MySQL核心--select单表查询常见操作
- select单表查询常见操作
- 关于通配符*的使用
- 结合MySQL运算符
- 去重distinct
- 空值查询
- union合并查询
- 带in子查询
- (重点)limit分页查询
- 排序order by
- 分组group by
- 笔试实践问题(新浪)
select单表查询常见操作
关于通配符*的使用
项目中最好不要使用这种不明确的方式,如果后面表的结构发生了改变,比如多了几个字段,
那么*就会多查询几个字段,不能保证这不会引入一些错误
select * from 表名;
最好明确字段:
select name,age,sex from user;
结合MySQL运算符
select * from user where sex='M' and age>=10;
select * from user where sex='W' and age between 10 and 30;
select * from user where sex='W' and age>=10 and age<=30;
select * from user where sex='W' and age>=10 or age<=30;
去重distinct
select distinct name from user;
空值查询
is [not] null
select * from user where name is null;
union合并查询

select * from user where age<=20 union all select * from user where age>=40;
带in子查询
[NOT] IN (元素1,元素2,…)
select * from user where id in (4,6,8,10);
select * from user where id not in (4,6,8,10);
select * from user where id in (select id from user where age>=20);
(重点)limit分页查询
- 基本使用
select * from user limit N; 取前N行
select * from user limit M,N; M表示偏移M行,N表示要取的行数
select * from user limit N offset M;
explain SQL语句; 查看SQL语句的执行计划(罗列出的一些关键信息并非准确,explain不解释MySQL的优化)
explain select * from user limit N offset M; explain反应不出limit的优化
limit仅仅只是对前面select查询的结果限制了数量吗?是否有做查询优化?
对于加了索引的字段来说,给出查询的限制条件,比如where name=‘张三’,依靠索引只需要查找一行,就能完成查询,但是对于没有添加索引的字段,比如user表中的age,根据比如where age=20这样的限制条件进行查找,进行的实际上是整表的查询,也就是需要逐行找过去,那靠后的数据的查找效率就会很低,而加了limit虽然依旧是逐行查找,但是一旦查到的数据量满足限制的条数,就完成查询了,而不是整张表查后,limit再限制显示的数量
- 创建一张测试数据表
CREATE TABLE t_user
(id INT(11) NOT NULL AUTO_INCREMENT,
email VARCHAR(255) DEFAULT NULL,
password VARCHAR(255) DEFAULT NULL,
PRIMARY KEY(id) 另一种添加主键约束的方式,这种方式可以添加联合主键
)ENGINE=INNODB DEFAULT CHARSET=utf8;
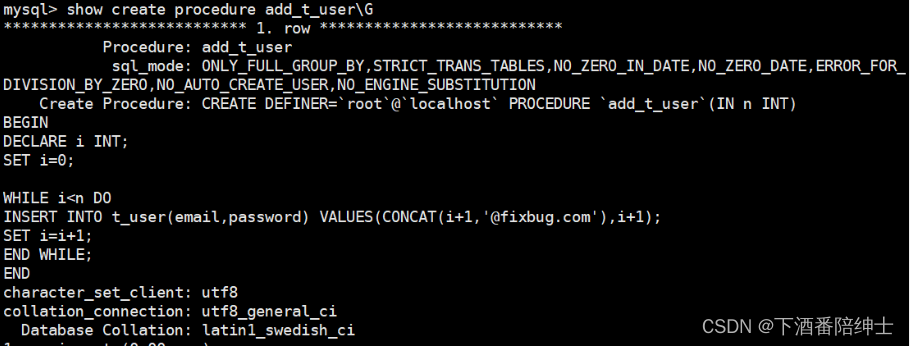
- 我们打算添加一个存储过程,并且通过call 执行存储过程来在数据表中添加一定规模的测试数据
说明:下面的语句不是一股脑的一起执行,需要分开执行的部分我都加了空行
delimiter $ 把SQL语句的分隔符由;-->$
Create Procedure add_t_user(IN n INT) IN表示输入参数
BEGIN
DECLARE i INT;
SET i=0;
WHILE i<n DO
INSERT INTO t_user(email,password) VALUES(CONCAT(i+1,'@fixbug.com'),i+1);
SET i=i+1;
END WHILE;
END$
delimiter ; 还原分隔符
call add_t_user(2000000); 调用存储过程
查看添加的存储过程:show create procedure add_t_user\G
我们来看一下limit对于查询的一个优化效果:
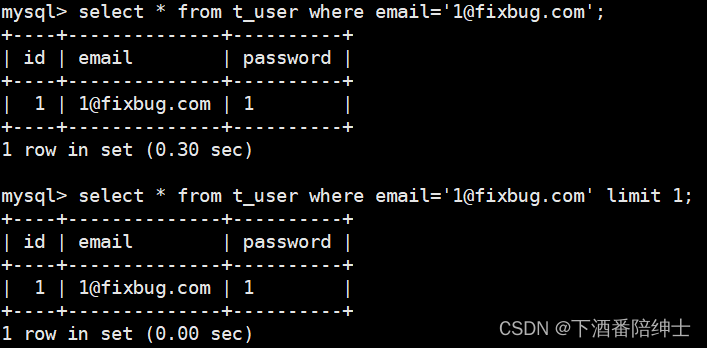
不添加limit 进行查找,要搜索整张表,耗时比较长;
添加了limit进行查找, 当查找到的数据量满足limit所限制的数量,就停止查找,所以耗时短
执行explain 查看select语句的执行计划,可以看到explain并没有解释limit对MySQL查询的优化,rows这行依然是接近2000000行:

