-
简介
Flink的定位是:Apache Flink是一个框架和分布式处理引擎,如图所示,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境运行,以内存执行速度和任意规模来执行计算。

-
应用场景
1、电商和市场营销
举例:实时数据报表、广告投放、实时推荐在电商行业中,网站点击量是统计 PV、UV 的重要来源,也是如今“流量经济”的最主要数据指标。很多公司的营销策略,比如广告的投放,也是基于点击量来决定的。另外,在网站上提供给用户的实时推荐,往往也是基于当前用户的点击行为做出的。我们需要的是直接处理数据流,而 Flink 就可以做到这一点。
2、物联网(IOT)
举例:传感器实时数据采集和显示、实时报警,交通运输业物联网是流数据被普遍应用的领域。各种传感器不停获得测量数据,并将它们以流的形式传输至数据中心。而数据中心会将数据处理分析之后,得到运行状态或者报警信息,实时地显示在监控屏幕上。所以在物联网中,低延迟的数据传输和处理,以及准确的数据分析通常很关键。
3、物流配送和服务业
举例:订单状态实时更新、通知信息推送在很多服务型应用中,都会涉及订单状态的更新和通知的推送。这些信息基于事件触发,
不均匀地连续不断生成,处理之后需要及时传递给用户。这也是非常典型的数据流的处理。
4、银行和金融业
举例:实时结算和通知推送,实时检测异常行为银行和金融业是另一个典型的应用行业。在全球化经济中,能够提供
24
小时服务变得越来越重要。现在交易和报表都会快速准确地生成,我们跨行转账也可以做到瞬间到账,还可以接到实时的推送通知。这就需要我们能够实时处理数据流。
-
特性总结
核心特性
- 高吞吐和低延迟。每秒处理数百万个事件,毫秒级延迟。
- 结果的准确性。Flink提供了事件时间(event-time)和处理时间(processing-time)语义。对于乱序事件流,事件时间语义仍然能够提供一致且准确的结果。
- 精准一次(exactly-once)的状态一致性保证。
- 可以连接到常见的存储系统。如kafka、es、jdbc和分布式文件系统如HDFS等。
- 高可用。本身高可用的设置,加上与k8s,YARN等的紧密集成,在加上从故障中快速恢复和动态扩展任务的能力,Flink能做到以极少的时间提供7*24小时全天候运行。
- 能够更新应用程序代码并将作业迁移到不同的flink集群,而不会丢失应用程序的状态。
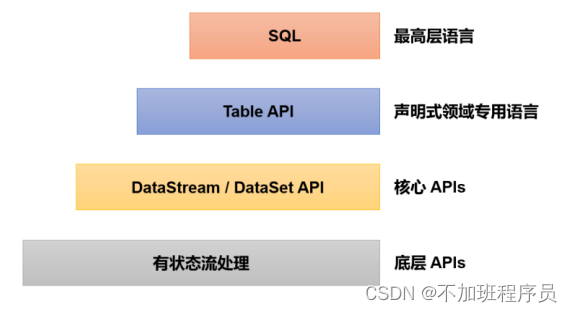
分层API