DAGA 代码阅读笔记1——LSTM-LM部分代码
文章目录
- DAGA 代码阅读笔记1——LSTM-LM部分代码
- 概述
- main函数逻辑分析
- 设置训练参数
- fields初始化
- 训练数据读入
- 模型建立
- 优化器
概述
学习人工智能的必经之路——读代码。目前阅读的代码来自于github数据增强项目DAGA,这个项目的原论文可以从这里获取。
这个项目主要将标记的句子线性化,然后在线性化数据上训练语言模型(LM),并用于生成合成标记数据,统一了句子生成和使用LM标记的过程。使用该方法,可以有效为序列标记任务生成高质量的合成数据,在低资源条件下,有效提升序列标记模型的性能。
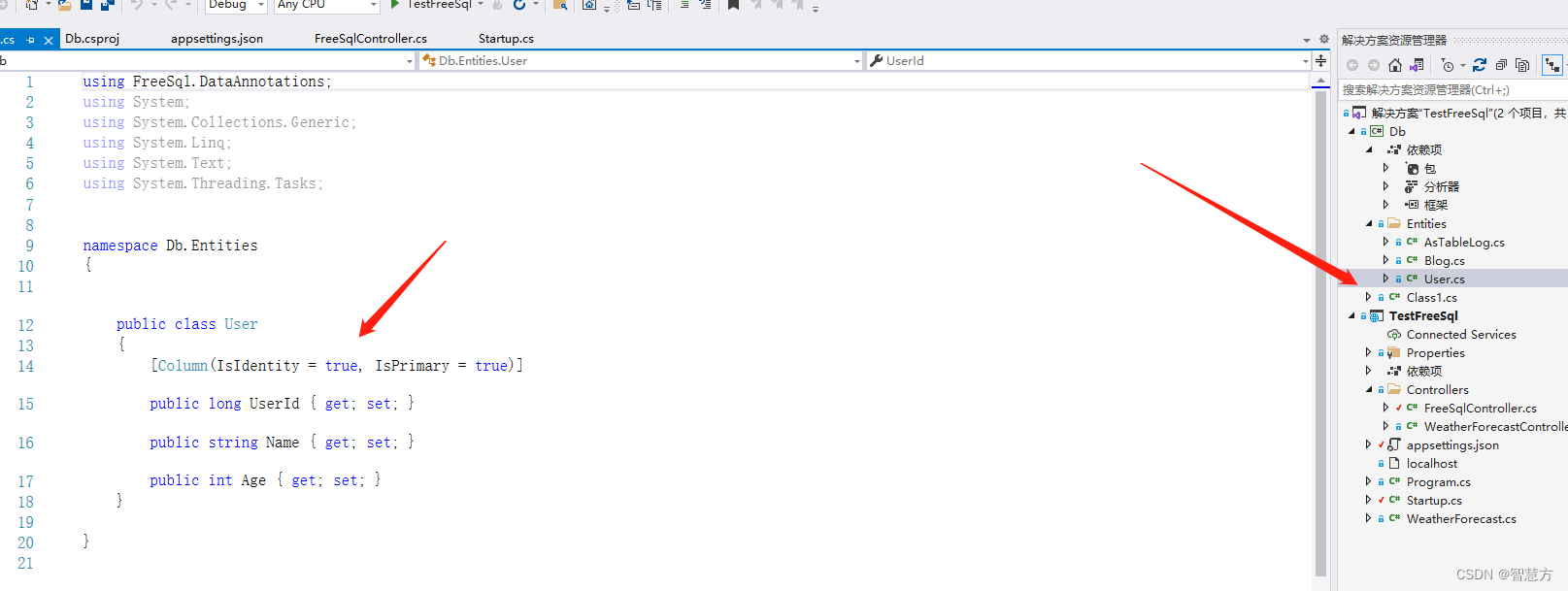
语言模型部分 代码文件如图所示
main函数逻辑分析
def main():
"""Main workflow"""
##### 运行参数读取 #####
args = utils.build_args(argparse.ArgumentParser())
##### 从模型文件中读取日志 #####
utils.init_logger(args.model_file)
##### 调用gpu训练 #####
assert torch.cuda.is_available()
torch.cuda.set_device(args.gpuid)
##### 确定随机种子 #####
utils.init_random(args.seed)
##### 设置训练参数 #####
utils.set_params(args)
logger.info("Config:\n%s", pformat(vars(args)))
##### field初始化 #####
fields = utils.build_fields()
logger.info("Fields: %s", fields.keys())
##### 训练数据读入 #####
logger.info("Load %s", args.train_file)
train_data = LMDataset(fields, args.train_file, args.sent_length_trunc)
logger.info("Training sentences: %d", len(train_data))
logger.info("Load %s", args.valid_file)
##### 测试数据读入 #####
val_data = LMDataset(fields, args.valid_file, args.sent_length_trunc)
logger.info("Validation sentences: %d", len(val_data))
##### 将数据以数值方式存储 #####
fields["sent"].build_vocab(train_data)
##### 迭代器 #####
train_iter = utils.build_dataset_iter(train_data, args)
val_iter = utils.build_dataset_iter(val_data, args, train=False)
##### 读取训练断点继续训练 #####
if args.resume and os.path.isfile(args.checkpoint_file):
logger.info("Resume training")
logger.info("Load checkpoint %s", args.checkpoint_file)
checkpoint = torch.load(
args.checkpoint_file, map_location=lambda storage, loc: storage
)
es_stats = checkpoint["es_stats"]
args = utils.set_args(args, checkpoint)
else:
checkpoint = None
es_stats = ESStatistics(args)
##### 模型建立 #####
model = utils.build_model(fields, args, checkpoint)
logger.info("Model:\n%s", model)
##### 优化器 #####
optimizer = utils.build_optimizer(model, args, checkpoint)
##### 训练效果输出 #####
try_train_val(fields, model, optimizer, train_iter, val_iter, es_stats, args)
下面按照main函数中的执行顺序,选择主要代码进行分析
设置训练参数
def set_params(args):
"""Set some params."""
