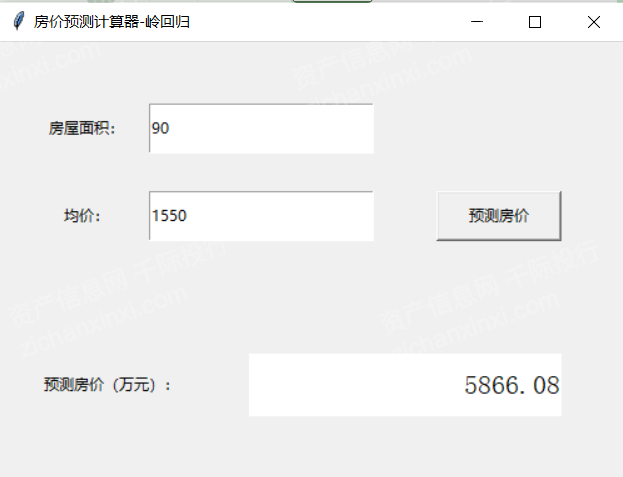
HTTP的特性
HTTP是构建于TCP/IP协议之上,是应用层协议,默认端口号80
HTTP协议是无连接无状态的
HTTP报文
请求报文
HTTP协议是以ASCⅡ码传输,建立在TCP/IP协议之上的应用层规范。
HTTP请求报文由请求行(request line)、请求头部(header)、空行和请求数据四个部分组成,下图是请求报文的一般格式。
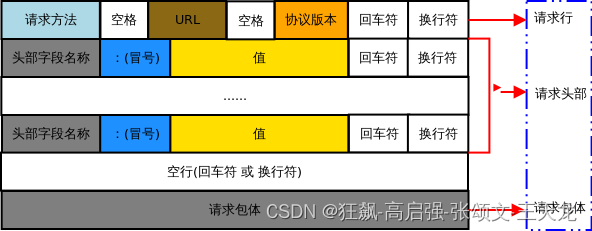
1、请求行
请求行是由请求方法、url字段以及HTTP协议版本字段三个部分组成,它们用空格分开。
HTTP协议的请求方法有GET、POST、HEAD、PUT、DELETE、OPTIONS、TRACE、CONNECT。
而常见的有如下几种:
1.1 GET
当客户端要从服务器读取数据时,点击网页上的链接,或者通过在浏览器的地址栏输入网址来浏览网页的,使用的都是GET方式。GET的方法要求服务器将URL定位的资源放在响应报文的数据部分,回送给客户端。使用GET的方法,请求参数和对应的值附加在URL后面,利用问号 (?),代表URL的结尾和请求参数的开始,传递的参数长度受到限制。例如,/index.html?id=1&password=123,这样通过GET的方式传递的数据直接显示在地址上,所以我们可以将请求以链接的方式发送给接收方。以http://httpbin.org/get为例,request的格式如下:
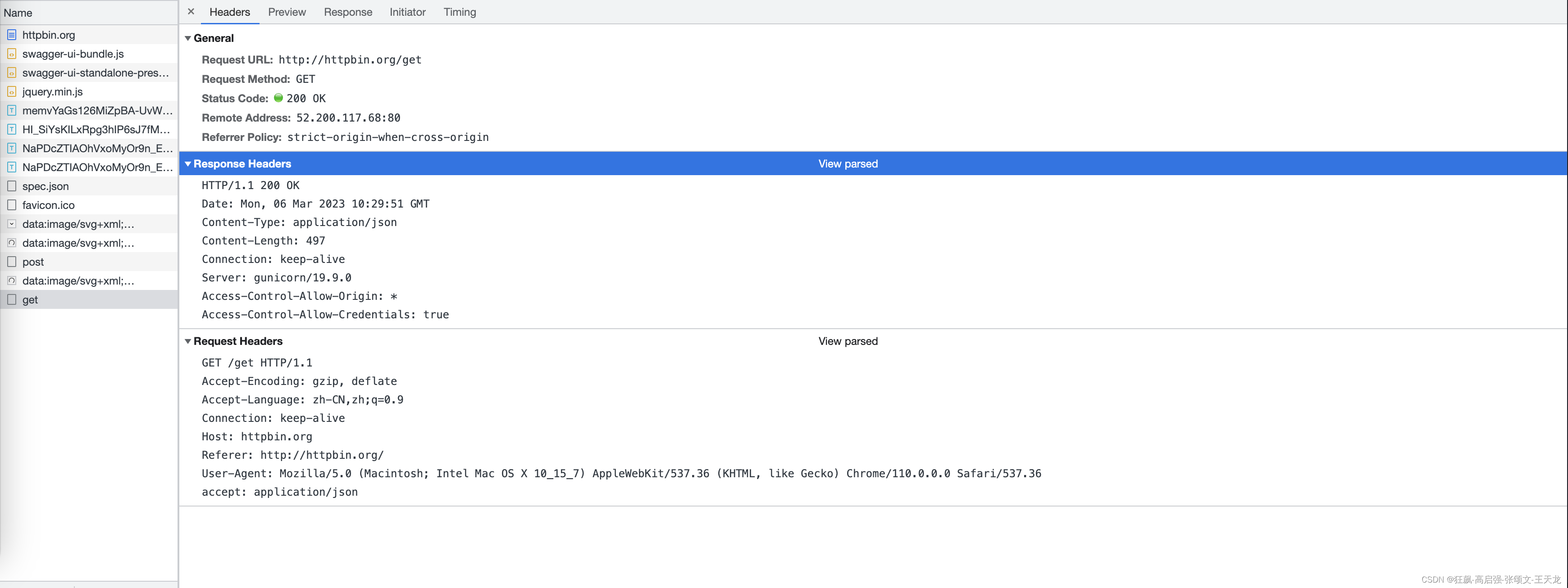
可以看到GET的请求一般不包含“请求内容”的部分,请求数据以地址的形式表现在请求行中,地址 ? 之后的部分就是通过GET发送的数据,我们可以在地址栏中看到各种数据之间用 & 符号隔开。
但是这种方式显然不能传递私密的数据。
另外不同浏览器对地址的字符长度限制有不同的数据,一般最多不超过1024个字符,所以大量的数据传输,不适合使用GET方式。
1.2 POST
对于以上适合使用GET方式的情况下,可以使用POST方式,因为使用POST的方法允许客户端给服务端提供较多的信息。POST将请求参数封装在HTTP的请求数据中,可以大量的传递数据,理论上对数据得大小的没有限制,但实际各个WEB服务器会规定对post提交数据大小进行限制。而且可以不显示在URL中。下图是用wireshark抓的一个POST请求的报文,红色为请求报文,蓝色为响应报文
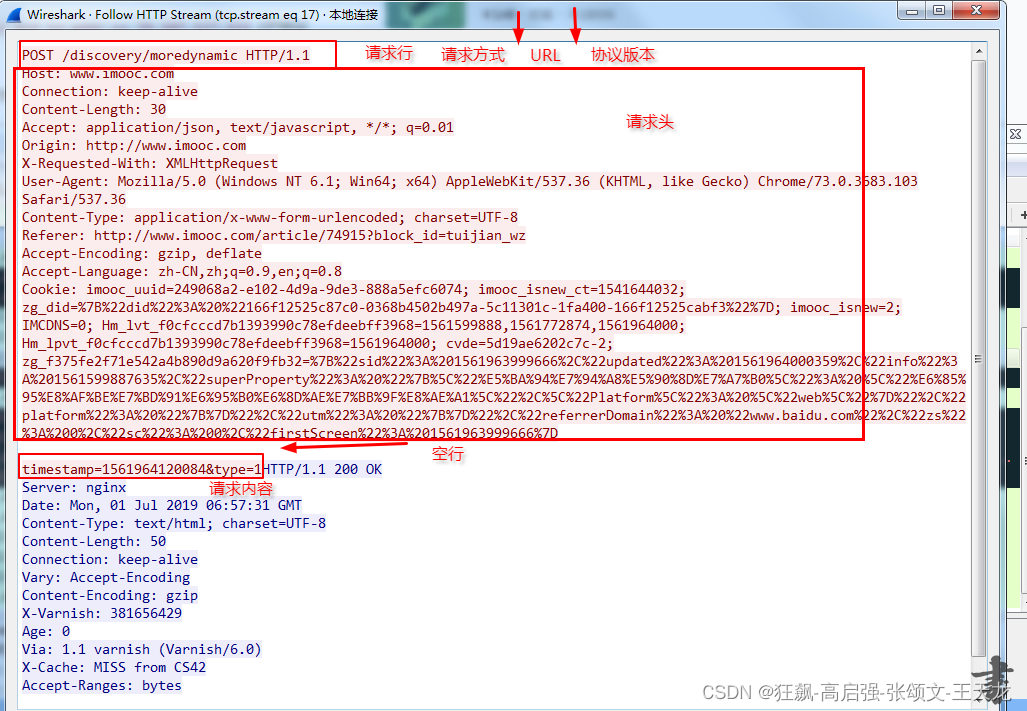
