近日,语音技术领域国际会议ICASSP公布了本届论文审稿结果,阿里巴巴达摩院语音实验室有14篇论文被大会收录。本次被接收的论文研究方向涵盖语音识别、语音唤醒、语音增强、说话人日志、语义理解、多模态预训练等。
01
TOLD: A Novel Two-Stage Overlap-Aware Framework for Speaker Diarization
论文作者:王嘉明、杜志浩、张仕良
论文单位:阿里巴巴集团
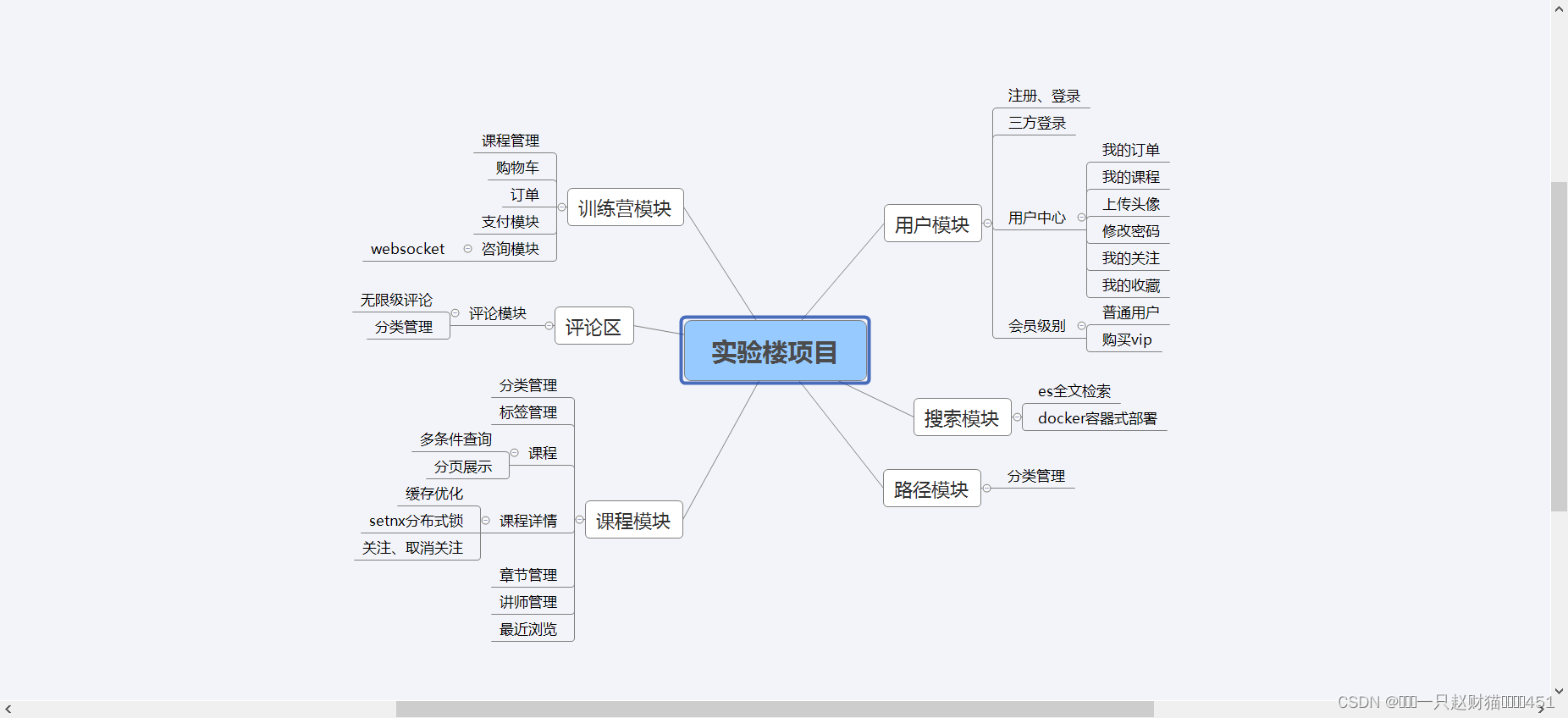
核心内容:基于端到端神经网络的说话人日志模型(EEND)在说话人重叠场景下取得了不错的结果。在EEND中,说话人日志被定义为一个多标签分类问题,其对于每个说话人的估计是独立的,忽略了说话人之间的依赖关系。为了克服这一缺陷,本文采用幂集编码(power set encoding,PSE),将说话人日志重新定义为一个单标签分类问题,提出了overlap-aware EEND (EEND-OLA) 模型,实现了对于说话人重叠和依赖的显式建模。此外,受到两阶段混合系统成功的启发,本文进一步提出了Two-stage OverLap-aware Diarization framework (TOLD) 模型,通过引入说话人重叠后处理(speaker overlap-aware post-processing,SOAP)来迭代改善说话人日志的结果。实验结果表明,与原始的EEND模型相比,本文提出的EEND-OLA在DER指标上实现了14.39%的相对改进,而采用SOAP则能进一步带来19.33%的相对改进,最终,本文提出的TOLD在CALLHOME数据集上取得了10.14%的DER。
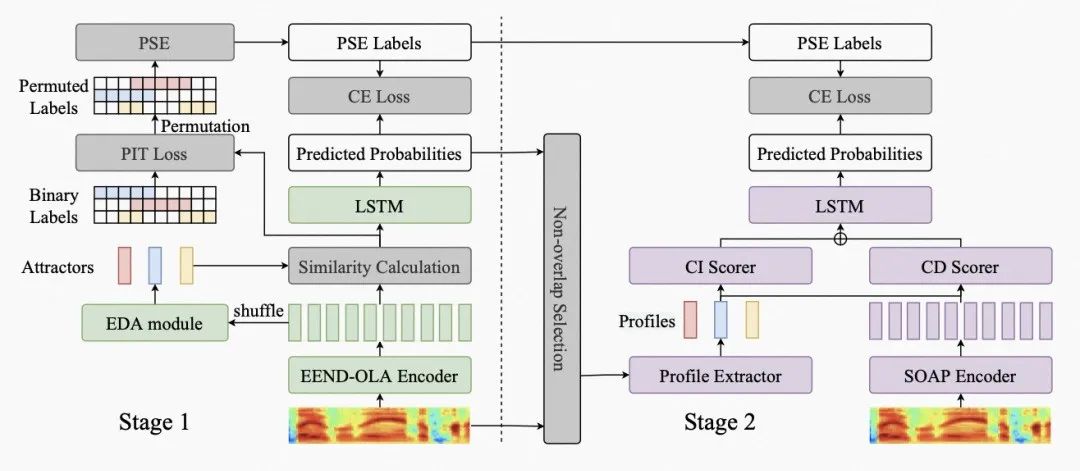
图示. 论文提出的TOLD框架的整体结构
02
MossFormer: Pushing the Performance Limit of Monaural Speech Separation Using Gated Single-Head Transformer with Convolution-Augmented Joint Self-Attentions
论文作者:赵胜奎, 马斌
论文单位:阿里巴巴集团
论文链接:https://arxiv.org/abs/2302.11824
模型已上线至ModelScope社区:
https://modelscope.cn/models/damo/speech_mossformer_separation_temporal_8k/summary
