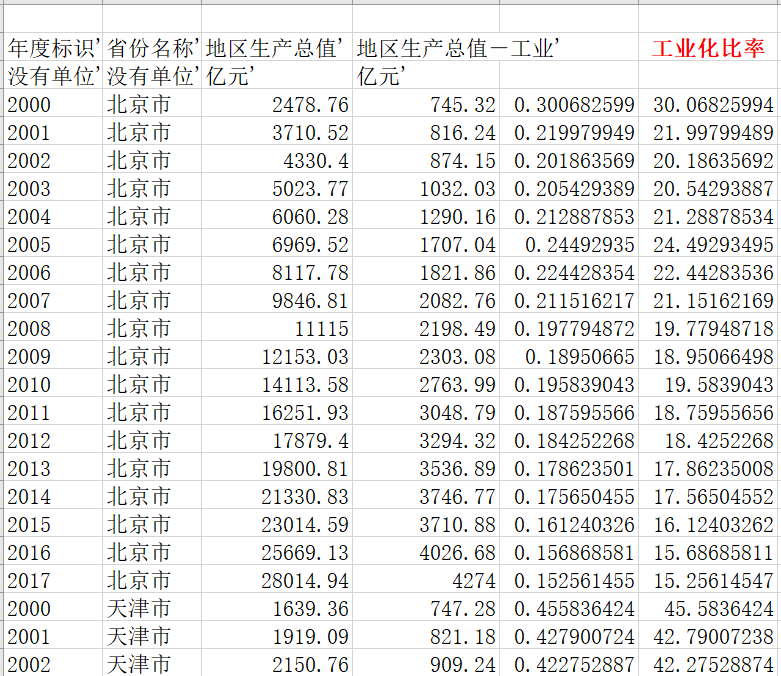
作者:Piero Paialunga
翻译:陈超
校对:和中华
本文约4200字,建议阅读11分钟
本文使用马尔科夫链的方法对星巴克购买咖啡的等待时长进行建模。
以下内容关于如何使用马尔科夫链计算你在星巴克咖啡的等待时长。


图片来自Unplash, Jon Tyson摄
我来自意大利,可以肯定的说,咖啡就是信仰。我们喝咖啡来社交,在早上喝来唤醒我们,在午餐、晚餐后也会喝咖啡。如果好久未见某个朋友,我们会说
“Vieni a prenderti un caffè”
意思是
“来喝杯咖啡吧”
我住在美国,美国人喝咖啡的方式完全不同。我上班的时候会选择将咖啡带走喝。在工作的时候喝咖啡。看电影的时候喝咖啡。美国人不喝“意式浓缩”,但是他们很享受花很长的时间喝一大整杯。此外:他们有很多种咖啡!
走进星巴克你可能会看到上百种咖啡。有黑咖啡,黑塔玛奇朵,拿铁或者星冰乐,或者是其他很多我叫不上名字的品类。
这里有很多容易制作的,也有很多复杂的咖啡。假设你在星巴克排队点咖啡,如果前面有三个人都点了黑咖啡,那你可能需要3分钟拿到你的咖啡。
然而,如果他们点了“额外鲜奶油加糖屑肉桂豆浆的焦糖玛奇朵”……那你的等待时长可能会加倍,或者至少你得多等几分钟。
所以问题是……
“我要等多久才能拿到咖啡,在此期间我可以写篇关于我要等多久才能拿到咖啡的文章吗?”
当然,我们无法获知其他人要点什么,所以这是一个概率问题(或者如果你想要一个随机过程)。所以我们该如何解决它呢?
一个可行的方法是建立马尔科夫链。或者说,我们需要一个时间依赖的马尔科夫链。
让我们来解决问题吧!
1. 理论介绍
让我们从问题的理论背景介绍和纠正错误开始。
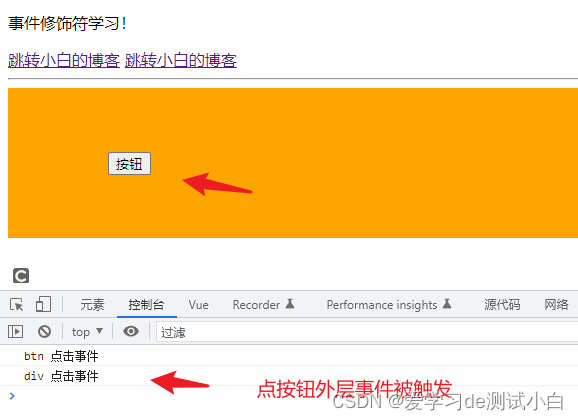
先从最简单的例子开始。我们进入星巴克开始点单。用数学语言来说,我们可能有三种状态。
第一种状态(O)是我们点咖啡。第二种状态(M)我们已经点完了咖啡并在等待。M状态导致他们帮你做咖啡。然后你拿到咖啡并转移到离开状态(L)。这意味着你的咖啡已经做好了你也可以走了。

