目录
1. 判断素数的个数 ☆
2. 分隔链表 ★★
3. 数据流的中位数 ★★
1. 判断素数的个数
在一个数组A中存放100个数据,用子函数判断该数组中哪些是素数,并统计该素数的个数,在主函数中输出该素数的个数。
代码:
#include <stdio.h>
#include <stdlib.h>
int isPrime(int n)
{
int i;
if (n < 2)
return 0;
for (i = 2; i * i <= n; ++i)
{
if (n % i == 0)
return 0;
}
return 1;
}
int CountPrime(int a[], int size)
{
int i = 0, count = 0;
for (i = 0; i < size; i++)
{
if (isPrime(a[i]))
{
printf("%d ", a[i]);
count++;
if (count % 10 == 0)
printf("\n");
}
}
printf("\n");
return count;
}
int main()
{
int a[100], i, count = 0;
for (i = 0; i < 100; i++)
a[i] = rand() % 1000;
printf("素数的个数:%d\n", CountPrime(a, 100));
return 0;
}输出:
41 467 281 827 491 827 421 811 673 547
757 37 859 101 439 929 541
素数的个数:17
2. 分隔链表
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
示例 1:
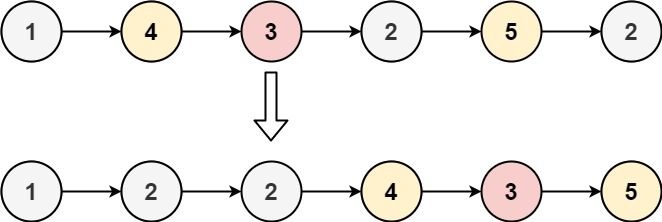
输入:head = [1,4,3,2,5,2], x = 3 输出:[1,2,2,4,3,5]
示例 2:
输入:head = [2,1], x = 2 输出:[1,2]
提示:
- 链表中节点的数目在范围
[0, 200]内 -100 <= Node.val <= 100-200 <= x <= 200
代码:
#include <stdio.h>
#include <stdlib.h>
struct ListNode
{
int val;
struct ListNode *next;
};
struct ListNode *partition(struct ListNode *head, int x)
{
struct ListNode dummy;
struct ListNode *prev1 = &dummy, *pivot;
dummy.next = head;
for (pivot = head; pivot != NULL; pivot = pivot->next)
{
if (pivot->val >= x)
{
break;
}
prev1 = pivot;
}
struct ListNode *p = pivot->next;
struct ListNode *prev2 = pivot;
while (p != NULL)
{
if (p->val < x)
{
prev2->next = p->next;
p->next = prev1->next;
prev1->next = p;
prev1 = p;
p = prev2->next;
}
else
{
prev2 = p;
p = p->next;
}
}
return dummy.next;
}
int main()
{
int target = 3;
struct ListNode *head = NULL;
struct ListNode *prev = NULL;
struct ListNode *p;
int arr[] = {1,4,3,2,5,2};
for (unsigned int i = 0; i < sizeof(arr)/sizeof(int); i++)
{
p = (ListNode*)malloc(sizeof(*p));
p->val = arr[i];
p->next = NULL;
if (head == NULL)
{
head = p;
prev = head;
}
else
{
prev->next = p;
prev = p;
}
}
p = partition(head, target);
while (p != NULL)
{
printf("%d ", p->val);
p = p->next;
}
printf("\n");
return 0;
}输出:
1 2 2 4 3 5
比较阅读
单链表的倒转
class Solution {
public:
ListNode* ReverseList(ListNode* head) {
if (head == NULL) return NULL;
ListNode *p = NULL;
ListNode *p1 = head;
ListNode *p2 = p1->next;
while (p2 != NULL) {
p1->next = p;
p = p1;
p1 = p2;
p2 = p2->next;
}
return p;
}
};
3. 数据流的中位数
中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。
例如,
[2,3,4] 的中位数是 3
[2,3] 的中位数是 (2 + 3) / 2 = 2.5
设计一个支持以下两种操作的数据结构:
- void addNum(int num) - 从数据流中添加一个整数到数据结构中。
- double findMedian() - 返回目前所有元素的中位数。
示例:
addNum(1) addNum(2) findMedian() -> 1.5 addNum(3) findMedian() -> 2
进阶:
- 如果数据流中所有整数都在 0 到 100 范围内,你将如何优化你的算法?
- 如果数据流中 99% 的整数都在 0 到 100 范围内,你将如何优化你的算法?
代码:
#include <bits/stdc++.h>
using namespace std;
class MedianFinder
{
public:
/** initialize your data structure here. */
MedianFinder()
{
}
void addNum(int num)
{
auto it = upper_bound(nums.begin(), nums.end(), num);
nums.insert(it, num);
}
double findMedian()
{
int n = nums.size();
if (n % 2 == 0)
return 1.0 * (nums[n / 2 - 1] + nums[n / 2]) / 2;
else
return nums[n / 2];
}
vector<int> nums;
};
/**
* Your MedianFinder object will be instantiated and called as such:
* MedianFinder obj = new MedianFinder();
* obj.addNum(num);
* double param_2 = obj.findMedian();
*/
int main()
{
MedianFinder obj = MedianFinder();
obj.addNum(1);
obj.addNum(2);
double median1 = obj.findMedian();
obj.addNum(3);
double median2 = obj.findMedian();
cout << median1 << endl << median2 << endl;
return 0;
}输出:
2
1.5
🌟 每日一练刷题专栏
✨ 持续,努力奋斗做强刷题搬运工!
👍 点赞,你的认可是我坚持的动力!
★ 收藏,你的青睐是我努力的方向!
✏️ 评论,你的意见是我进步的财富!
 | C/C++ 每日一练 专栏 |
 | Python 每日一练 专栏 |