文章目录
- 前言
- IP报文格式
- 分片处理
- 分片对传输层的影响
- 网段划分
- 路由转发中的路由表
前言
tcp作为传输层的典型协议,保证了报文传输的可靠性,使每份报文完整的传输。在传输层之下的网络层解决的是传输能力的问题,它使得数据可以发送到对方主机,负责数据的路由,与传输层的区别在于:网络层侧重于能不能,而传输层侧重于好不好
并且我们还要区分一些概念,避免被绕晕
- 数据段(segment):传输层的传输单元,由传输层报头和应用层报文构成
- 数据报(datagram):网络层的传输单元,由网络层报头和传输层数据段构成,需要根据链路层的MTU进行分片和重组
- 数据帧(frame):链路层的传输单元,由链路层报头,报尾,网络层数据报构成
- 数据包(packet):是一个通用的术语,可以指任何一种传输单元,但通常指的是网络层及以上的传输单元
IP报文格式

- 4位版本:表示IP协议的版本号,IPV4和IPV6,一般是IPV4
- 4位首部长度:表示IP报文中报头的大小,以4字节为基本单位。20字节是基本报头的长度,有的报文可能携带选项,这时我们可以先读取20字节的报头,得到整个报头的大小,将报头和有效载荷区别开
- 8位服务类型:表示IP报头中提供的服务质量,包括优先级、吞吐量、延迟、可靠性等
- 16位总长度:表示整个IP报文的长度,以字节为单位
- 这一行跳过,之后详细介绍
- 8位生存时间:表示报文在网络中能经过的最大路由器数量,注意这可不是时间。每经过一个路由器TTL就减一,直到TTL为0,IP报文被丢弃
- 8位协议:表示上层使用的协议,6表示TCP,17表示UDP,1表示ICMP
- 16位首部校验和:表示对IP首部进行校验和计算得到的结果。用于检测数据是否被发送错误
- 32位源IP地址和目的地址:表示发送方和接收方的IP地址,每个地址由32位二进制数构成,点分十进制中,每一段都是0~255之间的数字
- 选项和填充:选项表示一些额外信息和功能,选项有多种类型和长度。填充指的是用来使报头长度达到4字节整数倍的比特0
分片处理
对于其中的16位标识位,3位标志位,13位片偏移
MTU(Maximum Transmission Unit)最大传输单元,这是一个数据链路层的概念,由于物理结构的限制,数据链路层发送的报文有最大限制,一般是1500字节。如果网络层的报文长度超过了MTU,就要进行IP分片,这个过程由网络层进行,分片的重组由对方的网络层进行,解铃还须系铃人嘛。
要注意的是:MTU限制的是数据链路层的有效载荷,也就是网络层的报文长度,它不包括数据链路层的报头长度
如果传输层将一个2980字节的数据段(报头+有效载荷)交付给网络层,假设IP层的报头长度为标准的20字节,那么为数据段添加报头后的数据大小为3000字节,由于其大小超过了MTU,所以需要分片。分片后每个报文都需要携带IP报头,这是基本的原则,对原始报文进行分片,2980被分成了20 + 1480, 20 + 1480,此时已经拆分了2960(1480 + 1480)字节的数据,注意这里的20字节是网络层的报头长度,还剩20字节没有分片,所以最后一片的大小为20 + 20。左操作数是报头,右操作数是被分割的数据段,将右操作数相加,得到2980,说明此时的分片没有问题。