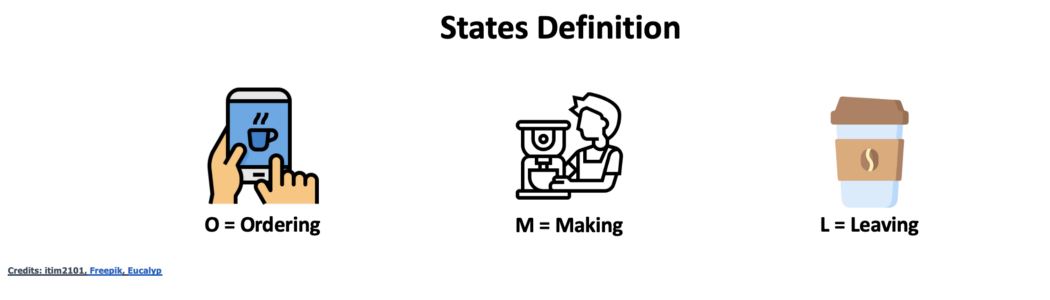
图片来自作者
好的。现在,可能的转移状态有哪些?
1) 你从点单到制作(O到M)
2) 也能从M到M(持续等待)
3) 最后你从M到L

图片来自作者
我们如何将其形式化呢?
1.1 关于马尔科夫链
马尔科夫链的假设是什么?具体如下:
“处入下一状态的概率仅依赖于当前状态”
例如:
在t=5的时候处入离开状态L的概率仅仅依赖于你在t=4时处于制作状态M中。
让我们将其形式化:

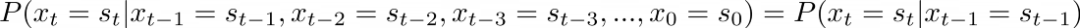
图片来自作者
在上述符号系统当中,我们在时间t时状态的概率,在空间s_t (O, M, L) 里仅依赖于我们在t-1时的状态。
在实验中我们还需要记住的是,t时刻的概率也是时间依赖的。因为,如果你已经等了5分钟,在下一分钟离开的概率就比只等待1分钟后离开的概率更大。
这意味着:

