一点就分享系列(实践篇5-补更篇)[迟到补发]—Yolo系列算法开源项目融入V8旨在研究和兼容使用[持续更新]
题外话
去年我一直复读机式强调High-level在工业界已经饱和的情况,目的是呼吁更多人看准自己,不管是数字孪生交叉领域,还是chatGPT等大模型热点,大家都应该去延申自己的研究方向和工程技能栈,事实证明这判断完全符合趋势,也不是说明基础的检测、分割等任务没有研究和学习的意义,所以今天抽空写一下。言归正传,之所以现在才更博主要原因是去年开始我就接触了一些交叉方向以及快速的工程落地任务,导致个人时间完全没有,所以没有做到春节把代码上传。
在yolov8刚出时候我就加进了”玩具项目github",实不相瞒,我甚至第一时间并没有仔细看V8的Readme和创新点,下意识使然觉得无非就是这些,事实上确实也是,不过出乎我意料的就是anchor-free和新的代码结构,于是打算沿用V5代码风格融进去并完全兼容,而且一直跟检测的同学也会觉得V5代码风格很亲切。一番修改后确实差不多了,但唯独训练的时候发生了问题,后大致定位到是用V5的数据处理结构存在问题,可是同时我身兼多个业务的项目指标,压力拉满,毕竟要以工作业务为主,同时考虑作者习惯不停更新代码,所以我只完全把V8的anchor-free结构和V5的anchor代码风格融合通用了,其余所有的训练和推理部分都是使用的V8代码,命名为YOLO文件夹,可分离使用,这种做法看来是临时的,迫于工作压力我做到这里同时看了官方的参数文件中标注V5数据读取处理是debug的,大概和我估计的问题一致就停了,并且我不确定是否全部整理成V5风格还是V8风格,故还是先暂定这样,近期同步V8仓库做代码相关的整合适配,这些和算法创新无关,然后上传到了项目地址:https://github.com/positive666/yolo_research上,如有使用问题也属正常!可以提出来最好挂iussue上我会尽快解决和回复,那么今天开始更更文章补补欠的债并持续更新优化代码,不过由于工作节奏太快更新会较慢,还望各位读者见谅。
文章目录
- 一点就分享系列(实践篇5-补更篇)[迟到补发]—Yolo系列算法开源项目融入V8旨在研究和兼容使用[持续更新]
- 工程结构目录和总结
- Feature ——概述
- yolov8改动详解
- 网络结构
- 动手修改V5代码适配V8
- 分割模块(补之前V5的分割坑顺便)
- 跟踪模块
工程结构目录和总结
目前代码风格是以model.py为共同定义和解析网络结构为基础,单独拓展yolo/v8 文件夹作为V8部分可独立使用。
项目地址,以V5代码为基础,新添加了临时版本的V8部分:https://github.com/positive666/yolo_research
yolo_research
│ pose
│ └───── ## 关键点检测任务使用
│ ...
│ models ## 存储模型:算子定义和所有模型的yaml结构定义,包含yolov5\yolov7\yolov8
│ └───── cls 分类模型结构
│ pose 关键点模型结构
│ segment 分割模型结构
│ .... 其余是检测部分待整理
│ ....
│ segment
│ └───── ## 分割任务使用
| classify
│ └───── ## 分类任务使用
| tracker
│ └───── ## 跟踪任务使用 Fork V8
│ utils
│ └───── #通用部分代码
| .
| .
| segment ##分割的数据处理操作部分
| yolo
│ └───── v8 ## yolov8 core ,主要包含训练部分和推理使用部分的相关代码
│ └───── .
| cfg ## default.yaml 设置所有V8相关参数
| engine ## 定义基类结构
| utils
| data
| .
| .
| .
| ..其余为YOLO通用代码
---
如果耐心看完我开篇的闲言碎语,大概能理解这个目前的结构,且也不是我最终的规划,简而言之:目前在该仓库yolov5—high_level基础上,加入yolov8的部分,保持以前的V5部分,也就是目前我改的逻辑:是所有v5.v8所有的模型结构的定义和解析分还是全部集中在model.py中,但是V8还是在独立的文件下可以单独使用,V5也是,V8的命令内容正常使用,和官方命令一样,也可自己修改用脚本启动。
方式一、比如V8的官方命令解析
yolo task=detect mode=train model=yolov8n.pt args...
classify predict yolov8n-cls.yaml args...
segment val yolov8n-seg.yaml args...
export yolov8n.pt format=onnx args...