如何实现数据的分页显示?
给定每页要显示的数据数量,比如pagenum=20,那么我们会执行以下SQL语句进行分页查询:
// pageno是每一页的页号(从1开始),(pageno-1)*pagenum表示偏移,pagenum表示要显示的行数
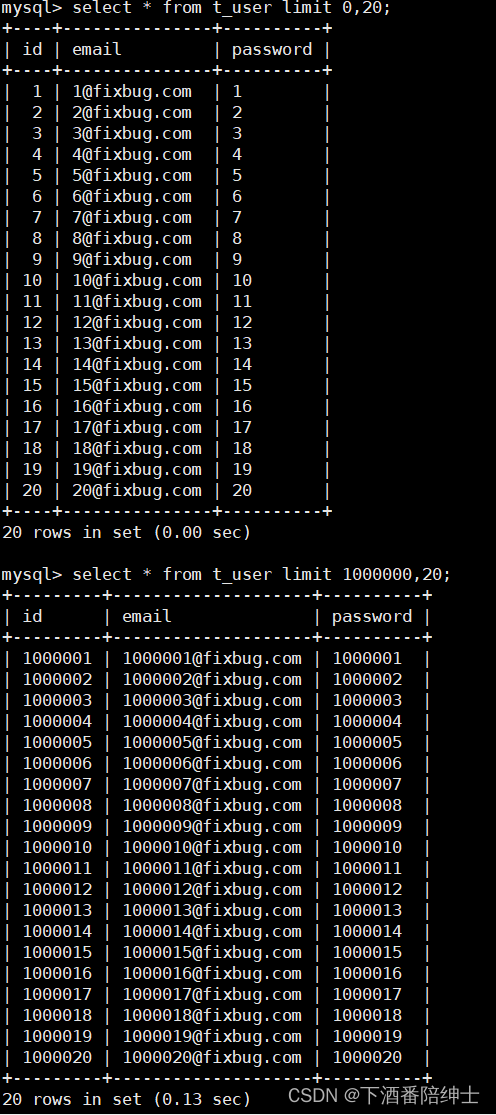
select * from t_user [限制条件(where...)] limit (pageno-1)*pagenum,pagenum;
但是以上的查询方式效率比较低,无法实现无论要显示哪一页的数据,查询时间都基本维持一致(查询时间常量)的要求,而影响查询效率的因素就是偏移,对于limit M,N 来说,偏移M表示查询时要扫前M行,所以页数越晚后,查询效率就越低:
如何过滤掉M所耗费的性能呢?
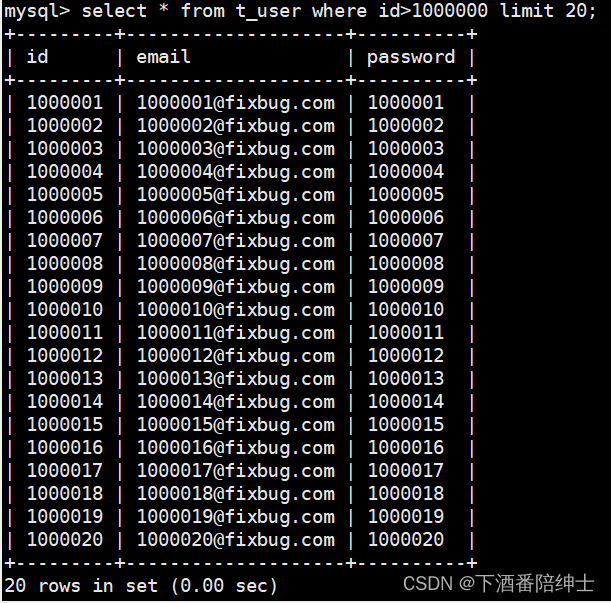
我们使用索引字段id来过滤数据,通过索引字段我们可以以常量时间过滤掉前面页面的数据
select * from t_user where id>上一页最后一条数据的id limit 20;
排序order by
select * from user [where...] order by name; 按照姓名默认升序排序
select * from user [where...] order by name desc; 加上desc降序排序
select * from user [where...] order by name,age; 先比较name,如果name一样再比较age,默认升序排序
接下来我们使用explain查看SQL语句的执行计划:
explain select * from user order by age;