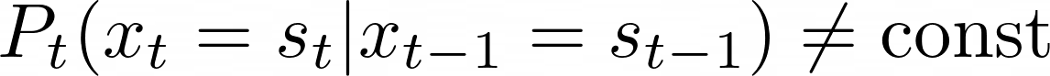
图片来自作者
这就是文章开头提到过的概念。
当然,星巴克不仅有我们在,也有很多其他顾客在!所以我们马上会把这个设置复杂化。但上述是一切的起点。
接下来我们正式开始!
2. 一顾客一饮品的例子
让我们从最简单的情况开始。我们知道要喝什么并且我们是咖啡店唯一的顾客。
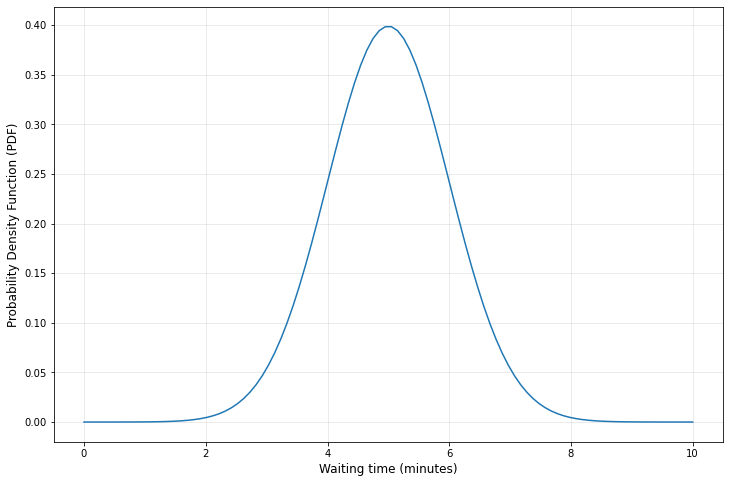
假设我们想要一杯焦糖玛奇朵。allrecipes食谱网站说做一杯需要5分钟。假设我们需要30秒来点单和支付。所以总共等待时间可能有5分30秒。但是让我们更进一步,5分钟只是平均制作时间,一般要用4-6分钟:

图片来自作者
好的。我们假设时间刻度是30秒(0.5分钟)。我们在30秒后有可能拿到我们的咖啡,也有可能8分钟之后我们仍然在等待。
2.1 动手实现
让我们来执行一下这个过程。首先导入库:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from scipy import signal
import sklearn
import seaborn as sns
Hosted on Jovian接下来定义状态:
customer_state = ['Ordering the coffee','Waiting for your coffee','Leaving']
states = {'O':customer_state[0],'M':customer_state[1],'L':customer_state[2]}接下来我们使用下面这个函数运行上述过程:
mu, sigma = 5,1
def one_drink_one_cust():
start = states['O']
print(start+'\n')
ordering_time = 0.5
first_state = states['M']
print(first_state+'\n')
waiting_time = 0
k = 0
while k == 0:
p = stats.norm.cdf(waiting_time, loc=mu, scale=sigma)
k = np.random.choice([0,1],p = [1-p,p])
waiting_time = waiting_time+0.5
if k == 0:
print('Coffee is brewing... \n')
print('Your coffee is ready! \n')
print(states['L']+'\n')
print('Waiting time is = %.2f'%(waiting_time))
return waiting_time这里是一次运行例子:
运行 one_drink_one_cust()
3. 一顾客多饮品
现在,让我们增加模型复杂性让情况更真实一些。
我们并不知道特定的顾客想要啥。而这种情况更真实的原因在于星巴克有多达150种饮品,且他们可能需要不同的等待时长。
现在马尔科夫链看起来像这样

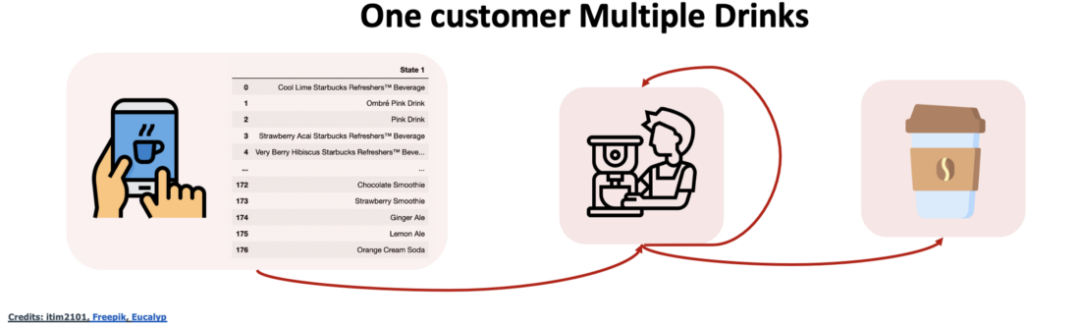
图片来自作者
与之前的一个例子不同之处在于,这里有一个概率分布,我们叫做:

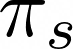
图片来自作者
特别地,所有可能的饮品有一个概率分布,我们叫做:

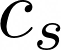
图片来自作者
例如:

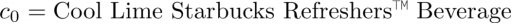
图片来自作者
所以我们可以说:

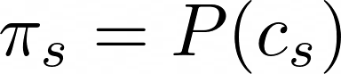
图片来自作者
3.1实际操作
我们可以从kaggle数据集
(https://www.kaggle.com/datasets/ashishpatel26/starbucks-menu-nutrition-drinks)导入所有的
星巴克饮品:
pd.read_csv('starbucks-menu-nutrition-drinks.csv')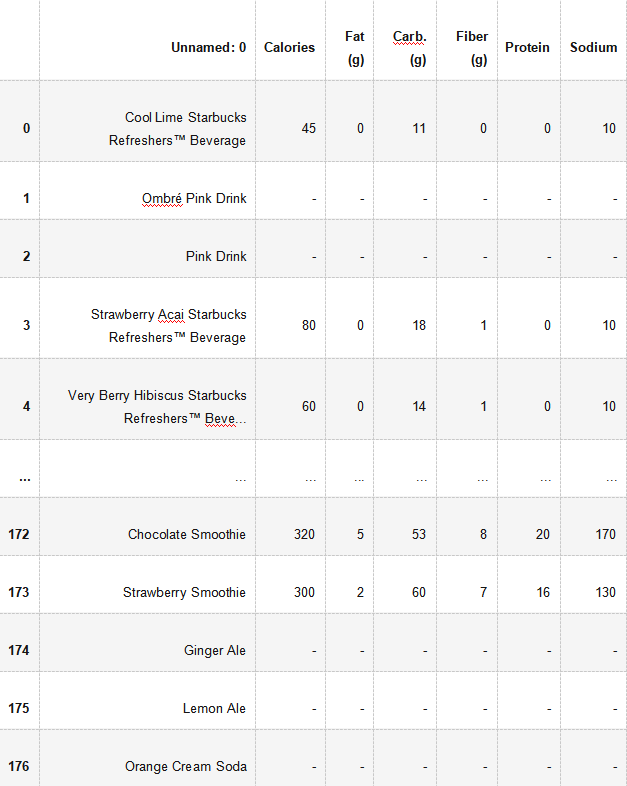
177 rows × 7 columns
Hosted on Jovian我们不需要其他列。
我们不知道最热门的单品是哪一个,所以我们做一个假的分布:
kind_of_coffee = np.array(pd.read_csv('starbucks-menu-nutrition-drinks.csv')['Unnamed: 0'])
p_start = []
for i in range(len(kind_of_coffee)):
p_start.append(np.random.choice(np.arange(50,100)))
p_start = np.array(np.array(list(np.array(p_start)/sum(p_start))))
Hosted on Jovian我们从50-100提取值,然后我们用和进行归一化,得到一个概率向量
coffe_picked = []
for i in range(10000):
coffe_picked.append(np.random.choice(range(0,len(kind_of_coffee)),p=p_start))
sns.displot(coffe_picked)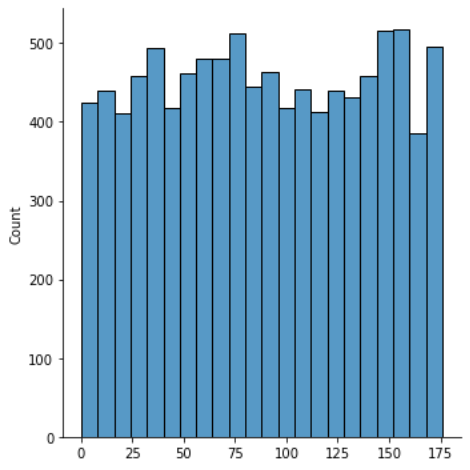
我们有了自己的概率分布。我们接下来要做什么?概率分布将会为我们作出选择:我们将从分布中取样。然后假设每种咖啡需要不同的制作时间。
现在,客观来说,没有太大的差异。假设需要3分钟(平均时长)来完成一杯最“简单”的咖啡(可能是黑咖啡),6分钟(平均时长)来完成一杯最复杂的咖啡(额外鲜奶油加糖屑肉桂豆浆的焦糖玛奇朵)
我们把方差变化范围取到0.1-1。
coffee_data = pd.DataFrame(kind_of_coffee,columns=['State 1'])
mu_list = []
var_list = []
for i in range(len(coffee_data)):
mu_list.append(np.random.choice(np.linspace(3,6,1000)))
var_list.append(np.random.choice(np.linspace(0.1,1.5,1000)))
coffee_data[r'$\mu$']=mu_list
coffee_data[r'$\sigma$']=var_list
coffee_data[r'$p$'] = p_start
coffee_data.head()
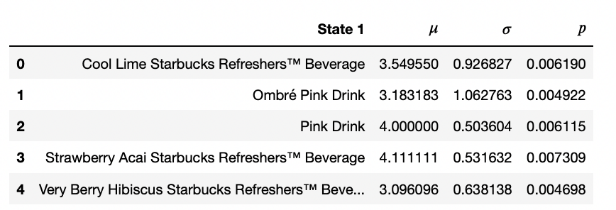
我们的均值可以从3-6取值,平均等待时长也可以从3-6分钟,有时不确定性更大。例如,有可能当你喝咖啡A的时候,等待的时间更长。
用代码来实现这一情形:
def random_drink_one_cust():
start = states['O']
print(start+'\n')
