专栏:神经网络复现目录
本章介绍的是现代神经网络的结构和复现,包括深度卷积神经网络(AlexNet),VGG,NiN,GoogleNet,残差网络(ResNet),稠密连接网络(DenseNet)。
文章目录
- 稠密连接网络(DenseNet)
- 从ResNet到DenseNet
- 稠密体块(密集块)
- 定义
- 实现
- 过渡层
- 定义
- 实现
- 模型设计
- 网络结构
- 实现
- 实战:训练CIFAR10分类
- 数据集
- 损失函数和优化器
- 训练
- 可视化
稠密连接网络(DenseNet)
DenseNet(密集连接网络)是一种深度学习架构,由黄等人在2017年提出。DenseNet是一种卷积神经网络(CNN),它使用密集连接层来改善网络中信息的流动。
传统的CNN中,每一层的输出只传递给下一层。然而,在DenseNet中,每一层都与后续所有层相连。这意味着任何一层的输入都是来自网络中所有前面层的特征图的串联。
DenseNet的好处包括:
-
减少梯度消失问题:因为每一层都直接访问所有后续层的梯度,所以梯度信号可以更轻松地通过网络进行传播和保留。
-
参数效率:与相似性能的传统CNN相比,DenseNet具有更少的参数,因为它可以重用特征图。
-
提高准确性:DenseNet在各种计算机视觉任务上取得了最先进的性能,包括图像分类、目标检测和语义分割。
总的来说,DenseNet是图像识别任务的强有力工具,并已被证明在提高CNN的准确性的同时减少所需的参数数量方面非常有效。
从ResNet到DenseNet
ResNet将函数展开为

也就是说,ResNet将f分解为两部分:一个简单的线性项和一个复杂的非线性项。 那么再向前拓展一步,如果我们想将f拓展成超过两部分的信息呢? 一种方案便是DenseNet。
ResNet(左)与 DenseNet(右)在跨层连接上的主要区别:使用相加和使用连结。
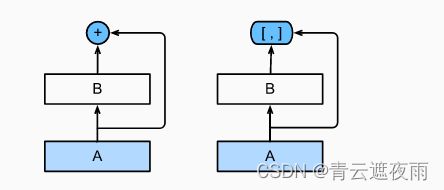
ResNet和DenseNet的关键区别在于,DenseNet输出是连接(用图中的[ , ]表示)而不是如ResNet的简单相加。 因此,在应用越来越复杂的函数序列后,我们执行x从到其展开式的映射:
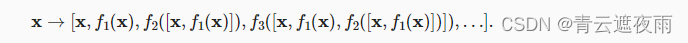
最后,将这些展开式结合到多层感知机中,再次减少特征的数量。 实现起来非常简单:我们不需要添加术语,而是将它们连接起来。 DenseNet这个名字由变量之间的“稠密连接”而得来,最后一层与之前的所有层紧密相连。稠密连接如图所示。
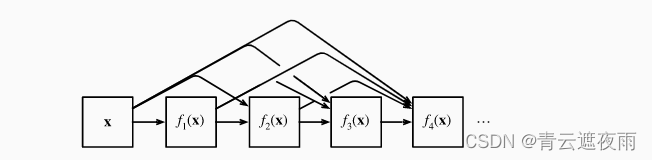
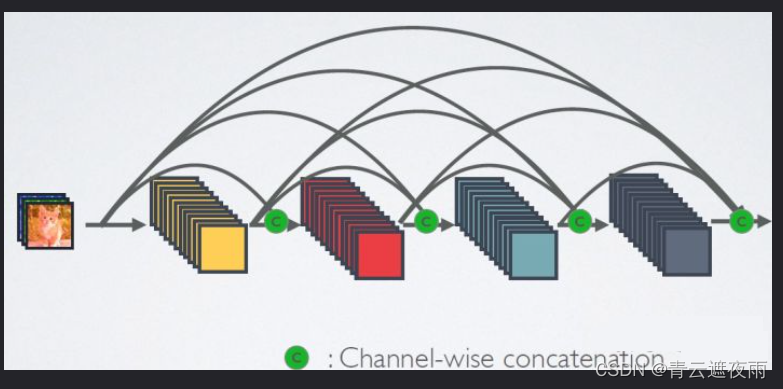
稠密网络主要由2部分构成:稠密块(dense block)和过渡层(transition layer)。 前者定义如何连接输入和输出,而后者则控制通道数量,使其不会太复杂。
稠密体块(密集块)
定义
密集块(Dense Block)是DenseNet网络结构的核心部分,它是由多个密集连接层(Dense Layer)组成的模块,用于提取图像中的特征信息。在每个密集块中,所有前面层的输出都会与当前层的输入进行连接,并通过一个非线性变换进行处理。具体地,假设当前是第 l l l个密集块,第 i i i层的输出为 x i x_i xi,则第 i i i层的计算公式为:
x i = H i ( [ x 0 , x 1 , ⋯ , x i − 1 ] ) x_i = H_i([x_0, x_1, \cdots, x_{i-1}]) xi=Hi([x0,x1,⋯,xi−1])
其中, H i ( ⋅ ) H_i(\cdot) Hi(⋅)表示第 i i i层的非线性变换, [ x 0 , x 1 , ⋯ , x i − 1 ] [x_0, x_1, \cdots, x_{i-1}] [x0,x1,⋯,xi−1]表示前 i i i层的输出的连接。
密集块的优点是可以促进信息的流动和梯度的传递,从而提高网络的性能和稳定性。另外,密集块还可以增加网络的深度和宽度,使得网络能够提取更多的特征信息。
在DenseNet中,每个密集块包含多个密集连接层,其中每个密集连接层都包含一个 3 × 3 3\times3 3×3的卷积层、一个BN层和ReLU激活函数。这些层共享相同的输入和输出,因此它们的输入和输出的通道数相同。而且,DenseNet中的每个密集块都会接上一个过渡层(Transition Block)用于控制网络的大小。
实现
class DenseBlock(nn.Module):
def __init__(self, in_channels, growth_rate):
super(DenseBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, 4 * growth_rate, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(4 * growth_rate)
self.conv2 = nn.Conv2d(4 * growth_rate, growth_rate, kernel_size=3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(growth_rate)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = F.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = F.relu(out)
out = torch.cat([x, out], 1)
return out
过渡层
定义