核心内容:基于Transformer架构的模型在单声道语音分离方面提供了显著的性能改进,然而,和Cramer-Rao上限相比,仍存在明显差距,主要原因在于自注意力运算的二次复杂度使Transformer架构受限于输入序列的长度,在语音分离任务上为了能够处理较长的时域输入序列,最新的基于Transformer的语音分离模型沿用双路径框架,将输入序列截断成较小的序列块,然后分别处理块内和块间的信息,该处理方式使跨块间的长距离信息依赖需要通过中间状态隐式建模,这一事实可能对长距离建模能力产生负面影响,导致模型次优表现,另外,Transformer架构主要针对序列块进行建模,而对局部特征模式的建模效率低下。在这项工作中,我们提出一种带有卷积增强联合自注意力的门控单头Transformer架构进行语音分离任务,命名为MossFormer(Monaural speech separation Transformer)。MossFormer采用了联合局部和全局自注意力架构,同时对局部块执行二次复杂度自注意力和对整个序列执行线性低成本的自注意力,能够直接建模全序列的元素信息交流,有效地提升双路径架构中跨块的间接元素信息交流的性能。此外,我们采用了一种较强大的自注意力门控机制 (Gated Attention)来提升性能和降低复杂度,不需要使用多头自注意力机制,而是采用简化的单头自注意力机制。除了关注长距离建模外,我们还通过卷积来增强MossFormer的局部特征建模能力。因此,MossFormer模型在WSJ0-2/3mix和WHAM!/ WHAMR!基准测试中显著优于以前的模型。不仅在WSJ0-3mix上达到了21.2 dB的SI-SDRi上限,并且仅比WSJ0-2mix上限23.1 dB低0.3 dB。
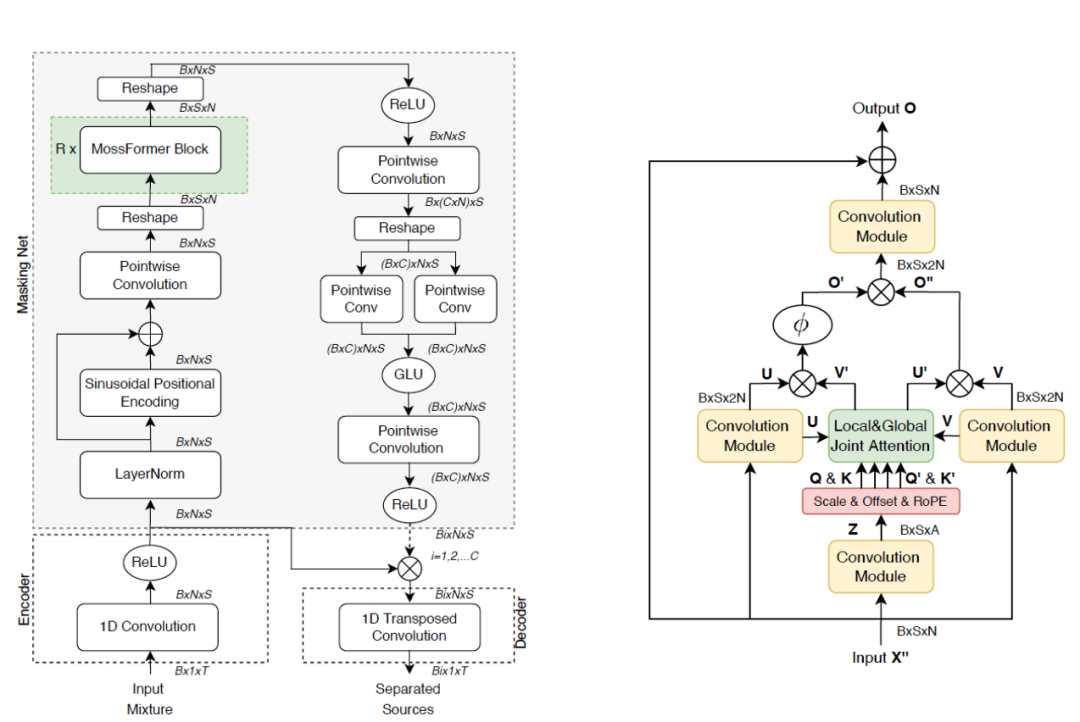
左图为MossFormer模型整体结构示意图, 由一个卷积编码器-解码器结构和一个掩蔽网络组成,编码器-解码器结构负责特征提取和波形重建,掩码网络执行从编码器输出到𝐶组掩码的非线性映射。右图为MossFormer模块架构示意图,一个MossFormer 模块由四个卷积模块、缩放&偏移&旋转位置编码操作、联合局部和全局单头自注意力(SHSA)以及三个门控操作组成,负责进行长序列的处理。
03
D2Former: a Fully Complex Dual-Path Dual-Decoder Conformer Network Using Joint Complex Masking and Complex Spectral Mapping for Monaural Speech Enhancement