那么现在就有一个问题,要怎么判断接收方接收的数据帧是被分片的还是没被分片的数据帧呢?这与下面这些字段有关
- 3位标志位:表示分片的相关信息,
- RF(Reserved Fragment): 第一位,保留不用,设置为0
- DF(Don’t Fragment):第二位,如果设置为1,表示上层不希望该数据段分片
- MF(More Fragment):第三位,如果设置为1,表示后面还有分片,反之表示后续没有分片
- 16位标识位:表示分片所属的原始数据段的编号,用来区分,重组不同的分片
- 13位偏移位:表示分片的首地址与原始数据段首地址的偏移量,如果为0,表示这是某一数据段的第一个分片。以8字节为单位,也就是说将它 * 8就能得到分片与原始数据段首地址的偏移字节数大小
所以,接收方接收数据帧时,只要根据MF和13位偏移位来判断数据帧是否为分片就可以了。如果MF = 0,并且偏移为0就表示该分片后面没有分片,且该分片是第一个分片,说人话就是该数据报没有被分片,是完整的。如果数据报不是上面的情况,就说明该数据报是一个分片,需要网络层进行重组。如何重组一个完整的数据报呢?我们可以根据片偏移量对数据帧进行排序,第一个肯定是片偏移量为0的数据帧,将片偏移量 + 自身的长度(网络层的报文长度)就能得到下一个数据帧的片偏移量,一直这样遍历下去,直到MF为0,如果片偏移量 + 自身的长度 = 下一个数据帧的片偏移量这个等式,总是成立,说明分片是完整的,就能重组数据报,反之需要继续收集分片。
要注意的是:虽然分片和重组都发生在网络层,但是分片可以在中间路由器或者源主机上进行,而重组只能在目的主机进行
分片对传输层的影响
在网络丢包概率同一的情况下,传输越多的报文丢包的可能就越大,将一个报文拆分成多个报文,进行分片传输,肯定增加了丢包的概率,那么丢包对上层有影响吗?传输层有两大协议:udp和tcp,由于tcp有可靠性保证,所以丢包不影响数据的发送,只是会降低传输的效率。但是对于udp,由于其没有可靠性保证策略,所以丢包就是真的丢了,无法恢复的那种,这使得本就不可靠的udp雪上加霜,所以在局域网中,通常建议udp有效载荷的长度为1472字节(1500 - 20 IP报头 - 8 udp报头),使udp尽量不分片
除此之外,分片将占用更多的带宽,每个分片都有相同的IP报头,这将增加网络拥塞的可能性。并且过多的分片可能带来传输的延迟,分片和重组都将消耗时间
网段划分
网络划分是网络层学习的一大重点
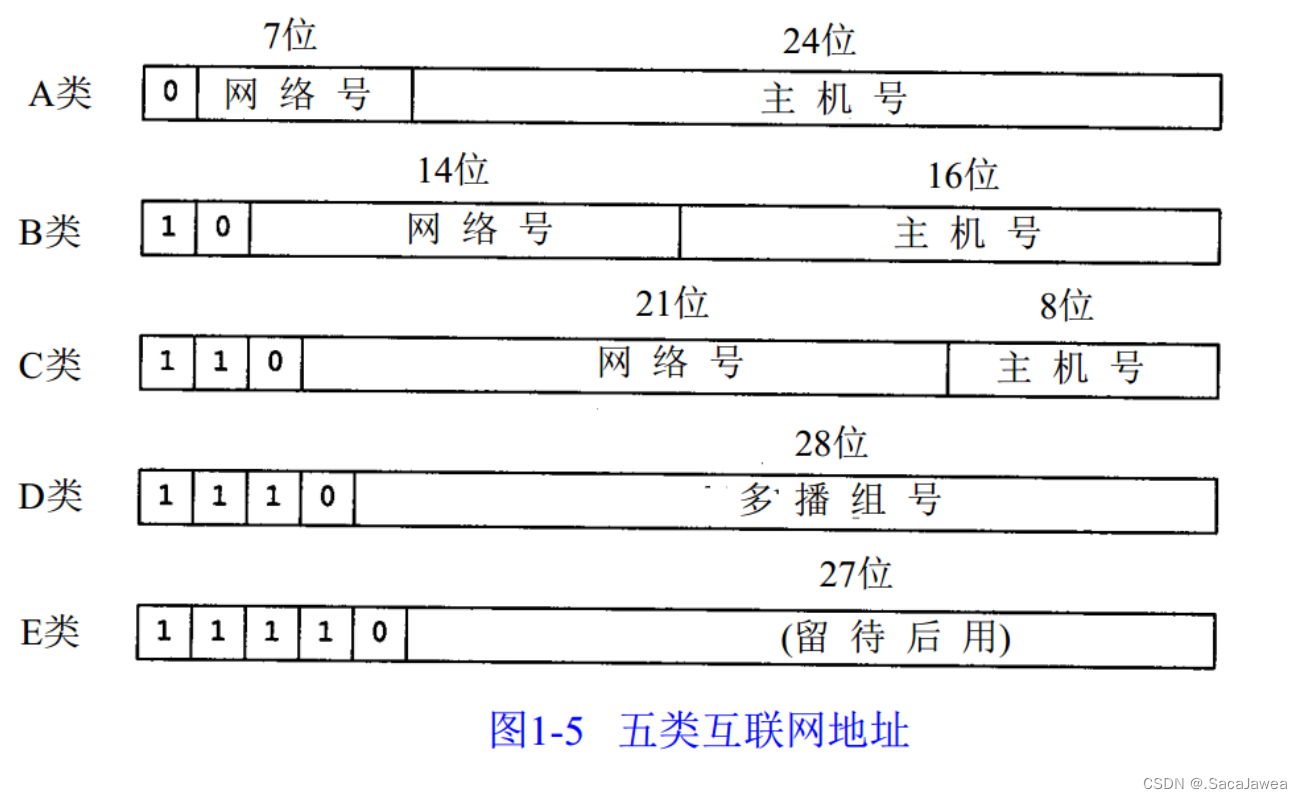
IP(IPV4)地址分为两个部分
- 网络号:表示不同的网段
- 主机号:表示某一网段下的唯一主机
(图源网络)