对于Transition层,它主要是连接两个相邻的DenseBlock,并且降低特征图大小。Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为BN+ReLU+1x1 Conv+2x2 AvgPooling。另外,Transition层可以起到压缩模型的作用。假定Transition的上接DenseBlock得到的特征图channels数为m mm ,Transition层可以产生 θ m θmθm个特征(通过卷积层),其中 θ ∈ ( 0 , 1 ] θ∈(0,1]θ∈(0,1] 是压缩系数(compression rate)。当 θ = 1 θ=1θ=1 时,特征个数经过Transition层没有变化,即无压缩,而当压缩系数小于1时,这种结构称为DenseNet-C,文中使用 θ = 0.5 θ = 0.5θ=0.5。对于使用bottleneck层的DenseBlock结构和压缩系数小于1的Transition组合结构称为DenseNet-BC。
实现
class Transition(nn.Module):
def __init__(self, in_channels, out_channels):
super(Transition, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.conv(x)
out = self.bn(out)
out = F.relu(out)
out = F.avg_pool2d(out, 2)
return out
模型设计
网络结构
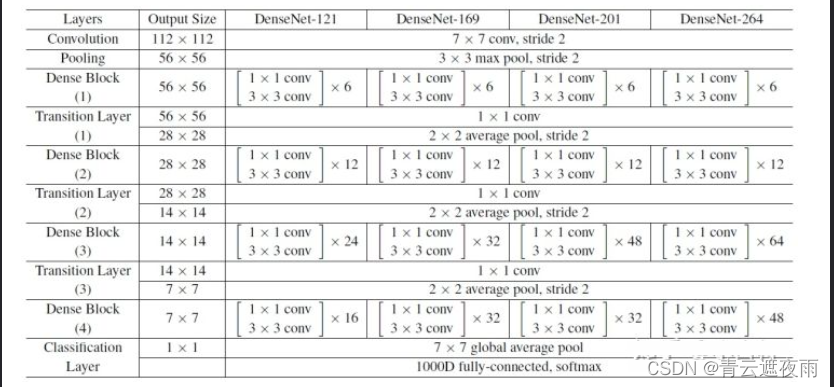
DenseNet是一种基于密集连接的卷积神经网络(CNN),其主要特点是在网络中引入了密集连接层,从而改善了信息的流动和梯度的传递。下面是DenseNet的网络结构:
1.输入层:输入层接收输入数据,并将其送入第一个卷积层中。
2.卷积层:DenseNet中的卷积层通常采用 3 × 3 3\times3 3×3的卷积核,并采用padding来保持特征图的大小不变。在每个卷积层后面,都会接上BN层和ReLU激活函数。
3.密集块(Dense Block):密集块是DenseNet的核心,它由多个密集连接层组成。在每个密集块中,所有前面层的输出都会与当前层的输入进行连接,并通过一个非线性变换进行处理。
4.过渡层(Transition Block):为了避免网络过深导致梯度消失和计算资源过度消耗,DenseNet中采用了过渡层来控制网络的大小。在每个密集块之间,都会接上一个过渡层,它包含一个 1 × 1 1\times1 1×1的卷积层、BN层和平均池化层,其中平均池化的步幅为2,用于减少特征图的大小。
5.全局池化层和全连接层:最后,DenseNet使用全局平均池化层将特征图降维为一个向量,然后通过一个全连接层进行分类。
综上所述,DenseNet的网络结构具有密集连接和过渡层两个核心特点,它能够有效地利用前面层的信息,提高网络的性能和稳定性。同时,DenseNet也非常适合处理较小的数据集,如CIFAR-10和CIFAR-100。
实现
class DenseNet(nn.Module):
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_classes=1000):
super(DenseNet, self).__init__()
# 初始卷积层
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.pool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# DenseBlock 和 Transition 的组合
self.dense1 = self._make_dense_block(growth_rate, block_config[0])
self.trans1 = self._make_transition(256, growth_rate * block_config[0] // 2)
self.dense2 = self._make_dense_block(growth_rate, block_config[1])
self.trans2 = self._make_transition(512, growth_rate * block_config[1] // 2)
self.dense3 = self._make_dense_block(growth_rate, block_config[2])
self.trans3 = self._make_transition(1024, growth_rate * block_config[2] // 2)
self.dense4 = self._make_dense_block(growth_rate, block_config[3])
# 全局平均池化层和分类层
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(growth_rate * block_config[3], num_classes)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = F.relu(out)
out = self.pool1(out)
out = self.dense1(out)
out = self.trans1(out)
out = self.dense2(out)
out = self.trans2(out)
out = self.dense3(out)
out = self.trans3(out)
out = self.dense4(out)
out = self.avg_pool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
def _make_dense_block(self, growth_rate, num_layers):
layers = []
for i in range(num_layers):
layers.append(DenseBlock(growth_rate * i + 64, growth_rate))