可以看到type字段是ALL,代表的是整表搜索,另外注意Extra字段的值是Using filesort,即文件排序(外排序),我们一般会采用n路归并排序,对于外排序来说,最重要的一个问题是当磁盘上的数据量太多,而内存又比较小无法把磁盘上的所有数据都加载到内存上,所以采用n路的归并排序的思想,但是这会涉及到大量的磁盘IO,导致查询效率降低。
我们接着查看下面语句的执行计划:
explain select * from user order by name;

explain select name from user order by name;

可以看到当我们选取name为待排序字段,并且要查询name字段的信息时,我们发现排序方式变成了使用索引进行排序,注意name字段是索引字段,说明order by的性能不仅与选取的待排序字段有关还与要查询的字段有关。
分组group by
-
基本语法
常结合聚合函数做数据的统计
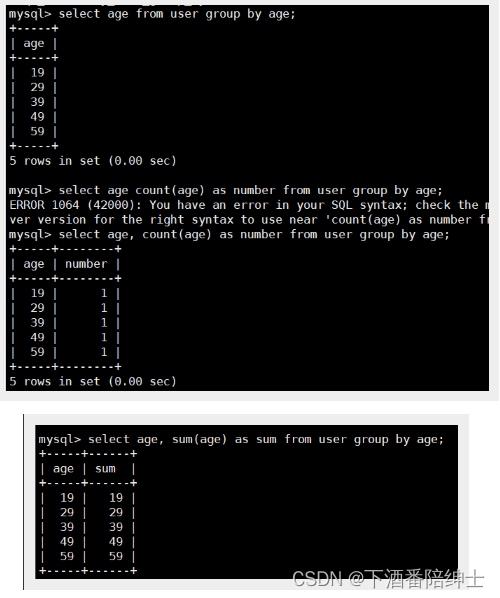
select age from user group by age; // 按照age分组,select后跟进行分组的字段,查看age的分布情况
select age, count(age) as number from user group by age; // 统计每组的数据量
select age, sum(age) as sum from user group by age; // 每组所有age相加的结果
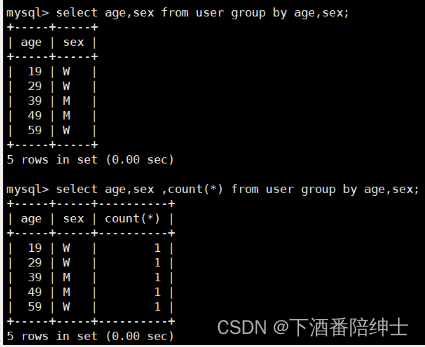
select age,sex from user group by age,sex; // 可以指定多个字段,多个字段都相同的就分为一组
select age,sex ,count(*) from user group by age,sex; // 统计每组的数据量
加上过滤条件
select age from user where age>20 group by age; // 分组前进行数据筛选,一般推荐这种方式,因为用来进行数据筛选的字段如果是索引字段能够确保查询效率
select age from user group by age having age>20; // 分组后再筛选数据