ordering_time = 0.5
first_state = states['M']
chosen_i = np.random.choice(range(0,len(kind_of_coffee)),p=p_start)
print('Ordering coffee %s'%(kind_of_coffee[chosen_i]))
print(first_state+'\n')
mu_i, var_i = coffee_data[r'$\mu$'].loc[chosen_i], coffee_data[r'$\sigma$'].loc[chosen_i]
waiting_time = 0
k = 0
while k == 0:
p = stats.norm.cdf(waiting_time, loc=mu_i, scale=var_i)
k = np.random.choice([0,1],p = [1-p,p])
waiting_time = waiting_time+0.5
if k == 0:
print('Coffee is brewing... \n')
print('Your coffee is ready! \n')
print(states['L']+'\n')
print('Waiting time is = %.2f'%(waiting_time))
return waiting_time
random_drink_one_cust()输出:
Ordering the coffee
Ordering coffee Teavana® Shaken Iced Black Tea
Waiting for your coffee
Coffee is brewing...
Coffee is brewing...
Coffee is brewing...
Coffee is brewing...
Coffee is brewing...
Coffee is brewing...
Coffee is brewing...
Your coffee is ready!
Leaving
Waiting time is = 4.00
4.0
现在,我相信我们可以提取一些额外的有价值的信息。例如……
“不管你在星巴克点什么咖啡,你通常需要等多久呢?”
这一个问题非常宽泛,所以我们也可以用一些统计数据来回答:
waiting_time_list = []
for i in range(10000):
waiting_time_list.append(random_drink_one_cust())
plt.figure(figsize=(20,10))
plt.subplot(2,1,1)
sns.histplot(waiting_time_list,fill=True)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.xlabel('Waiting time (minutes)',fontsize=14)
plt.ylabel('Count',fontsize=14)
plt.subplot(2,1,2)
sns.kdeplot(waiting_time_list,fill=True)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.xlabel('Waiting time (minutes)',fontsize=14)
plt.ylabel('Probability Density Function (PDF)',fontsize=14)
Text(0, 0.5, 'Probability Density Function (PDF)')
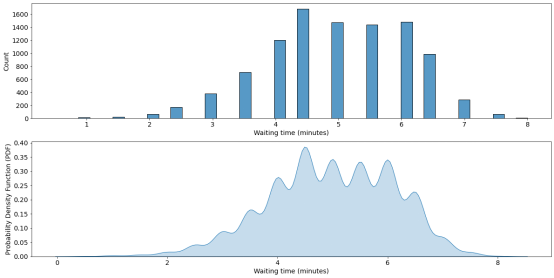
我改变了函数,去掉了所有的“print”,以便于我的电脑不会爆炸。
4. 多顾客多饮品
好的。现在我们有多名顾客,我们怎么办呢?现在的情形看起来像这样:

图片来自作者
现在去思考每次只能等前一杯咖啡做完才能做下一杯的情况已经不现实了。星巴克通常都有3,4个咖啡师。
这会让代码变得有点复杂,因为我们需要追踪所有咖啡师是否忙碌的事实。由于这个原因,该函数我们将设计为顾客数和咖啡师数量的函数。
函数如下:
def random_drink_multiple_cust(cust=2,num_baristas =5):
time_of_process = []
baristas = np.zeros(num_baristas)
q = 0
ordering_time = 0
for c in range(cust):
start = states['O']
print('Customer number %i is ordering'%(c))
ordering_time+=0.5
if sum(baristas)!=num_baristas:
print('There is at least one free baristas! :)')
waiting_time = random_drink_one_cust()
time_of_process.append(waiting_time+ordering_time)
baristas[q] = 1
q = q + 1
if len(time_of_process)==cust:
break
if sum(baristas)==num_baristas:
print('All the baristas are busy :(')
print('You have to wait an additional %i minutes until they can start making your coffee' %(min(time_of_process)))
waiting_time = min(time_of_process)+random_drink_one_cust()+ordering_time
baristas[num_baristas-1]=0
time_of_process.append(waiting_time)
q = q-1
if len(time_of_process)==cust:
break
print('The waiting time for each customer is:')
print(time_of_process)
return time_of_process好的,让我们来测试一下4个顾客和2个咖啡师的情况。
random_drink_multiple_cust(4,2)
Customer number 0 is ordering
There is at least one free baristas! :)
Ordering the coffee
Ordering coffee Iced Caffè Americano
Waiting for your coffee
Your coffee is ready!
Leaving
Customer number 1 is ordering
There is at least one free baristas! :)
Ordering the coffee
Ordering coffee Iced Skinny Mocha
Waiting for your coffee
Your coffee is ready!
Leaving
All the baristas are busy :(
You have to wait an additional 6 minutes until they can start making your coffee
Ordering the coffee
Ordering coffee Tazo® Bottled Organic Iced Black Tea
Waiting for your coffee
Your coffee is ready!
Leaving
Customer number 2 is ordering
There is at least one free baristas! :)
Ordering the coffee
Ordering coffee Starbucks® Bottled Caramel Frappuccino® Coffee Drink
Waiting for your coffee
Your coffee is ready!
Leaving
The waiting time for each customer is:
[7.0, 6.5, 14.0, 5.5]
[7.0, 6.5, 14.0, 5.5]在前两个例子中,咖啡师是有空的情况下,他们分别要等待7分钟和6.5分钟。
注意?这不是错误!这只意味着第二杯咖啡快于第一杯咖啡+点单的时间和。你仔细想想就可以想得通。如果你点了一杯复杂的咖啡,我只点了一杯拿铁,我可以比你等的时间更短,即使你在我之前点单。
然后是咖啡师忙的情况。我们不得不在点单之前额外等6分钟。(我可以让情况更真实一点,并减去1分钟点单时间,但是你的想法是对的吗?)
到第四个顾客点单时,有一个空闲的咖啡师,所以他不用再等那么长时间,只需要等5.5分钟。
注意到这个模型的复杂度以及情况的有趣性。以下是10个顾客和5个咖啡师:
random_drink_multiple_cust(10,5)
Customer number 0 is ordering
There is at least one free baristas! :)
Ordering the coffee
Ordering coffee Iced Coconutmilk Mocha Macchiato
Waiting for your coffee
Your coffee is ready!
Leaving
Customer number 1 is ordering
There is at least one free baristas! :)
Ordering the coffee
Ordering coffee Coffee Frappuccino® Blended Coffee
Waiting for your coffee
