安全验证 - 知乎知乎,中文互联网高质量的问答社区和创作者聚集的原创内容平台,于 2011 年 1 月正式上线,以「让人们更好的分享知识、经验和见解,找到自己的解答」为品牌使命。知乎凭借认真、专业、友善的社区氛围、独特的产品机制以及结构化和易获得的优质内容,聚集了中文互联网科技、商业、影视、时尚、文化等领域最具创造力的人群,已成为综合性、全品类、在诸多领域具有关键影响力的知识分享社区和创作者聚集的原创内容平台,建立起了以社区驱动的内容变现商业模式。![]() https://zhuanlan.zhihu.com/p/605761756
https://zhuanlan.zhihu.com/p/605761756
ModelScope 魔搭社区
1.introduction
基于提示的大模型是否满足我们特定的要求?在图像领域已经有明确范式的任务,大模型是否可以应用促进这些特定任务?我们应该构建什么样的框架来处理大范围的条件问题和用户的控制需求?在具体任务中,大模型能否保留从数十亿张图像中获得的优势和能力?
为了回答这些问题,我们的调查有三个发现。1.特定任务领域中的可用数据并不总是像一般图像-文本领域中那么大。许多特定问题(目标形状/normal,姿态理解等)的最大数据往往在100k以下,laion-B有5b的数据对。2.大型计算集群并不是谁都有的,预训练权重的迁移微调是可利用的。3.各种图像处理问题具有不同形式的定义,用户控制或者图像注释。尽管扩散算法可以以程序性方式来调节,这些问题本质上需要将原始输入解释为对象级别或者场景级别的理解,人工规则往往行不通,并且很多任务都是希望端到端进行的。

上图输入是canny边缘图,输出是符合控制条件的图。
本文介绍controlnet,这是一种端到端的神经网络结构,它控制大型图像扩散模型来学习特定任务的输入条件。controlnet将大型扩散模型权重克隆为trainable copy(可训练副本)和locked copy(锁定副本),锁定副本保留从数十亿图像中学习的能力,而可训练副本在特定任务的数据集上训练,以学习条件控制。可训练和锁定的模块与zero convolution连接,其中卷积权重以学习的方式从零逐渐增长到优化的参数。由于保留了production-ready weights,因此训练在不同规模的数据集上是稳健的。由于零卷积不会向深层特征添加新的噪声,因此与从头开始训练新图层相比,训练和微调扩散模型一样快。我们用不同条件的各种数据集训练控制王,小数据集(50k,甚至1k)效果也不错,在rtx3090ti上也可以训练。
2.related work
2.1 hypernetwork and neural network structure
hypernetwork用于训练一个小的递归网络来影响一个较大的神经网络的权重。controlnet使用一个特殊的卷积,zero convolution,在扩散模型中缩放几个卷积层的初始权重以改善训练的方法。
2.2 diffusion probabilistic model
扩散模型对训练和采样方法进行优化,采样方式包括DDPM/DDIM/score-based diffusion。本质上使用u-net作为架构,为了降低训练扩散模型所需的计算能力,提出LDM(潜在扩散模型)。
2.3 text-to-image diffusion
扩散模型可以用于文本到图像生成,通过使用clip将文本输入编码成潜在向量实现。
2.4 personalization,customization,and control of pretrained diffusion model
因为图像扩散模型是文本到图像的方法主导的,所以增强对扩散的控制最直接的方式是文本引导,这种类型的控制也可以通过操作剪辑特征实现。
2.5 image-to-image translation
尽管controlnet和图像到图像的翻译可能有一些重叠的应用,但是他们的动机本质是不同的,图像到图像的翻译旨在学习不同领域中的图像之间的映射,而控制网络旨在控制具有特定任务条件的扩散模型。
3.method
3.1 controlnet

如上图所示,我们锁定中的所有参数将其克隆到可训练副本中,复制的副本用外部条件c训练,在本文中,我们将原始参数和新参数成为锁定副本和可训练副本,制作这种副本而不是直接训练原始权重的动机是为了避免数据集较小时的过拟合,并保持从数十亿张图像中学习的大型模型的production-ready quality。神经网络块通过zero convolution的卷积层来连接,其权重和偏差都用零初始化。在一开始训练时,神经网络块中可训练和锁定副本中所有输入和输出都与不存在控制网络时情况一致。换句话说,当控制网络被应用在一些神经网络块时,在任何优化之前,它不会对深层神经网络的特征造成任何影响,任何神经网络块的能力、功能和结果质量都被保留,且任何进一步的优化将变得与微调一样快。
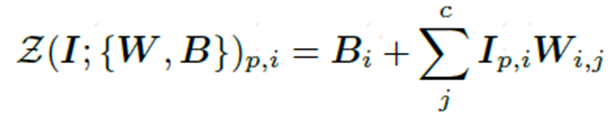
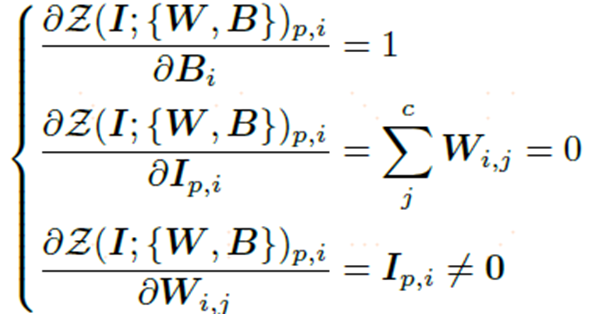
上述公式是零卷积的梯度计算,虽然对输入I的梯度初始为0,但是权重和偏差都不受影响,只要输入I不为0,权重将在第一次梯度下降中被优化为非0矩阵。