可以看到POST方式的请求行中不包括字符串数据,这些内容保存在“请求内容”部分,各个数据之间也是以 & 符号隔开。
POST方法向服务器提交数据,比如表单的数据的提交。GET的方法一般用于获取/查询资源信息。
2、请求头部
请求头部由键值对组成,关键字和值之间用 : 分开。请求头封装了有关客户端请求的信息,典型的请求头有:
请求头 | 含义 |
User-Agent | 产生请求的浏览器类型,User-Agent请求报头域允许客户端将它的操作系统、浏览器和其它属性告诉服务器 |
Accept | 客户端可识别的响应内容类型列表。eg:Accept:image/gif,表明客户端希望接受GIF图象格式的资源;Accept:text/html,表明客户端希望接受html文本。 |
Accept-Language | 客户端可接受的自然语言 |
Accept-chartset | 客户端可接受应答的字符集。eg:Accept-Charset:iso-8859-1,gb2312.如果在请求消息中没有设置这个域,缺省是任何字符集都可以接受。 |
Accept-Encoding | 客户端可接受的编码压缩格式 |
HOST | 请求的主机名称,允许多个域名同处一个IP之地,即虚拟主机 |
Connection | 连接方式(close或keep-alive) |
Cookie | 存储于客户端扩展字段,向同一域名的服务端发送该域的cookie |
Authorization | Authorization请求报头域主要用于证明客户端有权查看某个资源。当浏览器访问一个页面时,如果收到服务器的响应代码为401(未授权),可以发送一个包含Authorization请求报头域的请求,要求服务器对其进行验证。 |
3、空行
最后一个请求头之后是一个空行,发送回车符和换行符,通知服务器以下不会再有请求头。
4、请求数据
请求数据不再GET方法中使用,而是在POST方法中使用。POST方法适用于客户端提交表单。与请求数据相关的最常使用的请求头是包体类型 Content-Type 和包体长度 Content-Length
代码:
import socket
tcp_socket_client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_socket_client.connect(("httpbin.org", 80))
request_head = "GET /get HTTP/1.1\r\n"
request_headers = "Host: httpbin.org\r\nConnection:close\r\n"
