵活的,比如两个相似的物体在不同的运动中相互纠缠。在这种情况下,上下文和空间亲和性都不能为运动引导提供有效的信息。这个问题的一个可能的解决方案是学习用于自适应运动推理的可变形核。