文章目录
- STL简介
- 一.认识string
- 二.string中基本功能的使用
- 总结
STL简介
一、认识string

通过官方文档我们得知,string的原型是basic_string的类模板。
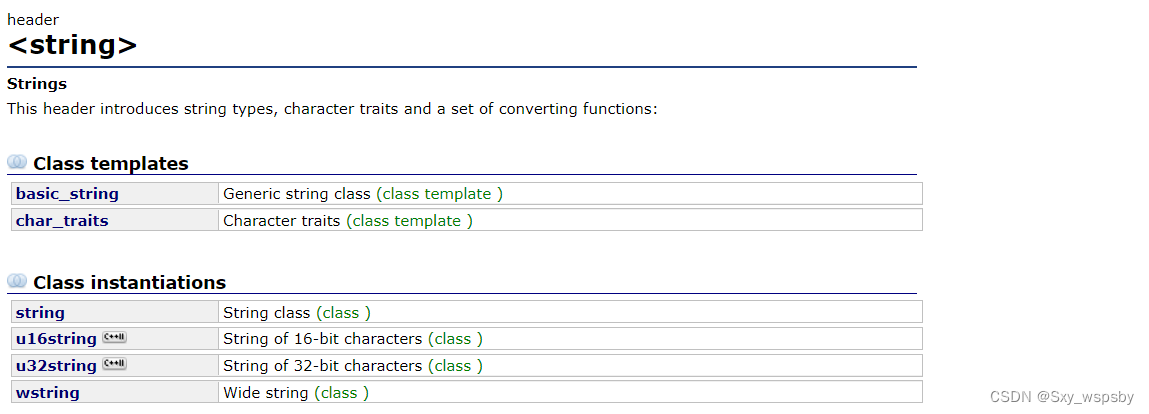 我们发现wstring,u16string,u32string这些又是什么呢?string的本质是一个管理字符的顺序表只不过里面存的都是1个char类型的字符,而wstring里面存的是2字节的char,u16string也是2个字节,u32string是4个字节,为什么会有这么多的差异呢?因为我们有管理不同的字符数组的需求。在这里我们要了解ascll码,用ascll编码可以在计算机里面存储和显示英文信息,而在一开始的ascll码表中仅有128个值,用7个比特位就可以代表这128个值了,所以一开始的string中的字符仅为1个字节,如下图:
我们发现wstring,u16string,u32string这些又是什么呢?string的本质是一个管理字符的顺序表只不过里面存的都是1个char类型的字符,而wstring里面存的是2字节的char,u16string也是2个字节,u32string是4个字节,为什么会有这么多的差异呢?因为我们有管理不同的字符数组的需求。在这里我们要了解ascll码,用ascll编码可以在计算机里面存储和显示英文信息,而在一开始的ascll码表中仅有128个值,用7个比特位就可以代表这128个值了,所以一开始的string中的字符仅为1个字节,如下图:
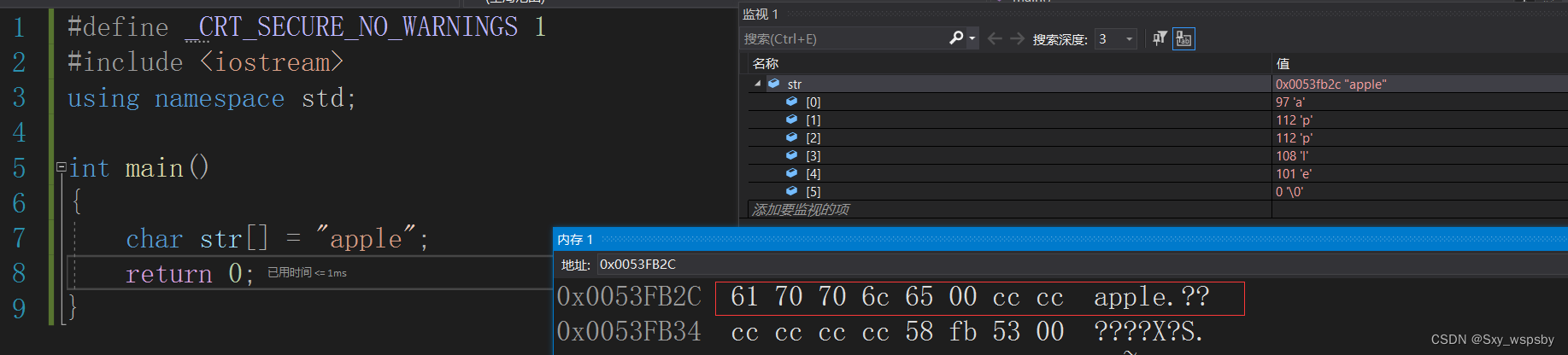
apple这个字符串存在char类型的数组中会消耗6个字节,多出来的1个字节用来存放\0,而字符a在ascll表中的值为97,内存中的16进制61转换过来就是97,所以字符确实是根据ascll的值在内存中一个一个存储的。而计算机不能只显示英文,如果只能显示英文计算机又如何卖到中国呢,所以为了显示其他国家的文字有人就发明了Unicode(万国码)能表示各个国家的文字,Unicode又分为utf-8,utf-16,uft-32,他们三个的区别是每个字符的字节数不同,比如utf-8的char就是1字节并且兼容ascll吗,utf-16用16个比特位也就是2个字节,utf-32则是4个字节表示一个字符。而string类就是因为这样的原因所以搞出了字节数不一样的模板。
总结:
二、string中基本功能的使用。
1.string的构造函数。

我们可以看到string的构造函数有7个不同的重载,第一个可以直接定义一个字符串,比如:

我们可以发现一个空字符串里面是有一个\0的。
第二个可以直接用字符串初始化:
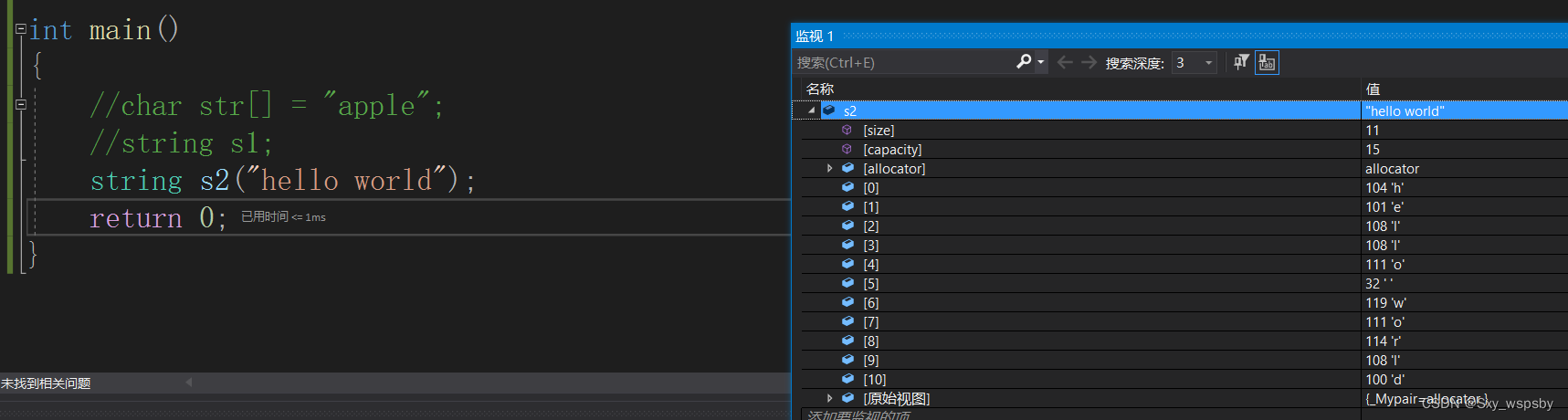
第二个是我们使用最多也是最方便的。第三个:给定一个字符串从这个字符串的某个位置及这个位置后面的len个长度初始化,如下:
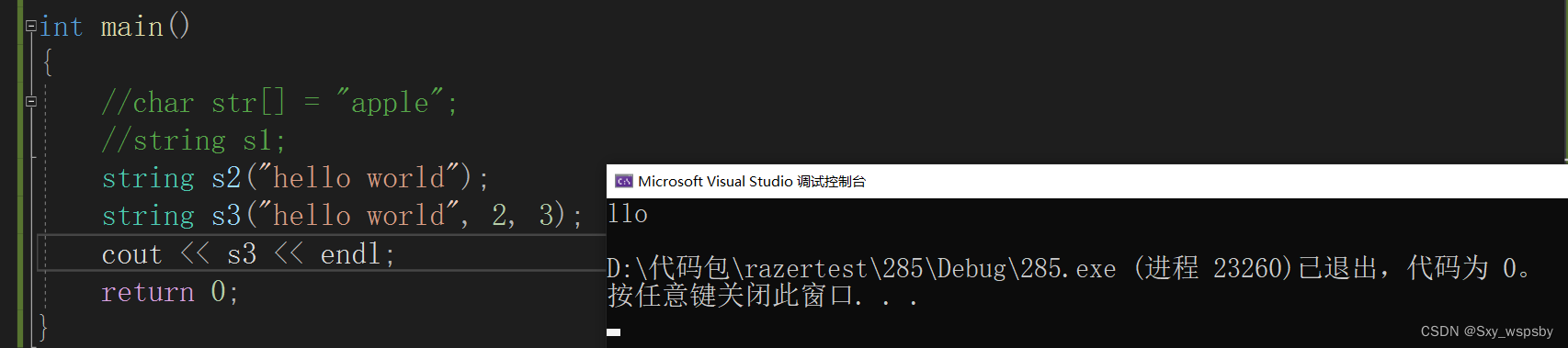
len这个参数给了缺省值,实际上如果我们不给len那么len默认就是npos,npos是size_t类型默认值是-1,我们都知道size_t类型是无符号整形,所以-1就是整形的最大值,也就是说如果你不写这个参数那么自动将从pos位置开始后的所有字符进行构造。

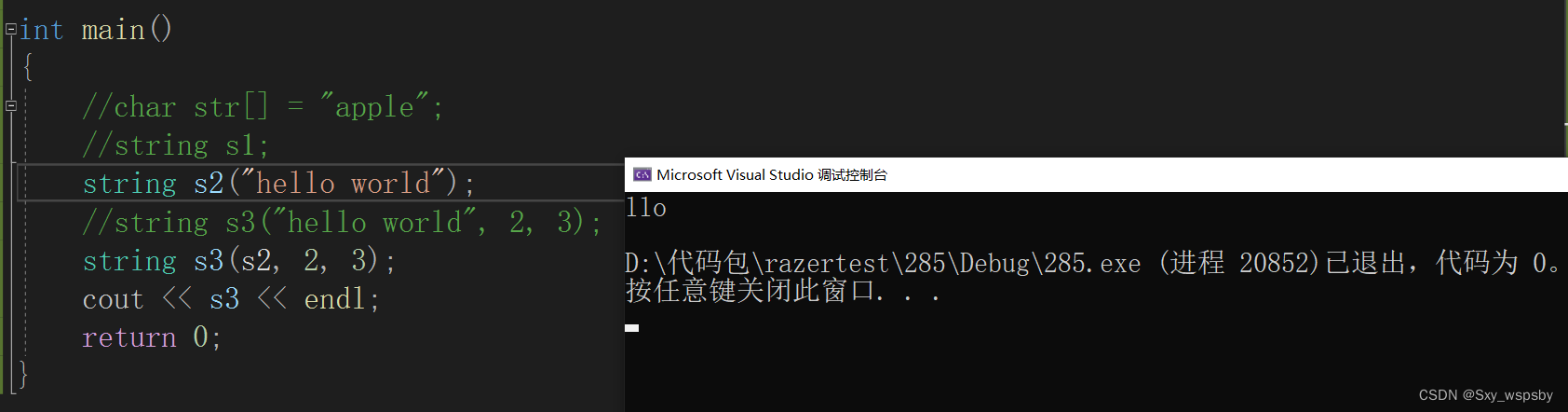 第四个:直接用字符串去构造。
第四个:直接用字符串去构造。
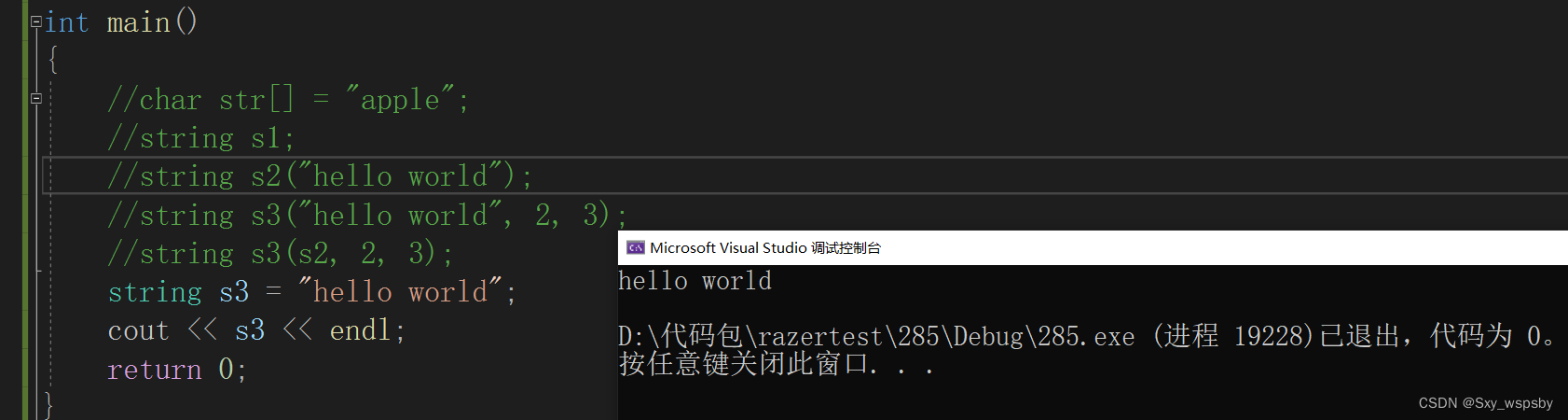
这里发生了隐式类型转换,将const char* 转换为string,如果不想要编译器发生隐式类型转换我们可以在构造函数前面加上explicit,这点我们在前面的类和对象文章讲过。
第五个:给定一个字符串用它的前n个构造

