本文将详细介绍stable diffusion webui的下载、安装及问题解决。
StableDiffusion是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,尽管它也可以应用于其他任务,如内补绘制、外补绘制,以及在提示词(英语)指导下产生图生图的翻译。它是一种潜在扩散模型,由慕尼黑大学的CompVis研究团体开发的各种生成性人工神经网络。它是由初创公司StabilityAI,CompVis与Runway合作开发的,并得到EleutherAI和LAION的支持。
一、环境准备
(一)硬件方面:
1. 显存
4G起步,4G显存支持生成512*512大小图片,超过这个大小将卡爆失败。
2. 硬盘
10G起步,模型基本都在5G以上,有个30G硬盘不为过吧?现在硬盘容量应该不是个问题。
(二)软件方面:
1. Git
https://git-scm.com/download/win
下载最新版即可,对版本没有要求。
2. Python
https://www.python.org/downloads/
截止发稿(2023.3.6)时,最高版本只能用3.10.*,用3.11.*会出问题。
3. Nvidia CUDA
https://developer.download.nvidia.cn/compute/cuda/11.7.1/local_installers/cuda_11.7.1_516.94_windows.exe
版本11.7.1,搭配Nvidia驱动516.94,可使用最新版。
4. stable-diffusion-webui
https://github.com/AUTOMATIC1111/stable-diffusion-webui
核心部件当然用最新版本~~但注意上面三个的版本的兼容性。
5. 中文语言包
https://github.com/VinsonLaro/stable-diffusion-webui-chinese
下载chinese-all-0306.json 和 chinese-english-0306.json文件
6. 扩展(可选)
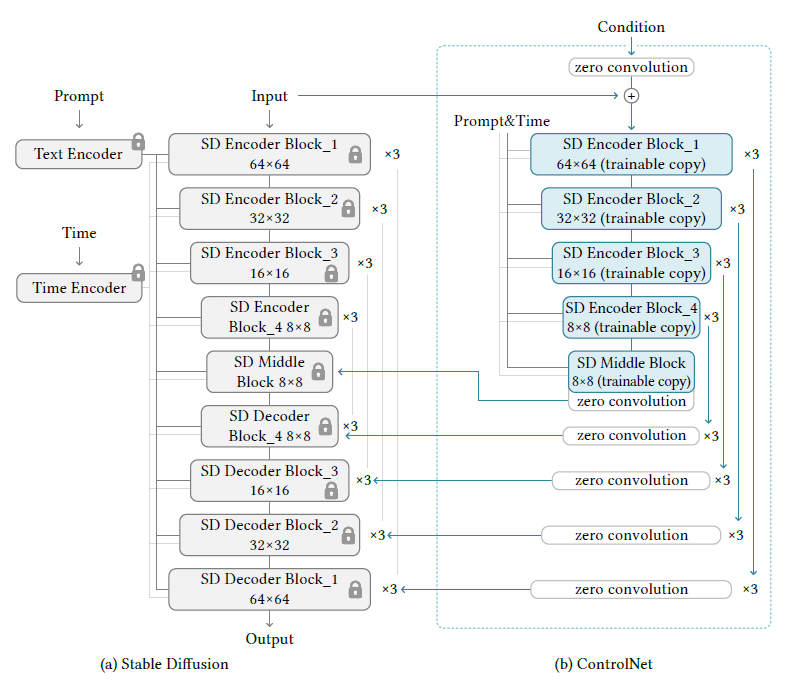
https://github.com/Mikubill/sd-webui-controlnet
下载整个sd-webui-controlnet压缩包
https://huggingface.co/lllyasviel/ControlNet/tree/main/models
下载其中control_sd15_openpose.pth文件
7. 模型
https://huggingface.co/models
https://civitai.com
可以网上去找推荐的一些模型,一般后缀名为ckpt、pt、pth、safetensors ,有时也会附带VAE(.vae.pt)或配置文件(.yaml)。
| 类型 | 文件格式 | 存放目录 | 备注 |
|---|---|---|---|
| check point | .ckpt,.safetensors | \models\Stable-diffusion | 文件较大 |