Your coffee is ready!
Leaving
Customer number 2 is ordering
There is at least one free baristas! :)
Ordering the coffee
Ordering coffee Strawberry Acai Starbucks Refreshers™ Beverage
Waiting for your coffee
Your coffee is ready!
Leaving
Customer number 3 is ordering
There is at least one free baristas! :)
Ordering the coffee
Ordering coffee Shaken Sweet Tea
Waiting for your coffee
Your coffee is ready!
Leaving
Customer number 4 is ordering
There is at least one free baristas! :)
Ordering the coffee
Ordering coffee Coffee Traveler
Waiting for your coffee
Your coffee is ready!
Leaving
All the baristas are busy :(
You have to wait an additional 5 minutes until they can start making your coffee
Ordering the coffee
Ordering coffee Starbucks® Doubleshot Protein Vanilla
Waiting for your coffee
Your coffee is ready!
Leaving
Customer number 5 is ordering
There is at least one free baristas! :)
Ordering the coffee
Ordering coffee Coconutmilk Mocha Macchiato
Waiting for your coffee
Your coffee is ready!
Leaving
All the baristas are busy :(
You have to wait an additional 5 minutes until they can start making your coffee
Ordering the coffee
Ordering coffee Nitro Cold Brew with Sweet Cream
Waiting for your coffee
Your coffee is ready!
Leaving
Customer number 6 is ordering
There is at least one free baristas! :)
Ordering the coffee
Ordering coffee Starbucks® Low Calorie Iced Coffee + Milk
Waiting for your coffee
Your coffee is ready!
Leaving
All the baristas are busy :(
You have to wait an additional 5 minutes until they can start making your coffee
Ordering the coffee
Ordering coffee Tazo® Bottled Lemon Ginger
Waiting for your coffee
Your coffee is ready!
Leaving
The waiting time for each customer is:
[5.5, 5.5, 7.0, 8.0, 6.5, 12.5, 8.5, 12.5, 7.5, 16.0]
[5.5, 5.5, 7.0, 8.0, 6.5, 12.5, 8.5, 12.5, 7.5, 16.0]5. 注意事项
在本文中,我们讨论一个排队等待时长的一般性问题。有不同的场景:
1) 我们可能是商店唯一顾客且明确知道自己想要买什么
2) 我们可能是商店唯一顾客但不知道自己想要买什么
3) 我们不是商店唯一顾客且不知道自己想要买什么
这三个场景依次变得复杂。由此,马尔科夫链也会变得越来越复杂。
1) 在第一个例子里,唯一的概率分布是煮咖啡的过程。例如,需要花费平均时长5分钟来做焦糖玛奇朵,制作时长是方差为1的高斯分布
2) 在第二个例子里,我们得到了所选咖啡的概率分布加上制作咖啡的概率分布,也就是之前那个
3) 第三个例子里,我们用上述两种情况,并且咖啡师变成了另外一个需要考虑的因素
我们可以让那个这个模型更复杂一点。我们可以考虑这样一个事实:机器是可以坏的。我们也可以考虑咖啡师人手不够的情况。可以考虑咖啡师人数随时间变化,也可以考虑一些咖啡师比另外一些人操作更快。以及更多可能性。
这个起点可以用来以几乎所有你想要的方式使模型复杂化。只要记住,我们使用的是时间相关马尔可夫链工具,并以此为基础进行构建。
原文标题:
Modeling Starbucks Waiting Time Using Markov Chains, with Python
原文链接:
https://towardsdatascience.com/modeling-starbucks-waiting-time-using-markov-chains-with-python-ab267670d02c
编辑:于腾凯
校对:林亦霖
译者简介

陈超,北京大学应用心理硕士,数据分析爱好者。本科曾混迹于计算机专业,后又在心理学的道路上不懈求索。在学习过程中越来越发现数据分析的应用范围之广,希望通过所学输出一些有意义的工作,很开心加入数据派大家庭,保持谦逊,保持渴望。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织