args.checkpoint_file = "{}.checkpoint".format(args.model_file)
##### encoder层和decoder层的层数设置 #####
if args.num_layers != -1:
args.num_enc_layers = args.num_layers
args.num_dec_layers = args.num_layers
logger.info(
"Set number of encoder/decoder layers uniformly to %d", args.num_layers
)
##### 校验encoder层和decoder层合法性 #####
if args.num_enc_layers < args.num_dec_layers:
raise RuntimeError("Expected num_enc_layers >= num_dec_layers")
##### z维输入确认 #####
if args.num_z_samples == 0:
args.z_dim = 0
args.z_cat = False
args.warmup = 0
args.beta = 1.0 if args.warmup == 0 else 0.0
args.device = "cuda" if args.gpuid > -1 else "cpu"
fields初始化
def build_fields():
"""Build fields."""
fields = {}
fields["sent"] = torchtext.data.Field(
##### 规定example数据的句首标记、句尾标记、填充标记 #####
init_token=BOS_WORD, eos_token=EOS_WORD, pad_token=PAD_WORD
)
return fields
训练数据读入
##### 这个文件主要用于读入文本数据 #####
"""Language modeling dataset"""
import io
import torchtext
##### 使用的是torchtext.data中的Dataset结构来储存数据 #####
class LMDataset(torchtext.data.Dataset):
"""Define a dataset class."""
##### 构造函数,传参fields对象,文件名,限制句子长度 #####
def __init__(self, fields, filename, truncate=0):
sents = []
with io.open(filename, "r", encoding="utf-8", errors="ignore") as f:
for line in f:
line = line.strip().split(" ")
if truncate:
line = line[:truncate]
sents += [line]
##### fields和examples在下方说明 #####
fields = [(k, fields[k]) for k in fields]
examples = [torchtext.data.Example.fromlist([sent], fields) for sent in sents]
super(LMDataset, self).__init__(examples, fields)
##### 定义排序键:句子长度 #####
def sort_key(self, ex):
"""Sort by sentence length."""
return len(ex.sent)
这段代码中比较抽象的部分是torchtext的dataset中有两个变量:fields和examples
examples即torchtext中的example对象构造的列表,而example就是对数据集中一条数据的抽象
fields即torchtext中的field对象构造的列表,field对象可以理解为数据表中的列标题,其定义了列数据的处理形式
TorchText使用一个声明式的方法来加载数据:你可以告诉TorchText你想要的数据类型,它会根据声明处理数据。这一方式是通过 声明那个一个Field对象来实现的。Field就是你定义的数据处理形式。
下面使用样例代码直观了解field和example这两个类
##### 对field对象的参数进行设置,后续处理数据时会按照设置的形式对数据进行处理 #####
TEXT = Field(sequential=True, tokenize=tokenize, lower=True)
LABEL = Field(sequential=False, use_vocab=False)
def get_dataset(csv_data, text_field, label_field, test=False):
fields = [('id', None), ('comment_text', text_field), ('toxic', label_field)]
examples = []
if test:
for text in tqdm(csv_data['comment_text']):
examples.append(data.Example.fromlist([None, text, None], fields))
else:
for text, label in tqdm(zip(csv_data['comment_text'], csv_data['toxic'])):
examples.append(data.Example.fromlist([None, text, label], fields))
return examples, fields
train_examples, train_fields = get_dataset(train_data, TEXT, LABEL)
valid_examples, valid_fields = get_dataset(valid_data, TEXT, LABEL)
test_examples, test_fields = get_dataset(test_data, TEXT, None, True)
train = data.Dataset(train_examples, train_fields)
valid = data.Dataset(valid_examples, valid_fields)
test = data.Dataset(test_examples, test_fields)
模型建立
def build_model(fields, args, checkpoint=None):
"""Build model."""
##### 具体模型建立过程在下一篇学习笔记中分析 #####
model = LMModel(fields, args)
if checkpoint is not None:
logger.info("Set model using saved checkpoint")
model.load_state_dict(checkpoint["model"])
return model.to(args.device)、
优化器
def build_optimizer(model, args, checkpoint=None):
"""Build optimizer."""
params = [p for p in model.parameters() if p.requires_grad]
n_params = sum([p.nelement() for p in params])
logger.info("Trainable parameters: %d", n_params)
##### 优化器定义两种方法,SGD和Adam #####
method = {"sgd": torch.optim.SGD, "adam": torch.optim.Adam}
optimizer = method[args.optim](params, lr=args.lr)
logger.info("Use %s with lr %f", args.optim, args.lr)
##### 保存点optimizer参数读取 #####
if checkpoint is not None:
logger.info("Set optimizer states using saved checkpoint")
optimizer.load_state_dict(checkpoint["optimizer"])
for state in optimizer.state.values():
for k, v in state.items():
if isinstance(v, torch.Tensor):
state[k] = v.to(args.device)
return optimizer