考柿时间是3.9
文章目录
- 多机系统
- 并行性发展及计算机系统的分类
- 开发并行性的途径
- 计算机系统的分类(Flynn分类)
- SISD与片内并行(芯片内的并行机制)
- SIMD分成两个子类:
- MIMD分为两类(**主要区别就是它们是否有共享的内存**、单系统映像):
- 多机互联网络
- 当代典型的并行机系统
- 并行系统的性能
- 期末考点
- 紧耦合:计算机间物理连接频带较高,一般通过总线or高速开关实现计算机的互联,可共享主存。
- 松耦合:通过通道or通信线路实现互联,可共享外设。
多机系统
并行性发展及计算机系统的分类
并行性:可同时进行运算或操作的特性。并行性同时包括同时性以及并发性。
同时性:两个或多个事件在同一时刻发生。
并发性:在同一时间间隔内发生。
开发并行性的途径
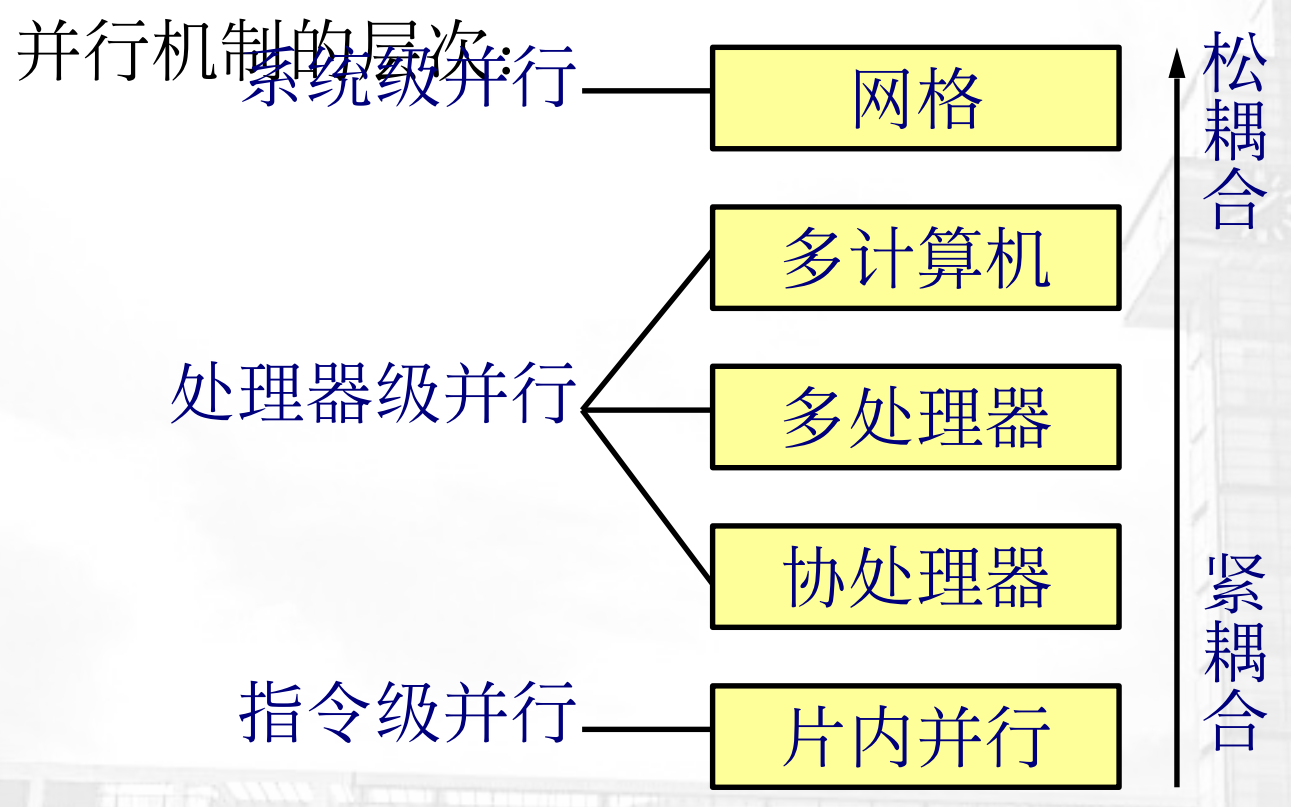
在计算机系统中实现并行处理机制的方法有如下4类:
- 时间重叠:运用时间并行技术,通过让多个处理任务或子任务同时使用系统中的不同功能的部件,使系统处理任务的吞吐量增大。如流水线
- 资源重复:大量重复设置硬件资源,使多个处理任务或子任务同时使用系统中的多个相同功能的部件,使系统处理任务中的吞吐量增大,从而达到使系统运行速度提高的目的。如多CPU
- 时间重叠+资源重复:同时运用时间和空间并行技术,当前并行机制的主流。
- 资源共享:软件方式
计算机系统的分类(Flynn分类)
一般来说,线程级并行比数据级并行更加灵活,用途也更加广泛。
大多数的现代的并行计算机都属于MIMD。
-
SISD 单指令流单数据流 一个时刻只做一件事(冯·诺伊曼计算机)
SISD与片内并行(芯片内的并行机制)
并行行为都发生在一个芯片内部。它实现加速的方式是:使芯片在同一时间内完成更多的工作来增加芯片的吞吐量。
