Spark 平衡 CPU
- CPU/内存平衡
- CPU 低效
- 线程挂起
- 调度开销
- 优化 CPU
CPU/内存平衡
Spark 将内存分 :
- Execution Memory : 用于分布式任务执行
- Storage Memory : 用于 RDD 缓存
- RDD 缓存展开前消耗 Execution Memory , 最后占用 Storage Memory
线程/执行内存关系:
执行内存抢占规则 : 在同个 Executor 有 N 个线程尝试抢占执行内存
抢占原则:
- 执行内存总大小 (M) = Execution Memory 初始大小 + Storage Memory 剩余空间
- 每个线程的可用内存的上下限,下限 : M/N/2,上限 : M/N
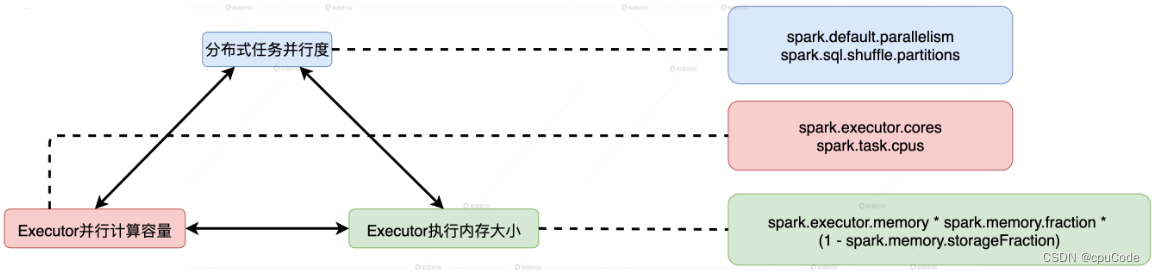
平衡 CPU/内存的 3 类配置参数 : 并行度、集群的并行计算能力、执行内存大小
并行度 :分布式数据集的划分数
- 并行度越高,数据的粒度越细,数据分片越多,数据越分散
并行度的配置项 :
spark.default.parallelism: 设置 RDD 的默认并行度spark.sql.shuffle.partitions: Spark SQL 指定 Shuffle Reduce 默认的并行度
并发度 : 同一时间内,一个 Executor 能同时运行的最大任务数量
spark.executor.cores:Executor 的线程池大小spark.task.cpus:每个任务在运行时要消耗的线程数- 并发度 = Executor 的线程池大小/ 每个任务运行时的线程数
spark.task.cpus默认为 1,并发度默认为spark.executor.cores
Executor 线程池:线程可以复用,但同一时间中,每个线程只能计算一个任务
- 每个任务负责处理一个数据分片
- 在运行时,线程、任务、分区是一一对应的关系
执行内存大小:
- 堆内执行内存的初始值:
spark.executor.memory * spark.memory.fraction * (1 - spark.memory.storageFraction) - 堆外执行内存 :
spark.memory.offHeap.size * (1 - spark.memory.storageFraction)
CPU 低效
线程挂起
线程挂起的原因 :
- 动态变化的执行内存总量 M
- 动态变化的并发度 N~
- 分布式数据集的数据分布
动态变化的执行内存总量 M :
- 下限: Execution Memory 初始值
- 上限:
spark.executor.memory * spark.memory.fraction - 上限会随着 Storage Memory 增加,而减少
线程总数 (N) 是固定 :
- Executor 最大并发度 (N) :
spark.executor.cores/spark.task.cpus - Executor 当前并发度 (N~) : Executor 中当前并行执行的任务数 ( N~ <= N )
数据分片的数据量决定了任务要申请多少内存
- 当分布式数据集的并行度设置好,线程挂起也就解决
调度开销
并行度设到最大,每个数据分片足够小,小到每个 CPU 线程都能申请到内存
- 数据分散的副作用:调度开销骤增
优化 CPU
定 Executor 线程池和执行内存大小的算法:
- 一个数据分片大小在(M/N/2, M/N)之间的并行度