也可以直接通过脚本启动后者自己构建调用,如找到对应任务下,需要你进入到cfg/default.yaml中去配置你的参数,比如模型、数据等路径以及超参数。
方式二、在我的项目目录下,可以这样使用
python yolo\v8\detect\train.py
在官方的目录下,可以直接调包
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.yaml") # build a new model from scratch
model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Use the model
model.train(data="coco128.yaml", epochs=3) # train the model
metrics = model.val() # evaluate model performance on the validation set
#results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
#success = model.export(format="onnx") # export the model to ONNX format
因为V8提供了全新的命令,设计一套yolo的命令格式,方式很简单就是现在最流行的低代码设计,降低使用者门槛。
通过yolo task… model=… arg=… 的格式启动所有任务
Feature ——概述
这种创新点其实老生常谈了,如果你是从21年看我偶尔随写的YOLO修改博客的话,对于算子、结构、LOSS样本匹配的思路应该比较熟悉了,可以看到V8版本在官方GIT上展示出了基于COCO性能的比对
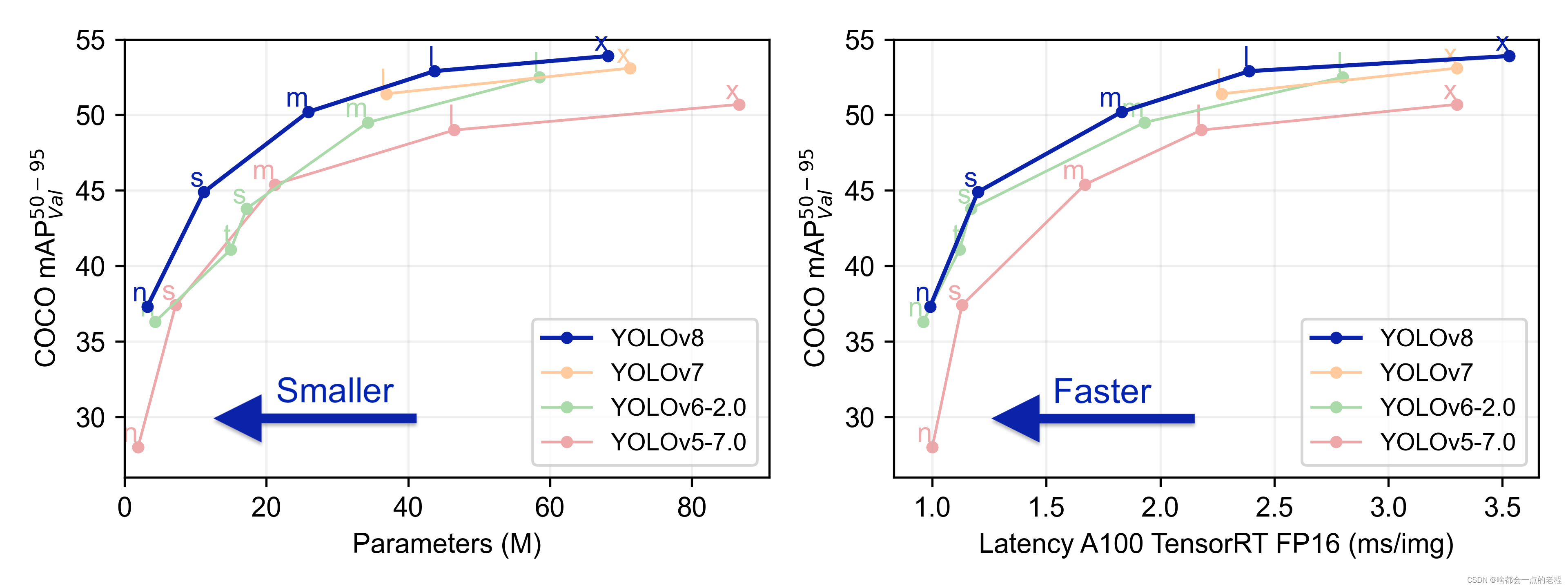
左图展示在COCO数据验证集上的性能指标,说明在精度提升的同时带来了参数量的提升,在常规尺度的n/s/M的模型上参数量增加;
右图展示在COCO数据验证集上Tensorrt的性能指标,A100 显卡上FP16精度推理下的速度展示,总之可以看出V8精度更高,但是相对V5来说牺牲了部分推理速度,但是在如今检测器部署泛滥的年代,这样的速度差异倒是可以忽略。
另外插一句,不知道大家有没有近两年的检测项目,包含V5-6.0版本开始已经不满足于检测,(去年我记得我把顺着V7官方推荐的V5版本的开源关键点检测融进我GIT的那天,我晚上调好,我习惯性看看V5作者的工程优化时候,他就发出来分割代码了 当时就感觉不谋而合 )是经典的基础视觉任务“通杀”的工程化模型,还有开箱即用的Tensorrt等部署代码的工具都是清一色标配,这也能从侧面反应检测、分类、分割等High-level经典任务算法和技术上已经趋于瓶颈,我又来说这个了,没办法,因为去年接触过不少跨领域的东西,感觉目前业界做CV除了纯科研产出论文等,只做检测或者只研究检测远远不够!话呢说回来,基础还是要打好,所以多兼顾就要多牺牲时间,做CV越来越累也正常,V8这次的出现褒贬不一,不管是质疑SOTA技巧的缝合还是泛化性的不足也好,终归也有我们学习的点。
下面,我会尽量详细对于V8版本的一些新变化,原理和代码等做出一些分析展示把,可能短期都更完,因为最近很多工程要做,尽快完成更新,并且我也会额外写出一个如何把V8代码嵌进各位自己修改改进的V5代码中(很多读者是自己在V5上做了改进后适应了自己任务的特定数据集,那么直接引入V8核心部分的程序使用可能会更方便),简单规划总结下,我心中V8的一些核心改动特色。
1. 性能提升并在检测、分类、分割三线任务中加入了最新的跟踪bytetrack等方法。
2. 模型结构变化:核心算子块C3变成C2F,由于增加了不少次shortcut,在深层模型中梯度的问题得到缓解同时,可能有利用特征重用; head部分沿用之前的解耦头,取消掉了objectnetss分支,使用了经典魔改利器之一的Distribution Focal
loss,以积分表示BOX,需要进行解码转换,Anchor-free取消了先验anchor部分,且提供了v5u的一系列anchorfree的V5、v8模型结构。
3. 训练部分 :核心样本匹配策略改为动态匹配Taskaligened分配机制区分正负样本
4. 额外的工程化代码改动和自定以YOLO命令格式
预告下面更新的内容进行详细分析,感兴趣的可以先MARK!读者也可以提议是完全使用V8代码风格,还是保持V5的部分。