在spark上运用SQL处理结构化数据
1、SparkSQL快速入门
1.1 什么是SparkSQL
SparkSQL 是Spark的一个模块,用于处理海量结构化数据
限定:结构化数据
1.2 为什么学习SparkSQL
SparkSQL是非常成熟的,海量结构化数据处理框架
学习SparkSQL主要在2个点
- SparkSQL本身十分优秀,支持SQL语言,性能强,可以自动优化,API简单,兼容HIVE等
- 企业大面积在使用SparkSQL处理业务数据
- 离线开发
- 数仓搭建
- 科学计算
- 数据分析
1.3 SparkSQL的特点
融合性
SQL可以无缝集成在代码中,随时用SQL处理书
统一数据访问
一套标准API可以读写不同的数据源
Hive兼容
可以使用SparkSQL直接计算并生成Hive数据表
标准化连接
支持标准化JDBC/ODBC 连接,方便和各种数据库进行数据交互
2、SparkSQL概述
2.1 SparkSQL和Hive异同
2.2 SparkSQL的数据抽象
Pandas -> DataFrame -> 二维表数据结构,单机(本地)集合
SparkCore -> RDD -> 无标准数据结构,存储什么数据均可
SparkSQL -> DataFrame -> 二维表数据结构,分布式集合(分区)

两者都是,有分区的,分布式的,弹性的
不同在于,RDD可以存储任何类型数据。
DataFrame存储的数据结构限定为:二维表结构化数据
SparkSQL其实有3类数据抽象对象
- SchemaRDD对象(已废弃)
- DataSet对象:可用于Java、Scala语言
- DataFrame对象:可用于Java、、Scala、Python
我们以Python开发SparkSQL,主要使用的是DataFrame对象作为核心数据结构
2.3 SparkSession对象
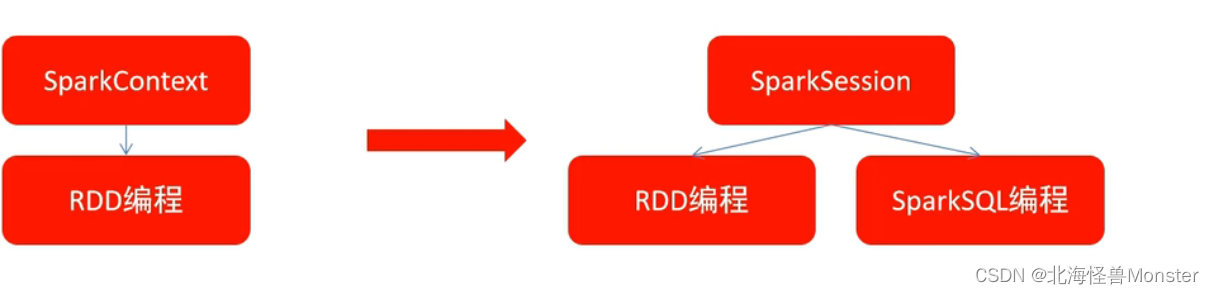
在RDD阶段,程序的执行入口对象是:SparkContext
在Spark2.0后,退出了SparkSession对象,作为Spark编码的统一入口对象。
SparkSession对象可以:
- 用于SparkSQL变成作为入口对象
- 用于SparkCore变成,可以通过SparkSession对象中获取到SparkContext
所以,我们后续的代码,执行环境入口对象,统一变更为SparkSession对象
构建SparkSession核心代码
# coding:utf8
# SparkSQL 中的入口对象是SparkSession
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 构建SparkSession对象,这个对象是 构建器模式 通过builder方法来构建
spark = SparkSession.builder.\
appName("test").\
master("local[*]").\
config("spark.sql.shuffle.partitions",4).\
getOrCreate()
# appName 设置程序名称,config设置一些常用属性
# master 设置模式
# 最后通过getOrCreate()方法 创建SparkSession对象
# 通过SparkSession对象 获取 SparkContext 对象
sc = spark.sparkContext
# SparkSQL的hello world
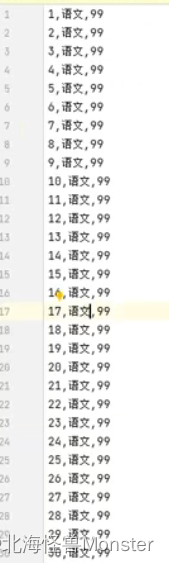
df = spark.read.csv("../data/input/stu_score.txt",sep=',',header=False) # 将txt文件转换为结构化数据
df2 = df.toDF("id","name","score") # 指定列名
df2.printSchema() # 打印表结构信息
df2.show() # 展示表数据
df2.createTempView("score") # 创建表,并指定表名
# SQL 风格
spark.sql("""
select * from score where name = '语文' limit 5
""")。show()
# DSL 风格
df2.where("name='语文'").limit(5).show()
测试数据:
总结
1、SparkSQL和Hive一样,都是用于大规模SQL分布式计算的计算框架,均可以运行在YARN集群上,在企业中广泛使用
2、SparkSQL的数据抽象为:SchemaRDD(废弃),DataFrame(Python,R,java,scala),DataSet(java,scala)
3、DataFrame同样是分布式数据集,有分区可以并行计算,和RDD不同的是,DataFrame中存储的数是以表格形式组织的,方便进行SQL计算
4、DataFrame对比DataSet基本相同,不同的是DataSet支持泛型特性,可以让java,scala语言更好利用
5、SparkSession是2.0后推出的新的执行环境入口对象,可以用于RDD、SQL等编程






![【项目设计】高并发内存池(六)[细节优化+测试]](https://img-blog.csdnimg.cn/b64eb0396efc4bbf95337a40ab181df8.png)
![[ 网络 ] 应用层协议 —— HTTP协议](https://img-blog.csdnimg.cn/5d2b0f854b0242948993be92f45a337f.png)