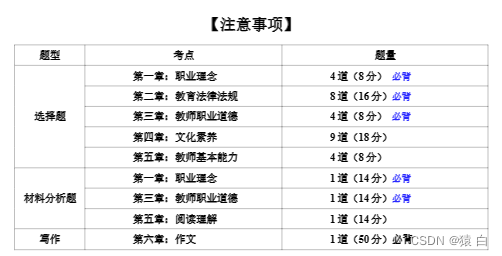
前言
上次介绍了基于Point-Based方法处理点云的模块,3D目标检测(一)—— 基于Point-Based方法的PointNet点云处理系列,其中相关的模块则是构成本次要介绍的,直接在点云的基础上进行3D目标检测网络的基础。
VoteNet
对于直接在点云上预测3D的目标框,有一个相对于2D而言难以解决的问题,即我们扫描得到的点云都是表示在物体表面的,而如果只利用物体表面的点云信息来预测其中心及大小信息,显然是有着一定差距的,而VoteNet这篇工作的主要思路就是想办法得到物体内部的点,然后利用这种内部的点来对物体的BB的中心,大小进行预测。(如下图中,原本黑色的点为物体表面的点,通过设计网络来预测得到物体内部中心的红色点以此来进行预测)
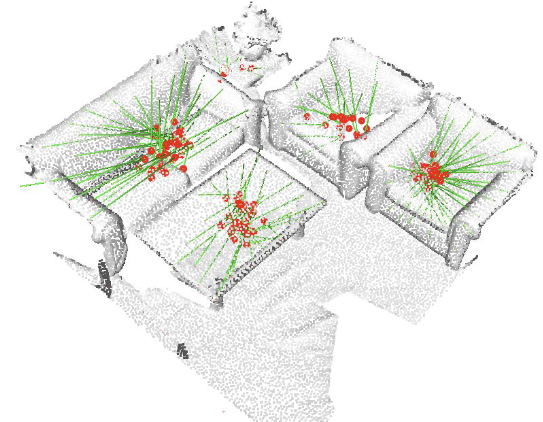
而这种中心的获得,文章主要是通过Hough Voting的思想获得的,Hough Voting有可能大家都对此有诸多的解释,但其主要思路或者说方法就是去构造一个需要检测物体对应的参数空间,像在这里就是一个由边界点到其对应物体中心点的参数空间,那么根据这些物体表面的点在这个参数空间的映射投票,就可以确定其中的中心点。

而其实VoteNet的网络结构主要可以分为两部分来解读,分别为对点云处理的Backbone部分,和目标框的生产Proposal部分。
Backbone
VoteNet是直接处理点云来进行目标检测的一个很好例子,其Backbone部分,采用了PointNet++中的SA下采样模块来对点云下采样的同时,提升其特征维度,但考虑到需要进行目标检测,最后采样后剩下的点太少了,于是会在最后接上两个FP模块来在不改变特征维度的情况下,进行上采样,扩充特征空间中的点云数量。
具体而言:
SA:FPS最远点采样->Ball-query+Group进行球查询后获得K个领域->MLP+Maxpooling经过多层全连接提取特征后汇聚特征。
FP:将输入第L个SA层的输入输出中的点云,计算距离矩阵来做为插值特征的权重,将得到的插值特征和输入特征拼接经过MLP后,升维得到上采样的点云特征。
经过Backbone得到的点云,称为Seeds,可以认为Seeds就是2维图像经过特征提取后的对图像的抽象特征表示形式。其实不经过后续的Vote操作来获得物体的中心点,也可以进行目标检测,但如上述所言,经过Vote后的物体内部的点,更能生成精确的位置信息。
Vote
Vote操作即将经过Backbone生成的Seeds点,通过霍夫投票的思想来生成中心点,而为了在网络上方便的训练和融合,作者利用MLP来处理Seeds点,让网络自主的学习从Seeds点到内部中心点的变换,每个点 ,其中
,其中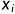 表示