论文作者:赵胜奎, 马斌
论文单位:阿里巴巴集团
论文链接:https://arxiv.org/abs/2302.11832
核心内容:在时频域(Time-Frequency Domain)中,基于实数网络的单声道语音增强算法已被广泛的进行了研究。然而,考虑到模型特征输入和模型目标输出在时频域中具有自然的复数值特性,因此非常需要一个完全为复数运算的网络模型来更有效地对复数值特征表示和复数值特征序列进行学习和建模。此外,时频域的语音相位作为语音感知质量的一个重要因素,已被广泛验证可以与语音幅度谱一起通过模型学习复数值掩蔽或复数值频谱的方式从带噪的语音中进行估计。
许多最近的研究大多集中在独立的复数值掩蔽或复数值频谱估计上,而忽略了它们各自学习目标的局限性。为了有效改善上述问题,我们提出了一个基于Conformer结构的完全使用复数值网络的语音增强模型:D2Former。在D2Former设计中,我们将Conformer中的实数值注意力机制扩展到复数值注意力机制,并结合时间序列和频域序列的双路径处理模式,更有效地对复数值时频语音特征序列进行建模。我们基于沿时间轴的复数值扩张卷积(Dilation Convolution)和沿频率轴的递归复数值前馈序列记忆网络 (Complex FSMN),通过双路径学习模式进一步提升编码器和解码器中的时频特征表示和处理能力。此外,我们通过一个多任务联合学习框架来结合复数值掩蔽和复数值频谱映射两个训练目标的优势,来改善模型学习的性能。因此,D2Former充分利用了复数值网络运算、双路径特征处理、和联合目标训练的优势,在与之前的模型相比中,D2Former以最小的模型参数量(0.87M)在VoiceBank+Demand基准测试中取得了最好的语音增强综合效果。

图1. D2Former模型架构示意图
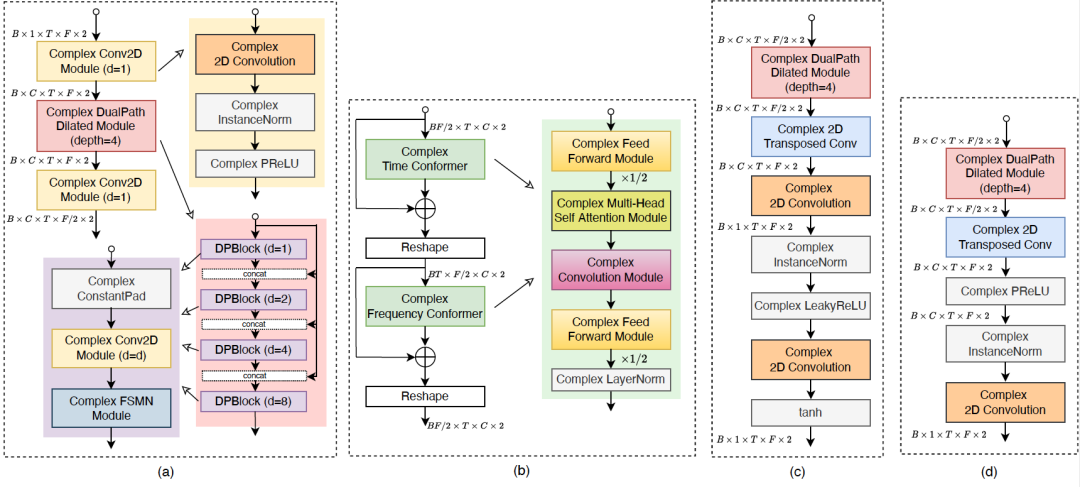
图2. D2Former各模块的网络结构示意图。 (a) 复数值双路径编码器模块,(b) 复数值双路径Conformer模块,(c) 复数值双路径掩蔽解码器模块,(d) 复数值双路径频谱解码器模块。
04
Pushing the Limits of Self-supervised Speaker Verification Using Regularized Distillation Framework
论文作者:陈亚峰,郑斯奇,王绘,程路遥,陈谦
论文单位:阿里巴巴集团
论文链接:https://arxiv.org/pdf/2211.04168.pdf