return nn.Sequential(*layers)
def _make_transition(self, in_channels, out_channels):
return Transition(in_channels, out_channels)
实战:训练CIFAR10分类
数据集
# 导入数据集
from torchvision import datasets
import torch
import torchvision.transforms as transforms
transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize((0.485,0.456,0.406),(0.229,0.224,0.225))
])
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'trunk')
cifar_train = datasets.CIFAR10(root="/data",train=True, download=True, transform=transform)
cifar_test = datasets.CIFAR10(root="/data",train=False, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(cifar_train, batch_size=16, shuffle=True)
test_loader = torch.utils.data.DataLoader(cifar_test, batch_size=16, shuffle=False)
损失函数和优化器
# 定义损失函数和优化器
net=DenseNet(num_classes=10);
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.001)
epoch = 5
net = net.to(device)
total_step = len(train_loader)
train_all_loss = []
val_all_loss = []
训练
import numpy as np
for i in range(epoch):
net.train()
train_total_loss = 0
train_total_num = 0
train_total_correct = 0
for iter, (images,labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
outputs = net(images)
loss = criterion(outputs,labels)
train_total_correct += (outputs.argmax(1) == labels).sum().item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_total_num += labels.shape[0]
train_total_loss += loss.item()
print("Epoch [{}/{}], Iter [{}/{}], train_loss:{:4f}".format(i+1,epoch,iter+1,total_step,loss.item()/labels.shape[0]))
net.eval()
test_total_loss = 0
test_total_correct = 0
test_total_num = 0
for iter,(images,labels) in enumerate(test_loader):
images = images.to(device)
labels = labels.to(device)
outputs = net(images)
loss = criterion(outputs,labels)
test_total_correct += (outputs.argmax(1) == labels).sum().item()
test_total_loss += loss.item()
test_total_num += labels.shape[0]
print("Epoch [{}/{}], train_loss:{:.4f}, train_acc:{:.4f}%, test_loss:{:.4f}, test_acc:{:.4f}%".format(
i+1, epoch, train_total_loss / train_total_num, train_total_correct / train_total_num * 100, test_total_loss / test_total_num, test_total_correct / test_total_num * 100
))
train_all_loss.append(np.round(train_total_loss / train_total_num,4))
val_all_loss.append(np.round(test_total_loss / test_total_num,4))
可视化
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
plt.figure()
plt.title("Train Loss and Test Loss Curve")
plt.xlabel('plot_epoch')
plt.ylabel('loss')
plt.plot(train_all_loss)
plt.plot(val_all_loss)
plt.legend(['train loss', 'test loss'])







![[Gin]框架底层实现理解(三)](https://img-blog.csdnimg.cn/b59c77aa52c648549416af16e6c8275d.png)