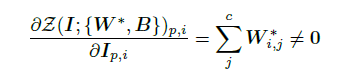
w※是一次梯度下降之后的,对输入I求导,获得非0梯度。以这种方式,零卷积成为一种独特类型的连接层,从零逐渐增长到优化的参数。
3.2 controlnet in image diffusion model
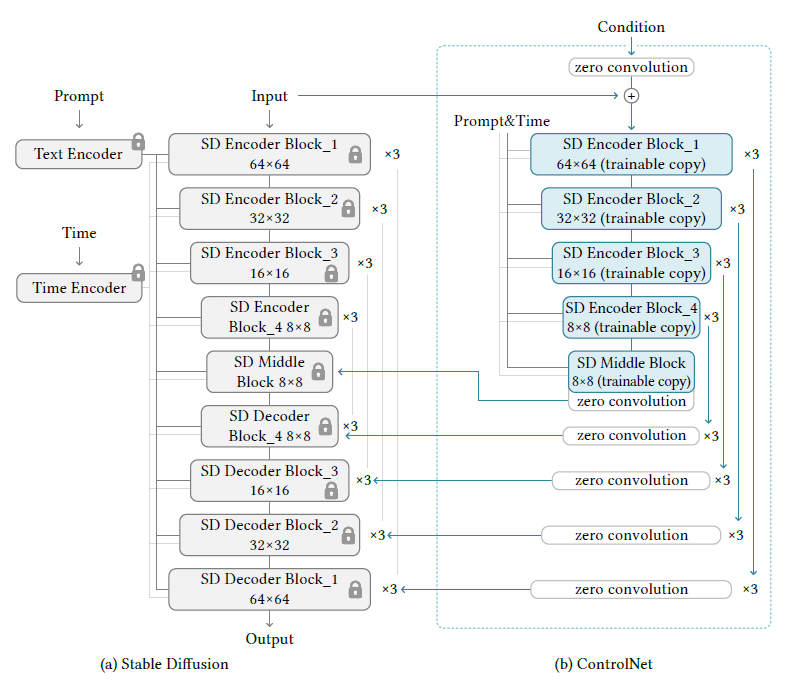
stable diffusion是在数十亿张图像上训练的大型文本到图像扩散模型。如上所示,本质上是一个u-net,有编码器、中间模块和解码器,中间进行跳跃连接,编码器和解码器都有12个,包括中间模块一共有25个模块,这些模块中,8个是上下采样的卷积层,17个主要的模块,每个包括4个resnet层和2个vision transformer,每个vit包括几个cross-attention或者self-attention。文本采用openai clip编码,扩散时间步长采用位置编码。
stable diffusion使用和vq-gan相似的预处理方法,将512x512图像转成64x64的潜在图像,controlnet将image-based condition(就是从图像中获取线框图)转成64x64,我们使用4个4x4核和2x2strides的卷积层(后接relu,通常数分别是16,32,64,128,Guassian weights)将image-space condition转成特征图。该网络将512x512转成64x64。
如上图所示,使用controlnet来控制u-net的每一层,锁定权重是不计算梯度的,使用controlnet训练大概只增加23%的内存和34%的一次迭代时间。具体来说,使用controlnet来创建stable diffusion的12个编码块和1个中间层的可训练副本,4个快采用4中分辨率,每个块有三个。
作者的安排十分有意思。笔者在做相关实验时会联想到学术界已经形成的一些共识来设计实验:比如由去年八月份论文prompt to prompt提出后,文生图里图片布局几何关系很大程度上由cross-attn时文本对不同位置的像素点的激活程度所决定。所以笔者初始时会思考是否可以直接将text embedding添加融合模块与sketch info(或其余模态的信息)交互,微调整个模型使其学会兼顾新的模态信息。笔者也会思考是否直接像GLIGEN的方式直接在attn层附近添加融合模块会取得好的效果。但论文作者没有如此安排。论文作者的思路更加类似于《Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation》这篇论文的思路。即对于一张模型生成的图片,其UNet的decoder一定已经包含了其生成的一些空间信息,语义信息等。直接抽取decoder相关的特征,添加到当前的生成能够影响当前生成的布局语义等。这是笔者觉得非常有意思的一点。
3.3 training
在训练过程中,我们随机将50%文本提示词替换为空字符串,这有助于controlnet从输入条件图中识别语义内容的能力,如涂鸦和边缘图,这主要是因为当提示对stable diffusion不可见时,编码器倾向于从输入控制映射中学习更多的语义作为提示词的替代。
3.4 implement
文本-条件图-图像对。