| vae | 名字带有vae的 | \models\vae | 细节更好地恢复,特别是眼睛和文字 |
| Textual Inversion | *.pt | \embeddings | 一般文件很小,额外的tag |
| Lora | *.pt | \models\Lora | 调整模型,理解为风格化也可以 |
| Hypernetworks | .pt,.ckpt,*.safetensors | \models\hypernetworks | 和lora工作方式相似,算法不同 |
二、安装流程
1. 安装Git
就正常安装,无问题。
2. 安装Python
建议安装在非program files、非C盘目录,以防出现目录权限问题。
注意安装时勾选Add Python to PATH,这样可以在安装时自动加入windows环境变量PATH所需的Python路径。
3. 安装Nvidia CUDA
正常安装,无问题。
4. 安装stable-diffusion-webui
国内需要用到代理和镜像,请按照下面的步骤操作:
a) 编辑根目录下launch.py文件
将https://github.com替换为https://ghproxy.com/https://github.com,即使用Ghproxy代理,加速国内Git。
b) 执行根目录下webui.bat文件
根目录下将生成tmp和venv目录。
c) 编辑venv目录下pyvenv.cfg文件
将include-system-site-packages = false改为include-system-site-packages = true。
d) 配置python库管理器pip
方便起见,在\venv\Scripts下打开cmd后执行如下命令:
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/ #镜像
pip install -r requirements_versions.txt #执行此条命令前,请检查你的剩余磁盘空间
pip install xformer #如果不执行此条命令,启动Stable Diffusion时可能会出现错误。xformer还可以在后续使用中降低显卡占用。
xformer会安装到\venv\Lib\site-packages中。
e) 安装语言包
将文件chinese-all-0306.json 和 chinese-english-0306.json放到目录\localizations目录中。
运行webui后进行配置,操作方法见下。
f) 安装扩展(可选)
将sd-webui-controlnet解压缩到\extensions目录中。
将control_sd15_openpose.pth文件复制到/extensions/sd-webui-controlnet/models目录中。
g) 安装模型
下载的各种模型放在\models\Stable-diffusion目录中即可。
h) 再次执行根目录下webui.bat文件
用浏览器打开webui.bat所提供的网址即可运行。

其中提供了网址:http://127.0.0.1:7860。