最早的时候,IP地址被划分成5个网段,这样的划分极其容易浪费IP地址,比如我申请了一个B类网,拥有了2的16次方个IP地址,但是只用了2的14次方个,剩下的地址不就浪费了吗?并且网段数量固定与主机号数量固定也使得这样的划分方法不够灵活,所以后来引入了CIDR(Classless Inter-Domain Routing),无类别域间路由技术,其主要是使用子网掩码进行按位与运算,充分使用不同的网段,利用每一个IP地址。具体表格式是IP address/prefix length,比如192.168.1.1/16,16表示255.255.0.0这个子网掩码(前16位为1的二进制序列),将子网掩码和IP地址按位与后得到192.168.0.0,表示当前IP处于192.168.0.0这个网段。使用子网掩码就能灵活划分不同子网,但是CIDR只是充分利用了每一位IP地址,IP地址的总量不变,其供给与需求的矛盾依然是存在的。有三种解决这个矛盾的典型方法
- 动态分配IP地址(DHCP):只给接入网络的设备分配IP地址,这时同一设备每次上网时所用的IP地址是不同的
- IPV6技术:IPV6和IPV4互不兼容,IPV6用128b来表示一个IP地址,2的128次方是个非常庞大的数目,在IPV6技术下,每个人都可以拥有属于自己的IP,但是该技术目前没有普及
- NAT技术(Network Address Translation)
解决IPV4地址耗尽问题的主要策略是NAT技术,NAT延缓了IPV6的普及,使IPV4延用至今。什么是NAT?NAT是一种将私有地址转换成公有地址的转换技术,其主要部署在一个组织网络的出口位置,将所有要访问Internet的私网地址转换成公网地址。不同的私网可以使用相同的IP地址,经过NAT的转换,它们都被转换成了不同的公网地址。理论上我们可以使用所有可能的字段作为私网地址,但是RFC 1918规定了用于组建局域网的IP地址
- 10.*,前8位为网络号,共16,777,216个地址
- 172.16到172.31,前12位是网络号,共1,048,576个地址
- 192.168.*,前16位为网络号,共65536个地址
在这些范围内的地址都是私网地址,其余都是公网地址。要注意的是,网段中最大主机号的IP,比如10.255.255.255,代表10网段下的一个广播IP。 如果是10.0.0.0,代表10网段的默认网关,这是路由转发的默认选择
家用路由器一般都有两条线,一条连接LAN(局域网)口,一条连接WAN(广域网)口。当使用家用路由器发送数据包时,由于我们的数据包位于私网中,私网不能和公网直接通信(要使用公网IP进行通信),所以路由器会将该数据包的源IP地址做转换,将其转换成自己的WAN口IP,如果WAN口IP也是一个私网IP(即路由器横跨两个私网),那么这个数据包的源IP地址会被不断的转换。直到源IP是公网IP为止,数据包的源IP从私网IP不断地被转换成公网IP的过程就是由NAT技术实现的,这个过程中数据包的目的IP一直没有发生变换,只有源IP在变换。
路由器在这个过程中也承担着重要的角色,它至少跨了两个网段,一个广域网,一个局域网。其接收来自局域网的数据包,负责将其路由,路由有两个方向,根据目标IP是否存在与当前局域网中(其实是根据目标IP的网段判断其与路由器广域网IP的网段是否一样,如果一样,数据包就会在局域网中进行转发),一个方向是在局域网中路由,另一个是将其向上交付,发送到广域网中,由上层的路由器负责路由。