表示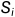 点在空间中的坐标,
点在空间中的坐标, 则表示点所带有的特征信息,将点经过MLP+BN+Relu后,网络学习点到其中心点的空间偏移量
则表示点所带有的特征信息,将点经过MLP+BN+Relu后,网络学习点到其中心点的空间偏移量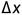 和特征偏移量
和特征偏移量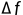 以此通过每个投票获得中心点。
以此通过每个投票获得中心点。

当然,这种Vote的过程是需要监督来完成的,由于我们知道每个BB框的中心点坐标,所以可以通过损失函数的形式来对坐标进行监督,而有关特征偏移量的学习,则相对于一种补偿机制。其中,我们只对是在目标物体表面的Seeds点来进行预测监督。
Proposal Generate
在得到Votes点后,我们对这些点进行一个SA操作,就相对于对这些点进行了聚合并且分成一簇簇的去提取了特征,即相对于在2D领域经过RPN后把生成的proposal一个个特征向量进一步提取特征。
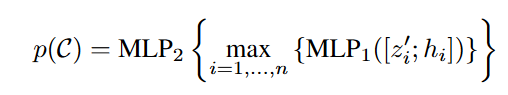
在将聚合了Votes点的特征经过预测头,在这里就是MLP+BN+Relu的操作,生成2+3+num_heading_bin*2+num_size*4+num_classes的向量做为proposal向量。其中2为是否是物体判断的objectness scores,3为基于上一步SA层进一步生成聚合点的xyz坐标里真实中心的偏移量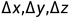 ,num_heading_bin为BB框的朝向角预测划分离散形式,在sun-rgbd数据集中,就划分为12个角度,细分为180/12=15°。而num_size和2D里常常直接预测BB的大小不同,其也是一种偏移概念,作者统计了每种物体的mean size,然后通过网络来预测其对应的偏移大小,num_classes则是代表预测物体的类别信息。
,num_heading_bin为BB框的朝向角预测划分离散形式,在sun-rgbd数据集中,就划分为12个角度,细分为180/12=15°。而num_size和2D里常常直接预测BB的大小不同,其也是一种偏移概念,作者统计了每种物体的mean size,然后通过网络来预测其对应的偏移大小,num_classes则是代表预测物体的类别信息。
像上面说的,不利用Votes点,而利用Seeds点也可以生成proposal点,其区别在于,我们可以通过FPS算法,来对Seeds进行采样获得伪的Votes点,也相对于是一种进一步聚合的方法。