request_end = "\r\n"
request = request_head + request_headers + request_end
tcp_socket_client.send(request.encode("utf-8"))
datas_bytes = b""
while True:
data = tcp_socket_client.recv(1024)
if not data:
break
datas_bytes += data
content = datas_bytes.decode("utf-8")
print(content)
response_head = content.split("\r\n")[0]
response_headers = content.replace(response_head + "\r\n", "").split("\r\n")
index = response_headers.index("")
print(index)
headers = "\r\n".join(response_headers[:index])
print(headers)
data = "\r\n".join(response_headers[index+1:])
print(data)响应报文
HTTP响应报文是由状态行、响应头部、空行和响应包体四个部分组成,如下图所示
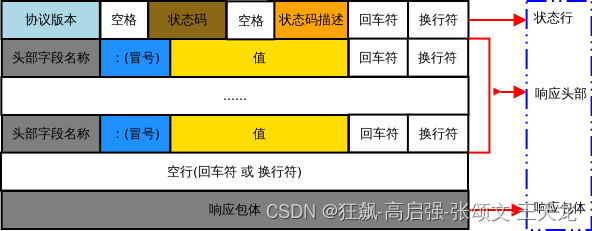
这响应中状态行(status line)代替了请求行。状态行通过提供一个状态码来说明请求情况。
1、状态行
状态行由HTTP协议版本(HTTP-Version),状态码(Statue-Code) 和 状态码描述文本(Reason-Phrase) 三个部分组成,它们之间用空格隔开;
状态码有三位数字组成,第一位定义了响应的类别,可能有五种取值:
1xx:表示服务端已经接收到客户端请求,客户端可以继续发送请求;
2xx:表示服务端已经成功接收请求并处理;
3xx:表示服务器要求客户端重定向;
4xx:客户端请求有问题;
5xx:服务端未能正常处理客户端的请求出现错误;
常见状态码描述文本有如下:
200 OK:请求成功;
400 Bad Request:客户端请求语法有问题,不能被服务端理解;
401 Unauthorized:请求未经授权,必须与Authorization请求报头域一起使用(eg:BASE64用户身份验证);