核心内容:在无法获得说话人标签的语音数据条件下,训练一个鲁棒性强的说话人识别系统是一个极具挑战性的任务。研究表明全监督说话人识别和自监督说话人识别之间仍存在不小的性能差距。在这篇文章中,我们将自监督学习框架DINO应用于说话人识别任务,并针对说话人识别任务提出多样性正则和冗余度消除正则。多样性正则提高特征多样性,冗余度正则减小特征冗余度。不同数据增强方案的优劣在该系统中得以验证。大量的实验在公开数据集VoxCeleb上开展,表现出Regularized DINO框架的优越性。

05
Meeting Action Item Detection with Regularized Context Modeling
论文作者:刘嘉庆,邓憧,张庆林,陈谦,王雯
论文单位:阿里巴巴集团
核心内容:随着技术的进步和疫情的推动,线上会议成为越来越普遍的协作沟通方式。在自动语音识别(ASR)的帮助下,我们可以越来越便捷地获取会议音频对应的转写文本(即会议记录)。然而,从会议记录中提取重要信息(如议题、决策、待办等)形成会议纪要,仍然主要依赖于人工整理。因此,很多任务被提出希望机器自动识别重要信息,辅助人工整理会议纪要。其中,行动项识别是在会议记录中自动识别待办的相关内容。行动项识别相关的数据集非常稀缺,为此我们构建并计划开源第一个带有行动项标注的中文会议数据集。在此基础上,我们提出了 Context-Drop 方法,通过对比学习来更好地建模局部和全局上下文,在行动项抽取表现和鲁棒性方面均取得了更好的效果。此外,我们探索了 Lightweight model ensemble 的方法,利用不同的预训练模型,提高行动项抽取的表现。
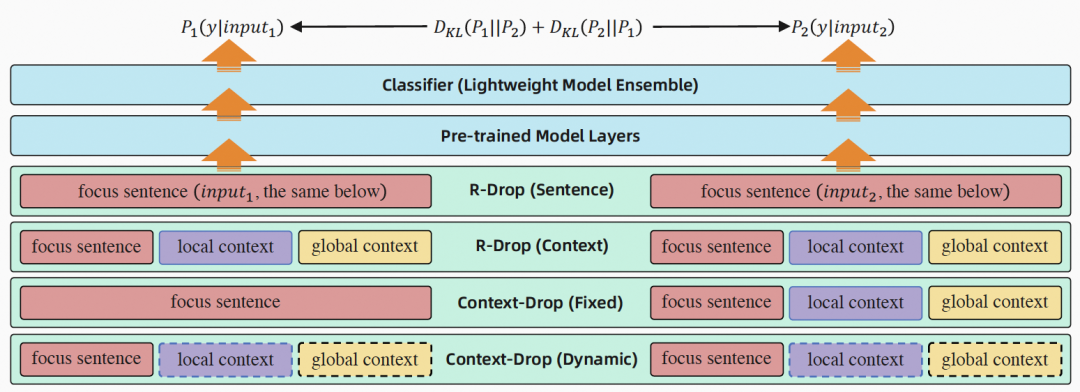
图示. 不同上下文建模方式及 Lightweight model ensemble 示意图
06
MUG: A General Meeting Understanding and Generation Benchmark
论文作者:张庆林,邓憧,刘嘉庆,于海,陈谦,王雯,鄢志杰,刘静林,任意,赵洲
论文单位:阿里巴巴集团,浙江大学
数据集详细信息链接:
https://www.modelscope.cn/datasets/modelscope/Alimeeting4MUG/summary