第六个:用n个字符去构造

第七个:迭代器区间的构造:
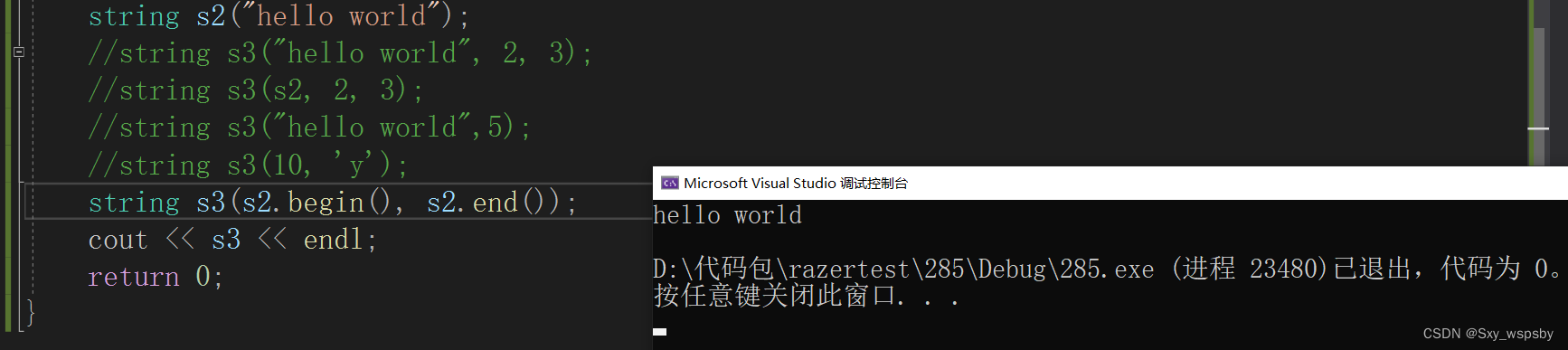
下面我们先来看string容量部分的函数:

第一个:size代表字符串的长度,length与size一模一样。

那么为什么要设计一模一样的函数呢,这里是因为c++早期的历史遗留问题,在没有STL之前是用length计算长度,有了STL后要计算二叉树等再用长度这个名称就不合适了所以多加了一个函数size。
第二个:max_size

max_size就是字符串的最大长度,它的理想是整形的最大值但实际上没有这么大因为要看堆的大小,并且这个借口并没有什么很大的作用。
我们先讲第四个:capacity
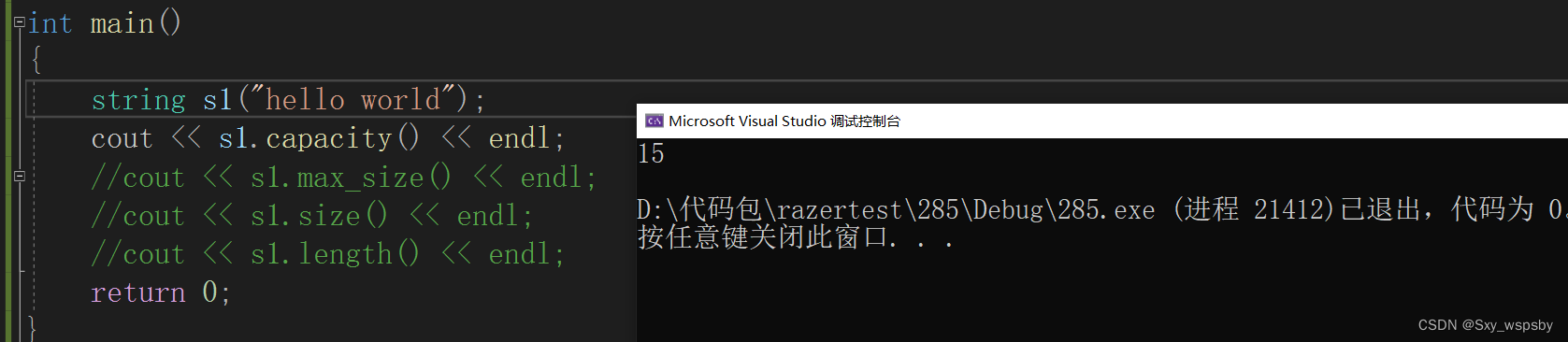
capacity就是字符能存储多少个字节,在这里需要注意的是:capacity不包含\0也就是说如果字符串是:“hello”,那么capacity就是5不会再加上\0的一个字节大小。
第三个:resize

第一个作用:resize的作用是开空间并且初始化,并且resize会改变size和capacity的大小。
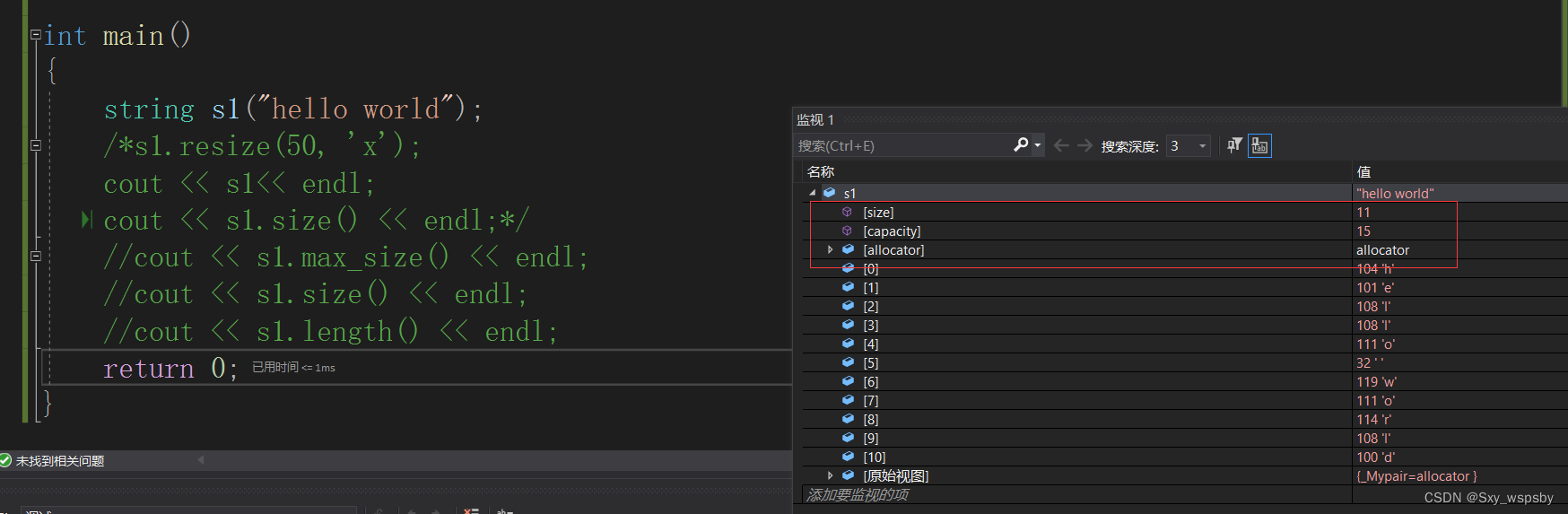

我们可以看到,s1的长度从11变成了50,空间从15变成了63,当然如果我们不主动初始化为某个字符会默认初始化为\0。
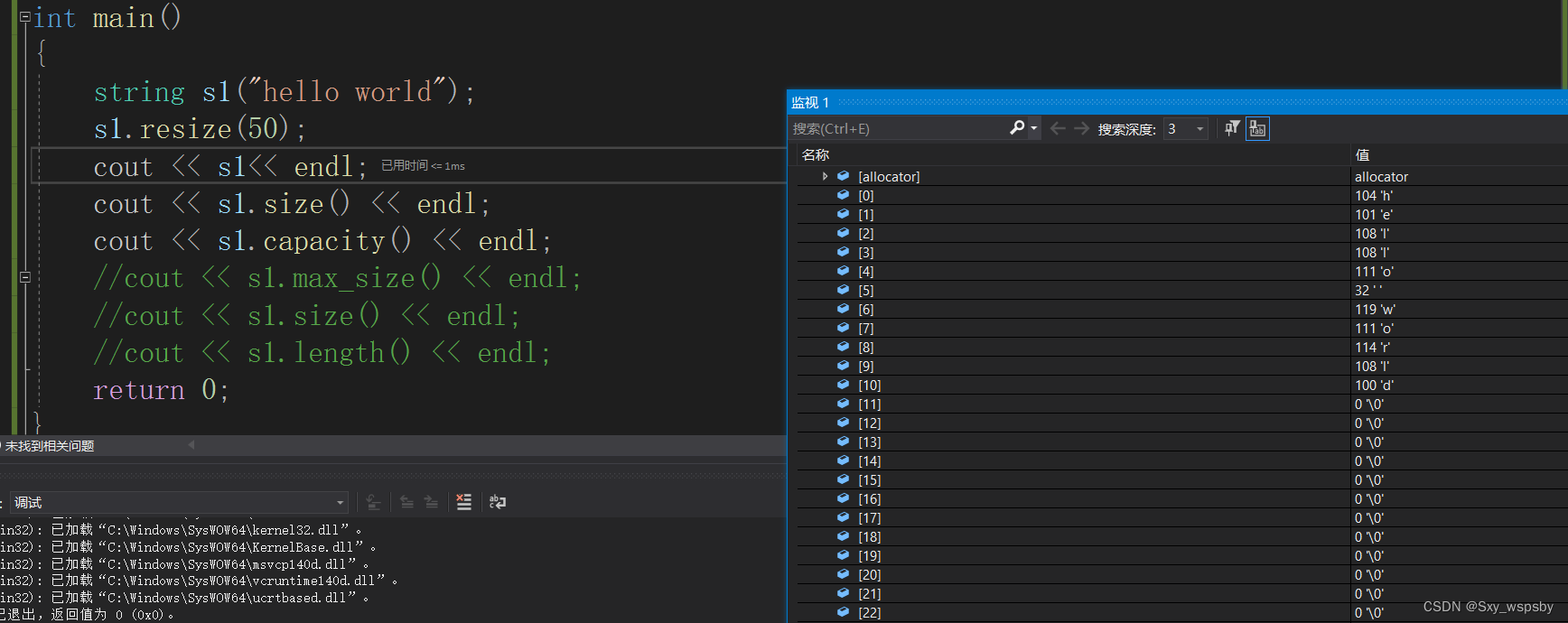
第二个作用:当resize的大小比原来字符串的capacity要小,那么resize就会将字符串中的字符缩减为resize的大小。

我们可以看到字符串只保留了前五个字符。
第五个:reserve 开空间,只改变capacity不改变size,并且不会初始化。

第六个:clear 清空字符串
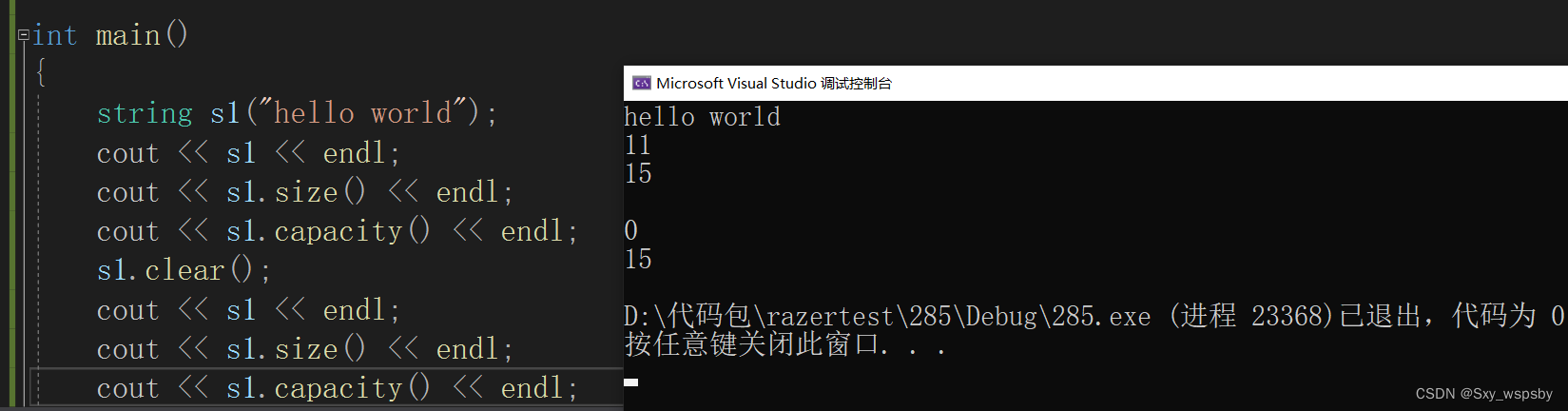
可以看到字符串为空了。
第七个:empty 判断字符串是否为空
 接下来我们看string中的modify接口:
接下来我们看string中的modify接口:

这里我们就不按照顺序进行演示了,因为有些接口不按照顺序效果会更好。
push_back :尾插一个字符

append:尾插一个字符串

第3个重载:
 这里也是有6个函数重载,实在太过冗余所以我们就演示经常使用的。
这里也是有6个函数重载,实在太过冗余所以我们就演示经常使用的。
第2个重载,尾插一个字符串的从pos位置起的sublen个字符