如果对VoteNet进行总结,可以发现其和2D图像里的二阶段目标检测方法其实是异曲同工的,先通过Backbone来提取特征,对提取出的特征用RPN/SA生成proposal,最后对proposal进一步操作,预测其BB属性。区别的是在直接处理点云的网络中,其把许多卷积的操作换成了SA操作,而且不仅需要处理特征信息,也要注意点云原始空间信息的运用,另外在二维图像中,想要获得更多的感受野,一般都需要卷积操作,而在点云中,则可用通过FPS操作后,ball-query+SA来提升采样点的感受野信息。
H3DNet
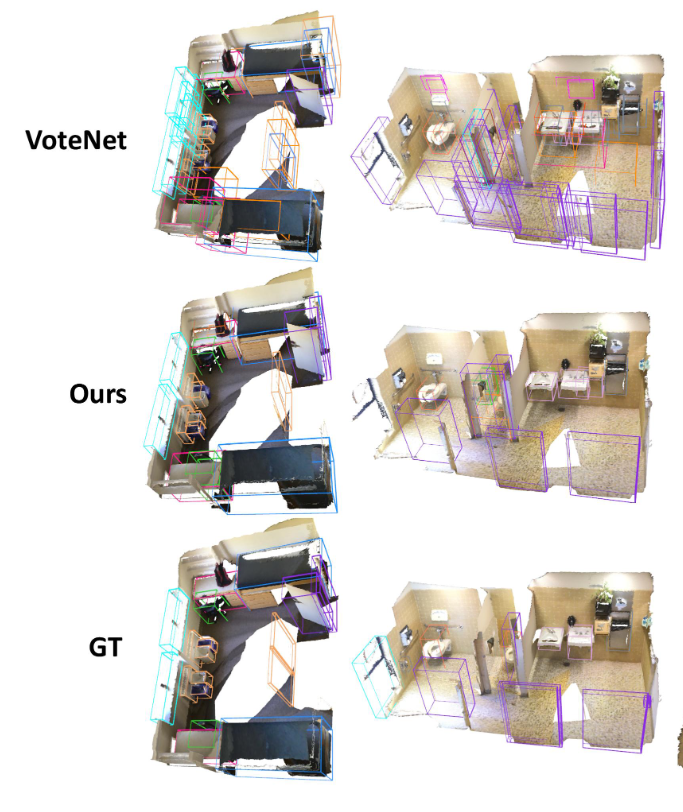
H3DNet是VoteNet的续作,其主要对VoteNet中的一些结果进行分析,然后发现仅仅利用Votes点,也就是中心点,对于如画框这种薄的物体,中心信息有可能并不如其边的信息有效,而对于几何信息丰富的BB框的边界,通过其面的约束,可以使其预测的更加精确。于是作者提出不仅要对物体中心点进行votes,对物体每个面的中心votes和物体的边进行votes也是十分有效的。
而如何Vote的细节,VoteNet中已经提及了,H3DNet需要解决的是,如何将多种Votes的结果利用起来,利用不同Votes的特征来约束生成更加精确的BB。
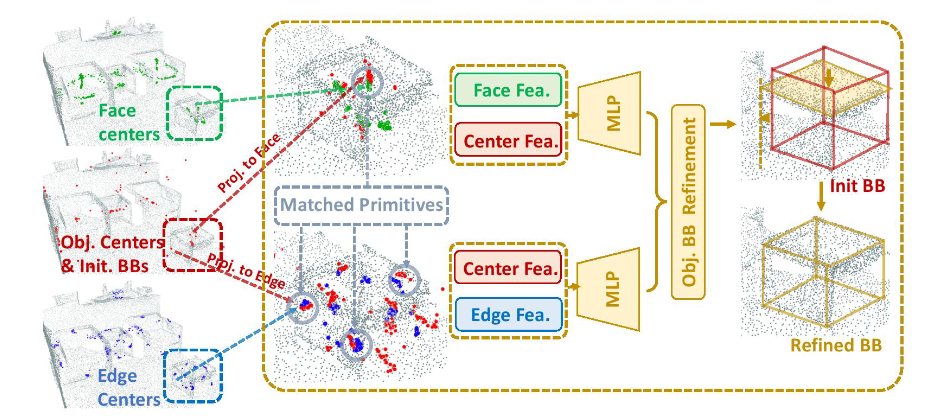
其主要思路在于,通过构建一个距离函数来表示每个Votes点距离其真正中心点的距离,其生成的proposal应该有最小化这个距离函数的效果。(中心点+6个面心+12条边的中点=19)
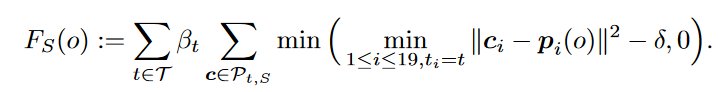
作者利用和VoteNet一样的方法,使用物体中心的Votes点来生成初始的proposal,然后利用face和edge信息来最小化这个距离函数,以达到refine初始proposal生成更精细结果的特点。
而在特征融合方面,作者将center的feature当做是初始的特征,分别和来自face和edge的feature进行match,所谓的match就是SA模块:采样+聚合,最后聚合后的face和edge特征concat起来对初始的proposal完成refine。
总结
H3DNet个人我认为,也是一篇工程性或者带有刷点性质的工作,不过其提供了一种改进直接处理点云网络的思路,就是数据的表达,会对最后的效果产生很大的影响,不像2D的工作,在3D中,由于BB的属性相对于2D而言,多了很多特征,而怎么样的表达形式,可以去更好表征BB框中的特征。如最先VoteNet提出通过内部信息的点的表达会比用表面的点,对最后生成BB框有更好的效果,和H3DNet认为face和edge特征对于BB框的表达很重要等,这种对点云不同表达,是值得研究的课题。
H3DNet虽然每种信息的表达不是完全孤立或者独立的,但如edge vote和line vote的产生是并行的,只是在特征层面稍微进行了融合,总归不是一种高效的表达形式。