核心内容:从视频会议和在线课程中收集信息时,听取长时间的视频/音频记录是非常低效的。即使ASR系统将录音转录成长篇的口语文档,读取ASR转录也只能在一定程度上加快查找信息的速度。众多研究表明,关键词提取、主题分割和摘要等一系列自然语言处理应用显著提高了用户获取重要信息的效率。会议场景是应用这些口语处理能力最有价值的场景之一。然而,缺乏针对这些口语处理任务进行注释的大规模公共会议数据集严重阻碍了它们的发展。为了推动口语处理的进步,我们建立了一个大规模的通用会议理解与生成基准(MUG),用于评估各种口语处理任务的性能,包括主题分割、主题级和会话级摘要、主题标题生成、关键词提取和行动项检测。为了方便MUG基准测试,我们构建并发布了一个全面的长篇口语处理开发的大规模会议数据集,即AliMeeting4MUG Corpus,其中包括424个涵盖不同主题的普通话会议记录,手动标注了音视频会议下人工转写文稿的SLP任务。在论文中,我们详细介绍了该语料库、SLP任务和评估方法、基线系统及其性能。
07
Auxiliary Pooling Layer for Spoken Language Understanding
论文作者:马煜坤, Trung Hieu Nguyen, 倪瑾杰, 王雯, 陈谦, 张冲, 马斌
作者单位:阿里巴巴集团,南洋理工大学
核心内容:端到端口语理解需要有语义标注信息的语音数据,而且可能会受到标注数据不足的影响。最近很多研究工作聚焦在利用未标注的语音数据对语音编码器进行预训练。然而,对于预训练语音表征来说,编码语义信息仍然是一个挑战。现有的研究通过在固定粒度上使用不同的对齐损失来探索从预训练文本模型转移知识。在本文中,我们通过 APLY(一种辅助池化层)解决了从文本到语音表示的可变粒度问题,它明确地融合了全局信息和自适应编码的本地上下文。我们在三个口语理解基准测试上展示了 APLY 的有效性。
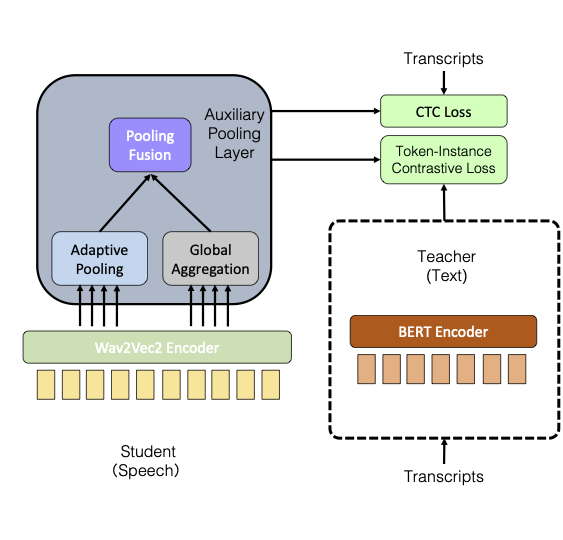
图示. 跨模态知识蒸馏结构示意图
Wav2vec2编码器是学生模型。BERT编码器是预训练文本模型。Auxiliary Pooling Layer用于融合多颗粒度信息,以更好地对齐BERT模型中编码的知识。
08
Weighted Sampling for Masked Language Modeling
论文作者:张琳涵,陈谦,王雯,邓憧,Xin Cao,Kongzhang Hao,Yuxin Jiang,Wei Wang
论文单位:阿里巴巴集团,新南威尔士大学,香港科技大学(广州)
核心内容:掩码语言模型(Masked Language Modeling,MLM)被广泛用于预训练语言模型。标准的随机掩码策略会导致预训练语言模型(PLMs)偏向于高频词。对于罕见词的表示学习效果较差,且PLMs在下游任务中的性能受到限制。为了缓解这种频率偏差问题,我们提出了两种简单而有效的加权采样策略,以基于词频和训练损失进行掩码。我们将这两种策略应用于BERT,并获得了加权采样BERT(WSBERT)。