403 Forbidden:服务器收到请求但是拒绝提供服务,通常会在响应正文中给出不提供服务的原因;
404 Not Found:请求的资源不存在,eg,输错了URL;
500 Internal Server Error:服务器发生错误,无法完成客户端请求;
503 Service Unavailable:表示服务器当前不能处理客户端请求,一段时间之后可能恢复正常;
2、响应头
响应头可能包括以下信息:
响应头 | 描述 |
Server | Server 响应报头域包含了服务器用来处理请求的软件信息及其版本。它和 User-Agent 请求报头域是相对应的,前者发送服务器端软件的信息,后者发送客户端软件(浏览器)和操作系统的信息。 |
Vary | 指示不可缓存的请求头列表 |
Connection | 连接方式 |
www-Authenticate | WWW-Authenticate响应报头域必须被包含在401 (未授权的)响应消息中,这个报头域和前面讲到的Authorization 请求报头域是相关的,当客户端收到 401 响应消息,就要决定是否请求服务器对其进行验证。如果要求服务器对其进行验证,就可以发送一个包含了Authorization 报头域的请求 |
3、响应包体
服务器返回给客户端的文本信息
以下是用wireshark抓的一段响应报文

HTTP无状态性
HTTP协议是无状态的(stateless)。也就是说,同一个客户端第二次访问同一个服务器上面的页面时,服务器无法得知这个客户端曾经访问过,服务器无法辨别不同的客户端。HTTP的无状态性简化了服务器的设计,是服务器更容易支持大量并发的HTTP请求。
HTTP协议是采用请求-响应的模型。客户端向服务端发送一个请求报文,服务端以一个状态作为回应。
当使用普通模式,即非keep-alive模式时,每个请求-应答都要重新建立一个连接,连接完成后立即断开;
HTTP1.1 使用持久连接keep-alive,所谓持久连接,就是服务器在发送响应后仍然在一段时间内保持这条连接,允许在同一个连接中存在多次数据请求和响应,即在持久连接情况下,服务器在发送完响应后并不关闭TCP 连接,而客户端可以通过这个连接继续请求其他对象。
HTTP 长连接不可能一直保持,例如 Keep-Alive: timeout=5, max=100,表示这个TCP通道可以保持5秒,max=100,表示这个长连接最多接收100次请求就断开。