第4个重载,尾插一个字符串的前n个

第1个重载:
 当然以上的这些接口其实都不是很实用,最实用的是操作符重载中的+=符号。
当然以上的这些接口其实都不是很实用,最实用的是操作符重载中的+=符号。

可以看到+=符号实在是太方便了。
insert:插入字符串或者字符
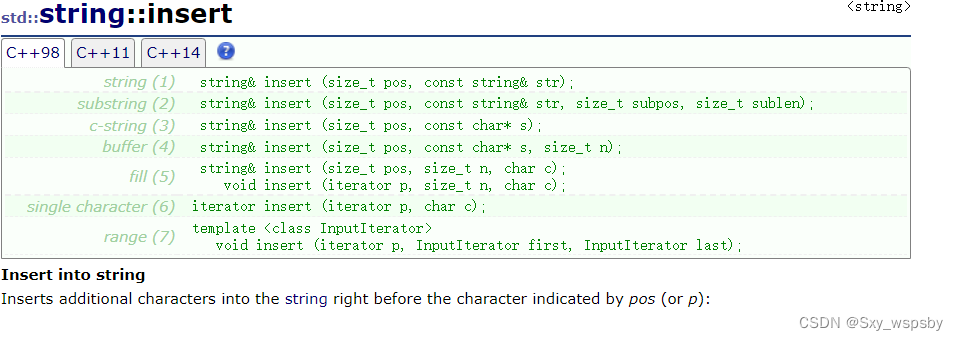
下面演示一下如何使用:在第pos个位置插入一个string对象
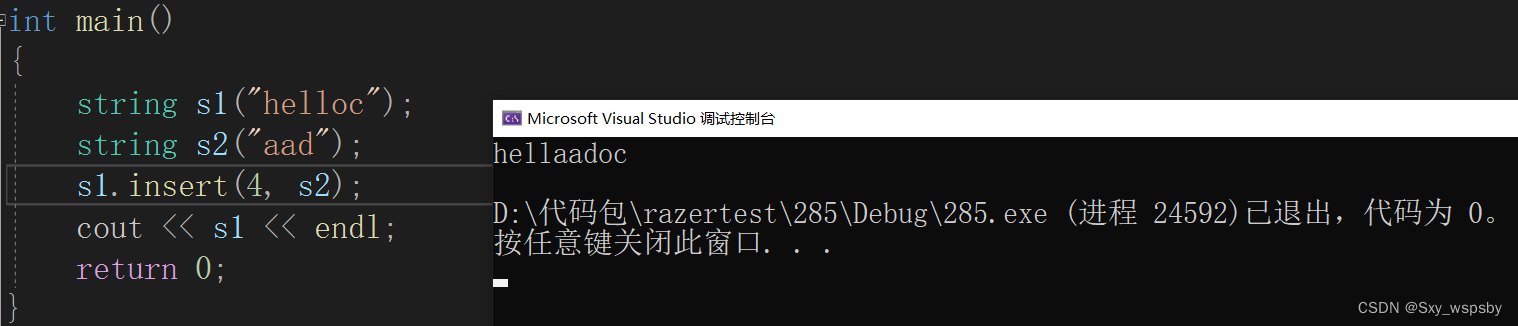
在第pos个位置插入一个string对象的从subpos下标位置开始的sublen个字符
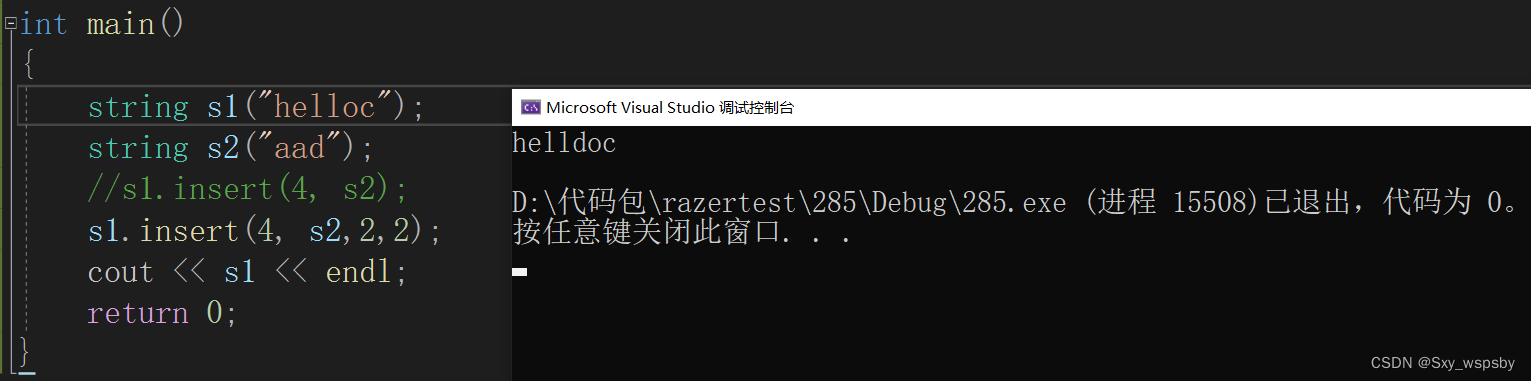
在第pos个位置插入一个字符串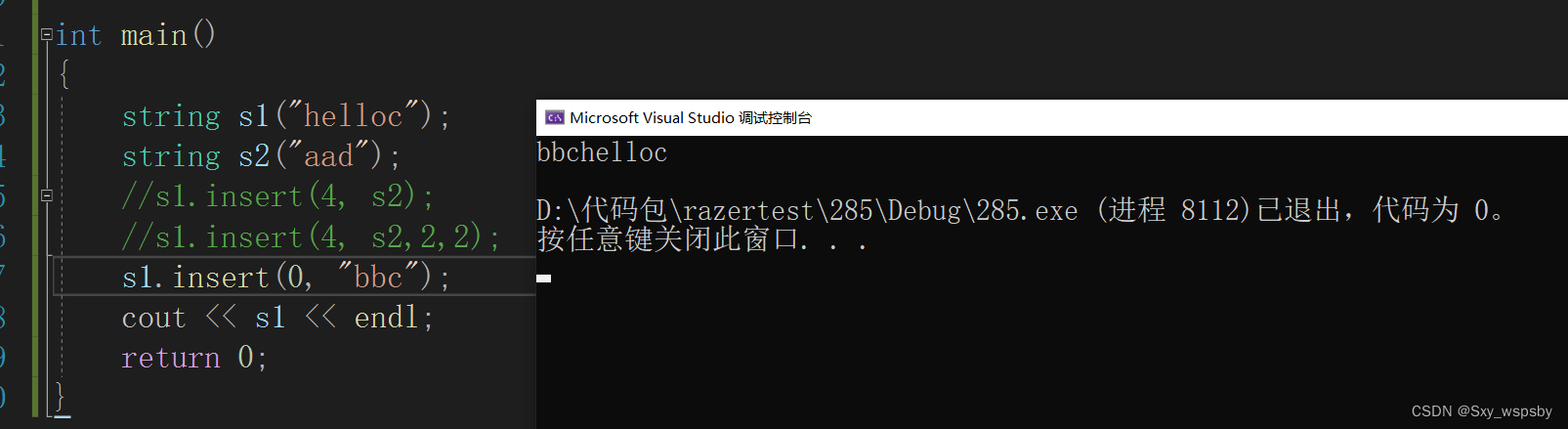
在第pos个位置插入字符串的前n个。
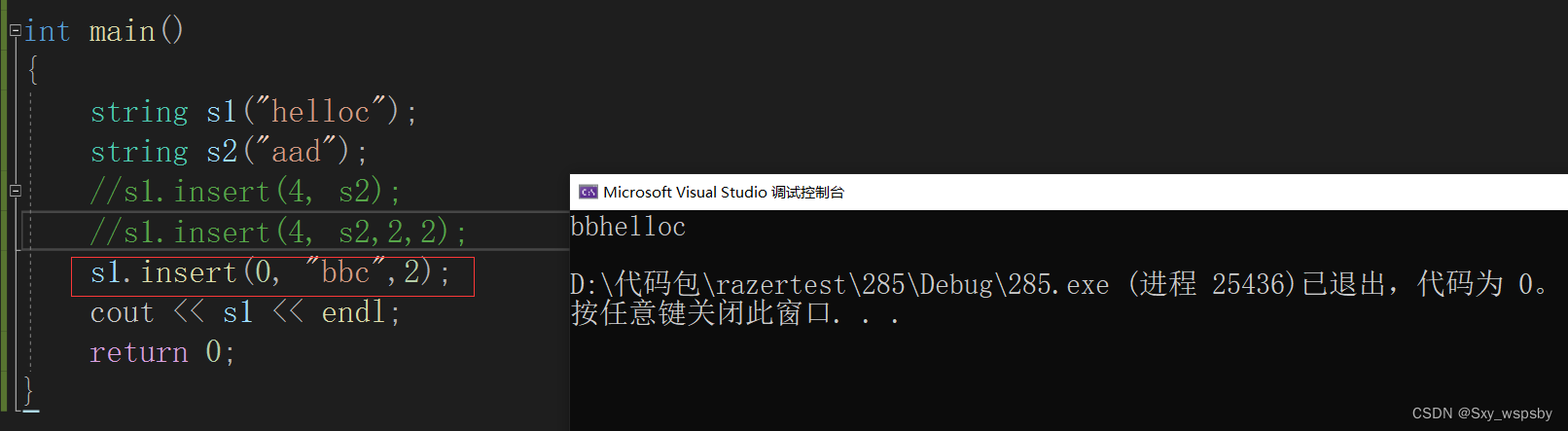
当然我们是不推荐使用insert的,因为插入要往后挪数据,时间复杂度为O(N)。
有insert就会有erase,我们看一下erase接口:
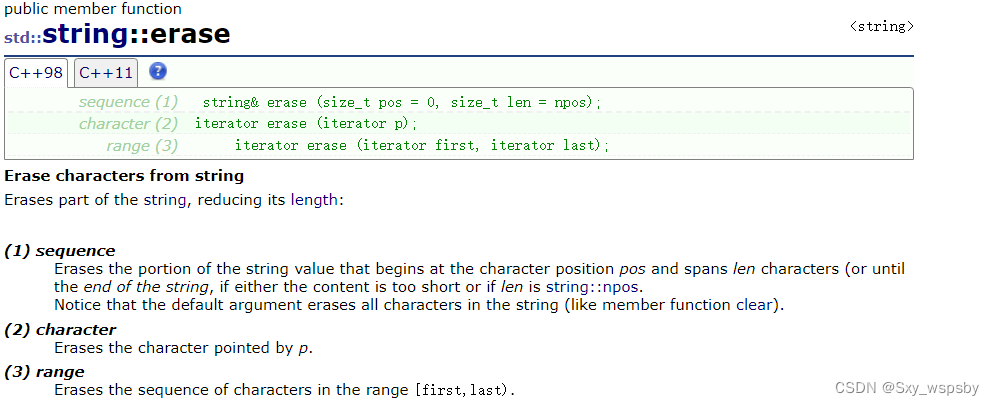
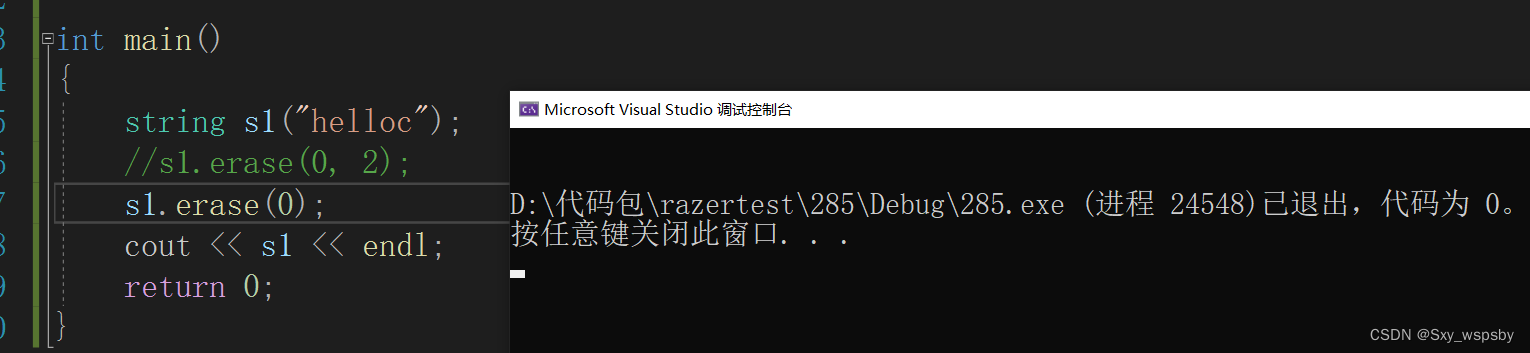
从pos位置起删除len个字符:
 len有缺省值,如果我们不传则从pos位置开始后面全删,如下:
len有缺省值,如果我们不传则从pos位置开始后面全删,如下:
接下来我们看一下replace接口:
 replace的重载太多了并且冗余,我们会用一两个即可:
replace的重载太多了并且冗余,我们会用一两个即可:

上图是从下标为pos的位置开始的len个字符串。
我们先一下find接口:

pos使用缺省值如果我们不写默认是0位置。
下面我们用find接口和replace接口做一道经典例题:将空格替换为%20
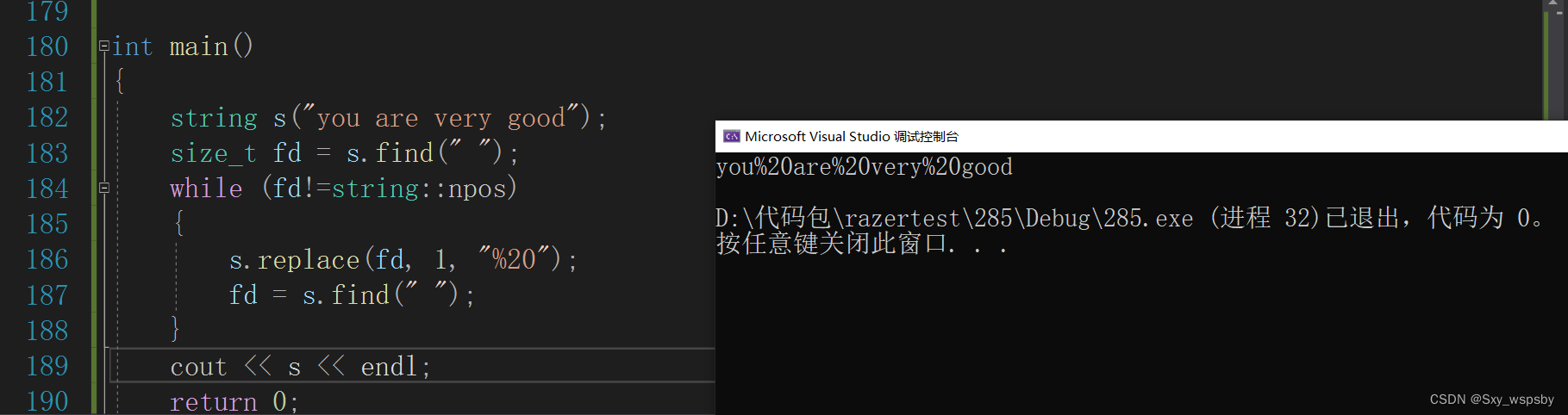
看到以上的代码我们还能在优化一下吗?答案是可以,我们每次查找完一个空格就没必要再重头开始查找了,我们从上一次的位置+3开始查找即可,为什么要+3不是+1呢?因为我们替换了%20是3个字符:
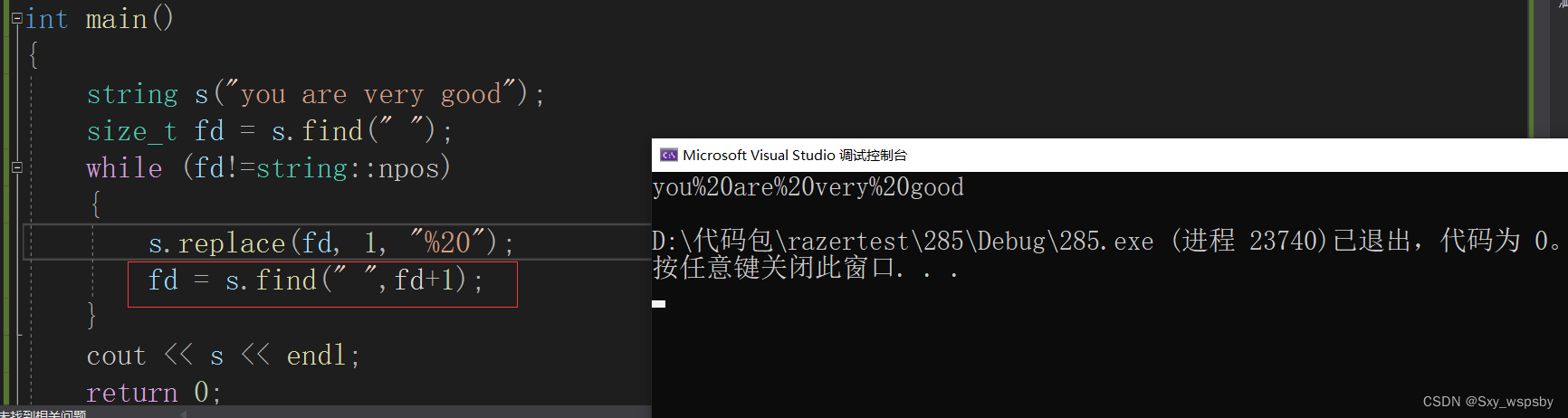
那么我们还能继续优化吗?大家还记得我们讲的reserve函数吗,我们可以提前开好空间避免在替换字符的过程中持续开空间浪费时间。
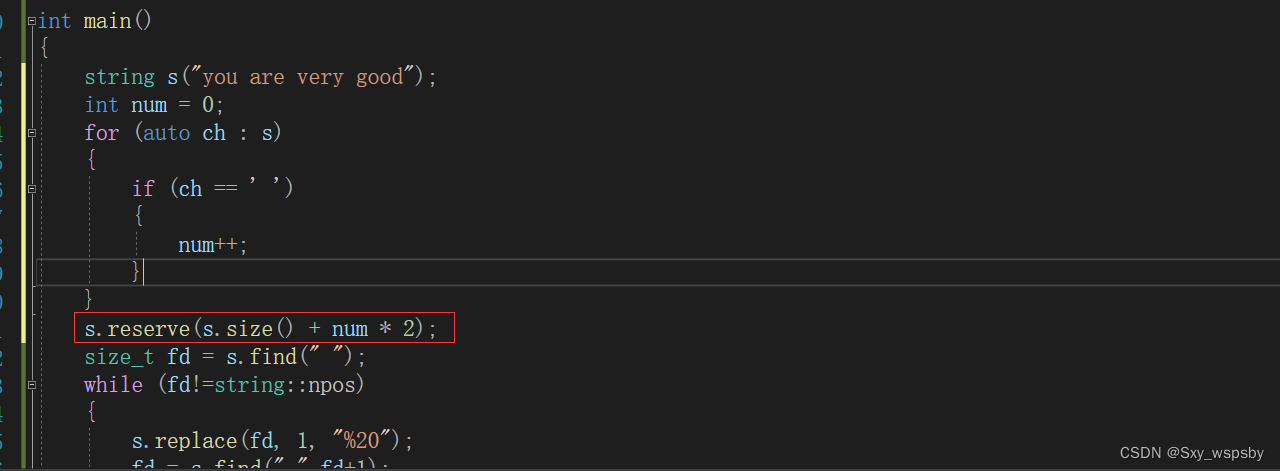
我们用另一种方法再做一次:
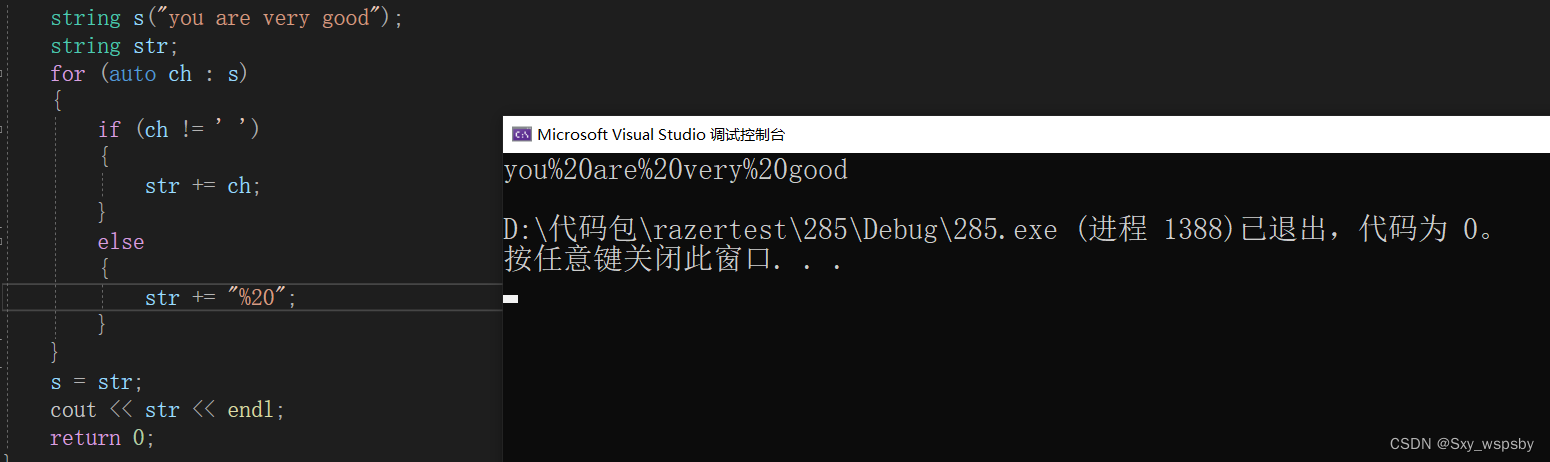 这次的效率很明显是高于上面那种方式的,当然这样的方式提前开好空间效率也会提升不少。
这次的效率很明显是高于上面那种方式的,当然这样的方式提前开好空间效率也会提升不少。
下面我们来看一下string中的字符串是如何扩容的:
int main()
{
string s;
size_t sz = s.capacity();
cout << "making s grow:\n";
cout << "capacity changed:" << sz << '\n';
for (int i = 0; i < 100; i++)
{
s.push_back('c');
if (sz != s.capacity())
{
sz = s.capacity();
cout << "capacity changed:" << sz << '\n';
}
}
return 0;
}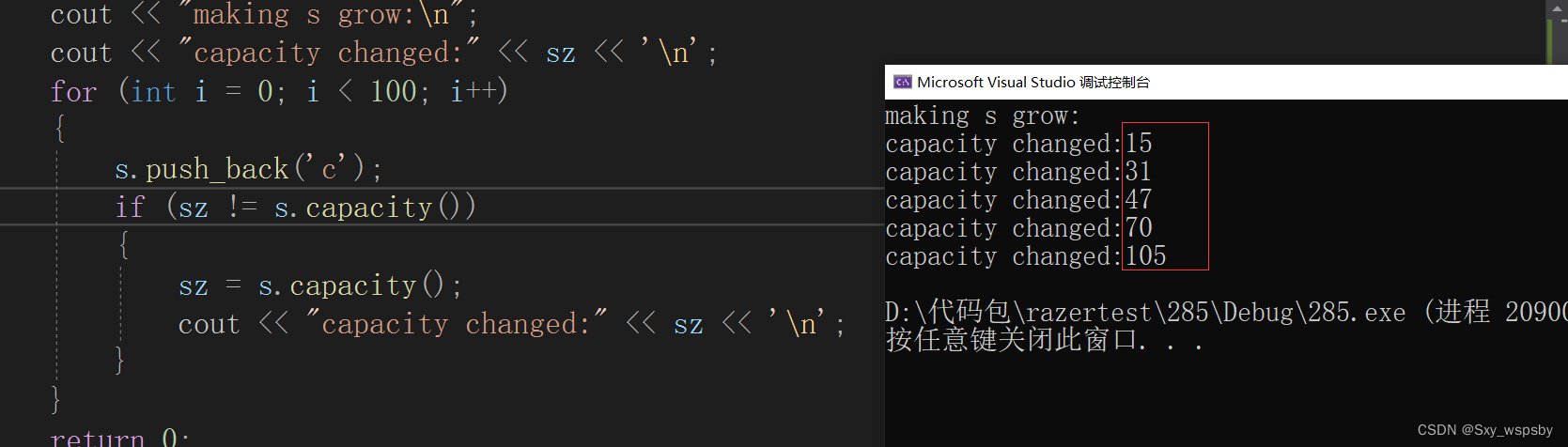
我们可以看到在vs下是按照1.5倍进行扩容的。
接下来我们看一下一个字符串的大小:

为什么一个空字符串的大小为28呢?看下图:
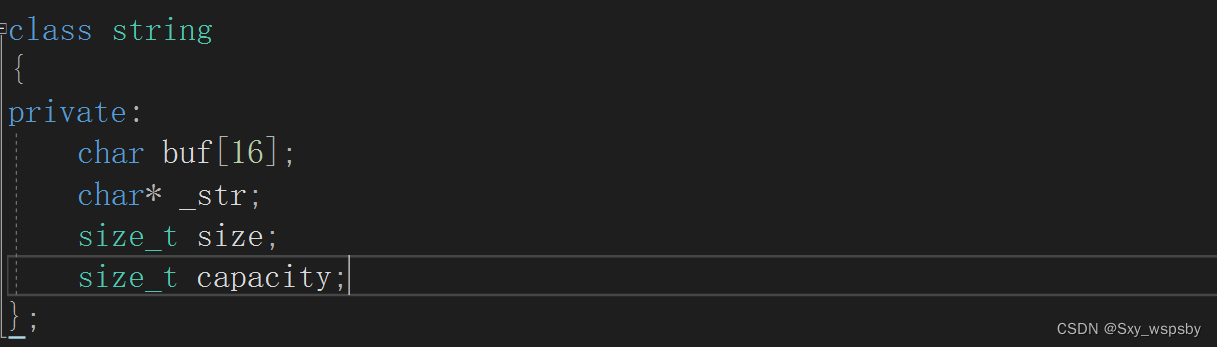 在VS下string的底层是这样实现的,当字符串很小的时候就不用频繁的开空间了直接用数组即可,当字符串很大就需要用_str开空间,所以大小为28,下面我们看看linux下的:
在VS下string的底层是这样实现的,当字符串很小的时候就不用频繁的开空间了直接用数组即可,当字符串很大就需要用_str开空间,所以大小为28,下面我们看看linux下的:
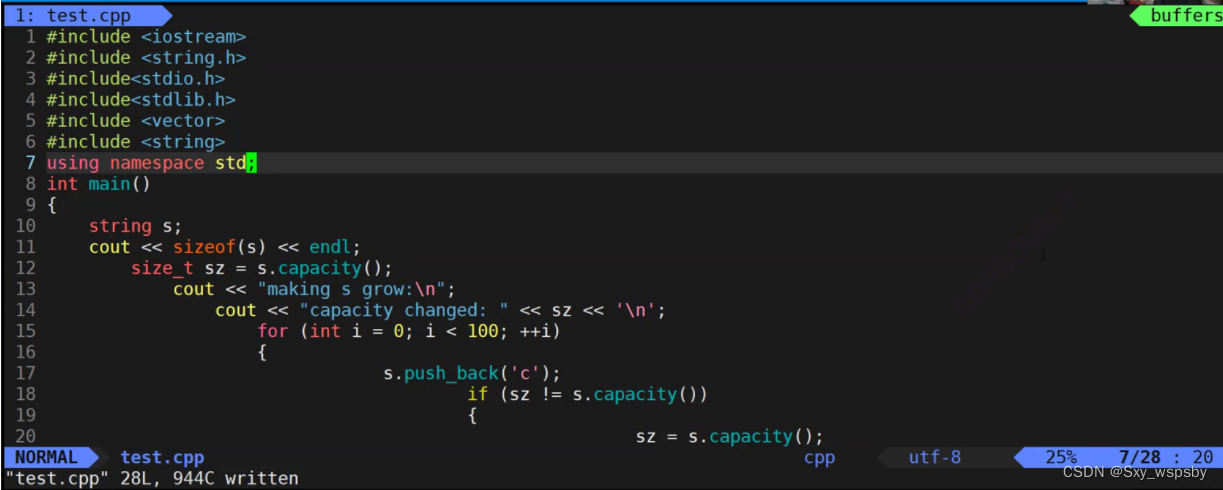
同样的代码我们运行起来:

我们发现在linux下是严格按照2倍扩容进行的,而且字符串大小为8,那么为什么linux下没有size和capacity变量呢?因为linux下的string是按照写时拷贝实现的,string对象内部只有一个指针,8字节是因为在64位地址下,该指针将来指向一块堆空间。
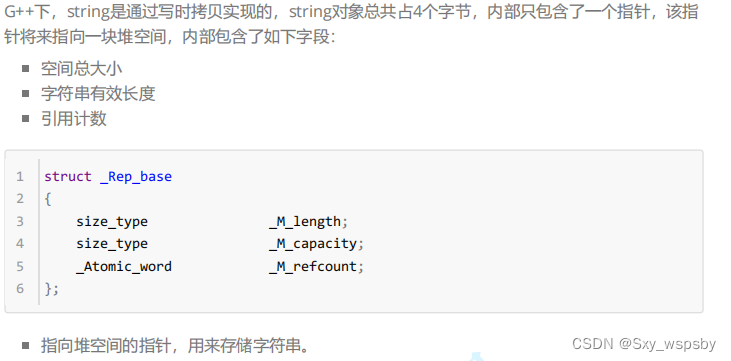
string迭代器的使用:

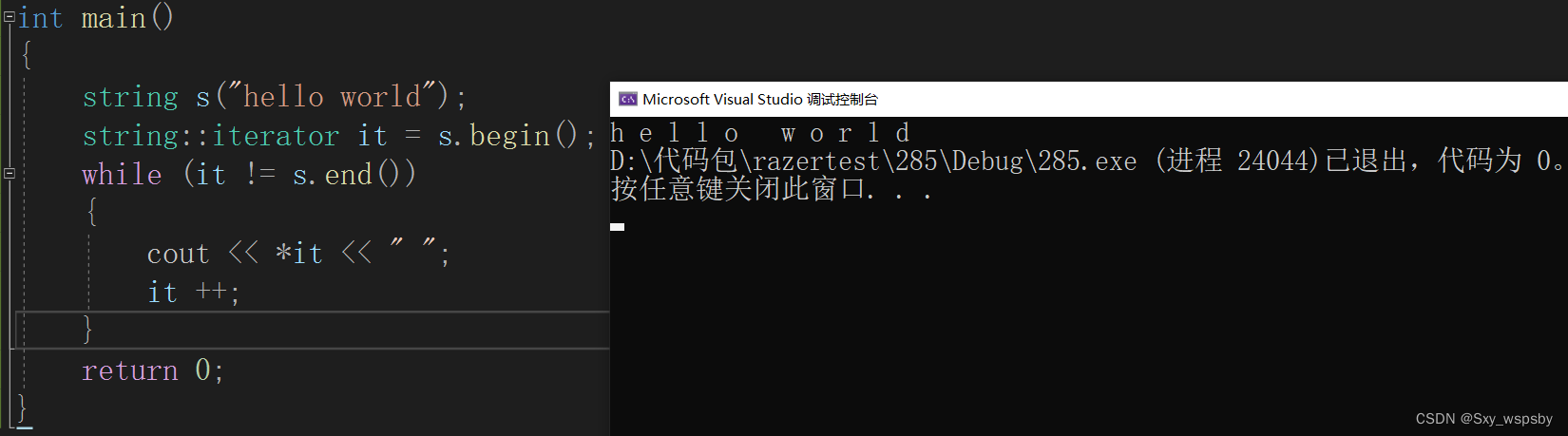 要注意的是迭代器的区间是左闭右开的如下图:
要注意的是迭代器的区间是左闭右开的如下图:

把begin给it这里的it就相当于指针,只有解引用后才是指针指向的内容。而我们最喜欢使用的语法糖实际上就是用迭代器实现的,并且这个实现非常的简单,类似于宏替换。
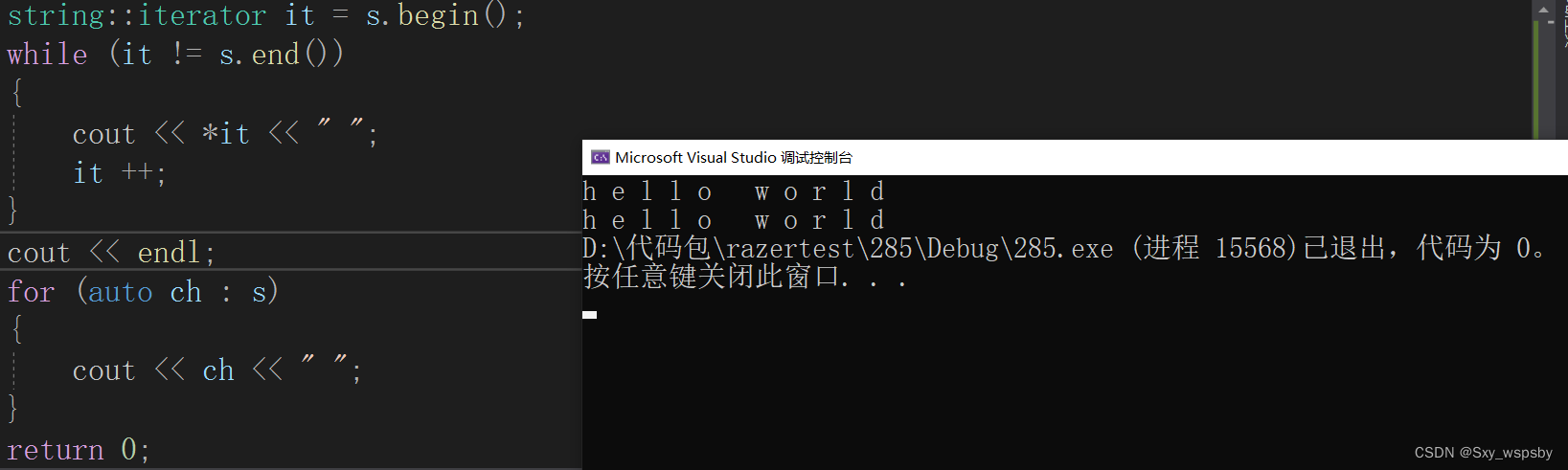

通过汇编我们也可以看到范围for实际上去调用迭代器的begin和end函数了。
接下来我们看反向迭代器的使用:
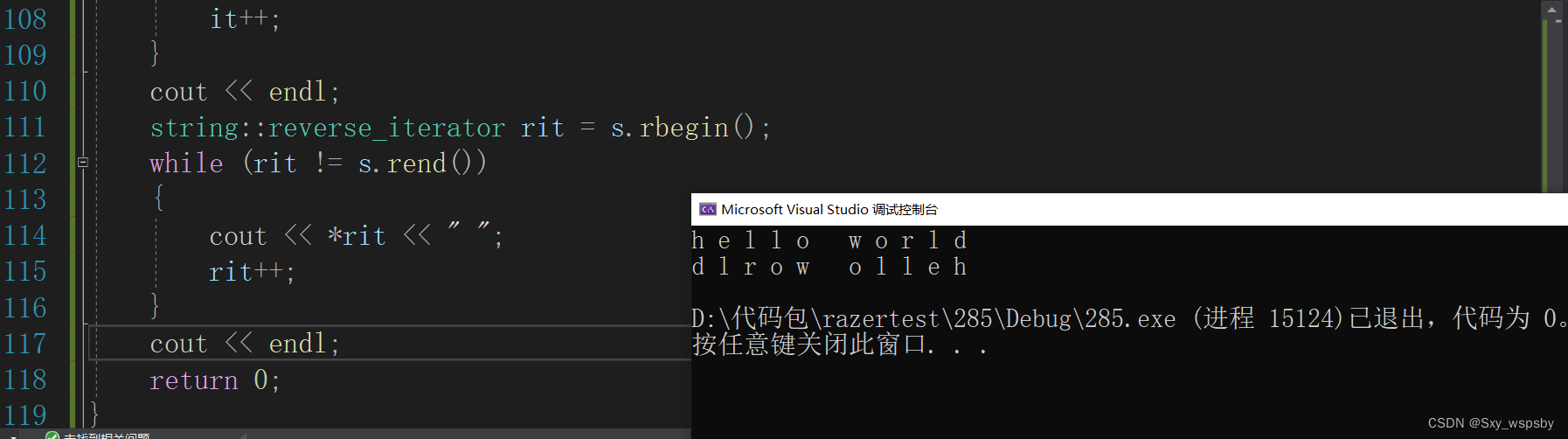 反向迭代器只需要在前面加上reverse即可,相对应的begin和end前面也加上r,需要注意的是反向迭代器原来的反方向,还是++向前走。
反向迭代器只需要在前面加上reverse即可,相对应的begin和end前面也加上r,需要注意的是反向迭代器原来的反方向,还是++向前走。
那么像下面这种情况该怎么办呢?
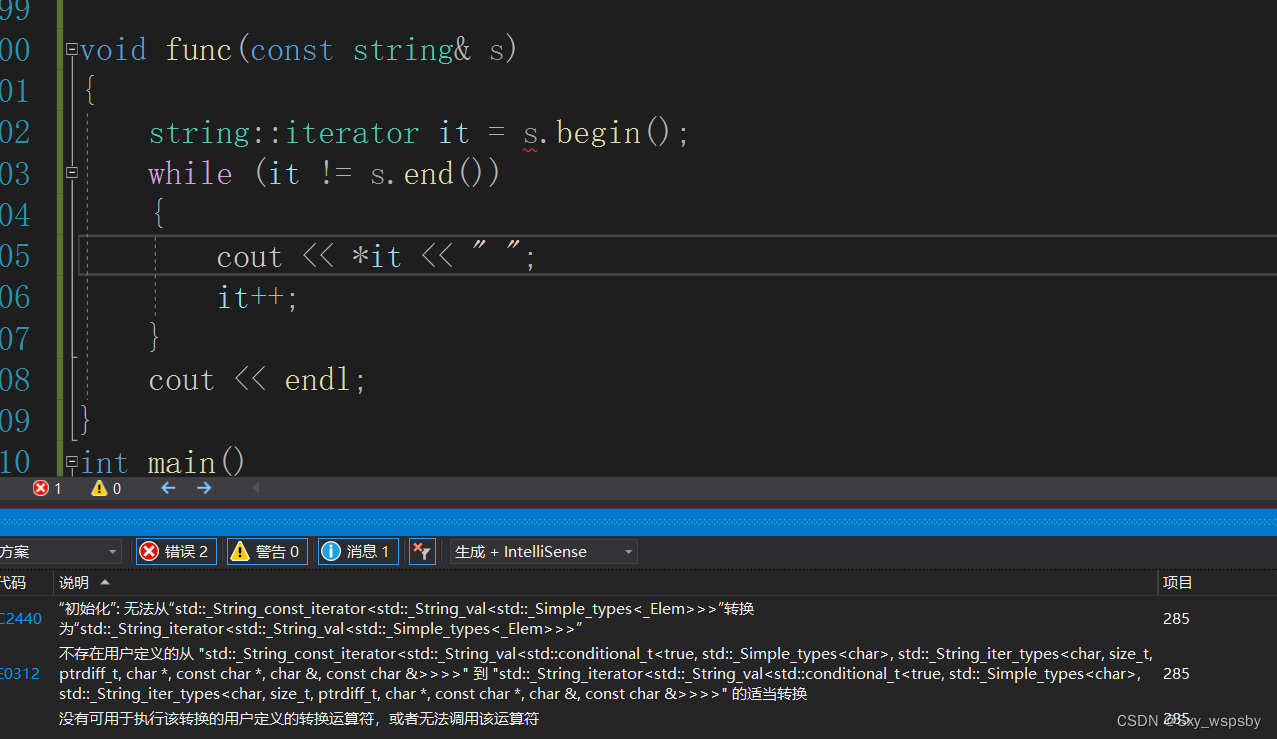
这种情况下我们就不能调普通迭代器了我们需要调用const迭代器。如下:
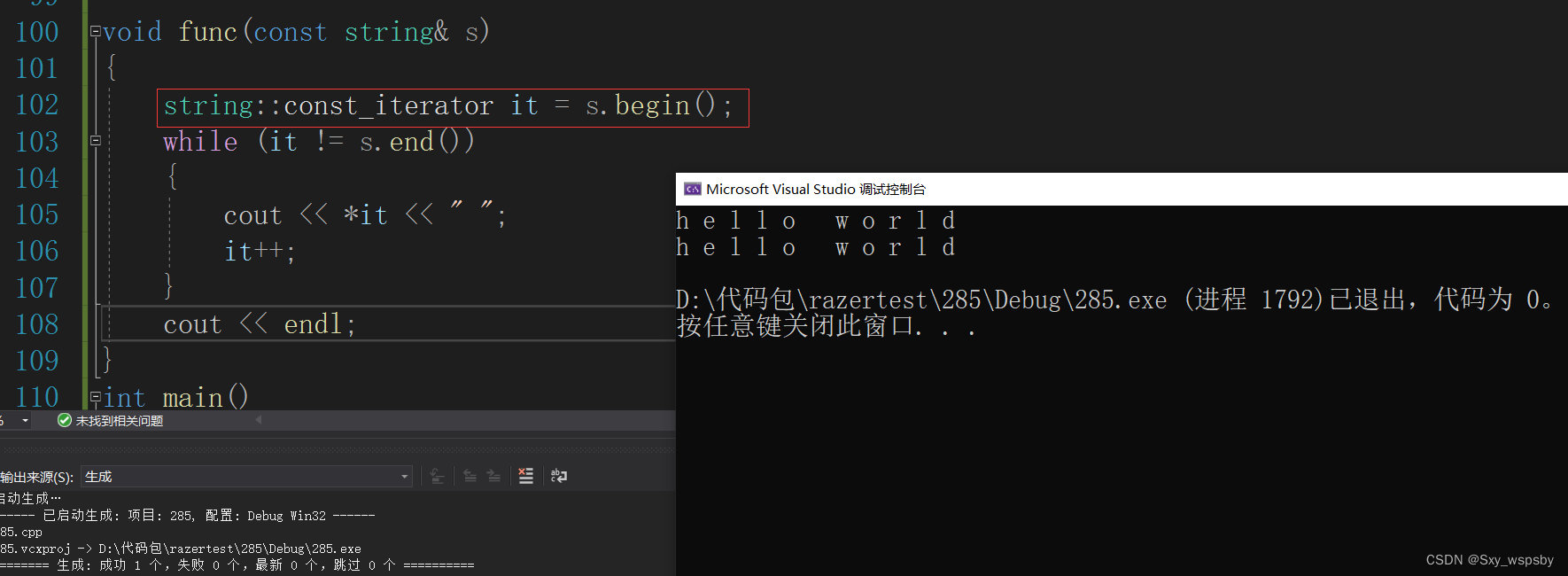 那么为什么存在const迭代器呢,因为我们有时候是不希望别人修改我们的代码的。
那么为什么存在const迭代器呢,因为我们有时候是不希望别人修改我们的代码的。
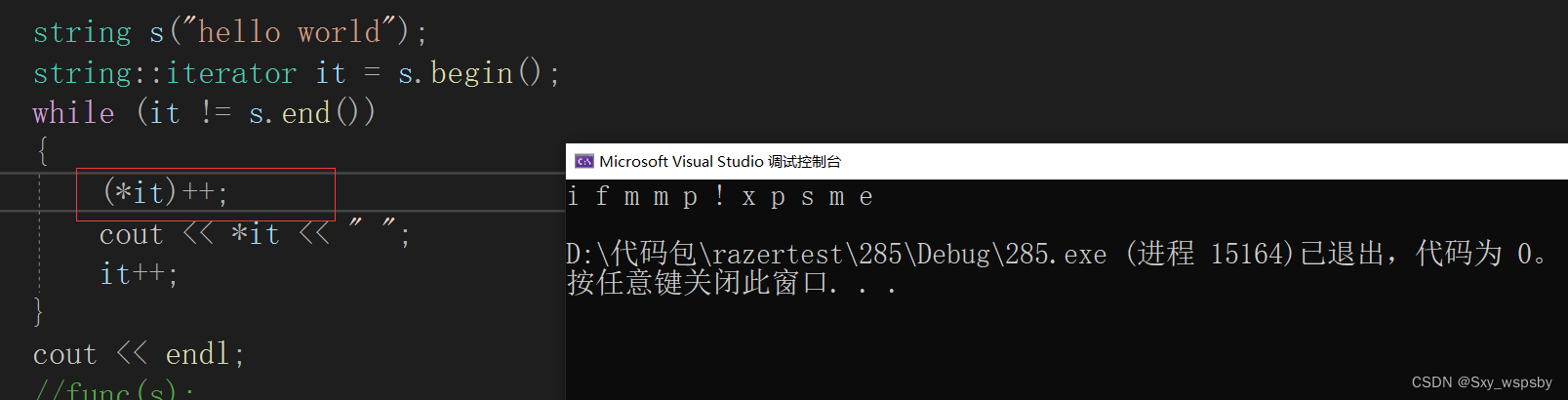
正常的迭代器允许我们去修改,但是const不行。
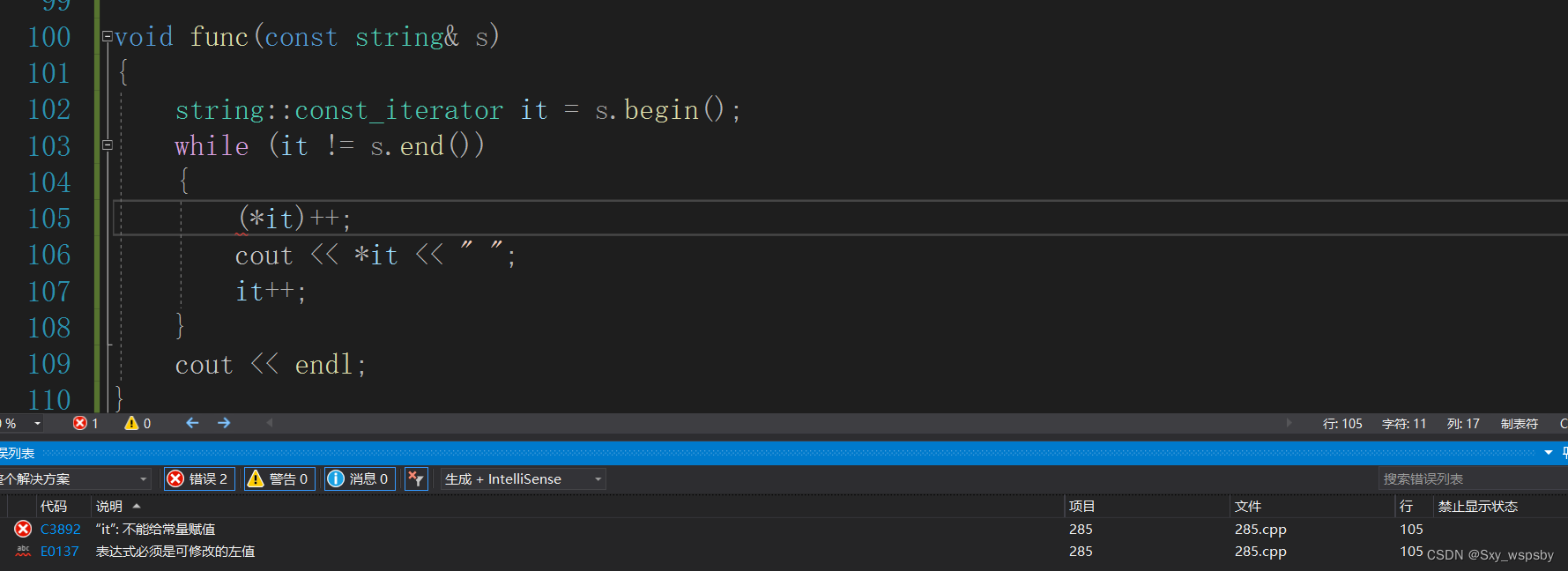 下面我们看一下string中用于访问的两个接口:
下面我们看一下string中用于访问的两个接口:

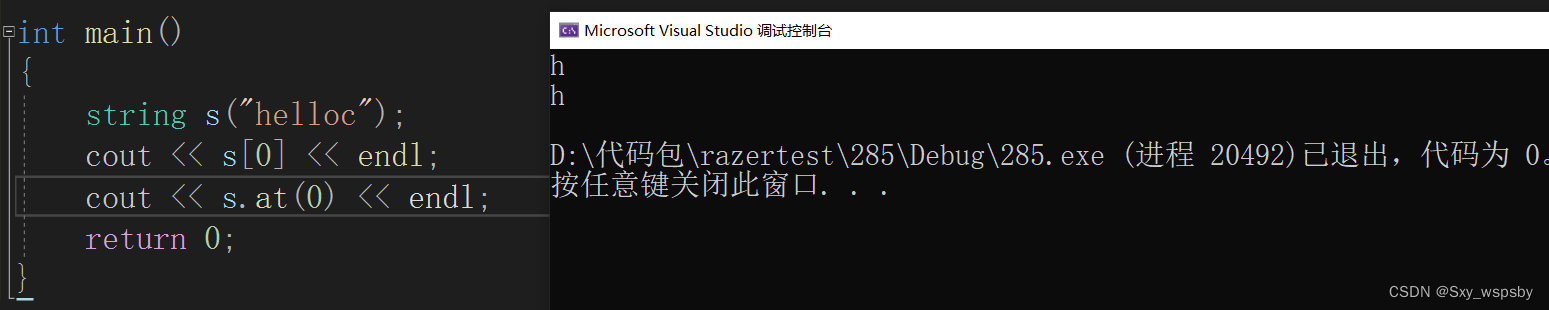
那么这两个接口有什么区别呢?
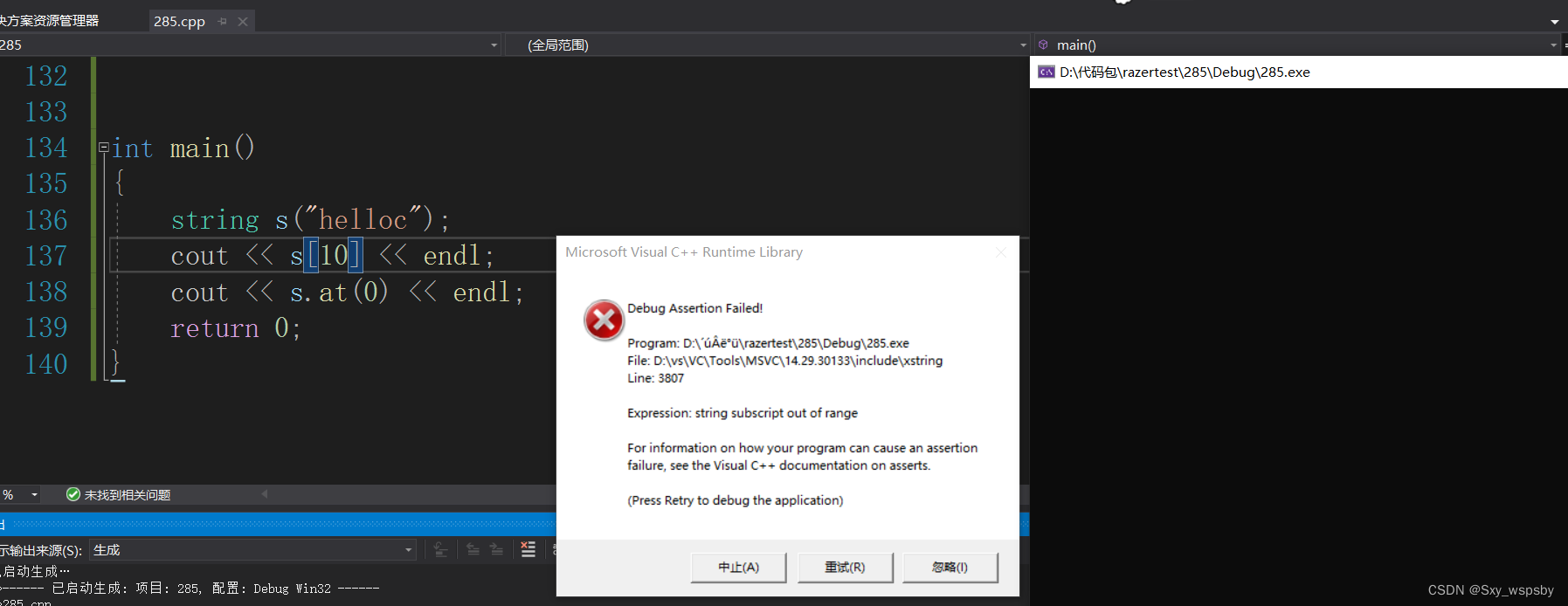
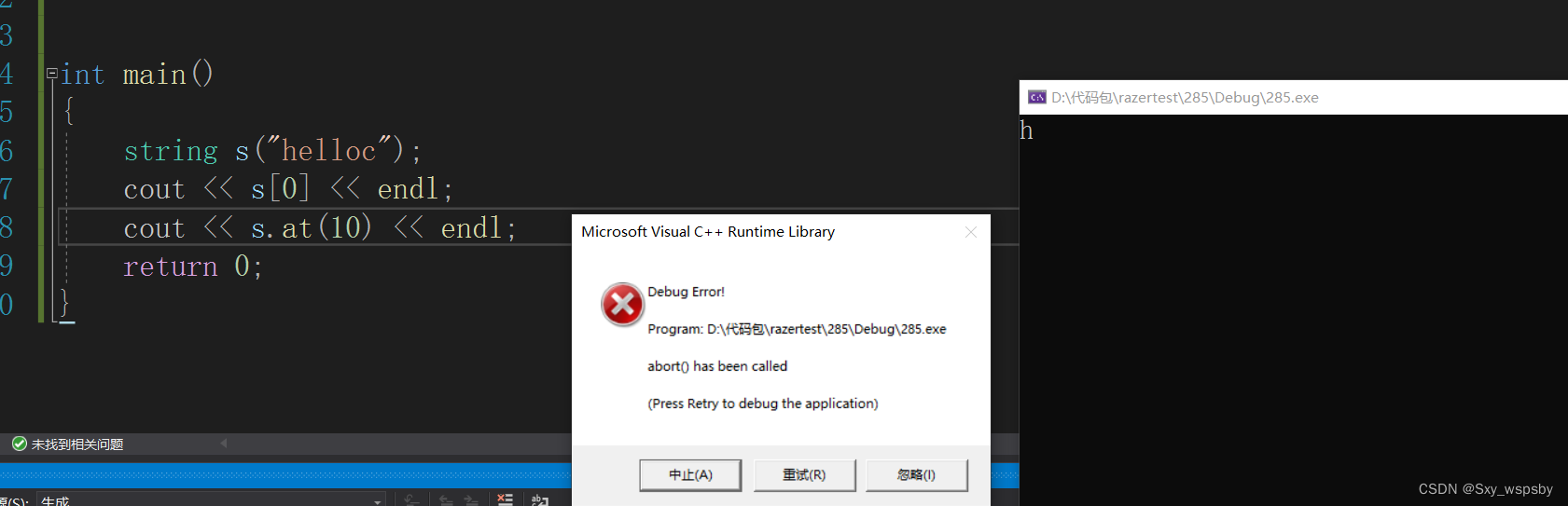
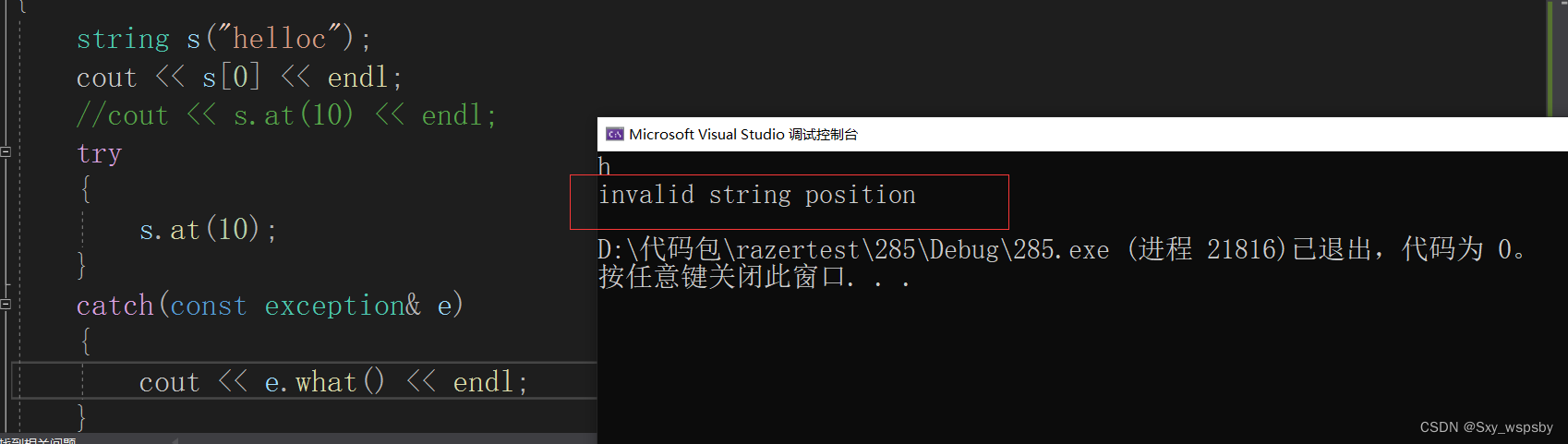 我们可以看到当用【】越界时会直接报错直接终止,而at则是抛异常。
我们可以看到当用【】越界时会直接报错直接终止,而at则是抛异常。
下面我们来看一下swap这个接口:
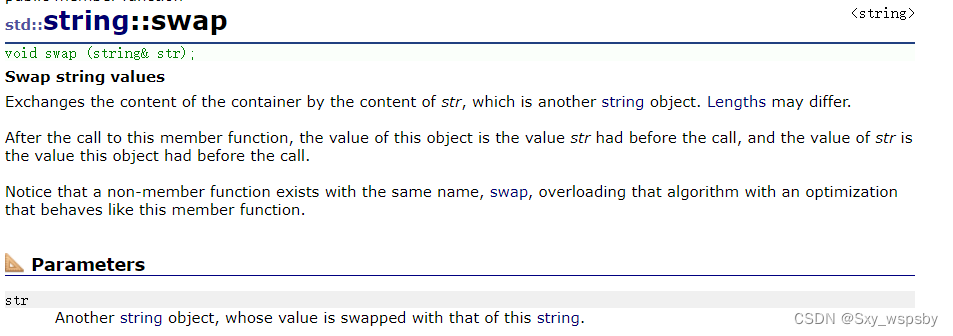
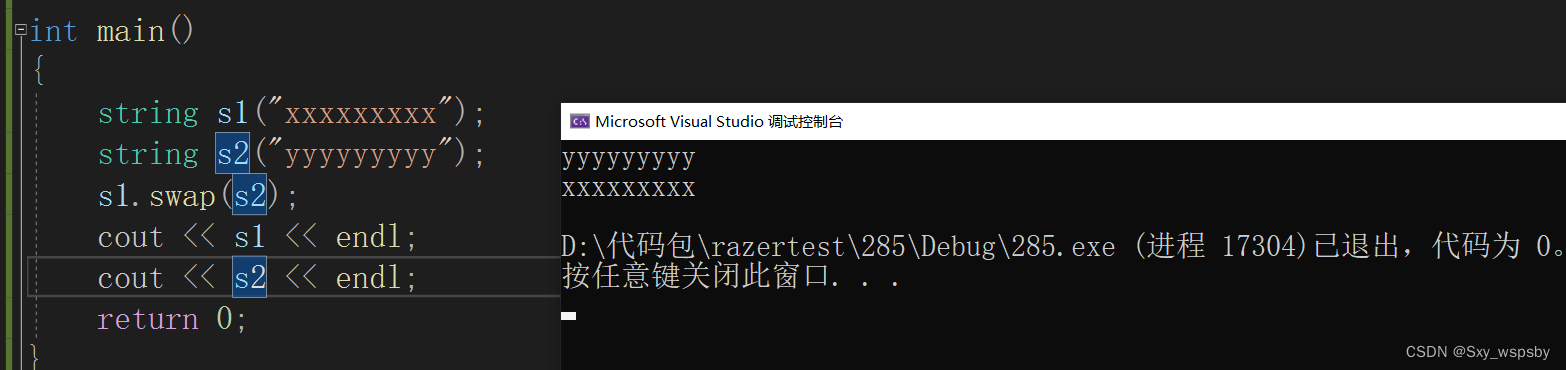
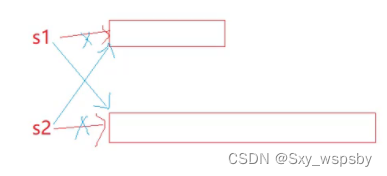
string中的swap与std::swap是不一样的,string中的swap是直接换指针的指向,而std::swap则需要调用三次拷贝构造函数,所以string中的swap的效率是更高的。
下面演示一下c_str这个接口:
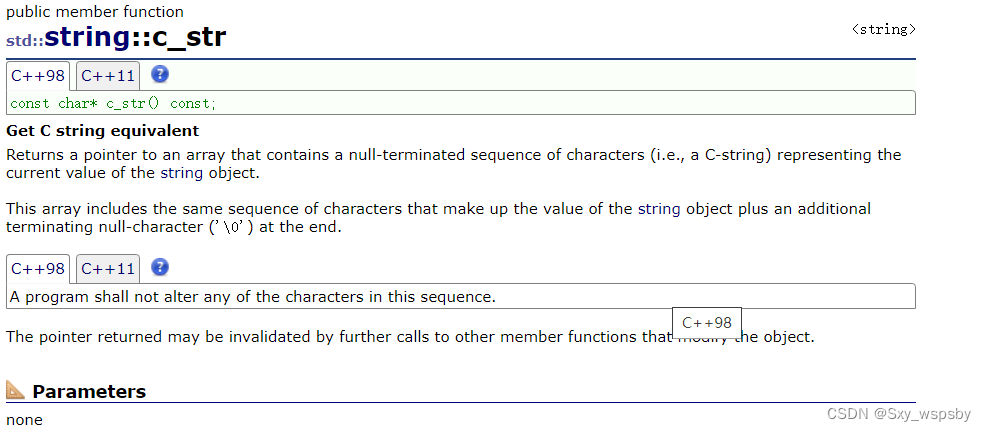
不知道大家是不是会有疑问,c_str和直接打印有什么区别呢?看下图:
 c_str是按字符串进行打印的,也就是说遇到\0就停止。而直接打印是按照字节数也就是size去打印,不去管\0.
c_str是按字符串进行打印的,也就是说遇到\0就停止。而直接打印是按照字节数也就是size去打印,不去管\0.
接下来看substr这个接口:
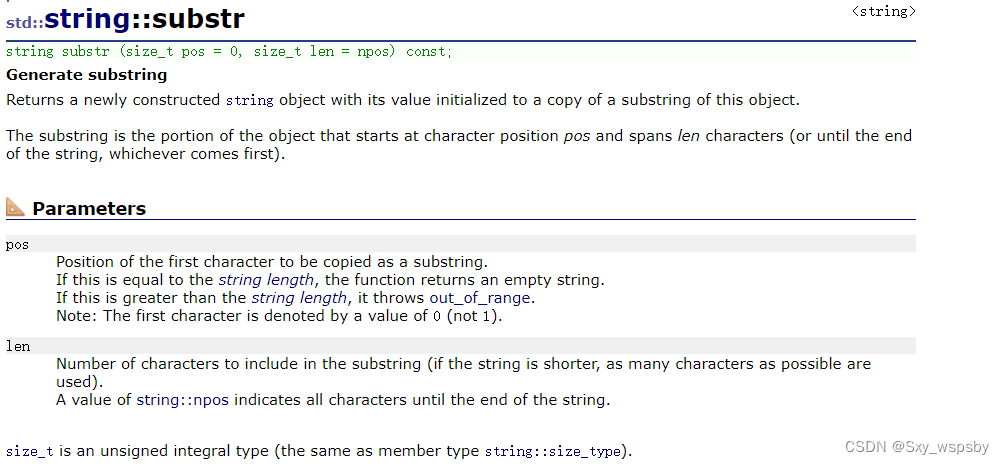
substr是取从pos位置开始的len个字符的子串。find函数我们前面讲过,其实还有一个rfind函数,find函数是从前往后找,rfind函数是从后往前找。
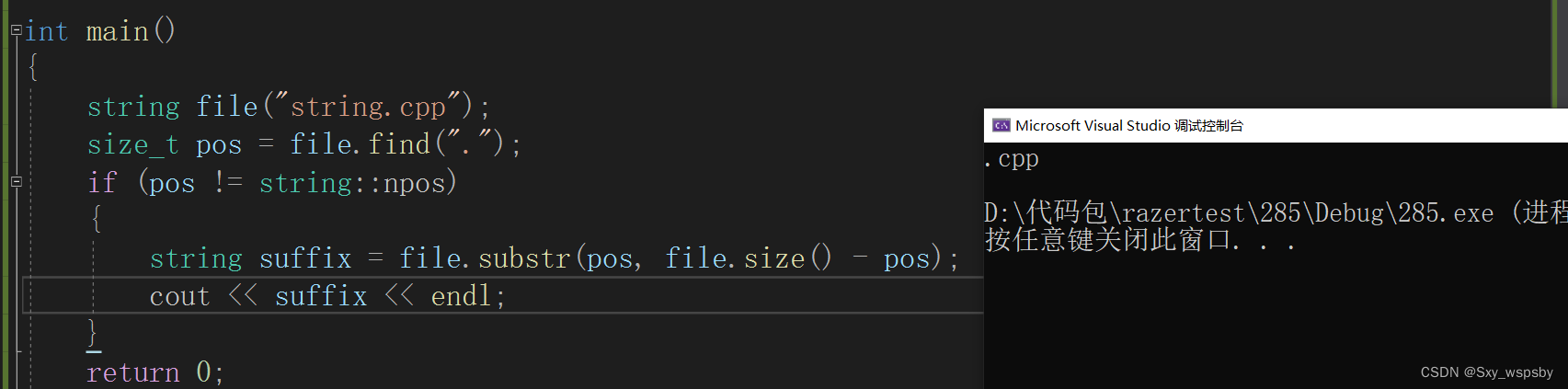
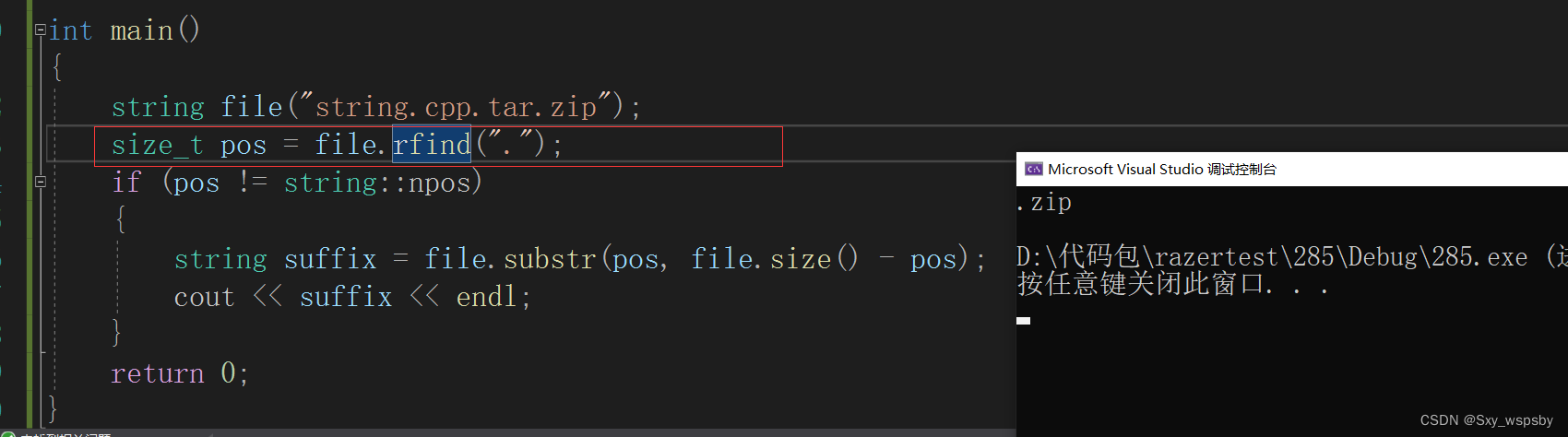 可以看到我们成功取到了文件的后缀。
可以看到我们成功取到了文件的后缀。
find_first_of: 从前往后查找任意一个出现在字符串内的字符