打开该网址后在Settings -> User interface -> Localization (requires restart)设置语言,在菜单中选择chinese-all-0220(前提是已经在目录中放入了对应语言包,见上),点击Apply Settings确定,并且点击Reload UI重启界面后即可。
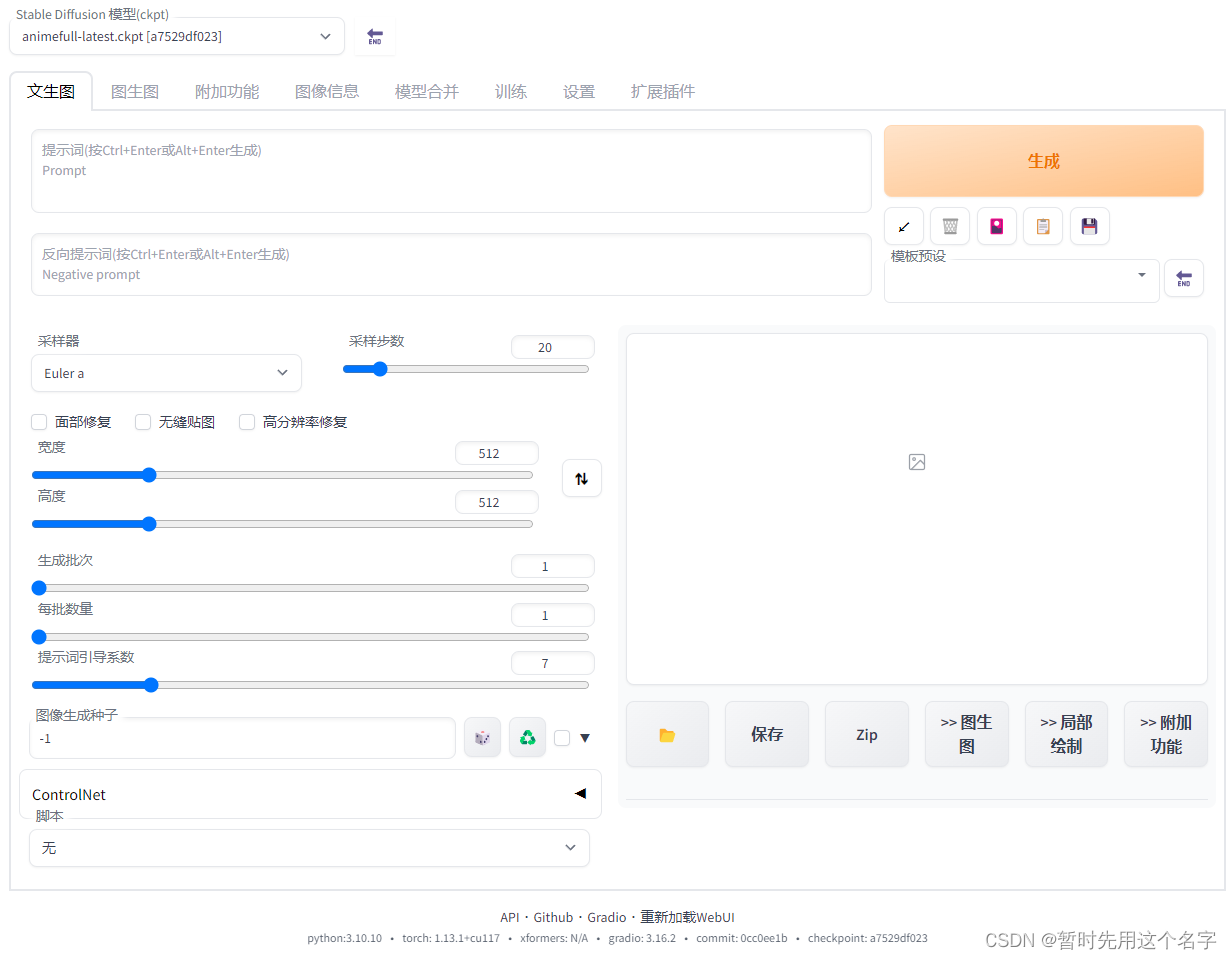
好了,现在可以开始使用了~~
三、问题及注意点
1. python版本错误
错误:
ERROR: Could not find a version that satisfies the requirement torch==1.13.1+cu117
ERROR: No matching distribution found for torch==1.13.1+cu117
这是由于python版本不对导致的(上面提过了,截止发稿时不能追求新版本),要用python 3.10.*版本。
解决来源:https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/7166
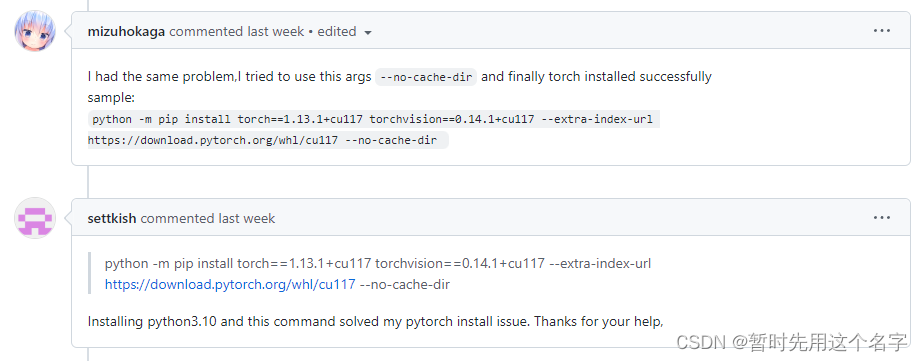
2. pip版本错误
警告:
[notice] A new release of pip available: 22.3.1 -> 23.0.1
[notice] To update, run: D:\stable-diffusion-webui\venv\Scripts\python.exe -m pip install --upgrade pip
提示中已经给出了解决方案:
在\venv\Scripts\目录中打开cmd,执行
python.exe -m pip install --upgrade pip
3. 安装停滞
如果在执行webui.bat进行包下载安装时会卡在某一步,等了许久都没反应,那么这时可以复制包名,进入python安装目录或\venv\Scripts\目录中打开cmd,执行
pip install 包名
4. 其他安装问题
删除/tmp和/venv目录后重启webui.bat试试。
5. 硬件问题
一般显卡不达标,就会爆卡,解决办法就是编辑根目录下webui-user.bat文件,试一下修改参数COMMANDLINE_ARGS即可。
以下几个设置逐一测试看看哪个适合自己。
set COMMANDLINE_ARGS=--lowvram --precision full --no-half --skip-torch-cuda-test
set COMMANDLINE_ARGS=--lowvram --precision full --no-half
set COMMANDLINE_ARGS=--lowvram
本机显存4G,使用最后一个配置方法,可以烧出2048*1080的图,前两种方法反而会在最后爆卡。
参考:
【AI繪畫】Stable-Diffusion 通過骨架分析插件ControlNet 來製作超有意境的圖片
Stable Diffusion2.1+WebUI的安装与使用(极详细)
低配显卡想玩Stable Diffusion?修改一个配置就行