路由转发中的路由表
路由过程中的“一跳”是怎样实现
路由转发指的是:路由器从一个接口中收到一个数据包,根据该数据包的目标IP地址进行定向并转发到另一个接口的过程。当IP数据包到达路由器时,路由器会先查看其目标IP,根据目标IP是否在自己的局域网内来决定是要把数据包转发给下一路由器还是转发到自己的局域网中。如何判断目标IP是否在自己的局域网中呢?这就涉及到路由表了

Linux的route命令展示的信息中,每个信息分别是什么意思:
- Destination:目标网络或主机的地址。
- Gateway:网关地址,即下一跳路由器的地址。
- Genmask:子网掩码,用于划分网络和主机部分。
- Flags:标志位,表示路由的类型和状态。常见的标志位有:
- U:表示该路由是可用的(up)。
- G:表示该路由使用了网关(gateway)。
- H:表示该路由是指向一个主机(host),而不是一个网络。
- D:表示该路由是动态生成的(dynamic),通常是通过某种协议如RIP或DHCP获得的。
- M:表示该路由已经被修改过(modified)。
- Metric:度量值,表示到达目标网络或主机所需的跳数或开销。一般来说,度量值越小,优先级越高。
- Ref:引用计数,表示有多少个数据结构指向这条路由。通常不需要关心这个值。
- Use:使用计数,表示有多少个数据包通过这条路由发送。通常不需要关心这个值。
- Iface:出接口,即发送数据包时使用的网络设备名称。
(源:newbing查询)
路由表是存储在路由器或者其他网络计算机上的表格或者类数据库,路由表的每一项代表一个网络或主机,以及如何到达它的信息。它可以是动态,也可以是静态的,一般都是动态路由表,静态路由表是由系统提前设置好的,route查看的就是静态路由表。
路由表在路由中的作用:路由器收到一个请求,将其目的IP与自己所在的局域网子网掩码做按位与运算,如果目的IP在自己的网段中,路由器会将该请求在自己的局域网中路由。如果不再自己的网段中,路由器会将其目的IP与路由表的某一项的子网掩码Genmask做按位与运算,得到其网段,判断该项的Destination是否和得到的网段匹配,如果匹配,将该数据包转发给该项的网关Getaway(说明该项所在网段与请求的目的IP所在网段相同,将请求交付给它,让它进行路由转发),反之就继续遍历路由表。如果Gateway为0.0.0.0,表示目的网络是本地连接,不需要经过中间路由器的转发。如果遍历完所有的表项,都没有找到与之匹配的网段,就将该数据包转发给当前网段的默认网关,默认网关的Destination为0.0.0.0或default



![[数据结构与算法(严蔚敏 C语言第二版)]第1章 绪论(章节题库+答案解析)](https://img-blog.csdnimg.cn/860864cb82154a5ab5e61cbb8e888d9d.png)