结合order by
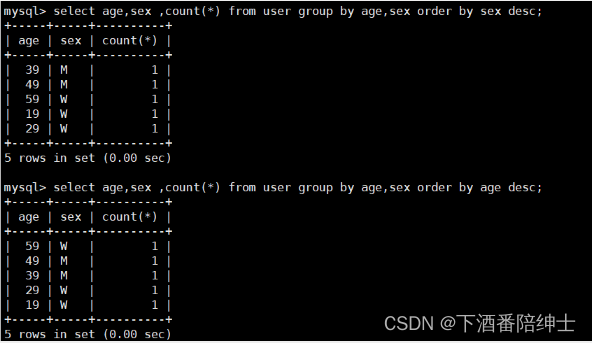
select age,sex ,count(*) from user group by age,sex order by sex desc;
select age,sex ,count(*) from user group by age,sex order by age desc;
- group by的性能分析
使用explain 查看语句的执行计划
explain select age from user group by age;

我们从图上可以看到,其实group by自带了order by,会按照分组的字段进行升序排序,本次分组我们使用了age字段,从Extra字段可以看到,此次分组需要创建临时表(用来排序),还要使用文件排序,如果数据表中的数据量较大,那么查询效率就会非常低了。
那我们换一个字段,使用带索引的字段name看看效果:
explain select name from user group by name;

可以看到这种分组方式仅使用了索引,查询效率非常高。所以group by和order by一样,性能和所选取的字段(索引字段)是相关的。
笔试实践问题(新浪)
先创建数据表bank_bill
CREATE TABLE bank_bill(
serno BIGINT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
date DATE NOT NULL,
accno VARCHAR(100) NOT NULL,
name VARCHAR(50) NOT NULL,
amount DECIMAL(10,1) NOT NULL,
brno VARCHAR(150) NOT NULL
)ENGINE=INNODB,DEFAULT CHARSET=utf8;
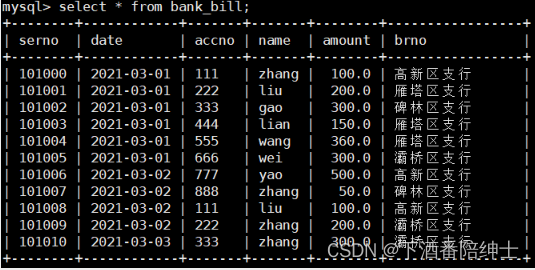
插入一些数据
INSERT INTO bank_bill VALUES
('101000','2021-3-1','111','zhang',100,'高新区支行'),
('101001','2021-3-1','222','liu',200,'雁塔区支行'),
('101002','2021-3-1','333','gao',300,'碑林区支行'),
('101003','2021-3-1','444','lian',150,'雁塔区支行'),
('101004','2021-3-1','555','wang',360,'雁塔区支行'),
('101005','2021-3-1','666','wei',300,'灞桥区支行'),
('101006','2021-3-2','777','yao',500,'高新区支行'),
('101007','2021-3-2','888','zhang',50,'碑林区支行'),
('101008','2021-3-2','111','liu',100,'高新区支行'),
('101009','2021-3-2','222','zhang',200,'灞桥区支行'),
('101010','2021-3-3','333','zhang',300,'灞桥区支行');
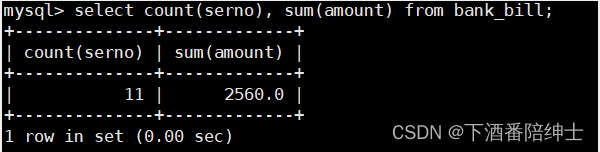
统计表中缴费的总笔数和总金额
select count(serno), sum(amount) from bank_bill;
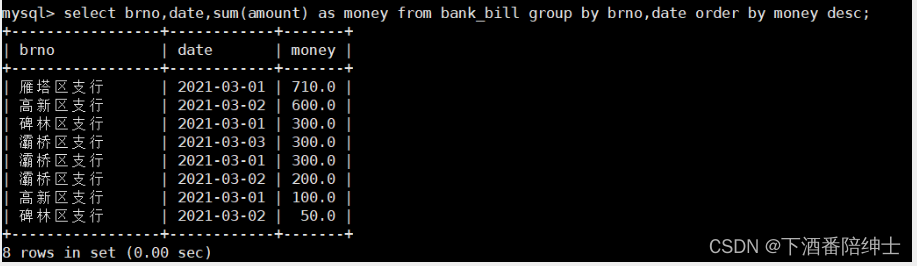
按照网点和日期统计每个网点每天的营业额,并按照营业额进行降序排序
select brno,date,sum(amount) as money from bank_bill group by brno,date order by money desc;