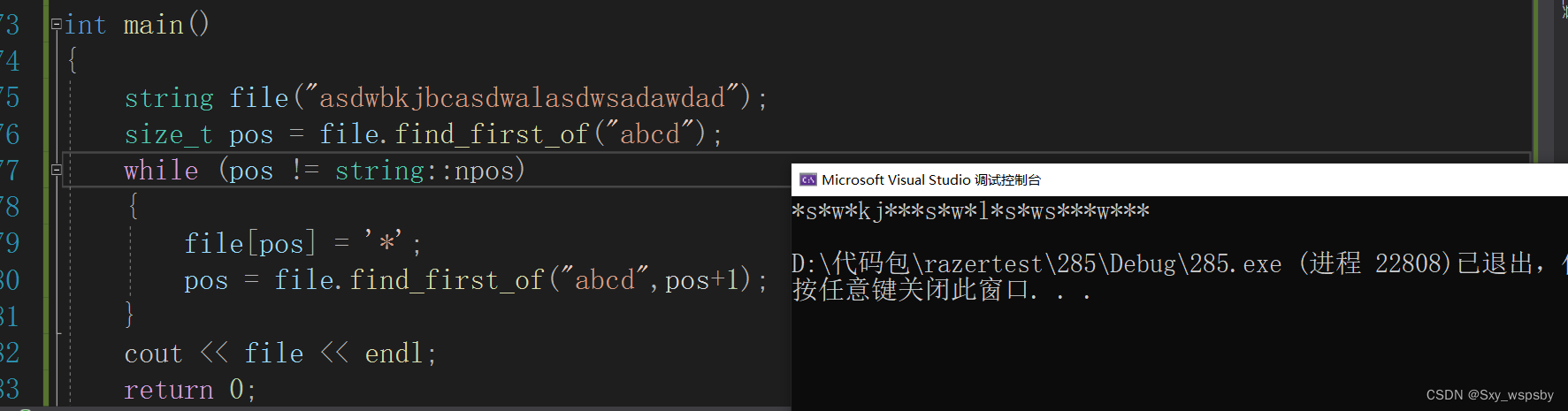 可以看到我们成功将abcd全部替换为*,还有一个与之对应的函数find_first_not_of,这个接口的作用是找到不在字符串中任意一个字符的位置。如下图所示:
可以看到我们成功将abcd全部替换为*,还有一个与之对应的函数find_first_not_of,这个接口的作用是找到不在字符串中任意一个字符的位置。如下图所示:
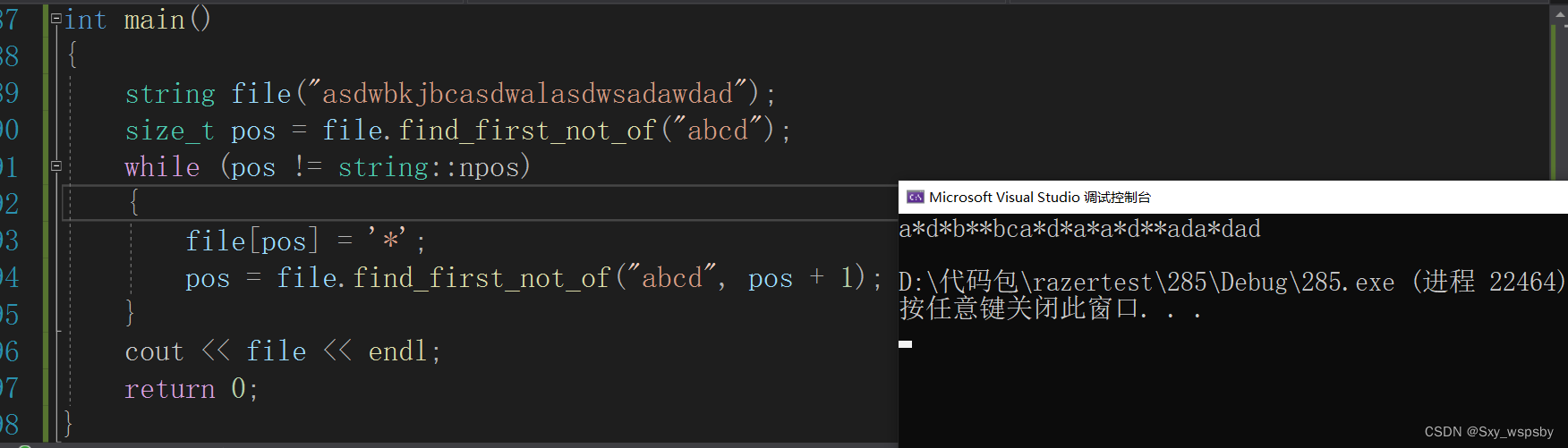
可以看到这个接口与find_first_of是相反的。
find_last_of: 从后往前查找任意一个出现在字符串内的字符
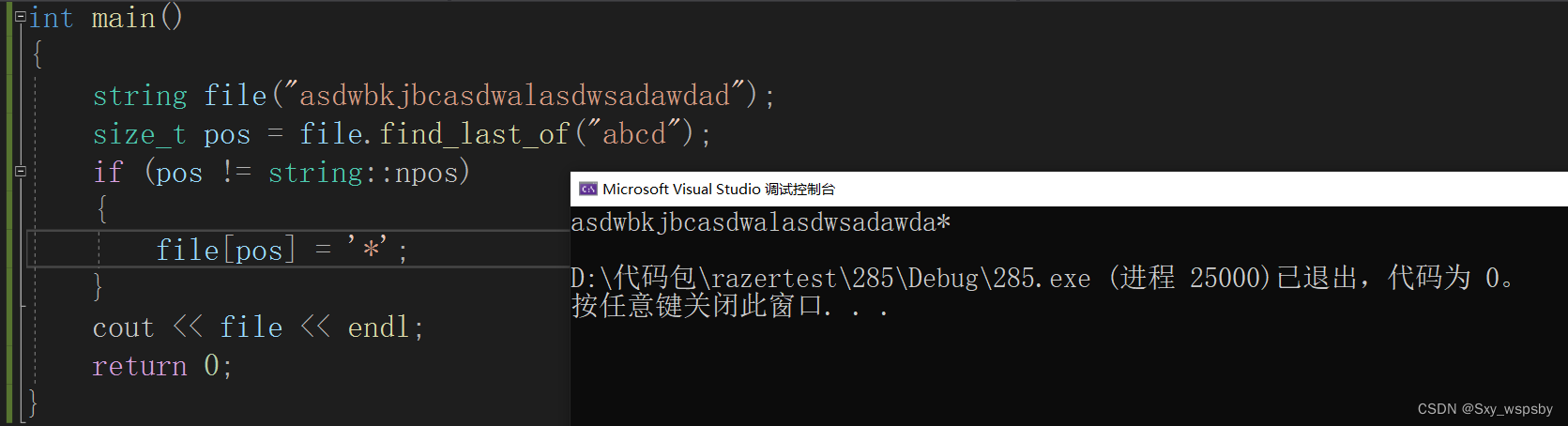
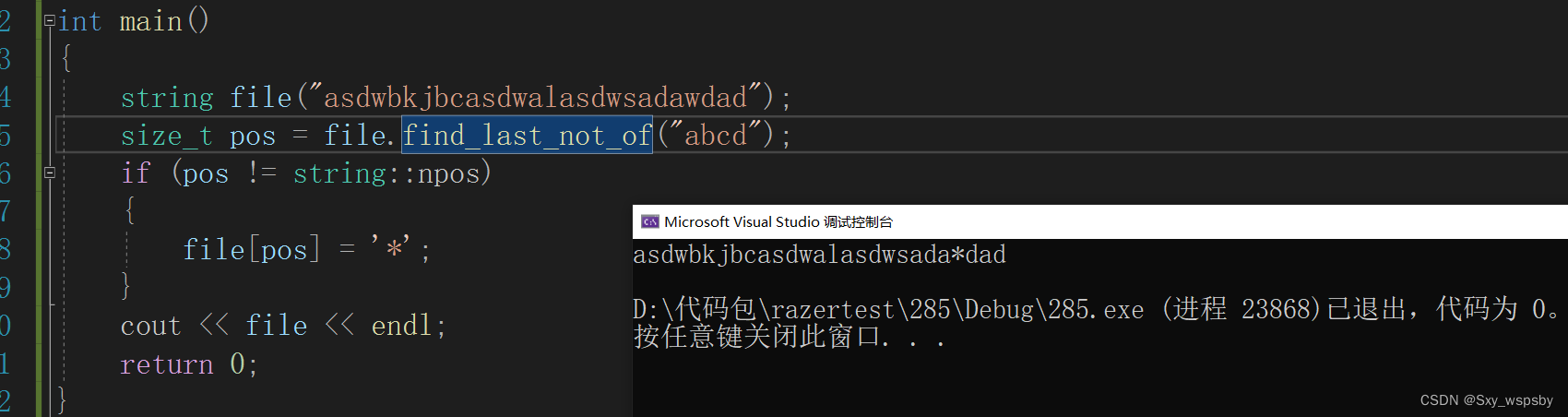
同样还有一个find_last_not_of接口是与find_last_of是相反的:
下面我们说一下字符串比较的几个接口,这里的比较与C语言一样都是通过比较字符的ascll码值来确定大小的,string中的接口compare是不经常用的,我们直接看运算符重载:
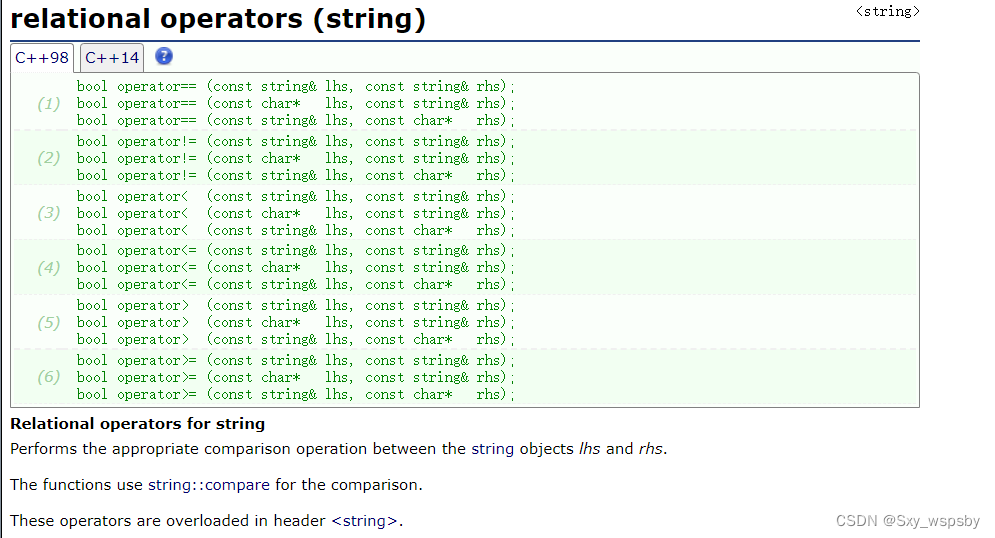
这里又再次说明了string中的接口是在太冗余了,光是相等这个重载就有三个,实在是不得不让人去吐槽。下面我们看怎么使用:
 也就是说我们可以直接对象与对象进行比较,对象与字符串进行比较,字符串与对象进行比较。后面的其他符号都与等于符号同理就不在一一演示了。
也就是说我们可以直接对象与对象进行比较,对象与字符串进行比较,字符串与对象进行比较。后面的其他符号都与等于符号同理就不在一一演示了。
下面我们讲一下getline这个接口,这个接口在写字符串类型的题目的时候非常有用:
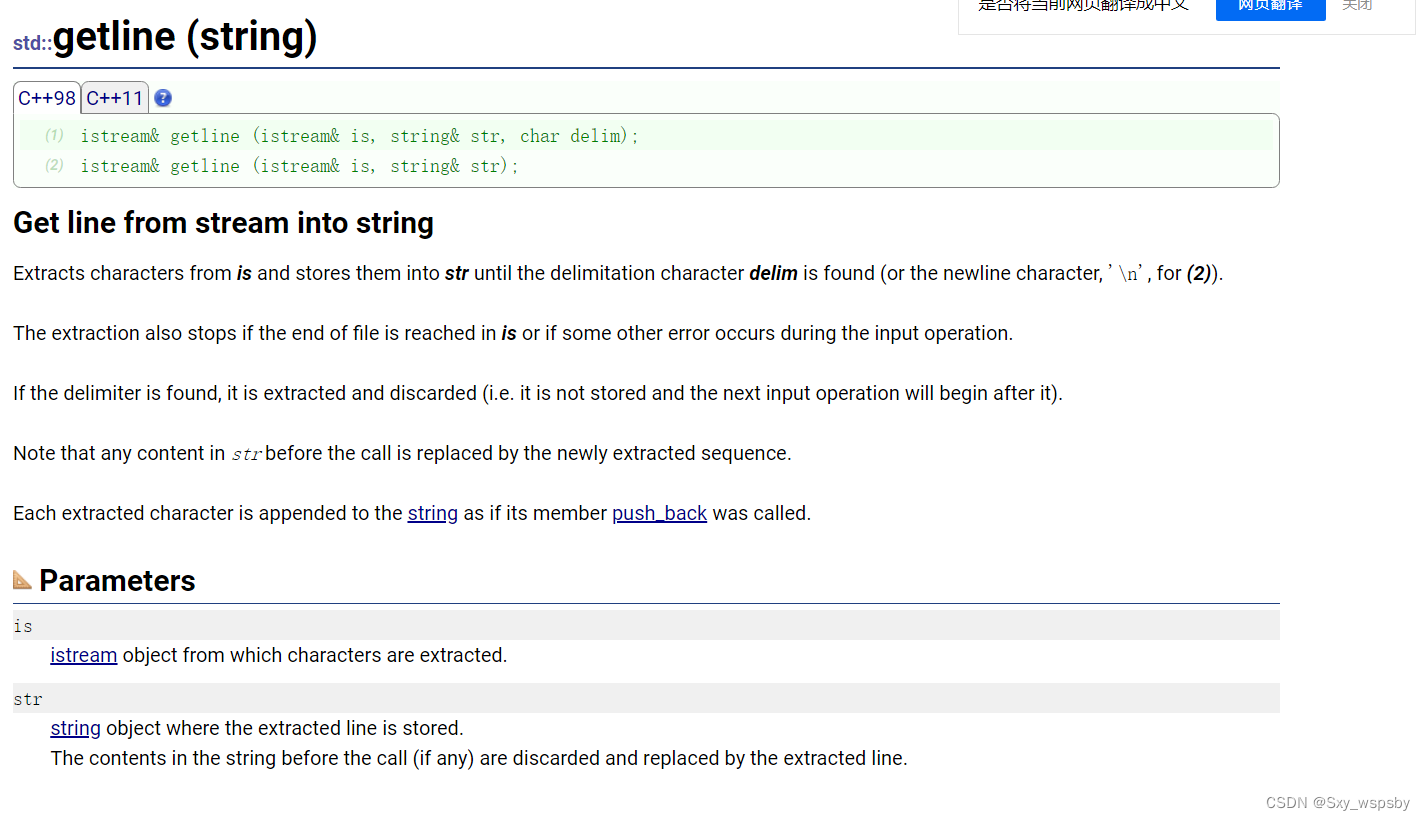