HTTP 是一个无状态协议,这意味着每个请求都是独立的,Keep-Alive 没能改变这个结果。另外,Keep-Alive也不能保证客户端和服务器之间的连接一定是活跃的,在 HTTP1.1 版本中也如此。唯一能保证的就是当连接被关闭时你能得到一个通知,所以不应该让程序依赖于 Keep-Alive 的保持连接特性,否则会有意想不到的后果。
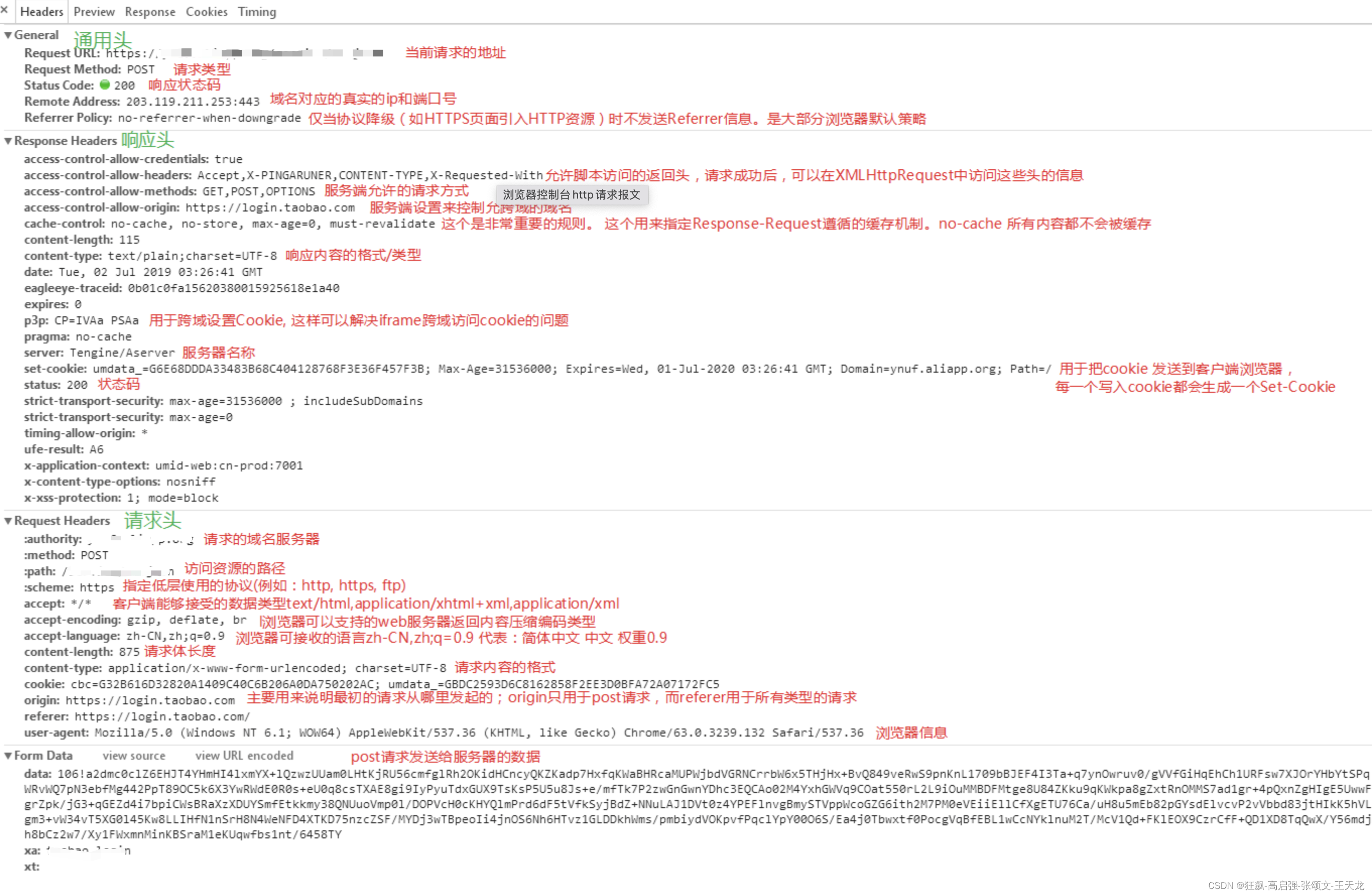
浏览器控制台中的http报文
这里简单的放一张浏览器控制台的http请求报文解析
代码:
import socket
tcp_socket_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_socket_server.bind(("0.0.0.0", 8080))
tcp_socket_server.listen(1024)
tcp_socket_c, tcp_socket_info = tcp_socket_server.accept()
data = tcp_socket_c.recv(10240)
print(data.decode("utf-8"))
response_head = "HTTP/1.1 200 OK\r\n"
response_headers = "Content-Type: text/html; charset=utf-8\r\nServer: gunicorn/19.9.0\r\n"
response_space = "\r\n"
response_content = """
{
"args": {},
"headers": {
"Accept": "application/json",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Host": "httpbin.org",
"Referer": "http://httpbin.org/",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-6405c3a3-29198e8b33a7a9ea54a2afca"
},
"origin": "120.244.162.239",
"url": "http://httpbin.org/get"
}
"""
response_data = response_head + response_headers + response_space + response_content
tcp_socket_c.send(response_data.encode("utf-8"))
tcp_socket_c.close()
tcp_socket_server.close()