在语义文本相似性基准(Semantic Textual Similarity benchmark,STS)上的实验表明,WSBERT在句子嵌入方面明显优于BERT。将WSBERT与校准方法和提示学习相结合,进一步提高了句子嵌入的性能。我们还研究了在GLUE基准上微调WSBERT,并表明加权采样也提高了骨干PLM的迁移学习能力。我们进一步分析并提供了WSBERT如何改善token嵌入的见解。
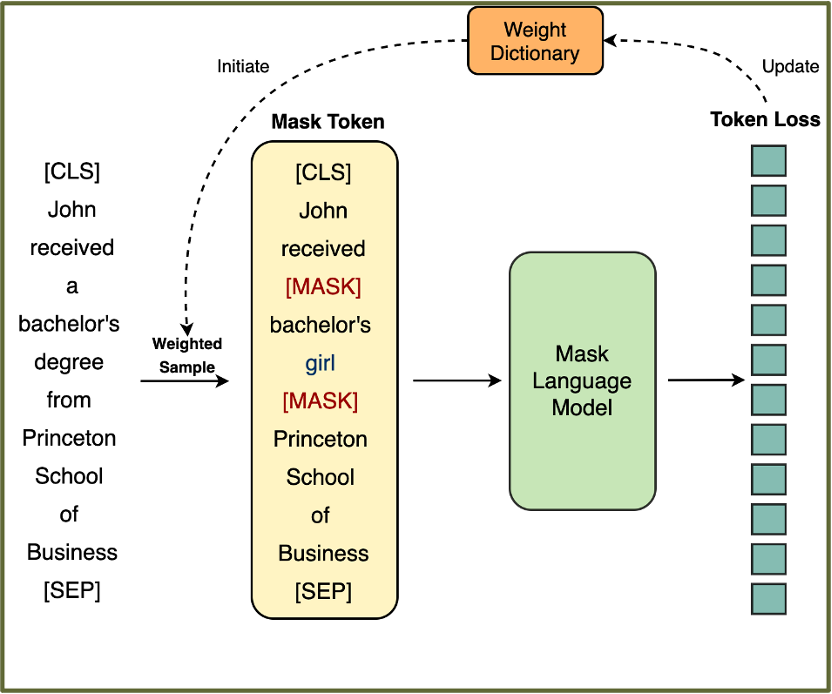
图示:动态加权采样用于掩码语言模型(MLM)的示意图
09
Adaptive Knowledge Distillation between Text and Speech Pre-trained Models
论文作者:倪瑾杰, 马煜坤, 王雯, 陈谦, 黄殿文, Han Lei, Trung Hieu Nguyen, 张冲, 马斌
作者单位:南洋理工大学,阿里巴巴集团
核心内容:通过学习大量的语音语料库,许多自监督语音模型在近期取得了成功。通过知识蒸馏,这些模型也可以从在丰富文本资源上预训练的语言模型所编码的知识中受益。但是,由于文本和语音表征空间之间存在模态差异,因此从文本到语音的知识蒸馏过程更具挑战性。本研究我们关注如何使用少量数据即可对文本和语音的嵌入空间进行对齐,而无需修改模型结构。由于现有的研究往往忽略了文本和语音之间的语义和粒度差距,从而影响了蒸馏的效果,我们提出了先验信息自适应知识蒸馏(PAD),它可以自适应地利用可变粒度和先验显著性分布的文本/语音单元,以实现文本和语音预训练模型之间更好的全局和局部对齐。我们在三个口语理解基准上进行了评估,以展示PAD在转移语言知识方面比其他蒸馏方法更有效。
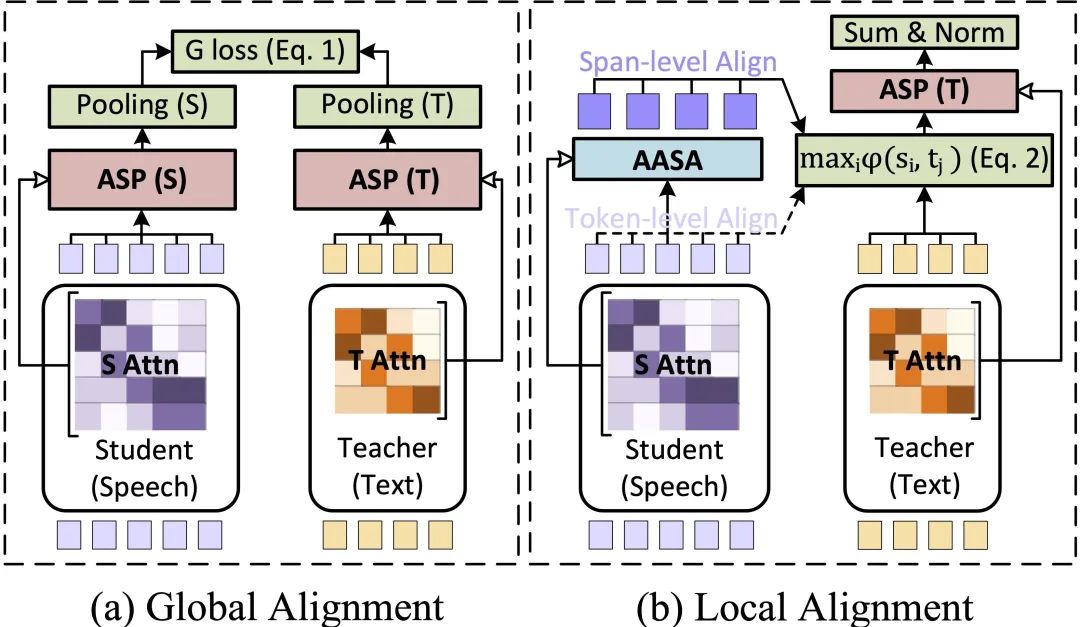
图示. 全局和局部对齐都受ASP的影响,以缩小语义差距。自适应音频段对齐(AASA)可重新组织语音序列,以缩小粒度差距。
10
deHuBERT: Disentangling Noise in a Self-supervised Model for Robust Speech Recognition
论文作者:黄殿文,张芮熙,叶家祺,杨钊,倪瑾杰,张冲,马煜坤,倪崇嘉,Eng Siong Chng,马斌
论文单位:阿里巴巴集团,南洋理工大学,西安交通大学