getline就是再我们用cin输入字符串的时候以换行作为结束标志,遇到空格不会结束。为什么要说这个问题呢,因为我们发现在做题的时候当输入一个字符串字符串中有多个空格的时候只会输出空格前的字符,而空格会被留在缓冲区。getline的第一个参数为cin,第二个参数为字符串。如下题:
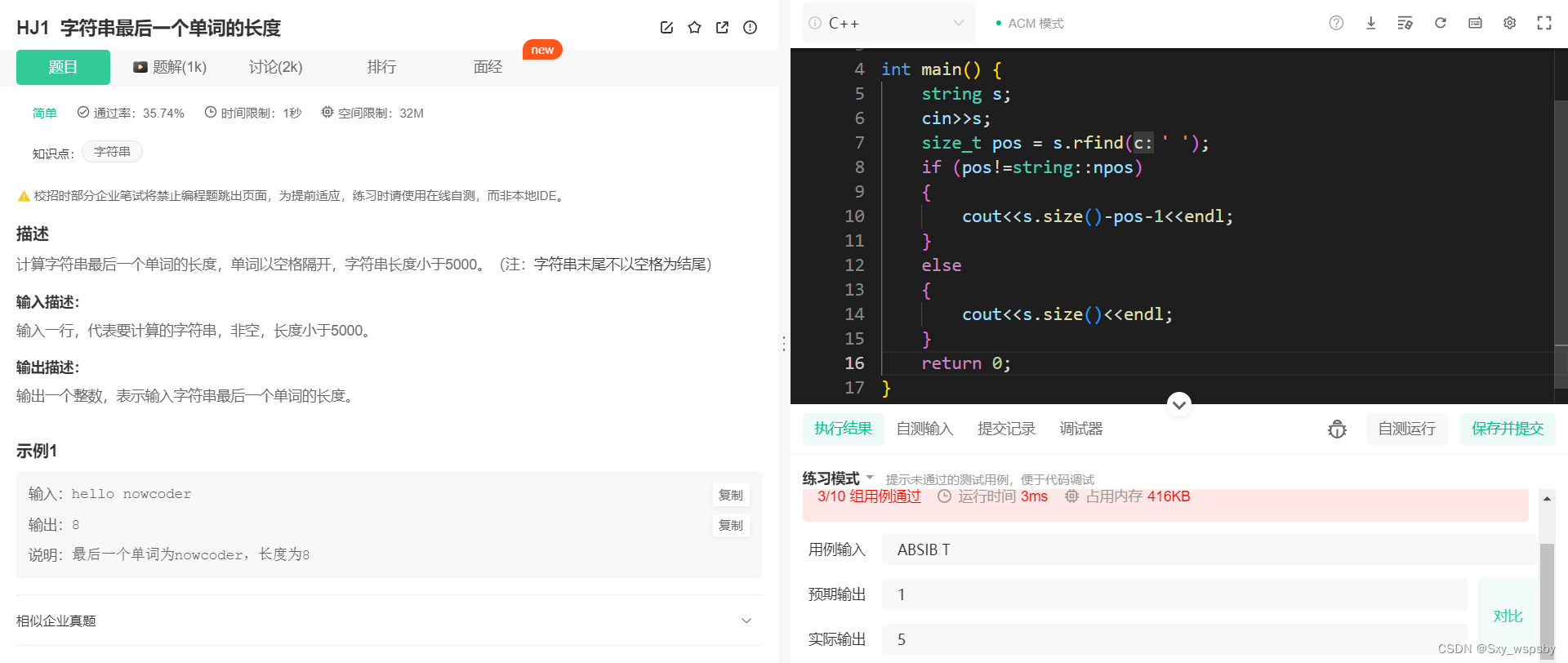
不通过的原因就是cin只识别了空格前面的字符,下面我们用getline来试一下:
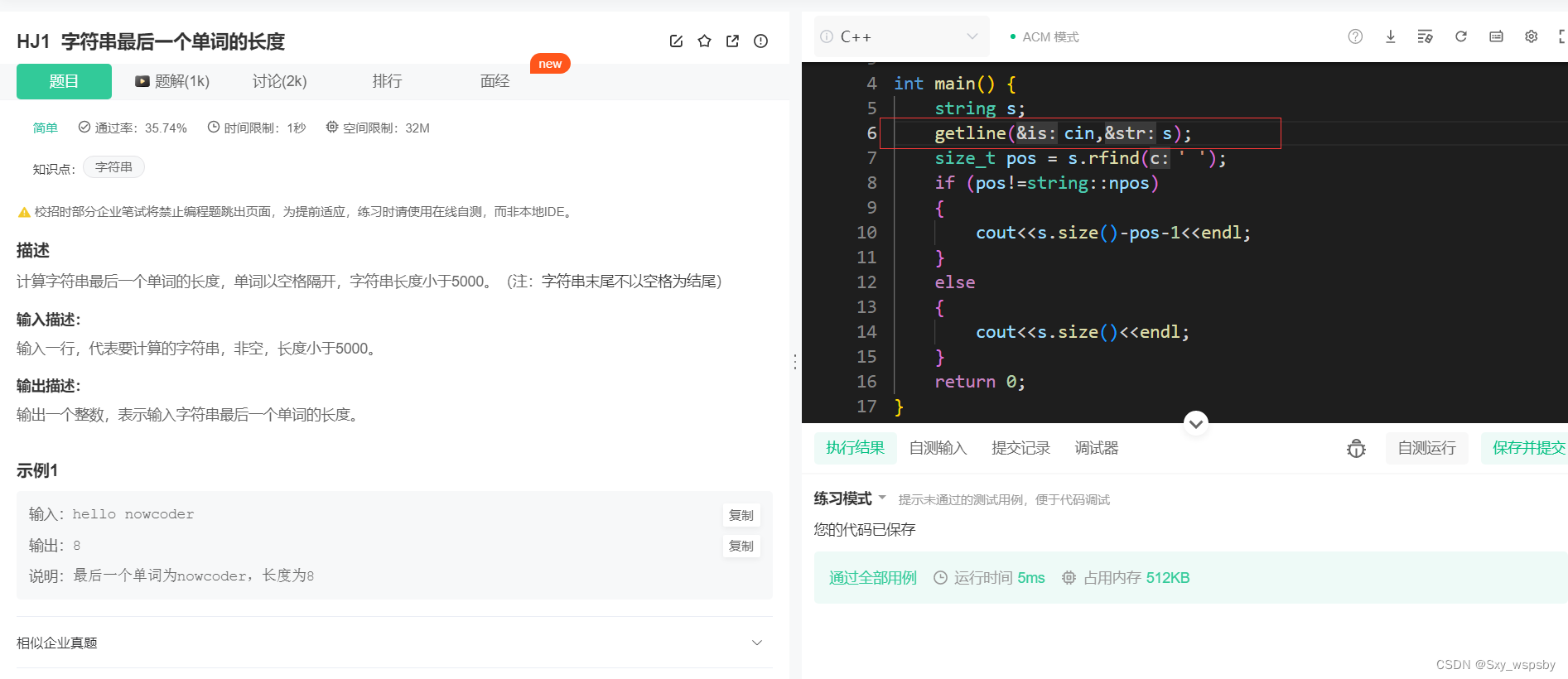 看来getline成功解决了我们的问题,所以在遇到这样输入带多个空格的字符串要用getline才可以。看到这里我们就已经把string的常用接口都演示了一遍,string一共有一百多个接口而其实大部分都是冗余的平时用不上的接口,大家就只需要把这个常用的接口用熟就能很好地使用string了。
看来getline成功解决了我们的问题,所以在遇到这样输入带多个空格的字符串要用getline才可以。看到这里我们就已经把string的常用接口都演示了一遍,string一共有一百多个接口而其实大部分都是冗余的平时用不上的接口,大家就只需要把这个常用的接口用熟就能很好地使用string了。
总结
string中的重要接口有以下几个:size() reserve() resize() operator+= c_str find + npos 以及比较操作符的重载,当然即使会使用这些接口也很可能对接口云里雾里,下一篇我们用c++模拟实现一个string类,届时大家可以更深刻的了解string。
![[深入理解SSD系列 闪存2.1.5] NAND FLASH基本读操作及原理_NAND FLASH Read Operation源码实现](https://img-blog.csdnimg.cn/img_convert/72f13a2b5cb2911feebdafaf3c42842e.png)






![[MySQL核心]2.select单表查询常见操作](https://img-blog.csdnimg.cn/fecff9377cf04eb0adfa189e7d65b94a.png)