- 指令级并行:允许多条之类在片内流水线的不同功能单元上并行执行。
- 芯片多线程:CPU在多个线程之间来回切换。
- 单片多处理器(多核CPU):同一芯片内设置了多个处理器内核,并允许它们同时运行。
-
SIMD 单指令流多数据流 相同的操作并行应用于各数据流来实现数据级并行
SIMD分成两个子类:
- 向量计算机/超级计算机:在一个向量的每个元素上并行执行相同的操作。
- 阵列计算机:处理并行类型- 可以利用一个控制单元把指令广播给多个独立的ALU进行处理。
-
MISD 多指令流单数据流 多条指令同时在同一数据上进行操作(至今无)
-
MIMD 多指令流多数据流 多个CPU执行不同操作,线程级并行
MIMD分为两类(主要区别就是它们是否有共享的内存、单系统映像):
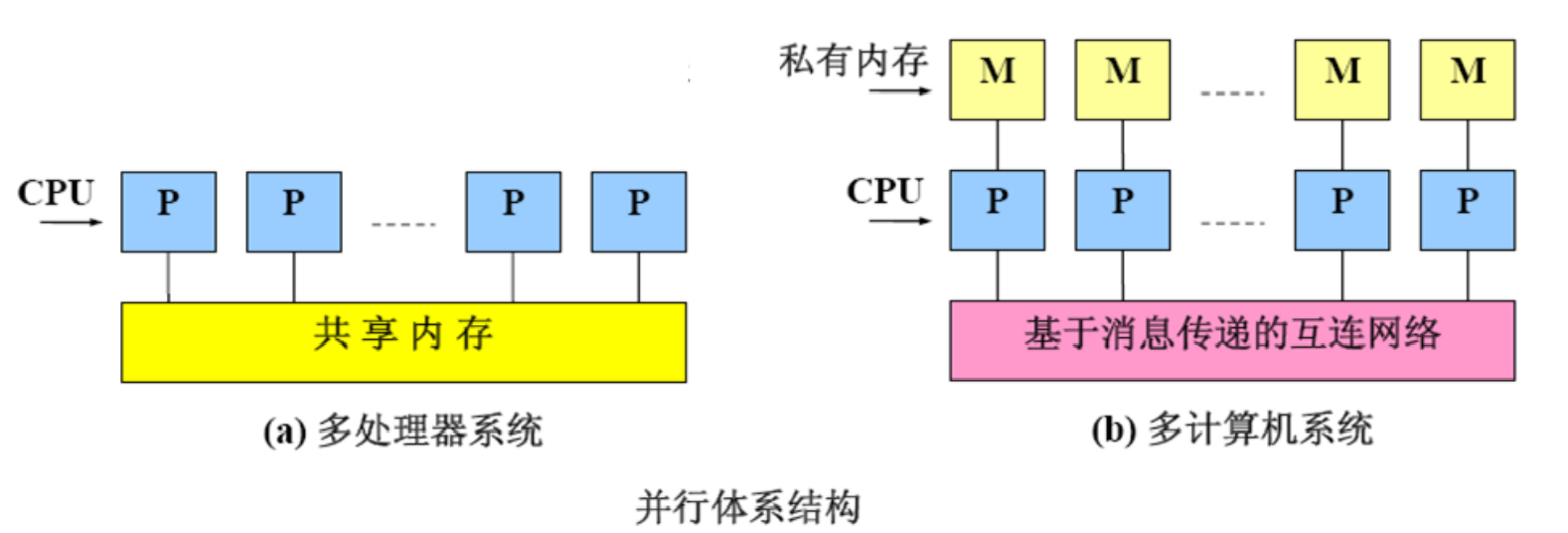
- 多处理器系统-共享存储器计算机-只有一个OS副本
- 多计算机系统-消息传递计算机-每台计算机都有自己的OS副本

向量处理机VS阵列处理机
| 向量处理器 | 阵列处理器 | |
|---|---|---|
| belong | 共享内存,所有加法运算由一个单独的高度流水的加法器实现。 | 分布式内存 |
| 都是数据组成的阵列 | 向量寄存器(由常规寄存器组成) | 对每个向量中元素都要有一加法器 |
| 特征 | 执行向量指令 | 不需要同步,步调一致,无商用产品 |
向量指令の重要特性:
- 一条向量指令相当于一个完整循环程序,因此需要足够的指令获取和译码带宽。
- 向量元素计算互不相关,硬件在一条向量指令执行期内不必检查数据相关。
- 硬件仅需在两条向量指令之间对每个向量操作数检查一次数据相关,而不需要对向量的每个元素进行检查。
- 如果向量元素是全部毗邻的,向量指令访问存储器的最好模式是从一组交叉存取的存储块中获取向量,即整个向量仅有一次等待主存的代价