核心内容:自监督学习利用大量未标注语料库训练的语音预训练模型,为构建良好的语音识别模型提供了一种有效的途径。然而,当前许多模型都是在单一来源的干净语料库上训练的,当在复杂场景中存在噪声时测试表现较差,导致模型识别率降低。因此,减少噪声对识别率的损失对于实际应用至关重要。受冗余度简化原则(H. Barlow's redundancy-reduction principle)的启发,我们提出了一种新的训练框架deHuBERT,旨在通过降噪编码来提高模型对噪声的鲁棒性。deHuBERT基于原始HuBERT算法,并引入一个辅助损失函数,通过将不同信噪比的噪声对之间的自相关矩阵和交叉相关矩阵驱向单位矩阵,促使模型从输入音频数据中学习到与噪声无关的噪音解耦语音表征。实验表明,deHuBERT能够显著提高模型在域内、域外噪声场景下的识别效果,同时不影响干净数据集上的效果。

图示. deHuBERT最小化潜层特征自相关和交叉相关矩阵驱向单位矩阵。
11
Contrastive Speech Mixup for Low-resource Keyword Spotting
论文作者:黄殿文,张芮熙,叶家祺,张冲,马煜坤,Trung Hieu Nguyen,倪崇嘉,Eng Siong Chng,马斌
论文单位:阿里巴巴集团,南洋理工大学
核心内容:基于神经网络技术的关键词识别模型通常需要大量的训练数据才能学习到较好的语音表征,以在大多数智能设备上使用。然而,随着智能设备越来越趋于个性化,关键词识别模型需要利用少量的用户数据来快速进行领域自适应。为了应对低资源关键词识别问题,我们提出了一种名为CosMix的对比语音混合数据增强算法。CosMix在现有的数据混合增强技术中引入了一个辅助对比损失函数,以最大化原始样本和增强样本之间的相对相似性。通过加入增强约束,利用同一数据样本的两个不同数据增强样本(即嘈杂混合和干净预混合音频),引导模型学习到更简单但内容信息更丰富的语音表征。我们在谷歌语音命令数据集上进行实验验证,并将训练集缩小到每个关键词两分半钟以模拟低资源条件,实验结果表明,CosMix适用于多种基础模型,并且在性能方面均得到了一致的提高,展现了该方法的有效性。
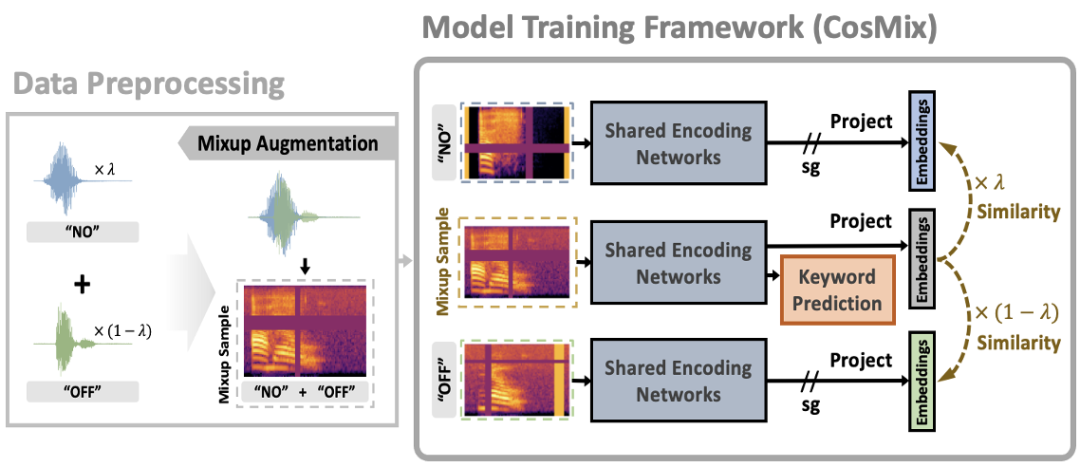
图示. Contrastive speech mixup (CosMix) 训练架构图示
12
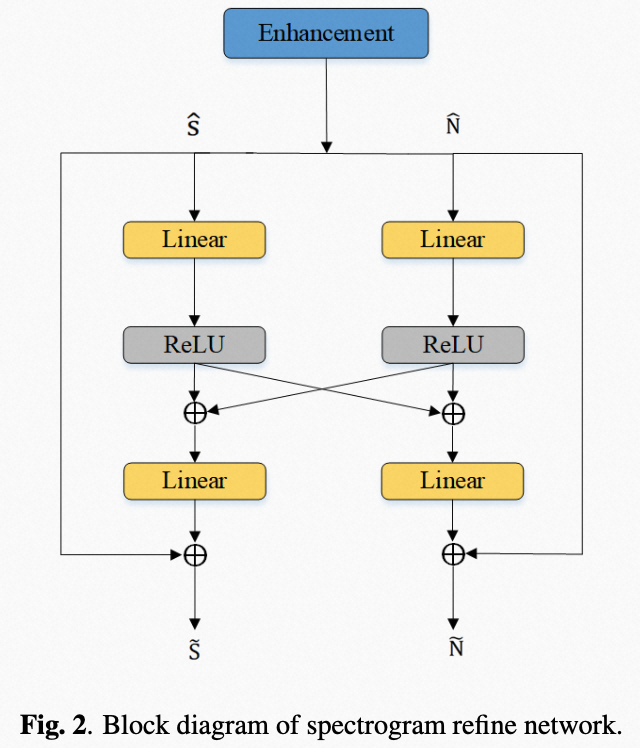
Speech and Noise Dual-Stream Spectrogram Refine Network with Speech Distortion Loss for Robust Speech Recognition
论文作者:芦皓宇、李楠、王龙标、党建武、王晓宝、张仕良
论文单位:天津大学、阿里巴巴集团
