1).sql三种排序的区别

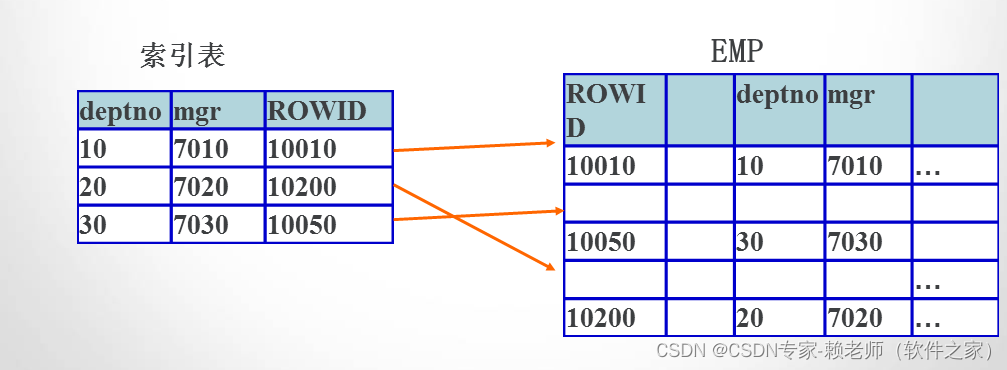
2).几种连接方式
![]()
![]()
![]()
![]()
![]()
3).union和union all的区别

4) .drop和delete的区别

5).有关机器学习random forest 和xgboost的区别

6) .SVM原理
SVM是在特征空间上找到最佳的分离超平面,使得训练集上的正负样本间隔最大。是用来解决二分类问题的有监督学习算法,在引入核方法后也可以解决非线性问题。
7).Hadoop有哪几种存储格式
参考:Hadoop文件存储格式_赵昕彧的博客-CSDN博客_hadoop存储方式
8).SQL 的执行顺序
FROM、ON 、JOIN、WHERE、GROUP BY、AGG_FUNC、WITH、HAVING、SELECT、UNION、DISTINCT 、ORDER BY、LIMIT
from(阐述对哪些表进行操作)-where(选出想要的记录)-group by(对选出的记录进行分组)-having(对分组后结果进行筛选)-select(选取需要的列)-order by(确定查询结果的排序规则)
AGG_FUNC:常用的 Aggregate 函数包涵以下几种:(AVG:返回平均值)、(COUNT:返回行数)、(FIRST:返回第一个记录的值)、(LAST:返回最后一个记录的值)、(MAX: 返回最大值)、(MIN:返回最小值)、(SUM: 返回总和)
WITH 对虚拟表5应用ROLLUP或CUBE选项,生成虚拟表
书写顺序大家都很清楚,就是常规的 select-from-where-group by-having-order by
9).简述p值的概念
根据检验统计量的样本观察值得出的概率,此概率为原假设可被拒绝的最小显著性水平
本质上是一种概率,可以由统计量的样本观察值计算出来,与显著性水平作比较时可以得出拒绝/不拒绝原假设的判断,这种检验方法也被称为p值法
10).如何向没有统计学基础的业务方从p值的角度解读AB实验的结果
AB实验的核心思想是假设检验,原假设为“策略/功能无效”(线上指标并不显著),备择假设为“策略/功能有效”(线上指标显著)。对于业务方而言,无须特别细究p值的定义,只需要向其说明p值小于AB实验设定的显著性水平即可判定策略或功能有效。