多处理器系统–实现困难,编程容易
多处理器系统共享内存,因此CPU具有通过执行LOAD/STORE指令读/写远程内存的能力。
根据共享内存的实现方式分成:
- UMA(Uniform Memory Access):CPU访问所有共享内存模块的时间都相同。
- NUMA(Non-Uniform Memory Access):由于共享内存被分组并分布到每个处理器,使得远程内存的访问时间比本地内存要稍长一些。出于提高性能的考虑,主要关系到代码和数据的位置。
- COMA(Cache Only Memory Access):Cache块可以根据需要在不同的处理器间移动,不像其他设计那样有固定的位置。
多计算机系统(分布式内存系统)–实现简单,编程困难
每个CPU都有自己的私有本地内存,只供CPU自己通过LOAD/STORE指令使用。
处理器or进程间利用消息传递机制通信,通常使用send/receive原语。
多机互联网络
在具有多处理器or多计算机的系统(MIMD)的系统中,Interconnection network is important .
互联网络:是一种由开关元件按照一定的拓扑结构和控制方式构成的网络,用于实现计算机系统中部件之间,处理器之间,部件与处理器之间甚至计算机之间的相互连接。
静态互联网络:各节点之间由固定的连接同类,且在运行中不能改变的网络。
– 线性、二位网格、树形、超立方网络
动态互联网络:由交叉开关构成,可按运行程序的要求动态地改变连接状态地网络。
– 总线、交叉开关网络、多级互联网络、多级均匀洗牌网络
实现packet在互联网络上从src送往dst节点的机制是routing,including route selection and information transmission.