核心内容:近年来,语音增强前端(speech enhancement)和语音识别(speech recognition)后端的联合训练被广泛用于提高语音识别系统的鲁棒性。传统的联合训练方法仅使用增强语音作为后端输入。由于具有不同强度的各种类型的噪声使得语音增强系统很难直接将语音从输入中分离出来。此外,在增强语音中经常观察到语音失真和残留噪声,并且语音和噪声的失真是不同的。大多数现有方法都侧重于融合增强特征和噪声特征来解决这个问题。
在本文中,我们提出了一个双流频谱图精炼网络(dual-stream spectrogram refine network)来同时精炼语音和噪声,并将噪声与从带噪的原始输入信号中解耦出来。我们在AISHELL-1任务上验证了所提出的方案,实验结果表明我们提出的方法可以获得更好的增强效果,语音识别字错误率相对降低8.6%。
13
The DKU Post-Challenge Audio-Visual Wake Word Spotting System for the 2021 MISP Challenge: Deep Analysis
论文作者:王浩旭,程铭,付强,李明
论文单位:武汉大学,阿里巴巴集团,昆山杜克大学
资源链接:https://github.com/Mashiro009/DKU_WWS_MISP
核心内容:本文探讨了在MISP Challenge 2021唤醒赛道排名第二的系统方案。首先,研究一种基于3D和2D卷积的单模态方法,并采用了简单注意力模块(SimAM)。其次,讨论了不同的数据增强方法。最后,我们研究了分数融合、级联融合和模型融合等不同的融合策略,提出的多模态系统使用互补的视觉信息来改进复杂声学场景中纯音频系统的性能。我们的系统在竞赛测试集上获得了2.15% FRR和3.44% FAR,相比以前的系统有21%的相对提升,并达到了新的较好结果。

图示:音视频唤醒检测系统框架
14
The WHU-ALIBABA Audio-Visual Speaker Diarization System for the MISP Challenge 2022
论文作者:程铭,王浩旭,王子腾,付强,李明
论文单位:武汉大学,阿里巴巴集团,昆山杜克大学
核心内容:本文介绍WHU-Alibaba团队为多模态信息语音处理挑战赛(MISP Challenge 2022)开发的系统。我们扩展了序列目标说话人语音活动检测框架,从音视频信号同时检测多个说话人的语音活动。最终的系统在测试集评估中取得了8.82%的DER,在说话人日志赛道排名第一。
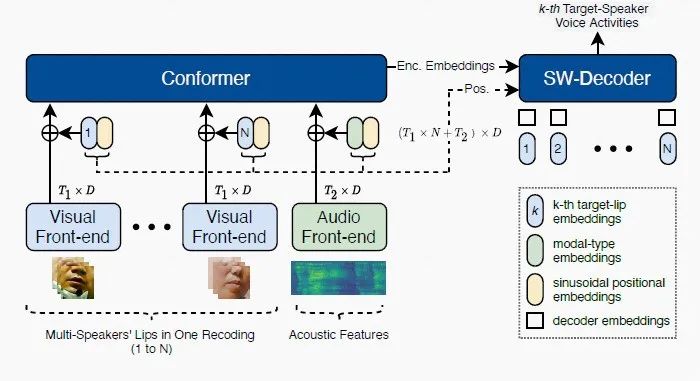
图示:音视频序列说话人检测系统框图