当代典型的并行机系统
- 共享存储多处理器系统–对称多处理器SMP(including UMA,NUMA)
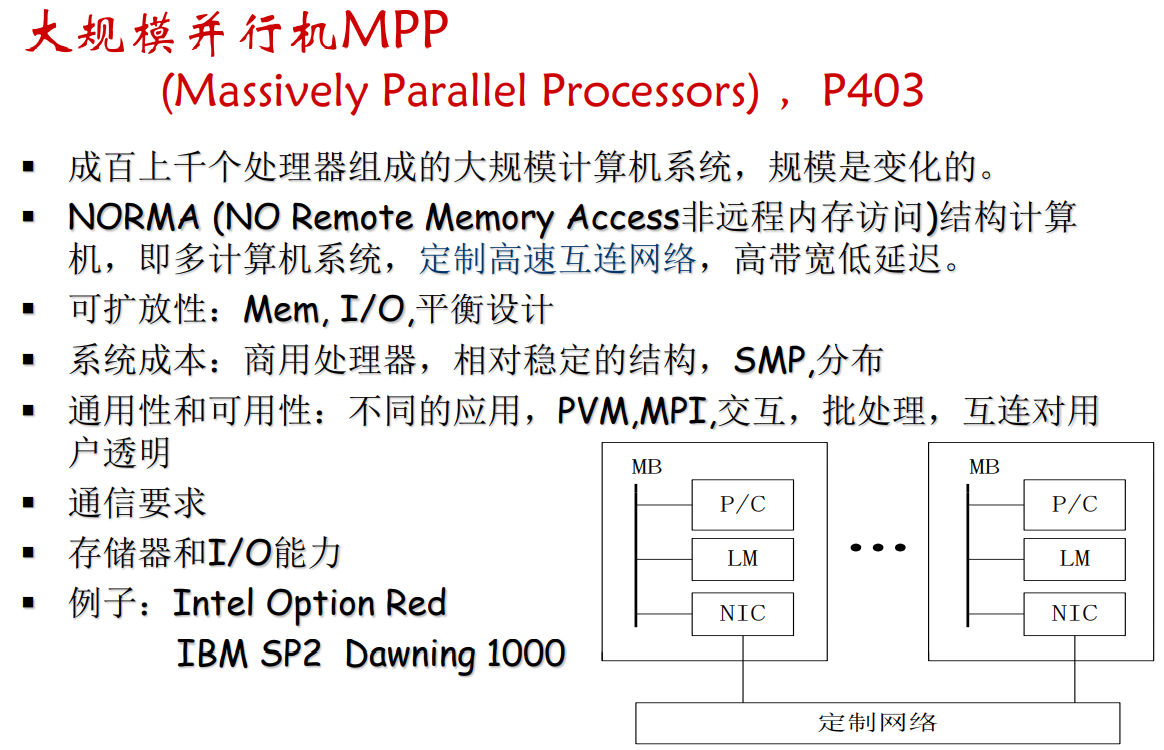
- 分布存储多计算机系统–大规模并行机MPP
- 机群系统–工作站机群COW
对称多处理器系统的特点:
- 系统是由两个以上的多个相同的处理机构成
- 多个处理机通过总线or其他互联方式连在一起
- 所有处理机通过相同的通道or不同的通道共享IO设备
- 每一处理机都能完成相同的功能
- 整个对称多处理器系统是在一个集中的OS统一管理下 仕事



并行系统的性能
Amdahl定律
challenge
- 程序可获得的并行度有限–提高程序的并行度
- 相对较高的通信开销–减少长时间远程访问的延迟
期末考点
如何通信,如何分类,有什么类型,简答题(7分)
SISD SIMD MISD MIMD
6(0.4) 8(0.6) 9
课后题,概念
不考记分牌
覆盖一个到两个:8255(必),8253,8259
8259的概念,简单代码题
课后题答案大多在微机原理内。

IMD MISD MIMD
6(0.4) 8(0.6) 9
课后题,概念
不考记分牌
覆盖一个到两个:8255(必),8253,8259
8259的概念,简单代码题
课后题答案大多在微机原理内。